이번 주에는 미니프로젝트 5차와 6차가 연이어 진행되었는데요, 5차 프로젝트는 KT에서 주관하는 AICE(AI 자격증) 대비 특강이 있었고, AICE 시험과 비슷한 유형의 문제로 혼자서 시험을 치르는 듯한 과제를 해보는 기회가 있었습니다.
6차 프로젝트에서는 3일 동안 다양한 데이터를 활용하여 특정 가게의 특정 상품들의 2일 후 판매량(Lead Time)을 예측하는 모델을 만들기 위해 데이터 분석, 데이터 전처리, 모델링 작업을 진행했습니다.
같은 가게 상품에 대한 3가지 상품을 예측하는 것이 목표였었는데 저희 조는 총 7명이었기 때문에, 각각 2명, 2명, 3명씩 나누어 프로젝트를 수행했습니다.
먼저 AICE 자격증에 대해 설명드리겠습니다.
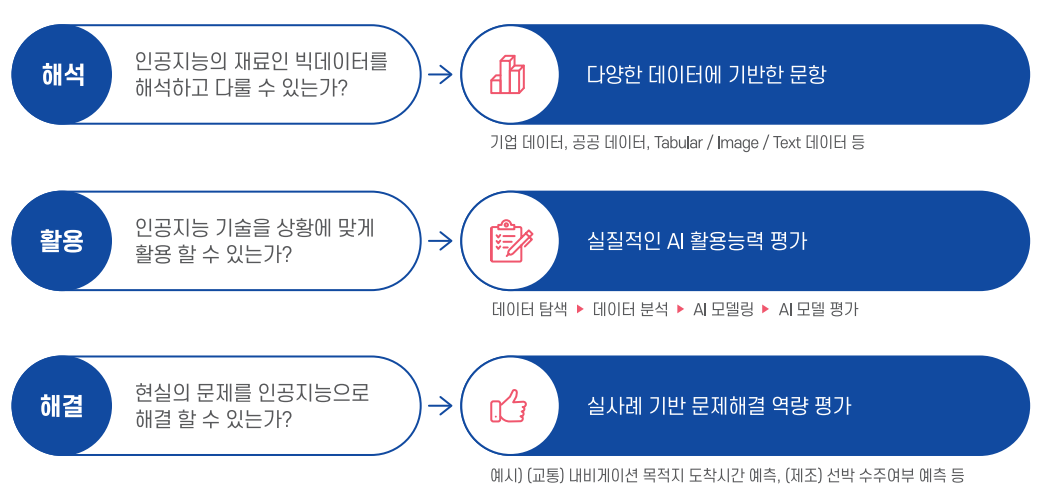
AICE 자격증은 KT가 개발하고 한국경제신문이 함께 주관하는 인공지능 활용 능력을 평가하는 시험입니다.
이 자격증의 주요 목적은 인공지능을 제대로 다룰 수 있는 능력을 검증하는 것입니다.
AICE 자격증은 초등학생부터 성인, 비전공자부터 전공자까지 필요한 AI 역량에 따라 다섯 가지 수준으로 구분되어 있습니다.

AICE ASSOCIATE의 출제 범위는 비즈니스 혁신 역량에 해당하는 데이터 분석 및 모델링으로,
다음과 같은 내용을 포함합니다:
1. 탐색적 데이터 분석
2. 데이터 전처리
3. 머신러닝/딥러닝 모델링
4. 모델 성능평가
이와 관련하여 1일차와 2일차 동안 총 세 가지 과제를 수행해보는 시간을 가졌습니다.
미니프로젝트 5차가 끝난 후, 6차 프로젝트가 시작되었습니다.
이번 6차 프로젝트는 미국의 특정 주에 위치한 상점의 상품들의 이틀 후 판매량을 예측하는 모델을 만드는 것이었습니다.
첫째 날에는 데이터에 대해 탐색적 데이터 분석(EDA)을 진행했습니다.
팀원들과 함께 데이터를 어떻게 처리할지 근거를 찾고, 그 근거에 대해 논의했습니다.
선형보간, 평균값 등 여러 방법을 통해 결측치를 처리하고, 파생변수를 만들어보면서 다양한 접근을 시도했습니다.
하루 종일 EDA만 진행하라는 강사님 덕분에 데이터에 대해 더 깊이 고민할 수 있는 시간이 있어서 좋았습니다.
그런데 2일차와 3일차에 모델을 돌려본 결과, 모델의 성능이 기대했던 만큼 나오지 않았습니다.
오히려 강사님은 결측치를 전부 'dropna'를 사용해 제거하고, 파생변수를 다양하게 생성하기보다는 한두 가지만 사용했는데, 이 방법이 제가 만들었던 데이터보다 오히려 성능이 좋았습니다.
또한 모델의 레이어를 쌓을 수록 오히려 성능이 떨어지거나 과적합이 일어나는 현상을 발견했습니다.
이러한 결과를 보고 느낀 점은 때로는 모델을 단순화하는 것이 더 효과적일 수 있다는 것입니다.
너무 많은 파생변수를 추가하거나 복잡하게 모델을 구성하기보다, 필요한 핵심 데이터에 집중하는 것이 모델의 성능을 높일 수 있는 중요한 요소임을 깨달았습니다.
또한 1100개 중에 300개의 결측치를 선형보간을 통해 채웠는데, 이 또한 일부 데이터에서 예상치 못한 결과를 초래했습니다.
선형보간 방식이 모든 상황에 적합하지 않을 수 있어, 이는 결국 모델의 정확도를 저하시키는 원인이 되었습니다.
데이터의 결측치 처리 방법에 따라 모델의 성능이 완전히 달라질 수 있기 때문에, 좀 더 많이 생각하고 깊이 고민해보아야겠다는 생각이 들었습니다.
이번 6차 미니 프로젝트는 6일간 전부 대면으로 진행되기로 했어요.
아침마다 교육장에 가는 것이 힘들긴 하지만, 가면 사람들과 이야기하는 것이 재미있더라구요.
I였었는데, E가 된 것 같기도 해요.
이번주 알고리즘 스터디는 한주 쉬어가기로 했습니다!!
그 이유는 함께 공모전을 진행하기로 했기 때문이에요. 

위는 같은 스터디 분이 만드신 디자인인데 되게 잘 만드시더라구요!!
저는 백엔드쪽을 맡았는데 어서 완성해서 보여드리고 싶습니다!!
에이블스쿨을 고민하거나 같이 듣고 있는 분들 모두 화이팅입니다~!!
