Normalization 은 DB 에게 DML 쿼리를 날릴 때,
이상현상(anomaly)을 방지하기 위해 DB 를 분리하는 방법이라 이해하면 좋을 것 같다.
anomaly 란 결국 다음 3가지이다.
- INSERT: can't add
- UPDATE: can't update
- DELETE: can't delete
주어진 요구사항을 만족하는 쿼리를 짜기 어려운가?
당신의 쿼리 작성 능력이 부족할 수도 있지만,
그보다는 근본적으로 데이터베이스 스키마가 잘못 설계되었을 가능성이 크다.
요새는 기획자와 디자이너도 파이썬 프로그래밍과 쿼리를 배우는 시대이다.
쿼리를 요청하는 분들을 데이터베이스의 엔드 유저라고 생각을 해야한다.
데이터베이스 스키마를 설계하는 입장에서는, 엔드유저가 CRUD 쿼리를 쉽게짤 수 있도록,
스키마의 역할과 책임을 이해하고 조합하기 쉽게끔 분리를 해야한다.
마치 객체지향 설계에서, 객체의 단위를 책임에 따라 작게 만들려는 것과 비슷한것 같다.
다만 무조건 작게 만들어도 상관없는 객체설계와 다르게,
DB 는 지나치게 단위가 작아지면 성능이슈가 발생하므로, 균형을 잘 맞추는게 필요할 것 같다.
보통 4NF 까지 다루는 경우는 드문 것 같아서,
1NF, 2NF, 3NF, BCNF 에 대해 정리를 해보려 한다.
(NF : Normalization Form)
요약
- 1NF: atomic data
- 2NF: No partial FD
- 3NF: No transitive FD
- BCNF:
- If FD X -> A
- and FD is not trivial
- and X not contains superkey
- , then X+ = X or X+ = {all attributes}
부가 설명
- NF: Normalization Form
- FD: Functional Dependency
- FD X -> A is trivial if X contains A
- X+ = closure of X
1NF
- all data value should be atomic (flat)
atomic 혹은 flat 이라는 키워드만 기억하면 될것 같다.
단어가 생소하지만, 그냥 attribute 에다가 serialized 된 data value 를 넣지 말라는 소리이다.
db 에다가 이미지 링크가 아닌, 바이너리 데이터를 넣으려는 요상한 분들과 마찬가지로,
db 에다가 json 혹은 csv 를 VARCHAR 데이터로 그대로 쑤셔넣는 사람들이 있다.
이런 경우에는 API 도 list 가 아니라 요상한 csv string 을 반환하는 경우가 있는데,
프론트 개발자도, 백엔드 개발자도 모두 괴롭게 만드는 테이블 설계이다.
1NF 를 지키지 않는 DB 스키마는 바닐라 파일 시스템을 사용하는 것과 다를바가 없다.
성능 이슈와 상관없이, 1NF 는 반드시 지켜져야 하는 normalization form 이라고 생각한다.
2NF
No Partial FD
이걸 이해하려면 FD(Functional Dependency) 에 대한 이해가 필요하다.
Functional Dependency

특정 attribtue 집합으로 다른 attribute 집합을 특정할 수 있다면,
attribute 집합 사이에 FD 가 있다고 할 수 있다.
즉 FD X -> A 에서, X 와 A 는 둘다 attribute 집합이다.
개발자에 친숙한 표현으로 바꾸기 위해 한번 쿼리로 설명을 해보자.
X 를 {x,y,z} 로 하고, A를 {a,b} attribute 집합이라고 해보자.
만약 아래 쿼리를 실행했을 때 결과가 1개의 tuple 이 나온다면,
{x,y,z} -> {a,b} 는 functional dependency 가 있다고 할 수 있다.
SELECT DISTINCT a, b FROM table WHERE x={값} AND y={값} AND z={값}Partial FD
FD X -> A 에서 X 가 minimal 해야함을 뜻한다.
마치 super key 와 candidate key 관계에서 나왔던 minimal 조건을 떠올리면 쉽다.
즉 {x,y,z} -> {a,b} 가 FD 일 때,
{x,y} -> {a,b} 혹은 {y,z} -> {a,b} 처럼 {x,y,z} 의 부분집합에 대해서도 FD 가 성립할때,
Partial FD 가 있다고 한다.
예시
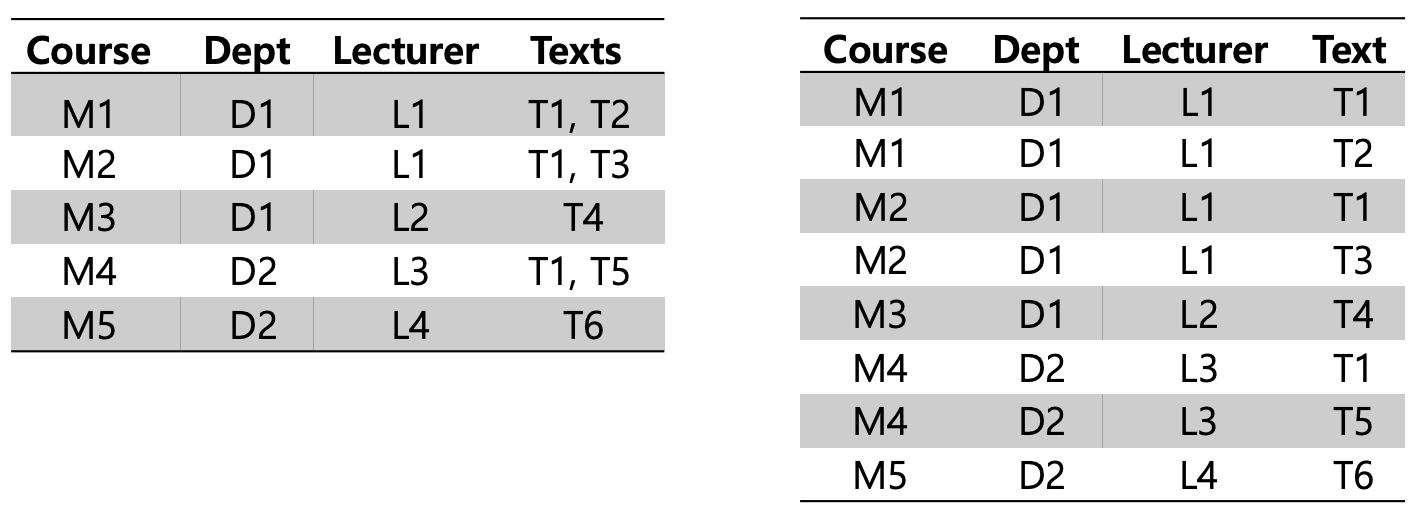
왜 2NF 가 필요한지 파악을 해보자.
Course 에 따라서 {Dept, Lecturer} 와 {Text} 가 결정된다.
하지만 하나의 Course 에 교재(Text) 를 여러개 사용을 할 수도 있기에,
1NF 테이블에서 {Course, Dept, Lecturer} 가 중복되어 나타나고 있다.
즉 {Course, Dept, Lecturer} -> {Text} 에 대한 FD 에 대해
{Course} -> {Text} 라는 Partial FD 가 존재한다.
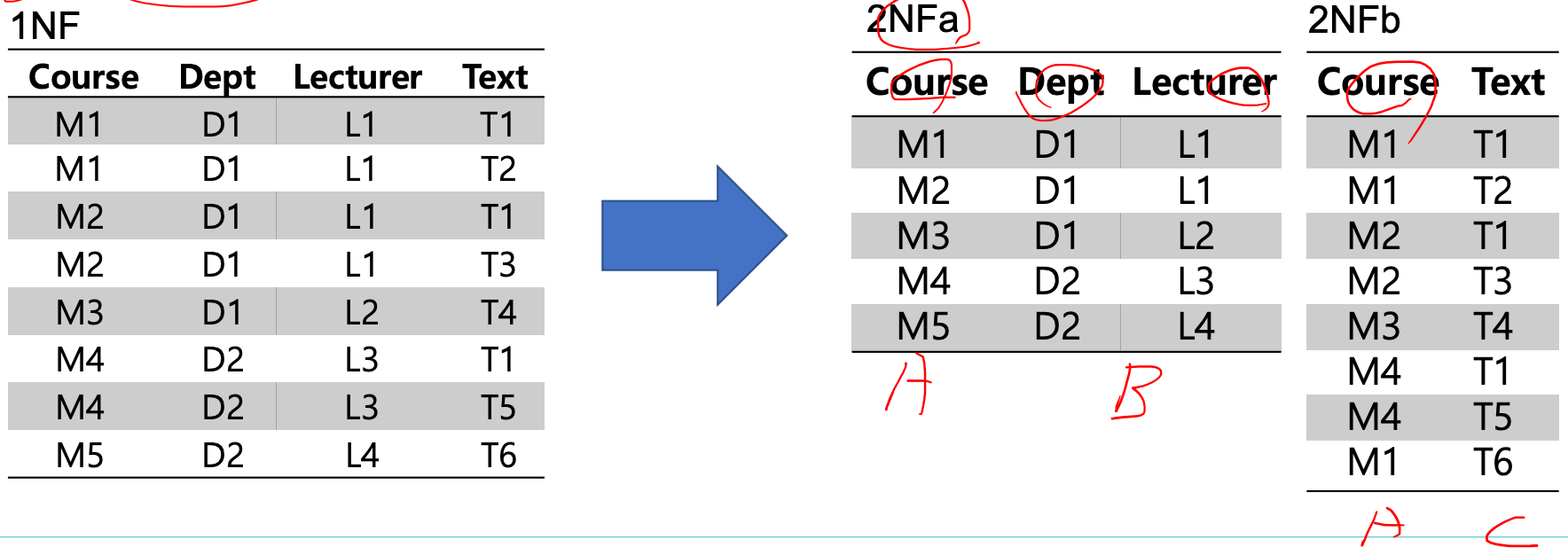
M1 Course 를 생각해보자.
교재(Text) 를 추가, 수정, 삭제할 때는 쿼리를 한번만 날리면 되지만,
강사(Lecturer) 를 바꾸려면 교재의 수만큼 UPDATE 쿼리를 날려야한다.
요렇게 귀찮게 추가로 UPDATE 를 날려줘야하는게 anomaly 이다.
이를 해결하기 위해 2NFa 와 2NFb 로 테이블을 분리하였다.
3NF
No transitive FD
transitive 란 말이 어렵다면 삼단 논법을 기억하자.
If a -> b and b -> c, then a -> c
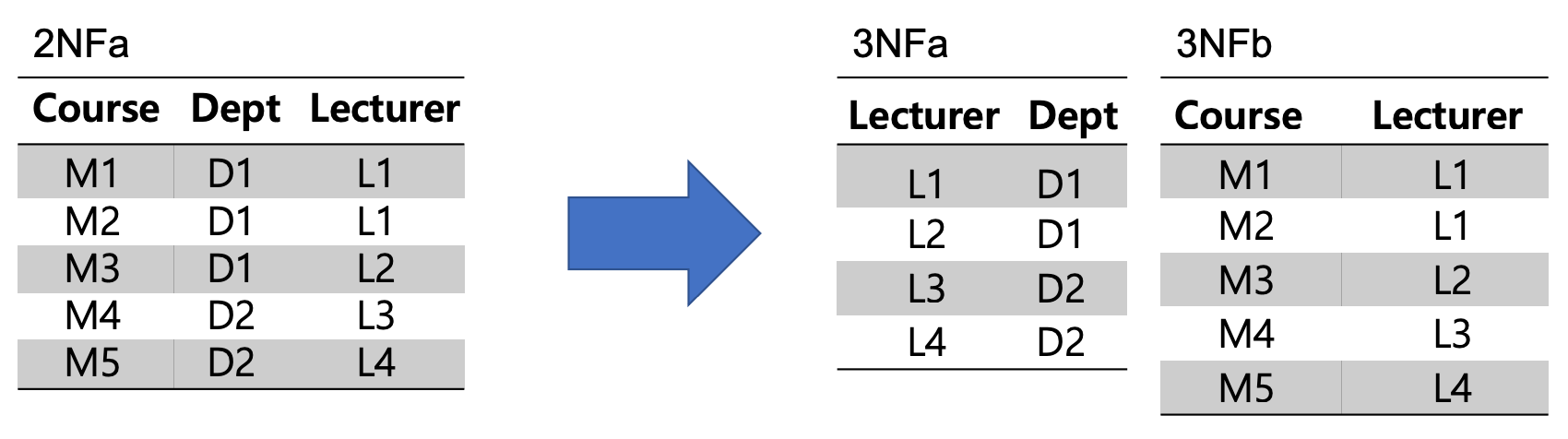
Course 는 한명의 강사가 책임지고 강의한다. FD {Course} -> {Lecturer})
강사는 하나의 부서(Dept)에 소속되어 있다. FD {Lecturer} -> {Dept}
따라서 Course 는 하나의 부서에 소속되어 있다. FD {Course} -> {Dept}
이런 transitive FD 가 같은 테이블에 존재해서는 안된다.
가령 백엔드(D1) Dept 소속의 강사(L1)를 인프라(D3) Dept 소속으로 옮기고 싶다면,
Lecuturer 와 Dept 만이 아니라,
M1 Course 와 M2 Course 2개의 tuple 에 대한 update 가 필요하다.
이렇게 2개의 tuple 이 영향 받는 이유는 결국 transitive 한 의존성 때문이다.
이를 분리해내야한다.
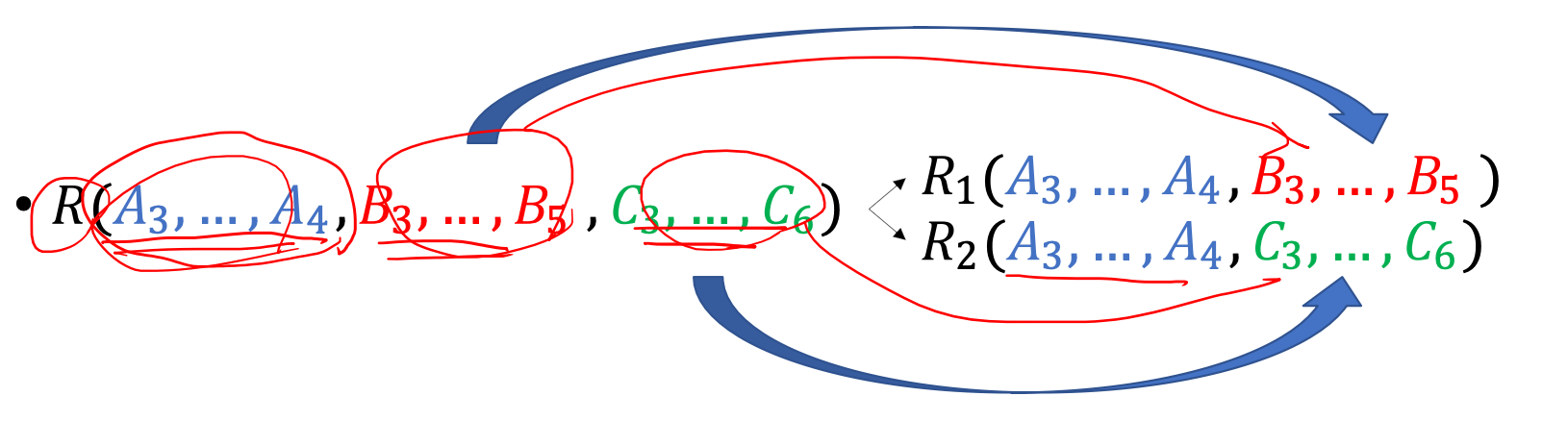
BCNF
If FD X -> A
and FD is not trivial
and X not contains super key
, then X+ = X or X+ = {all attributes}
BCNF 를 이해하려면 먼저 closure(X+) 에 대해서 이해해야한다.
Closure
X: set of attributes
X+ = closure of X
:= {a : (FD X -> a) where a is an attribute}
X+ 는 X 에 대해서 FD 가 성립하는 attirbute 들의 집합이다.
가령 2NFa 테이블에서
Course -> Lecturer & Lecturer -> Dept 인 상황에서,
Course 에 대한 closure 를 구하면 다음과 같다.
{Course}+ = {Course, Lecturer, Dept}
BCNF 결론
말을 어렵게 써놨지만, 조금 더 엄격한 3NF 이다.
3NF 에서 transitive FD 를 배제한 이후에,
non-trivial FD 의 모든 antecedent 가 super key 가 되어야 한다는 뜻이다.
참고로, 2NF 에서 이미 partial FD 를 허용하지 않으므로,
이 super key 는 자동적으로 candidate key 가 된다.
즉 key 와 연관되지 않은 (혹은 tuple 전체를 판별하는 것과 무관한)
FD 를 모두 철저하게 배제한다고 생각할 수 있다.
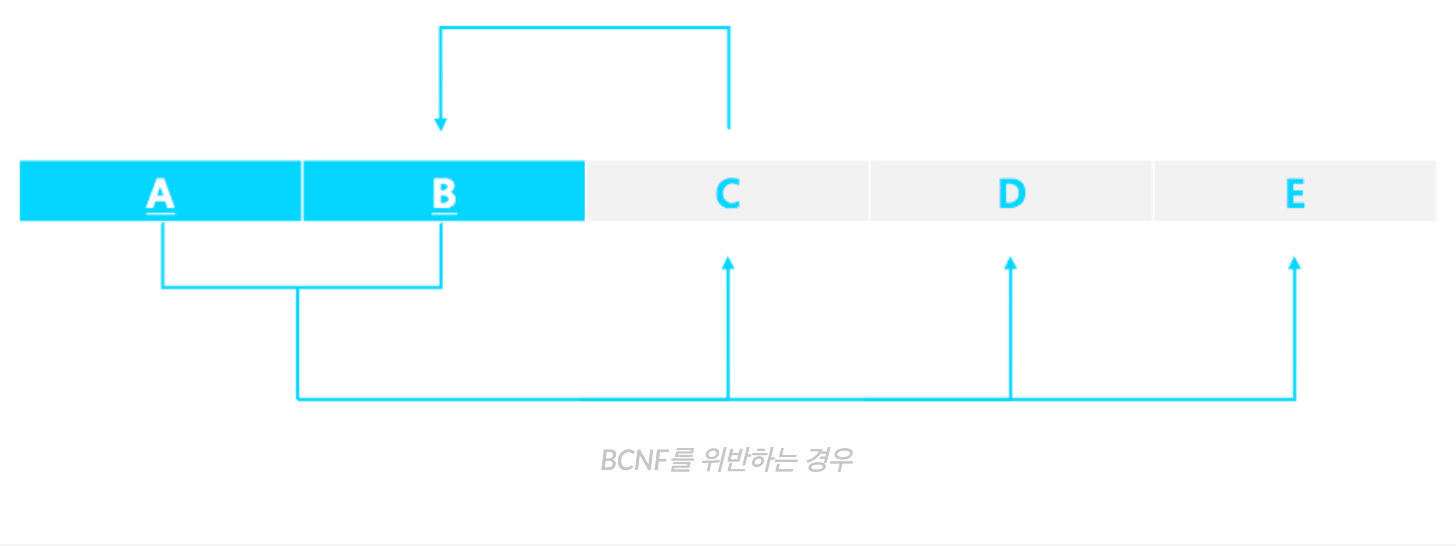
호눅스는 FD 사이에 cycle 이 생기면 BCNF 가 아니라고 직관적으로 이야기 하시던데,
BCNF 를 지키지 않으므로써 생기는 anomaly 를 매우 훌륭하게 표현하신 것 같다.
cycle 을 연결하는 핵심 링크가, 곧 key 와 연관되지 않은 FD 이기 때문이다.
즉 아래와 같은 예시에서는 FD C -> B 로 가는 부분을 별도의 테이블로 분리해내야한다.
참고로 이렇게 분리하는 과정 속에서, 기획에서 정의한 FD 요구사항이 손실될 수도 있으므로,
기획과 함께 면밀한 검토가 필요하다.

좋은 정리 너무 고마워요!
파이로 DB 렉처 정주행 해봐야겠네요.