k mooc 실습으로 배우는 머신러닝 정리
분류(Classification)와 회귀(Regression)
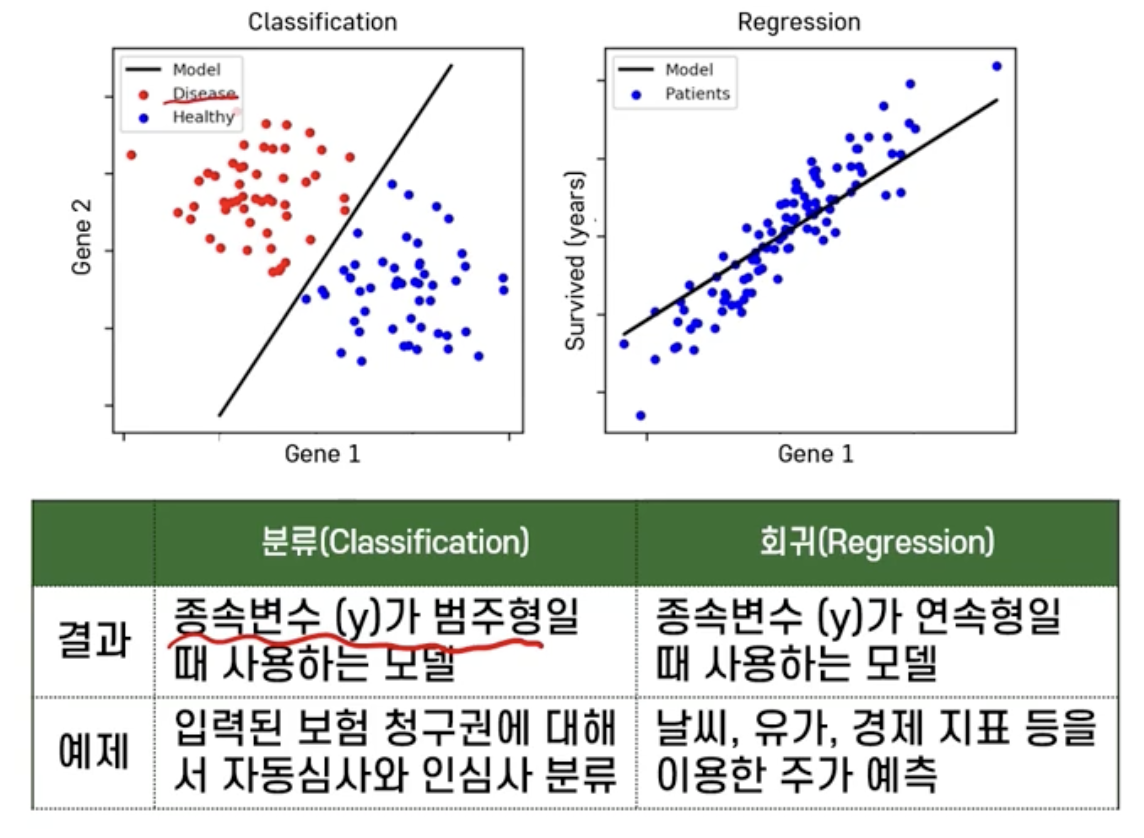
분류는 타겟이 분류되는 선 즉, 함수를 찾는 것이 목적.
회귀는 어떤 변화를 수치적으로 확인하고 싶을 때, x 와 y 간의 상관관계를 표현해 줄 수 있는 함수를 찾는 것이 목적
Data 준비 과정
1. Dataset Exploration
- 데이터 모델링을 하기 전에 데이터 변수 별 기본적인 특성들을 탐색하고 데이터의 분포적인 특징을 이해
- EDA(탐색적 데이터 분석)
2. Missing Value
- 데이터를 수집하다 보면 일부 데이터가 수집되지 않고 결측치로 남아 있는 경우가 있어서 이러한 부분 보정필요
3. Data Types and Conversion
- 데이터셋 안에 여러 종류의 데이터 타입(숫자, 텍스트, 범주, 시간 등)이 있을 수 있고, 이를 분석 가능한 형태로 변환 후 사용해야 한다.
- 이 데이터 정제 단계에서 사실 가장 많은 시간이 소요된다.
4. Normalization
- 데이터 변수들의 단위가 크게 다른 경우들이 있고, 이러한 것들이 모델 학습에 영향을 주는 경우가 있어서 정규화 함.
- ex) 몸무게 10~100 단위, 소득 100만~1000만 단위 처럼 많은 차이가 나는경우 모형에 영향을 줄 수 있음
- 스케일링
5. Outliers(이상치)
- 관측치 중에서 다른 관측치와 크게 차이가 나는 관측치들이 있고 이러한 관측치들은 모델링 전처리가 필요함.
6. Feature Selection(변수 선택)
- 많은 변수 중에서 모델링을 할 때 중요한 변수가 있고 그렇지 않은 변수가 있어서 선택이 필요한 경우가 있음.
7. Data Sampling
- 모델을 검증하거나 이상 관측치를 찾는 모델링을 할 때 또는 앙상블 모델링을 할 때 가지고 있는 데이터를 일부분 추출하는 과정을 거치기도 함.
Modeling(모델링)
- Model
모델은 입력 변수와 출력 변수 간의 관계를 정의해줄 수 있는 추상적인 함수 구조.
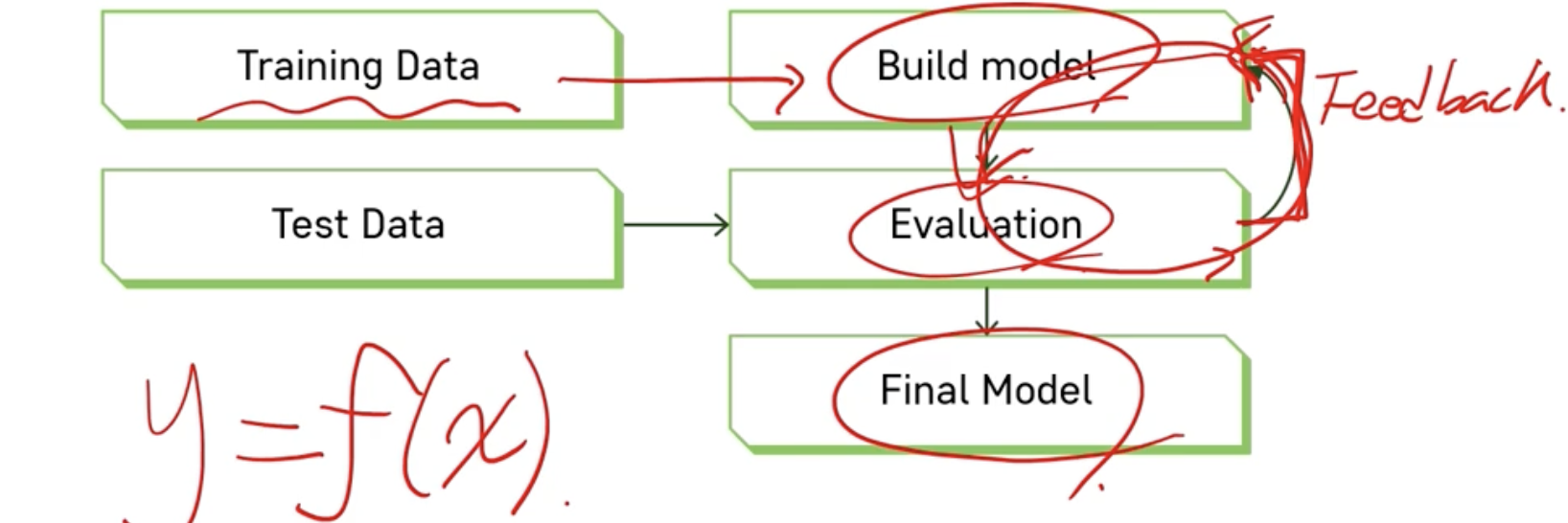
Build model 단계와 Evaluation 단계에서 원하는 만큼의 결과가 나오지 않는다면 계속 순환하면서 feedback 과정이 필요하다.
그 후 최종적인 모델을 정한다.
Modeling 검증
- Testing error = validation error => 둘 다 트레이닝에 사용되지 않았던 데이터를 가지고 검증한다
- 오차가 크면 underfitting 과 overfitting 을 의심해볼 필요가 있다.
- validation error 가 가장 작을 때, 그때의 복잡도를 가지는 모형을 잘 선택해주어야 한다.
복잡도는 어떻게 결정을 할까 ?
- 모형의 기본적인 형태를 직접 구축해야하는데, 이 기본적인 형태를 구축하는 과정에서 모형의 복잡도를 사용자가 결정을 해줄 수 있다 => hyperparameter 를 조정한다.
검증 방식
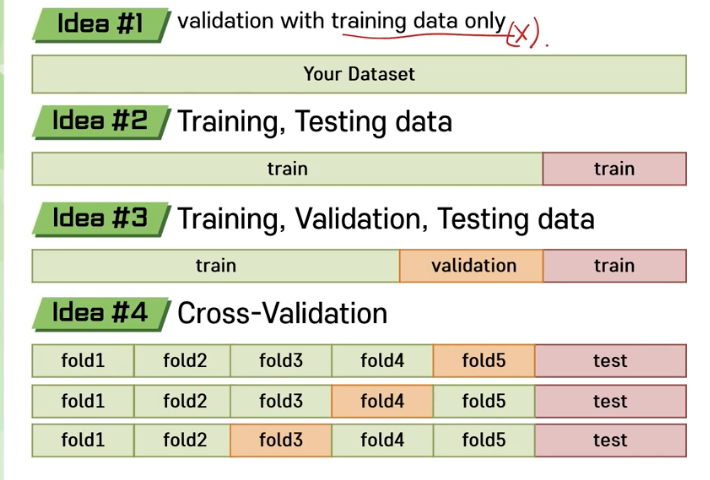
- training data만 사용해서 정말 이 모형이 일반화가 잘되는지 확인할 수 없음. (사용 X)
- 트레이닝을 하고 학습된 모형을 테스팅에다가 테스트 해보는 방법.
- hyperparameter 를 바꿔가면서 검증해보고 검증한 결과에도 사용되지 않았던 테스트 데이터를 가지고 검증하는 것이 가장 검증력이 높은데, 적절한 hyperparameter를 고를 수가 없음.
- 가장 일반적인 절차
- train, validation, test 세개로 나눈다.
- train 데이터로 모형을 학습하고, validation 데이터에 대해서 검증을 하면서 가장 적합한 어떤 모델의 복잡도를 결정 해준다.
- 결정이 됐으면 validation 을 test로 편입 시켜서 최종적으로 결정된 모델 복잡도의 모형을 가지고서 train 을 시키고 최종 테스팅을 해서 실제로 이 정도의 성능이 나올 것이라는 결과를 도출.
- 일반적으로 train 데이터 7, validation 2, test 1 정도로 나누기도 하고 5:3:2 로 나눌 수도 있음.
- 데이터 숫자가 적은 경우 주로 사용.
- 전체 데이터를 폴더를 나눠서 사용
- 나눠진 상황에서 validation 을 순차적으로 바꿔가면서 적용 후 최적의 파라미터와 복잡도를 찾고
- 마지막에 테스팅하는 방법이다.

고수