인공지능과 머신러닝에 대해 ..
k-mooc 실습으로 배우는 머신러닝
- 인공지능과 머신러닝 개요
- 머신러닝 학습 개념
- 머신러닝 프로세스 및 활용
내용 정리
머신러닝 : 함수를 학습하는것 => 데이터가 있고 그 다음에 우리가 컴퓨터를 학습시킬 수 있는 알고리즘을 컴퓨터에게 입력 시켜주면 컴퓨터가 스스로 데이터 안에 있는 유용한 패턴을 찾아서 유용한 함수를 찾는다. => 이 함수를 사용하면 되는것
딥러닝 : 일종의 머신러닝 기법. => 인간의 인지능력, 시각능력, 언어적인 능력에 관련되어 모델링을 하는데 굉장히 좋은 성능을 보이고 있음.
완벽한 머신러닝 기법은 없기때문에 다양한 알고리즘들을 배워야함.
CPU Computing
=> 기본적으로 우리가 쓰는 컴퓨팅 환경
=> 기본적인 연산과 계산을 해주는 장치
GPU Computing
=> pc 게임에서 사용하는 연산장치
=> 분산해서 빠르게 쉬운 계산들을 처리할 수 있다.
=> 요즘 빅데이터에 접목 시켜서 GPU를 활용한 대용량 데이터 처리가 굉장히 효율적으로 진행되고있다.
=> 딥러닝의 발전을 가속화 시키는데 굉장히 큰 역할을 했다.
=> 딥러닝에서의 성공을 보면서 기존 기본적인 머신러닝 알고리즘들도 GPU를 응용하기 시작
즉, 많은 양의 데이터를 처리하고 계산할 수 있게 되었다 => 이게 키포인트
머신러닝의 정의
컴퓨터 알고리즘에 대한 학습과정 => 자동으로 자기 스스로 어떤 경험들에 의해서 스스로를 발전시켜나갈 수 있는 그러한 일련의 컴퓨터 프로그램 체계를 학습하는 학문.
머신러닝의 구성요소
- Environment(E)
=> 머신러닝 알고리즘이 대응되는, 실제로 머신러닝 알고리즘이 적용되는 환경을 뜻함.
=> 우리가 학습을 한다 하면 경험(experience)가 필요한데 머신러닝에서의 경험은 Data를 뜻함. - Date(D)
- Model(M)(중요)
=> 함수
=> 이 함수에 데이터를 넣어서 함수를 학습시킨다.
=> 처음에는 함수를 대략적인 형태만 잡아주고 그 다음에 데이터를 넣어서 이 함수가 정말로 쓸모 있게끔 만들어준다. - Performance(P)
=> '좋은 함수로 만들었다' 를 알려면 이 함수를 '평가' 해주어야 함.
=> 우리가 공부를 잘하고 있는지 평가하기 위해 시험을 보는 것과 같다.
=> 즉, 최종적인 모형의 성능을 평가할 수 있는 그런 기준을 뜻함.
결국 모델(함수)를 잘 만들어야 하는데 함수의 output과 input 간에 상관관계를 잘 설명할 수 있는 그런 함수를 찾아야 한다. => input 과 output 을 이어주는 함수를 찾아야 한다.
=> 이러한 잘 만든 함수는 오차가 작은 것 !! (오차가 작아야 좋은 모델)
MSE(Mean Squared Error) : 가장 기본적인 오차의 개념 (수식을 만들어 기준을 잡은 것.) => 작을수록 좋은 모델
지도학습과 비지도학습 및 강화학습
머신러닝은 input과 output 간의 관계를 설명하는 방법론이 가장 대표적인 방법.
=> 이것을 크게 Supervised Learning(지도학습) 이라고 부른다.
=> 어떤 입력이 들어갔을 때 어떤 output이 나와야 된다는 걸 잘 지도를 해주는 것.
=> 정답을 알려주면서 학습을 하는 것.
Supervised Learning(지도학습)
=> 크게 Classification(분류) 과 Regression(회귀) 이 있다.
=> y의 최종적인 output이 어떠한 범주이다.
=> 강아지, 자동차, 고양이 같은 범주라면 Classification
=> 혈압의 정확한 수치, 몸무게 같이 수치와 같은 continuous(연속적인) 한 값이 라고 하면, Regression
Unsupervised Learning(비지도학습)
=> 인간도 그냥 어떤 사물들을 바라보고 어떠한 지도 없이 학습하는 것들이 있다.
Reinforcement Learning(강화학습)
=> 알파고가 강화학습을 이용해서 학습됨.
학습 오차를 줄이는 것과 예측 했을때 생기는 오차도 굉장히 중요한 이슈이다.
=> 머신러닝에서 모형을 잘 학습시키는 것도 중요한 이슈지만, 학습된 모형이 잘 예측 되게끔 만들어 주는 것도 굉장히 중요한 이슈이다.
=> 학습 오차를 줄이는 함수를 찾는 것 만으로도 만족스러운 상황이 있을 수 있지만(데이터의 패턴을 설명한다는 측면에서), 대부분의 케이스에서 우리는 내가 가지고 있지 않은 데이터를 가진 데이터 내에서 잘 예측하기를 원한다.
ex) 나이와 혈압 간 관계를 나타낸 데이터가 있다면 그 데이터에 없는 나이대의 사람들에 대해서도 잘 예측하기를 원한다.
=> 그것과 연관해서 error의 개념이 Training error 와 Validation error 로 쪼개진다.
Training error & Validation error
Training error(학습오차)
=> 내가 학습시키는 그 데이터 내에서 발생하는 오차
Validation error(검증오차)
=> 내가 학습할 때 사용하지 않았던 데이터에 대해서 검증한, 그 데이터를 이 모형에 넣으면 출력되는 y값이 있고,
=> 그 y가 실제 y, validation 데이터에 있는 실제 y랑 모형에서 출력된 y랑 정말 차이가 큰지 작은지 검증용으로 쓰는 error
=> 일반화 오류 라는 개념으로 연관이 되어진다.
=> 내가 학습한 모형이 정말 일반적으로 좋은가 ? 일반화가 잘 되는가에 대한 정보를 주는 것이다.
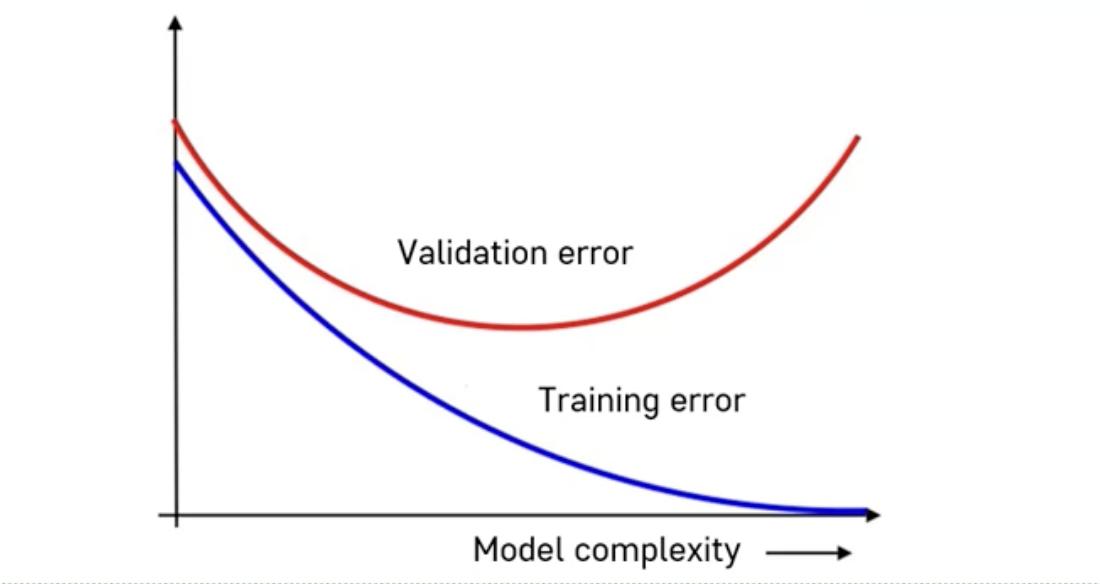
전체적으로 모형이 복잡해지면 Training error 는 쭉 줄어들지만, validation error(일반화 예측오차) 는 줄어들다가 다시 커지는 모습이 보인다.
여기서 모형이 너무 적합이 안되고, 너무 심플하다. 우리의 모형이 너무 단순해서 데이터에 들어있는 전체 패턴을 표현하지 못한다 => Under-fitting
너무 복잡해서 쓸데없는 패턴까지 다 학습을 해버렸다. 그러면 예측이 잘 안되게 되고 일반화가 잘 안된다.
내가 갖고 있는 트레이닝 데이터에만 너무 집중을 해서 그 패턴에만 몰두를 했기 때문에 일반적인 패턴에 가면 오히려 실패를 하게 된다 => Over-fitting
=> 그래서 우리는 validation error를 보면서 적합하게 가장 이 validation error가 최소가 되는 그런 적절한 모형을 찾아야 한다.
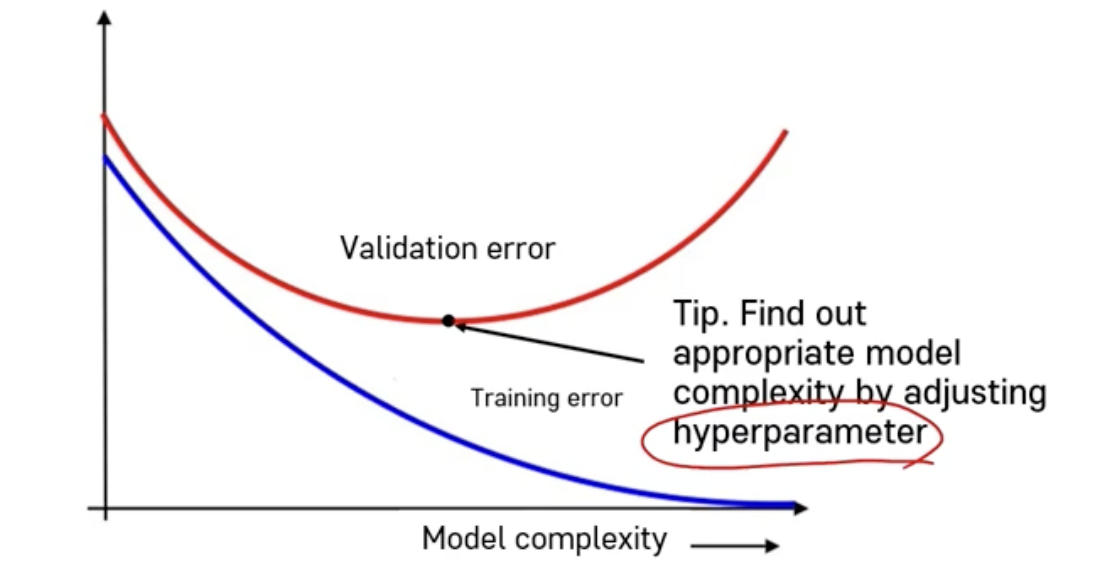
model complexity 를 결정하는데 hyperparameter 라는게 영향을 준다.
hyperparameter : 이 모형을 구축하는, 모형의 형태들이나 모형의 특성을 규정하는 모형의 외적인 요소 이고, 유저들이 직접 결정해 주어야 한다.
그래서 그런 hyperparameter 모형의 형태들을 조정해가면서 가장 좋은 것을 찾는 절차가 필요하다.
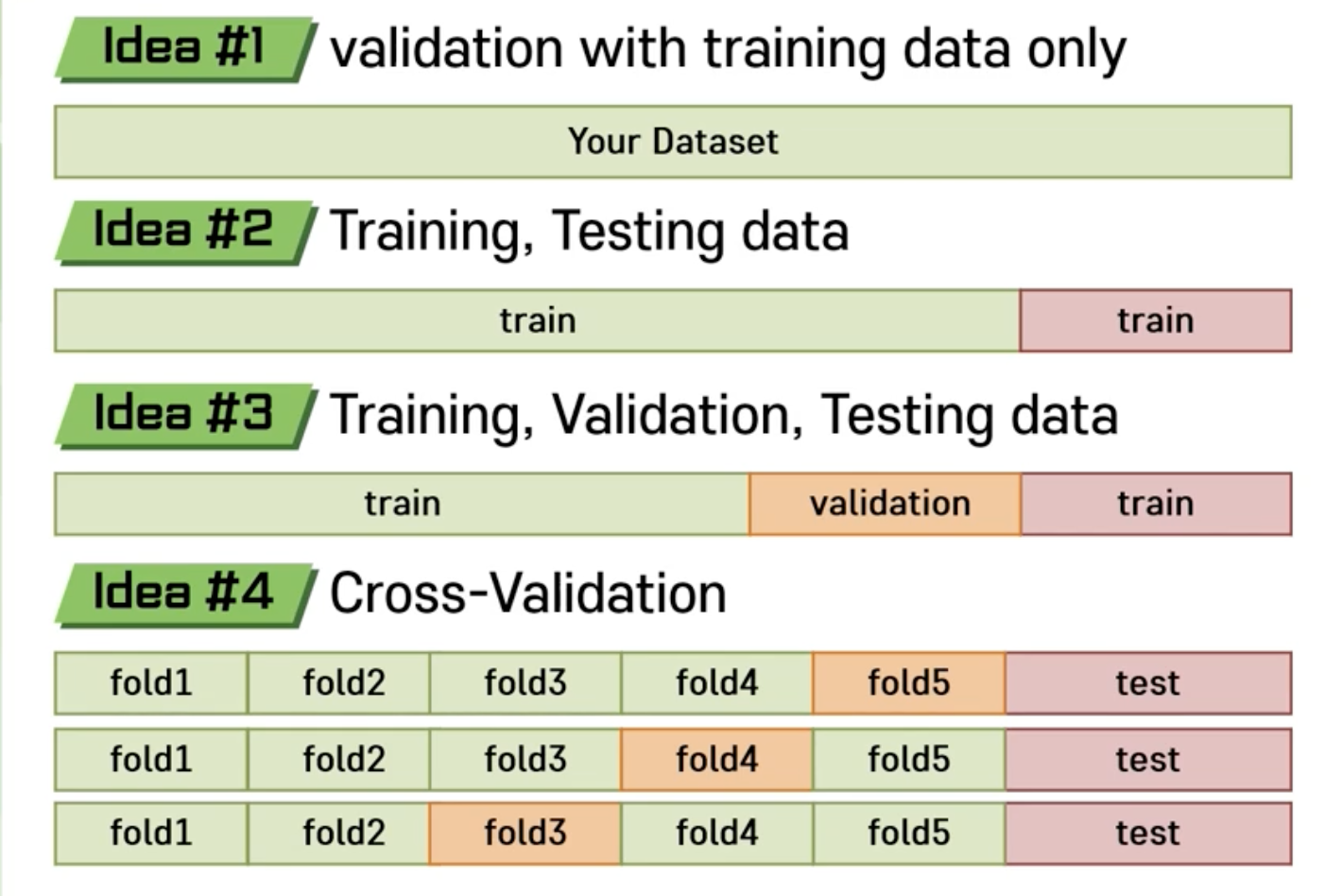
3번째 경우를 가장 추천.
