1. df.groupby()
- 데이터를 특정 기준에 따라 그룹화(Groupong)하고 이를 바탕으로 집계 (Aggregation)하는 과정
- 그룹화를 위한 기준과, 집계에 사용될 특정 연산이나 계산의 기준을 설정하는 것이 필요
- 절차
Splitting (분할)
Applying (적용)
Combining (결합)
df.groupby(by = 'col')['col_agg'].agg_fun().reset_index()
# 두 개 이상의 column으로 그룹화 하는 경우
# by= ['col1', 'col2']
# reset_index() : index로 설정된 'group'을 column으로 만들어줌2. Splitting (분할)
- 데이터를 일정한 기준에 따라 여러 그룹으로 나눈다
데이터를 미리 불러와본다
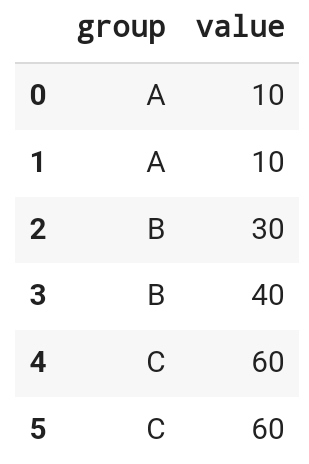
print('A:', df[df.group == 'A'])
print('B:', df[df.group == 'B'])
print('C:', df[df.group == 'C'])
3. Applying (적용)
- 각 그룹에 독립적으로 함수를 적용.
- pandas에서 sum, mean, max, min과 같은 집계 함수는 기본적으로 숫자 데이터에 적용 (sum, max 등은 적용되지만 사용하지 않음)
- 반면에 count와 nunique 함수는 모든 데이터 유형(숫자, 문자열 등)에 적용

4. Combining (결합)
- 결과를 하나의 데이터 구조로 결합함
# 위에서 집계한 값을 합산된 데이터프레임 형태로 출력
df.groupby(by = 'group')['value'].sum().reset_index()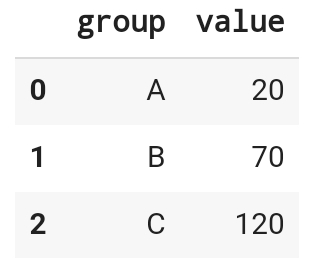
4.1 reset_index()
- index로 설정된 값을 column으로 만들어줌
df.groupby(by = 'group')['value'].sum()
# 그룹핑해주는 기준 컬럼(group)이 인덱스로 설정되어 있음
4.2 Aggregarion (집계)
- sum, mean, max, min : 이들 함수는 숫자형 데이터에 대해 작동함. 예를 들어, 문자열 데이터가 있는 열에 이 함수들을 적용하면 결과가 의미가 없거나 오류가 발생할 수 있음.
- 이외에도 std 등
df.groupby(by='group')['value'].mean().reset_index()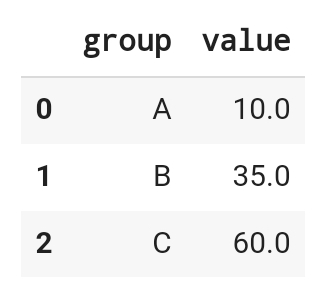
5. groupby.agg()
여러 집계 연산을 수행함
df.groupby(by= 'group').agg( col_name1 = ('col1', 'agg_func'), col_name2 = ('col2', 'agg_func') ).reset_index() # agg_func -> sum, mean, max, min ...
6. Exercise
- Titanic 데이터셋을 이용한 그룹화 및 집계
- 데이터를 'Pclass' (객실 등급)별로 그룹화하고, 각 그룹에 대해 다음과 같은 집계를 행하라.
- Survived 컬럼의 합계 (생존자 수)
- Fare 컬럼의 평균 (평균 요금)
- Embarked 컬럼의 고유한 값 (출발한 항구의 종류 수)
- 결과를 새로운 데이터프레임으로 저장하고, 그룹화했던 'Pclass' 컬럼을 다시 데이터프레임 컬럼으로 변환하라. (reset_index() 사용)
import seaborn as sns
df = sns.load_dataset('titanic')
df.head()df.groupby(by='pclass').agg(
survived_sum = ('survived', 'sum'),
fare_mean = ('fare', 'mean'),
embarked_nunique = ('embarked', 'nunique')
).reset_index()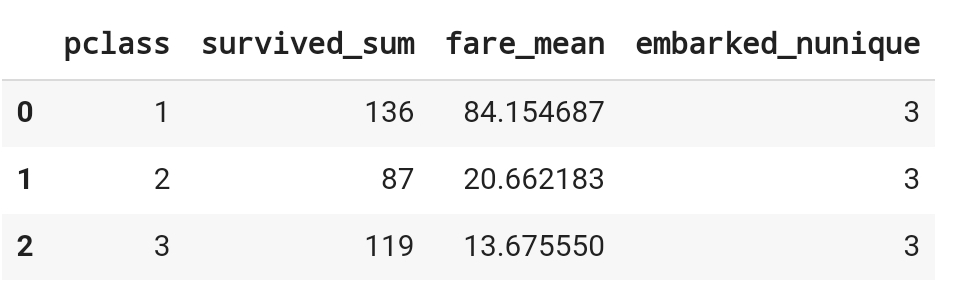

데이터 공부하는 예비 데이터 분석가, 김정민입니다.