데이터분석
1.데이터 분석과 라이브러리

전처리 데이터를 분석에 적합한 형태로 정리 -- 데이터셋 붙이기, 불러오기, 집계하기 등 시각화 그래픽으로 표현 -> 패턴이나 트렌드를 파악 -- 선그래프, 히스토그램 등 인사이트 도출 시각화된 데이터나 분석 결과를 통해 유용한 정보나 지식을 도출하는 단계 -- 의
2.pd.read_csv & Tabular

1. pd.read_csv() >csv 데이터 불러오기 어디서 가져오는 건지 파일 path도 가져와야 한다 2. Tabular Data와 Data type >행 (row) : 데이터 테이블에서 가로 방향의 데이터 집합. 하나의 행은 특정 레코드. 열 (column
3.DataFrame
1. Dictionary > 중괄호로 감싸고, key와 value를 : 로 묶어줌. value에 list가 들어가면 데이터 프레임으로 만들어 줄 수 있음 2. DataFrame > head() : 처음 5줄 보여줌 tail() : 마지막 5줄 보여줌 info()
4.Columns & Series
1. column 선택 >* 단일 column 선택 >*다중 column 선택 2. column 수정하기 >column 삭제 : drop() >column명 변경 : rename() 
인덱스(Index) : 행을 구별하는 데 사용되는 고유한 식별자특정 기준에 따라 순서대로 나열sort_values() : 특정 column 기준ascending =False : 내림차순ascending = True : 오름차순 sort_index() : index 기준
6.Filtering

1. Filtering >pd.DataFrame에서 Filtering은 조건에 부합 (Boolean값이 True)하는 row만 남기는 과정 2. between(), isin(), isna() >* fromn 이상, ton 이하 df['col'].between(fr
7.Dates & Times
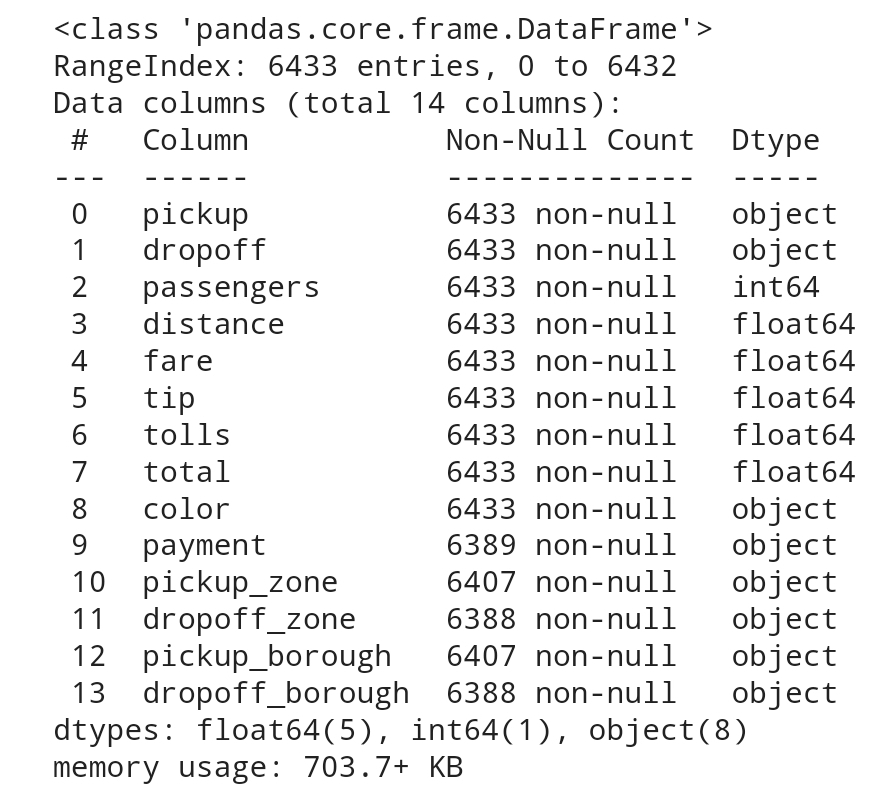
시간 관련 데이터를 Python의 datetime 객체로 변환다양한 형태의 날짜 및 시간 데이터를 처리할 수 있음날짜/시간 데이터를 주어진 주기('M', 'W', 'Y' 등)로 변환read_csv( , parse_dates = 'col1', 'col2', ...)파일을
8.Groupby
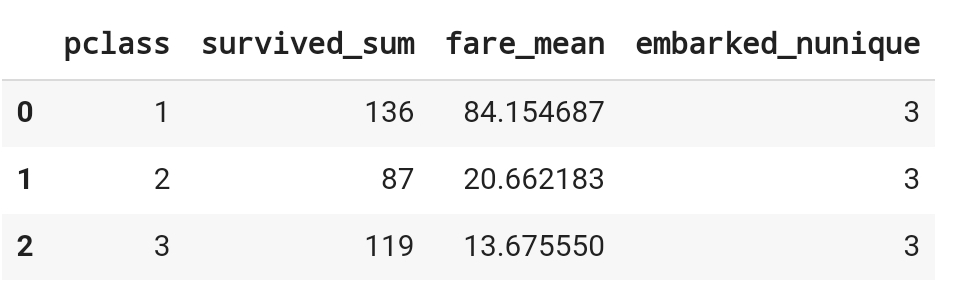
1. df.groupby() > * 데이터를 특정 기준에 따라 그룹화(Groupong)하고 이를 바탕으로 집계 (Aggregation)하는 과정 그룹화를 위한 기준과, 집계에 사용될 특정 연산이나 계산의 기준을 설정하는 것이 필요 절차 ** Splitting (분할)
9.combine
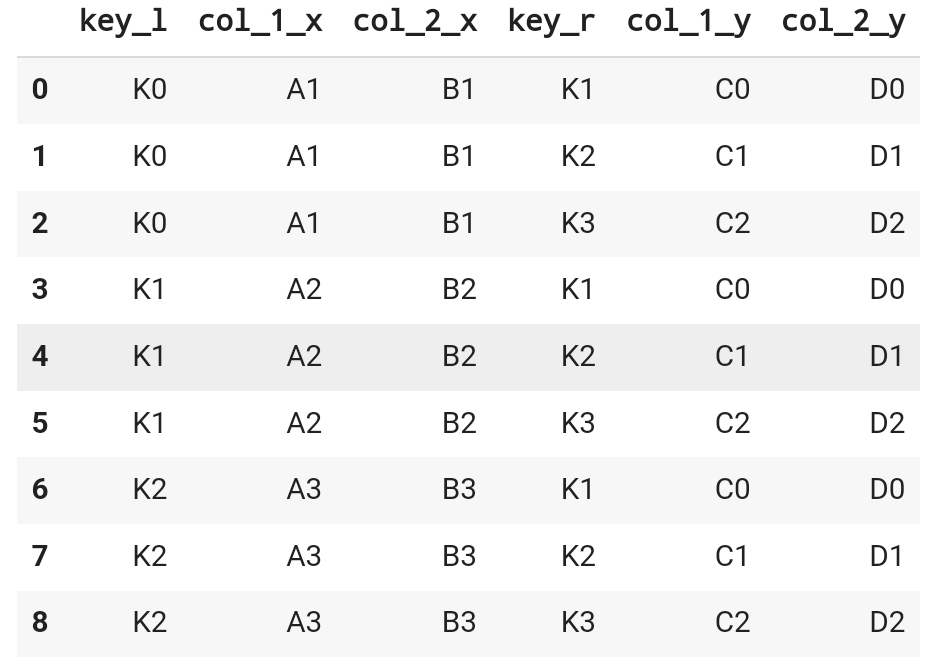
1. pd.concat() > concat 함수는 데이터프레임들을 세로 방향으로 결합함 2. pd.merge() - join > 두 개의 데이터프레임을 가로 방향으로 결합하는 데 사용되며, SQL의 JOIN 연산과 유사. 이 두 함수는 두 데이터프레임 간의 공통
10.pivot
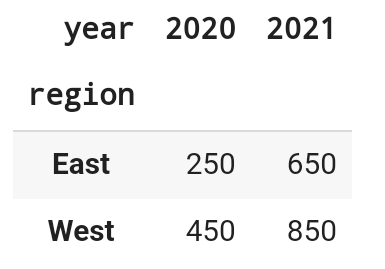
1. Long Form vs Wide Form > 가로로, 세로로 형태를 변환하는 걸 reshaping, pivoting이라고 한다. Long Form : ** 긴 형식은 데이터를 더 상세하게 나타냄 ** 유연하게 데이터를 조작하고, 다양한 형태의 분석에 적합 Wid
11.values & NA
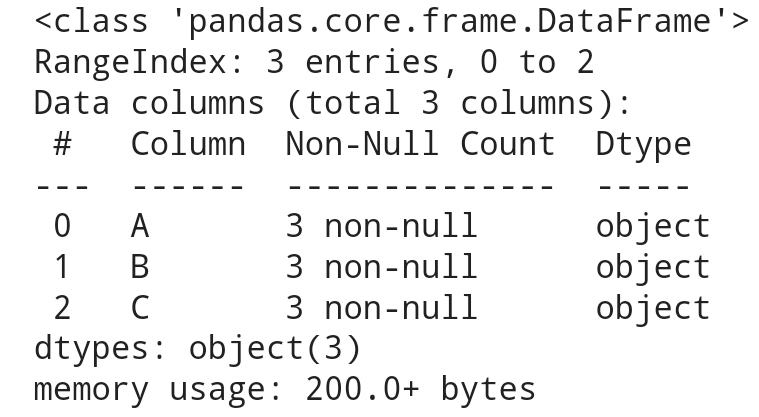
데이터 타입을 변경해주는 데 사용df.info()에서 보여주는 데이터 타입 별로 설명:object : 텍스트 또는 혼합된 데이터 타입. 주로 문자열 데이터에 사용됨int64 : 정수형 데이터float64 : 부동소수점 숫자bool : 부울 값(True 또는 False)