🍀 1. JOIN 연산자
GROUP BY 다음으로 중요한 구문.
여러 개의 테이블에서 동시에 데이터를 불러온다. 각각의 테이블에는 key들이 존재하고 (각각의 테이블의 관계를 만듦), 각각의 key들을 연결시키는 것이 JOIN.
- JOIN 연산자는 두 테이블 간의 관계를 나타내기 위해 사용
SELECT * FROM table A JOIN B ON 조건~
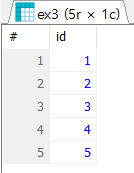
# 조인을 위한 테이블 ex3, ex4 생성
CREATE TABLE ex3(
`id` TINYINT,
`NAME` VARCHAR(10),
`age` TINYINT
)
;
INSERT INTO ex3
(`id`, `name`, `age`)
VALUES
(1,'이상훈',34),
(2,'박상훈',30),
(3,'최상훈',20)
;
CREATE TABLE ex4(
`id` TINYINT,
`region` VARCHAR(10)
)
;
INSERT INTO ex4
(`id`, `region`)
VALUES
(1,'서울'),
(4,'대구'),
(5,'부산')
;
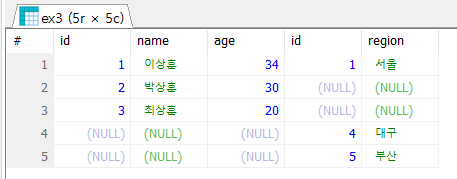
- 데이터를 보면 확실히 알 수 있는 것은 34살 이상훈은 서울에 살고있다.
- 박상훈과 최상훈은 어디에 사는지 모른다.
- 4번과 5번의 이름은 모르지만 각각 대구와 부산에 살고있다.
- 두 테이블의 관계를 연결해주는 컬럼은 Id, 이를 key라고 부름
🌱 inner join
#inner join
SELECT *
FROM ex3
JOIN ex4 ON ex3.id = ex4.id;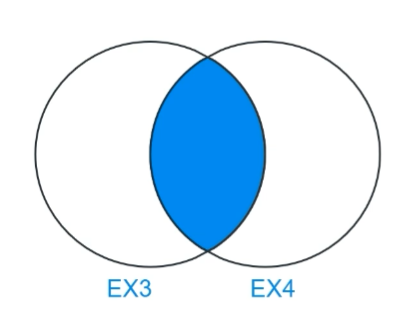
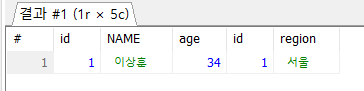
- 가장 많이 사용되는 join 방법 중에 하나.
- SELECT * : 모든 컬럼을 가져옴
- FROM ex3 : ex3든 ex4든 상관없음. 주로 주인공이라고 생각하면 편함
- JOIN ex4 : ex3테이블을 ex4 테이블과 조인한다
- ON ~ : 중요 조건! ex3의 id와 ex4의 id가 같은 경우만! 조인한다
🌱 Left join(1/2)
SELECT *
FROM ex3
LEFT JOIN ex4 ON ex3.id = ex4.id;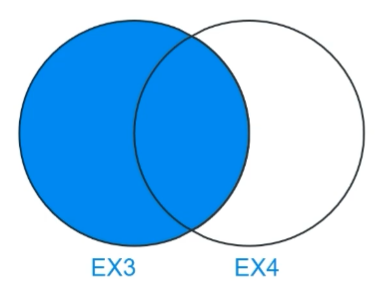
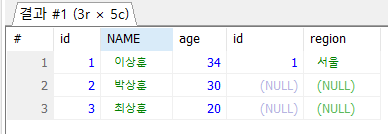
- 주인공(FROM)은 왼쪽에 있고, 오른쪽(LEFT)에 테이블을 가져다 붙인다 라고 생각하면 편함
- 4번과 5번은 데이터가 없기 때문에 NULL
- Left join : 그림 상태에서 왼쪽을 기준으로 오른쪽이 붙는다.
🌱 Left join(2/2)
SELECT *
FROM ex3
LEFT JOIN ex4 ON ex3.id = ex4.id
WHERE ex4.id IS NULL;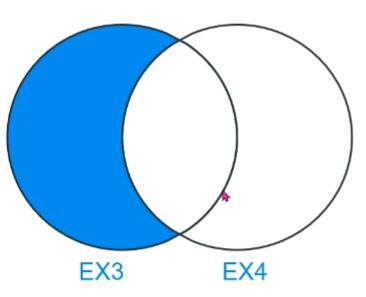
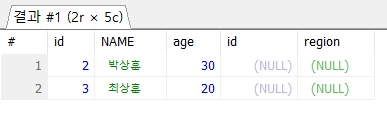
- 공통되지 않는 것만 남기는 것 (교집합을 뺌, id가 1인 것)
- ex4의 id가 NULL인 것만 남기자.
🌱 Right join
SELECT *
FROM ex3
RIGHT JOIN ex4 ON ex3.id = ex4.id;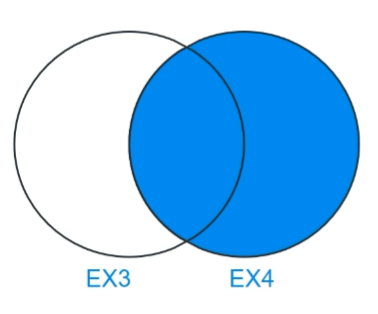
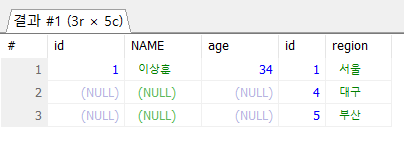
- FROM ex3 : 주인공 먼저 등장(그림에서 그려질 때)
- 그림을 기준으로 오른쪽을 기준으로 왼쪽이 붙는다.
- 잘 안씀. 순서만 바꾸면 left이므로 left를 잘씀
🍀 2. UNION
UNION은 두 테이블의 데이터를 세로로 쭉 나열하는 역할.
COLUMN의 수가 같아야 하며 중복은 제거함.SELECT id FROM ex3 UNION SELECT id FROM ex4;
- UNION ALL 은 중복을 그대로 표시
🌱 FULL OUTER JOIN
SELECT ex3.id, ex3.name, ex3.age, ex4.id, ex4.region
FROM ex3
LEFT JOIN ex4 ON ex3.id = ex4.id
UNION
SELECT ex3.id, ex3.name, ex3.age, ex4.id, ex4.region
FROM ex3
RIGHT JOIN ex4 ON ex3.id=ex4.id
WHERE ex3.id IS NULL;
- sql에서는 full outer join은 제공하지 않아서 쿼리를 만들어줘야 함.
- 컬럼의 숫자가 같아야 나열해줌
- 어디의 테이블에서 가져오는 컬럼인지 명시해줘야 함 ex3.id

데이터 공부하는 예비 데이터 분석가, 김정민입니다.