SQL
1.SQL : 데이터베이스/설치
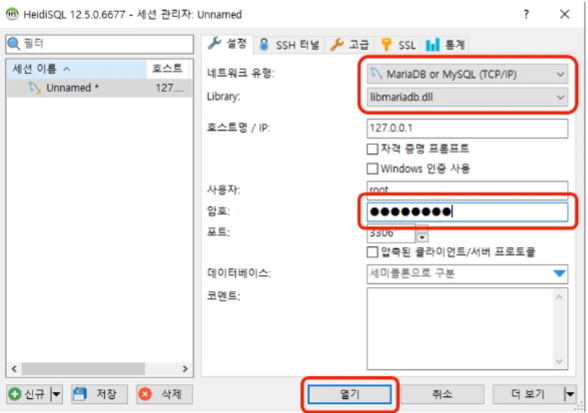
목차 데이터베이스와 RDBMS 그리고 SQL MYSQL& HEIDISQL 설치 Data Type (문자형, 숫자형, 날짜형 데이터베이스 Table (create, alter, drop, truncate, insert, update, csv file import to t
2.SQL : DataType, Database, UPDATE/ALTER

1. DataType 1.1 문자형 여기에서는 encoding type utf8을 사용할 예정 Encoding : 문자를 컴퓨터가 이해할 수 있는 신호로 만드는 것 Utf8에서 영어, 공백은 1byte, 한글은 한 글자당 3byte 1.2 숫자형 TINYINT
3.SQL : 데이터를 테이블에 넣는 방법/문제
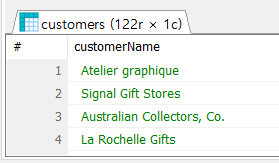
1. 데이터를 테이블에 넣는 방법 만들어진 테이블에서 데이터를 불러오는 작업은 후에 포스팅. 데이터를 집어넣는 방법은 크게 2가지 직접 엑셀 이용해서 데이터를 만들고 csv파일로 만드는 방법 다른 사람이 만든 데이터베이스 자체를 가지고 오는 방법 IMPORT CSV
4.SQL : WHERE구문, 비교연산자, 논리연산자,LIKE/BETWEEN/NOT BETWEEN
1. WHERE 구문 >목차 1.1 비교연산자 (, =) 1.2 논리연산자(AND, OR, NOT) 1.3 LIKE, BETWEEN, NOT BETWEEN 🍀 1.1 비교연산자 > SQL Code 이 문법 순서가 바뀌면 안된다.(select ,from, where
5.SQL : IN/NOT IN/IS NULL, ORDER BY

IN은 특정 값이 존재하는 데이터만 조회비교연산자, 논리연산자로 대체 가능WHERE orderdate ='2003-02-11' OR orderdate ='2003-02-17' 과 같은 결과IN 함수 중요하다. 나중에 자주 사용됨❔ 문제 1: customers 테이블에서
6.SQL : GROUP BY(이론, 실습)
1.1 GROUP BY 각각의 섹터별로 상장주식수의 합 GROUP BY 절은 한 개 이상의 컬럼을 기준으로 결과를 그룹화 주로 SUM(), AVG(), COUNT(), MAX(), MIN() 등의 집계 함수와 결합되어 사용함 Products 테이블에서 product
7.SQL : GROUP BY (실습2)
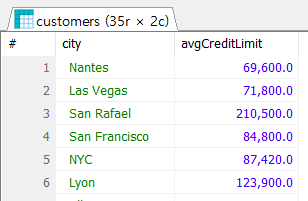
❔ 문제 1: customers 테이블에서 국가(country)가 'USA', 'Canada', 'France'인 도시(city)별로 평균 크레딧 한도(creditlimit)을 계산하라.WHERE country IN ('USA' , 'Canada', 'France')W
8.SQL : GROUP BY(HAVING), IF/CASE
목차 GROUP BY구문(SQL에서 가장 중요) HAVING IF/CASE JOIN 1. HAVING > HAVING절은 SQL의 GROUP BY절과 함께 사용되며 그룹화된 결과에 조건을 적용하는 데 사용함. WHERE절과 차이점 WHERE절은 개별 테이블에 대
9.SQL : JOIN(INNER,LEFT,RIGHT,UNION)

GROUP BY 다음으로 중요한 구문.여러 개의 테이블에서 동시에 데이터를 불러온다. 각각의 테이블에는 key들이 존재하고 (각각의 테이블의 관계를 만듦), 각각의 key들을 연결시키는 것이 JOIN.JOIN 연산자는 두 테이블 간의 관계를 나타내기 위해 사용데이터를
10.SQL : JOIN 실습
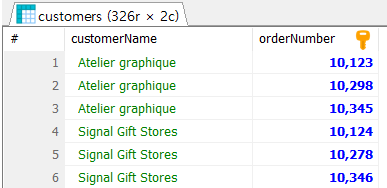
JOIN 실습(1) ❔ 문제 1: 'customers' 테이블과 orders 테이블을 사용하여, 모든 고객의 이름과 주문 번호를 조회하라. customerNumber : 두 테이블을 연결하는 key 고객의 이름과 주문번호를 합침, customerNumber가 같을
11.SQL : Window 함수, LEAD/LAG 함수
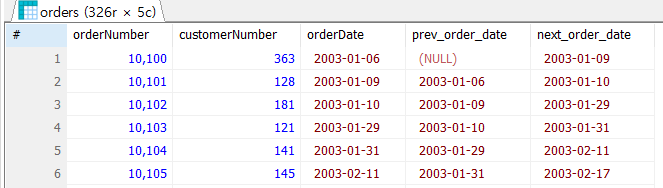
1. Window 함수 > 특정 구간, 기간이라고 생각하면 됨. 데이터를 조회할 때 통계적인 개념이 들어간다. SELECT 구문에서 사용되며 분석 구간을 변동시키는 역할. EX)누적합 SUM(COLUMN1) OVER(PARTITION BY COLUMN2 ORDER B
12.SQL : 순위함수/Window Frame

ROW_NUMBER : 중복 없이 고유한 순위 부여(많이 사용)RANK : 중복값에 같은 순위 부여, 중복된 숫자만큼 건너뜀 (1,1,1,4,5,6)DENSE_RANK : RANK와 유사하지만 중복된 숫자를 건너뛰지 않음(1,1,1,2,3,4)row_number : 중
13.SQL : 실습(GROUP BY)
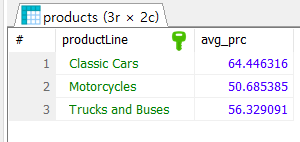
실습 ❔ 문제 1: employees 테이블과 customers 테이블을 JOIN하여 각 직원별로 담당하는 고객 수가 5명 이상인 직원들의 이름과 담당 고객 수를 조회하라. ❔ 문제 2: products 테이블에서 각 제품 라인별로 제품 가격의 평균을 계산하라. 그
14.SQL : 서브쿼리(Sub-query), 상관 서브쿼리
1. 서브쿼리 (Select절, from절, where절) > 특정 경우에 가장의 테이블을 만들어서, 실제에 있는 테이블과 JOIN을 한다던지. 가상의 테이블을 만들어서 조회를 한 것을 가지고 다른 통계적인 것을 만든다던지. 실제 가지고 있는 테이블에서 한 번 조회한
15.SQL : CTE(Common Table Expression)/WITH구문
WITH문 (Common Table Expression, CTE)과 서브쿼리는 둘 다 SQL 쿼리의 구조를 단순화하고 복잡한 쿼리를 분해하는 데 유용.CTE (WITH문) : CTE는 쿼리의 시작 부분에 정의되며, 이름을 가진 임시 결과 집합을 생성 -> 코드의 가독성
16.SQL : CTE(Common Table Expression) 실습

실습 ❔ 문제 1: products 테이블에서 각 제품 라인별로 평균 제품 가격을 계산하라. 그리고 이 평균 가격보다 높은 가격을 가진 제품들만을 해당 제품 라인별로 조회하라. (55row) ❔ 문제 2: 각 제품 라인별로 제품의 평균 가격과 전체 제품의 평균 가격