🍀 1. 순위함수
ROW_NUMBER : 중복 없이 고유한 순위 부여(많이 사용)
RANK : 중복값에 같은 순위 부여, 중복된 숫자만큼 건너뜀 (1,1,1,4,5,6)
DENSE_RANK : RANK와 유사하지만 중복된 숫자를 건너뛰지 않음(1,1,1,2,3,4)
SELECT customername, creditLimit,
ROW_NUMBER() OVER (ORDER BY creditLimit DESC) AS row_number_,
RANK() OVER (ORDER BY creditLimit DESC) AS rank_,
DENSE_RANK() OVER (ORDER BY creditLimit DESC) AS dense_rank_
FROM customers
ORDER BY creditlimit DESC;
- row_number : 중복없이 순위 부여
- rank : 중복값에 같은 순위 20위 부여하고, 중복된 숫자만큼 건너뛴 다음 22위 부여
- dense_rank : 중복값에 같은 순위 20위 부여하고, 건너뛰지 않고 21위 부여
First_value() : 가장 첫번째 오는 row 조회
Last_value() : 가장 마지막에 오는 row 조회
위 두 함수는 order by의 활용에 따라 결과가 달라짐 (주의!)
Ex) first_value(column) over (partition by ~ order by ~)
실습
❔ 문제 1 : products 테이블에서 각 제품 라인별로 가장 비싼 제품의 이름과 가장 싼 제품의 이름을 조회하라.
SELECT productLine, productname, buyprice,
FIRST_VALUE(productname) OVER (PARTITION BY productLine ORDER BY buyprice ASC ) AS cheapest_product,
FIRST_VALUE(productname) OVER (PARTITION BY productLine ORDER BY buyprice DESC ) AS expensive_product
FROM products;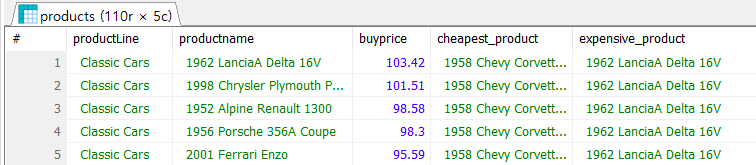
🍀 2. WINDOW FRAME(윈도우 프레임)
ROW : 행의 개수로 윈도우 프레임을 정의
RANGE : 정렬의 기준이 되는 행의 값을 기준으로 정의
PRECEDING : 현재 행보다 전에 있는 행들을 의미
FOLLOWING : 현재 행보다 다음(아래)에 있는 행들을 의미
UNBOUNDED PRECEDING : 현재 파티션의 첫번째 행부터 현재 행까지의 범위를 의미
UNBOUNDED FOLLOWING : 현재 행부터 현재 파티션의 마지막 행까지의 범위를 의미
CURRENT ROW : 현재 행
ex)올해 초부터 지금까지 실적이 얼마냐?
SELECT orderNumber, productCode, quantityOrdered,
AVG(quantityOrdered) OVER (ORDER BY orderNumber ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg_quantity_1,
AVG(quantityOrdered) OVER (ORDER BY orderNumber ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS moving_avg_quantity_2,
AVG(quantityOrdered) OVER (ORDER BY orderNumber ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS moving_avg_quantity_3,
AVG(quantityOrdered) OVER (ORDER BY orderNumber RANGE BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg_quantity_4
FROM orderdetails
;
- 첫번째 : orderNumber를 줄을 세워서 quantityOrdered의 평균을 구할거다. 현재 기준으로 하나 위의 것과 현재 기준으로 하나 아래 것까지 포함시켜서. (즉, 3개의 평균)
- 두번째: 현재 기준으로 다음 것의 평균을 구할 것이다.
- 세번째 : 현재 기준으로 위의 것, 현재 것. 두 개의 평균을 구할 것이다.
- 네번째 : range (구간내), 그 구간은 orderNumber로 나눔(10,100이 하나의 구간). 1 PRECEDING의 평균은 x, 다음 구간의 평균 36.625

데이터 공부하는 예비 데이터 분석가, 김정민입니다.