
Python 기본 개념 복습
기본 데이터 타입
- 정수형 (Integer, int)
정수 값을 저장
예: 5, -10, 0 - 실수형 (Float, float)
소수점이 있는 실수
예: 3.14, -0.001, 2.0 - 불리언 (Boolean, bool)
참(True) 또는 거짓(False)만 저장
주로 조건 판단에 사용됨 - 문자열 (String, str)
문자들의 집합
예: "Hello", 'Python', "123"
컬렉션 데이터 타입
- 리스트 (List, list)
여러 값을 순서대로 저장하는 자료형 (mutable: 값 변경 가능)
예: [1, 2, 3], ["a", "b", "c"] - 튜플 (Tuple, tuple)
리스트와 비슷하지만 값을 변경할 수 없음 (immutable)
예: (1, 2), ("a", "b") - 딕셔너리 (Dictionary, dict)
키-값 쌍을 저장
예: {"name": "John", "age": 30} - 셋 (Set, set)
중복 없는 값들의 집합
예: {1, 2, 3}, { "apple", "banana" }
참고: 왜 데이터 타입이 중요할까?
- 올바른 연산 수행: 예를 들어 문자열끼리만 연결(+)이 가능하고, 숫자끼리만 덧셈이 가능합니다.
- 에러 방지: 잘못된 타입을 다루면 오류가 발생합니다.
- 성능 최적화: 적절한 타입 선택은 메모리 사용과 처리 속도에 영향을 줍니다.
NumPy Array란?
numpy.ndarray 클래스의 인스턴스
동일한 데이터 타입의 값들을 다차원 배열로 저장
일반 Python 리스트보다 빠르고 메모리 효율적
예: arr = np.array([1, 2, 3]) # 1차원 배열
주요 특징
- 고정 타입 : 모든 요소가 같은 데이터 타입
- 다차원 지원 : 1D, 2D, 3D 이상 배열 지원
- 빠른 연산 : 내부적으로 C로 구현되어 연산 속도가 빠름
- 브로드캐스팅 : 배열 간 연산 시 크기를 자동 조정해 연산 수행
- 다양한 기능 : 선형대수, 통계, 푸리에 변환 등 강력한 수치 함수 제공
배열 생성 예시
# 1차원 배열
a = np.array([1, 2, 3])
# 2차원 배열
b = np.array([[1, 2], [3, 4]])
# 0으로 채운 배열
zeros = np.zeros((3, 3))
# 1로 채운 배열
ones = np.ones((2, 2))
# 0~9까지 숫자 생성
arange = np.arange(10)
# 랜덤 배열 생성
rand = np.random.rand(2, 3)연산 예시
x = np.array([1, 2, 3])
y = np.array([10, 20, 30])
x + y # 요소별 덧셈: array([11, 22, 33])
x * 2 # 각 요소에 2배: array([2, 4, 6])
x.mean() # 평균: 2.0
NumPy Array vs Python List
| 항목 | NumPy Array | Python List |
|---|---|---|
| 속도 | 빠름 (C 기반 벡터 연산) | 느림 (파이썬 루프 기반) |
| 메모리 사용 | 적음 (고정 타입) | 큼 (유연한 타입) |
| 데이터 타입 | 모든 요소가 동일한 타입 | 요소마다 타입 다를 수 있음 |
| 차원 지원 | 다차원 (1D~nD 가능) | 기본적으로 1차원 |
| 연산 처리 | 벡터화 연산 가능 (빠름) | 반복문 필요 (느림) |
| 과학 계산용 | 매우 적합 (선형대수, 통계 등) | 부적합 (복잡한 수치 계산 어려움) |
01. Constants
Tensor
- Deeplearning framework는 기본적으로 Tensor를 다루는 도구다.
-
Tensor를 다룰 때 가장 중요한 것!
SHAPE !!!
(해보면 알겠지만, 제일 에러 많이 나는 이유, 제일 헷갈리는 것, 개발할 때 우리가 이론을 알아야 하는 이유, 함수들의 설정값을 확인해야하는 이유)
Tensor 생성
우리가 생성하는 것은 tf.Tensor 데이터!
항상 체크 해야 할 것 !
- shape
- dtype (데이터 타입이 같아야 연산이 가능합니다.)
Constant (상수)
-
tf.constant()- list -> Tensor
- tuple -> Tensor
- Array -> Tensor
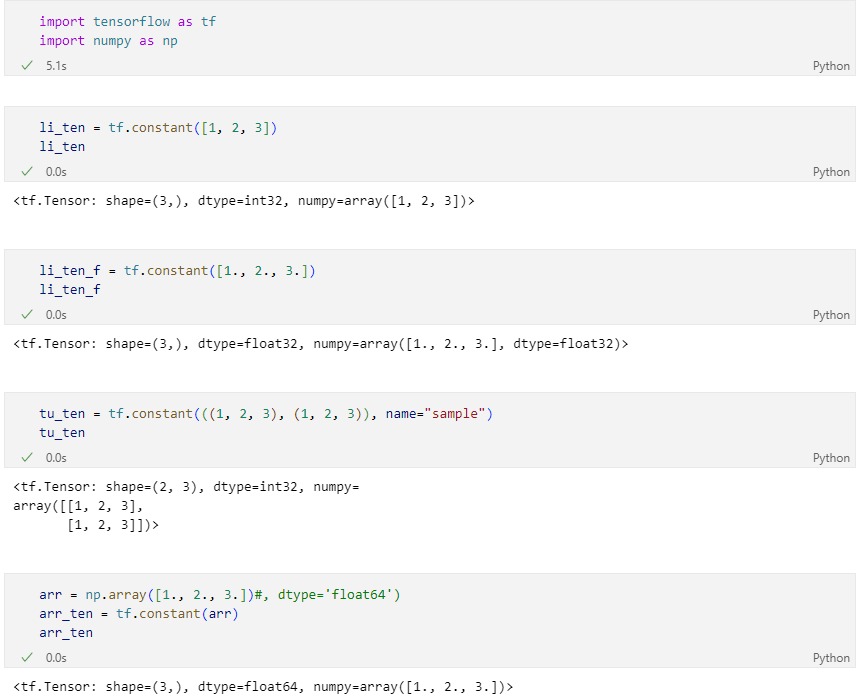
참고
- double precision : 64bits
- single precision : 32bits
- half precision : 16bits
Numpy array 추출
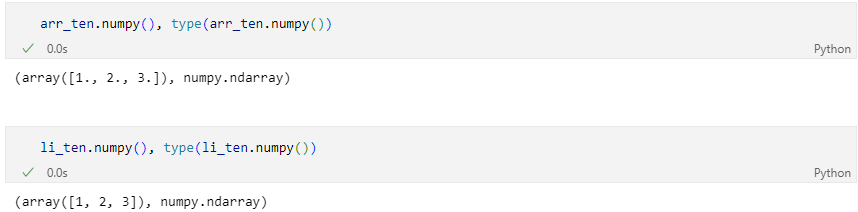
해당 과정에서 발생 가능한 에러
[Quiz] 에러가 발생하는 원인을 파악하고 수정하시오
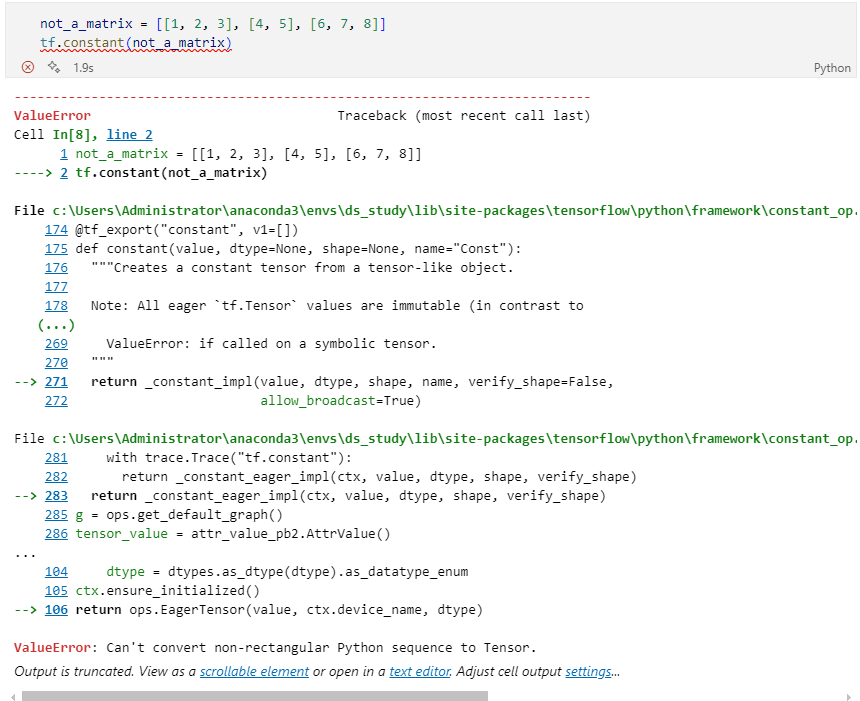
예제 1
-
ValueError: Can't convert non-rectangular Python sequence to Tensor.
-
error 발생 원인
shape에 이상이 있어 Tensor를 생성하지 못함.
차원(Dimension)과 요소(Elements)가 shape을 결정하는데
차원은 데이터가 "축(axis)"이 몇 개인지를 의미하고 요소는 텐서 안에 있는 데이터의 개수를 말하는데 이 요소의 개수는 일정해야 한다.
해당 데이터는 3개의 차원을 가지고 있지만 요소의 수가 일정하지 않아 생긴 에러이기 때문에 요소의 개수를 맞춰주면 해결된다. -
수정 코드

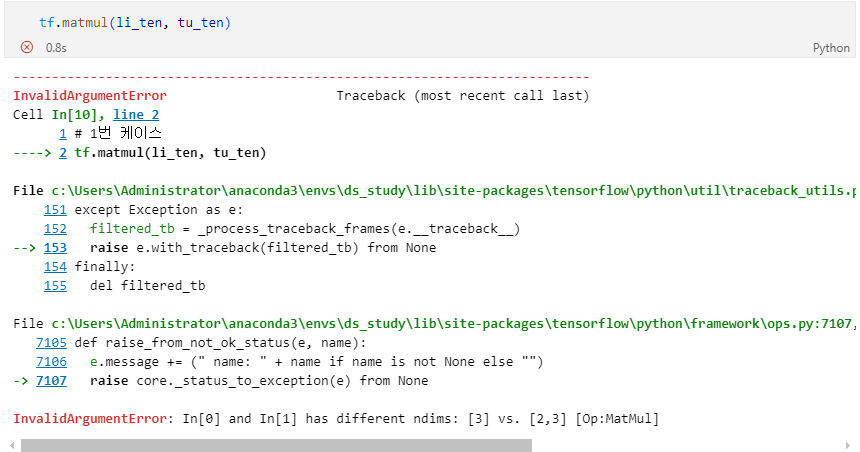
예제 2
-
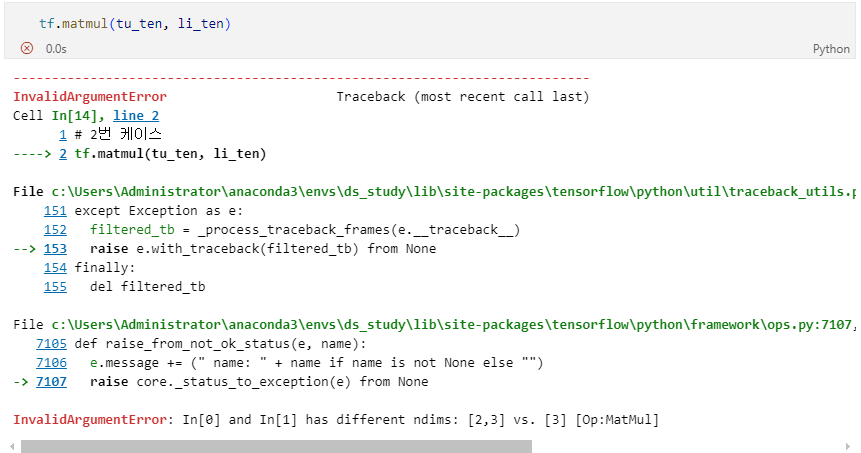
InvalidArgumentError: In[0] and In[1] has different ndims: [3] vs. [2,3][Op:MatMul]
-
error 발생 원인

tf.matmul(A, B)를 사용하기 위해서는 앞의 열 수와 뒤의 행 수가 일치해야한다는 조건이 있다.
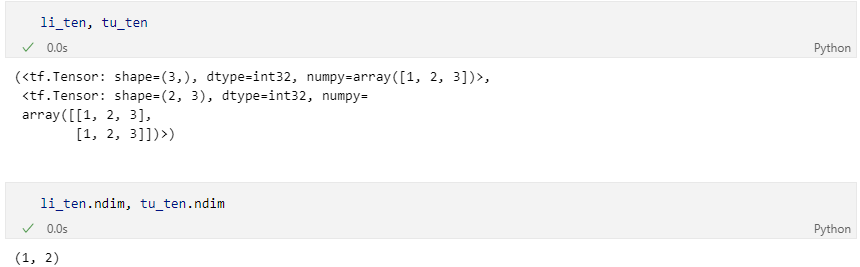
li_ten의 shape은 (3,)이고 tu_ten의 shape은 (2, 3)으로 조건에 부합하지 않아 발생한 에러이기 때문에 조건에 맞게 수정해주면 해결된다.
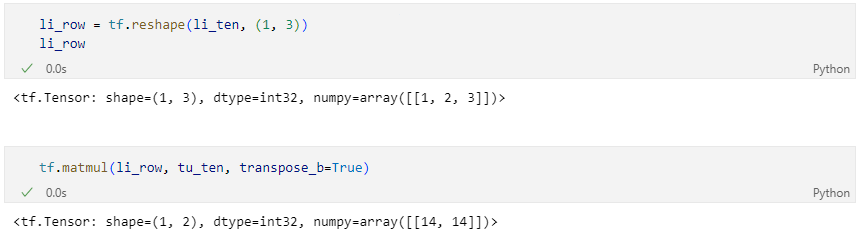
[방법_1] - li_ten을 (1, 3)으로 reshape하고 tu_ten을 전치(transpose)하는 방법
(전치는 tf.transpose(tu_ten) 또는 transpose_b=True 옵션을 추가)
[방법_2] - li_ten을 여러 행으로 복제해서 (2, 3) 같은 shape으로 만든 뒤 tf.matmul을 하거나 브로드캐스팅을 활용하는 방법 -
수정 코드
예제 3
-
InvalidArgumentError: In[0] and In[1] has different ndims: [2,3] vs. [3][Op:MatMul]
-
error 발생 원인
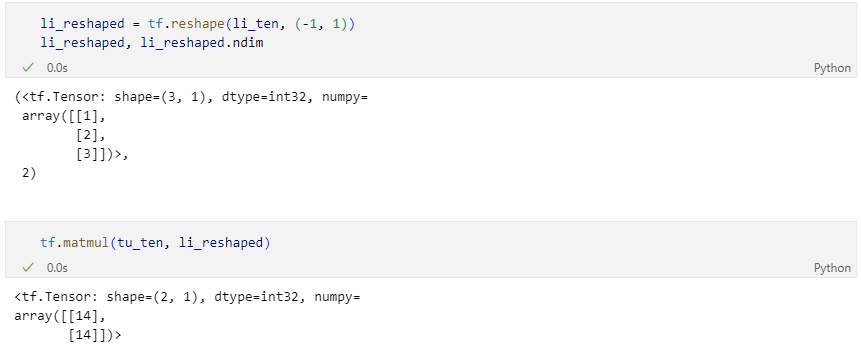
두 텐서의 차원 수(rank, ndims) 불일치로 발생하는 에러이기 때문에 차원수만 맞춰주면 해결된다.
-
수정 코드
예제 4
-
InvalidArgumentError: cannot compute Mul as input #1(zero-based) was expected to be a double tensor but is a int32 tensor [Op:Mul]
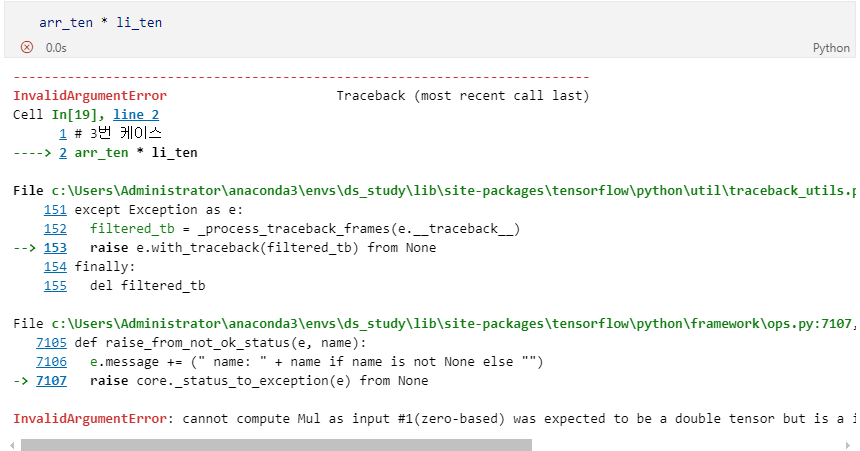
-
error 발생 원인

Data Type의 불일치로 발생한 에러이다.
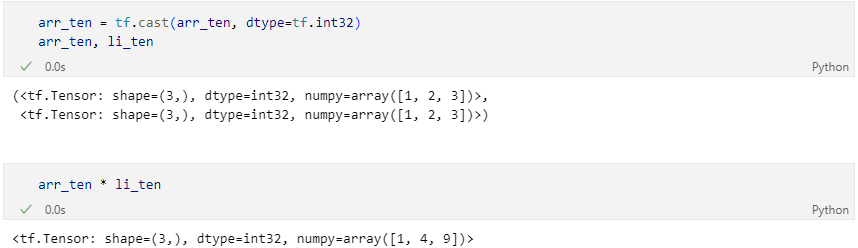
에러를 막기 위해 데이터 생성시에 미리 지정하거나 tf.cast()로 수정 가능하다.
(ex) tensor = tf.constant([1, 2, 3], dtype=tf.float32)
tf.cast(tensor, dtype=tf.int16) -
수정 코드
특정 값의 Tensor 생성
tf.onestf.zerostf.range

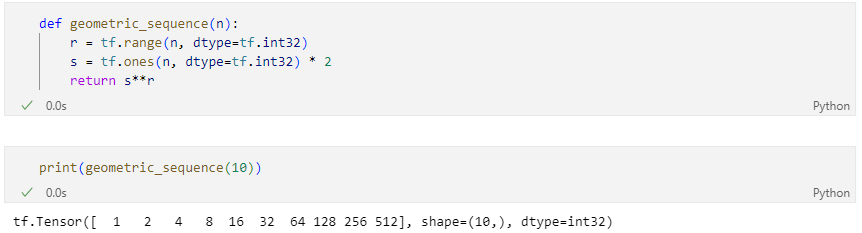
[Quiz] n 을 입력하면 첫항이 1이고 공비가 2인 등비수열을 생성하는 함수를 만드시오
(이 때 결과값은 tf.Tensor 데이터이고, 데이터 타입은 tf.int32)
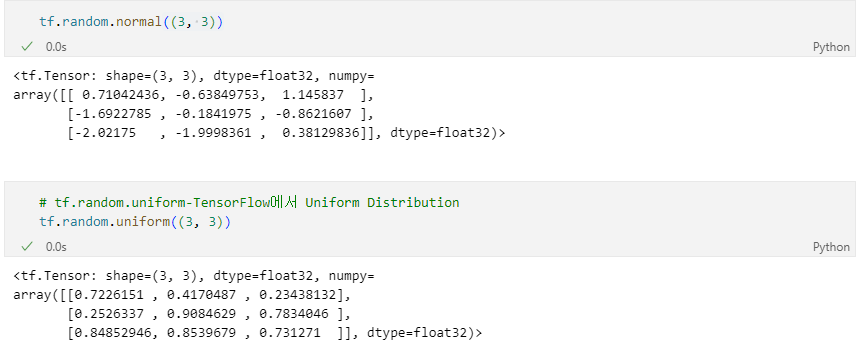
Random Value(난수)
- 무작위 값을 생성할 때 필요.
- Noise를 재현 한다거나, test를 한다거나 할 때 많이 사용됨
- 데이터 타입은 상수형태로 반환됨
tf.random 에 구현 되어 있음.
tf.random.normal- Gaussian Normal Distribution
tf.random.uniform- Uniform Distribution
- 참고
Random seed 관리
Random Seed란?
- Seed는 "씨앗"이라는 의미로, 난수를 생성하는 알고리즘의 시작점을 지정하는 값입니다.
- 이 값이 같으면, 난수 생성기는 항상 같은 순서대로 난수를 생성하게 됩니다.
즉, 같은 seed 값을 사용하면 매번 동일한 난수를 생성할 수 있습니다.
일반적으로 사용되는 시나리오
- 모델 초기화: 딥러닝 모델의 가중치 초기화가 랜덤으로 이루어지기 때문에, 동일한 초기화에서 반복 실험이 필요할 때 사용합니다.
- 데이터 셔플링: 훈련 데이터를 무작위로 섞는 과정에서 동일한 셔플링을 반복할 수 있도록 시드를 설정합니다.
- 교차 검증: 동일한 랜덤 시드로 데이터를 나누어 반복실험할 수 있습니다.

02. Variable
Variable (변수)
-
미지수, 가중치를 정의할 때 사용
-
직접 사용할 일이 많지는 않음
-
변수 정의는 변수 생성 + 초기화
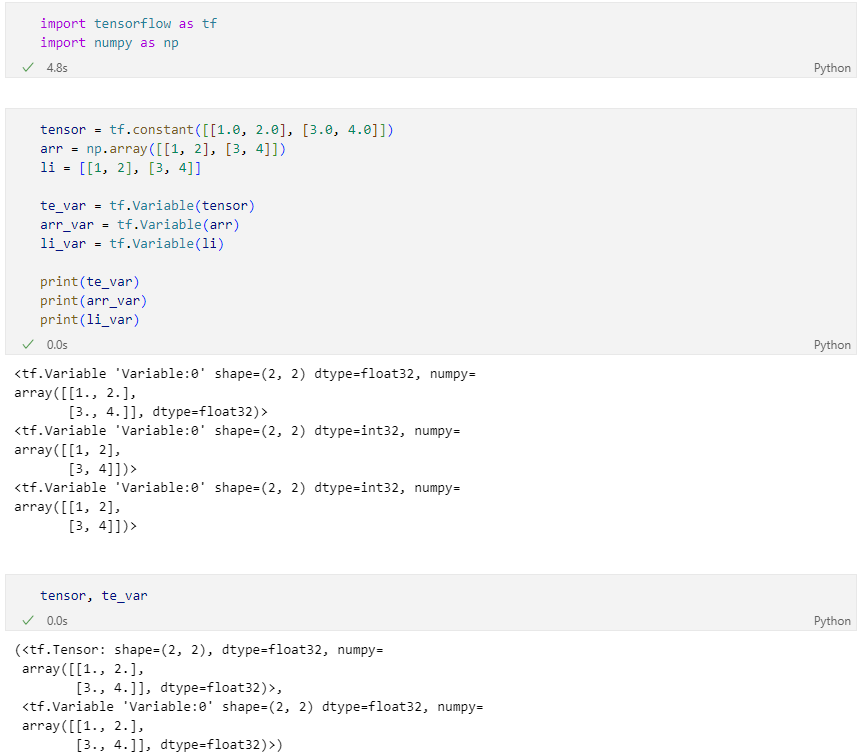
Constant와 같이 기본 속성값이 들어있음.

변수는 기존 텐서의 메모리를 재사용하여 텐서를 재할당 할 수 있다.
(기존 메모리의 크기와 다르면 할당 할 수 없음)

03. Tensor 연산
기본 연산 기능
아래의 기본 연산은 특수 메서드를 이용하여 연산자 오버로딩이 되어 있으므로 그냥 연산자 기호를 사용하는게 가능!
tf.add: 덧셈tf.subtract: 뺄셈tf.multiply: 곱셈tf.divide: 나눗셈tf.pow: n-제곱tf.negative: 음수 부호
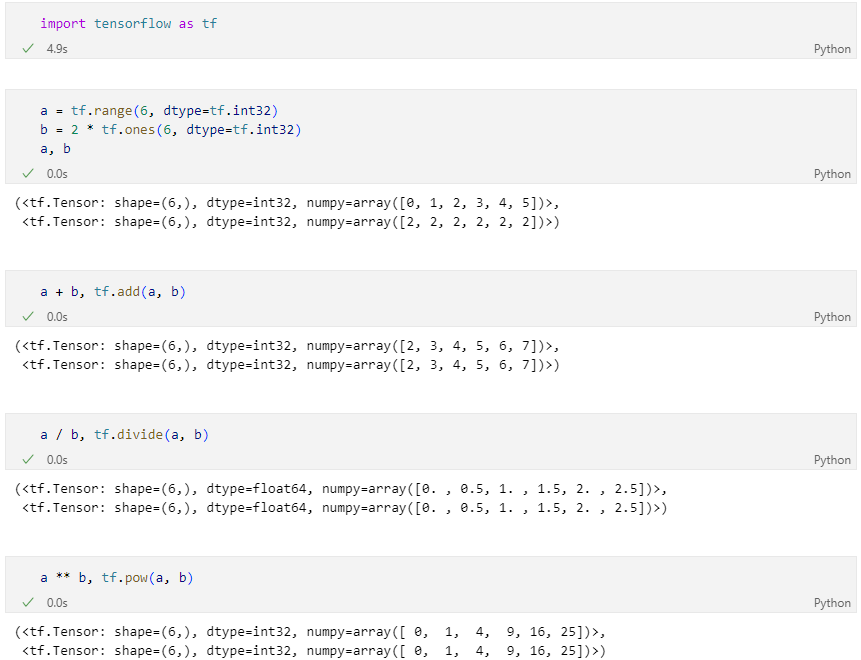
여러가지 연산
tf.abs: 절대값tf.sign: 부호tf.round: 반올림tf.ceil: 올림tf.floor: 내림tf.square: 제곱tf.sqrt: 제곱근tf.maximum: 두 텐서의 각 원소에서 최댓값만 반환.tf.minimum: 두 텐서의 각 원소에서 최솟값만 반환.tf.cumsum: 누적합tf.cumprod: 누적곱

Axis 이해하기
- 2 차원
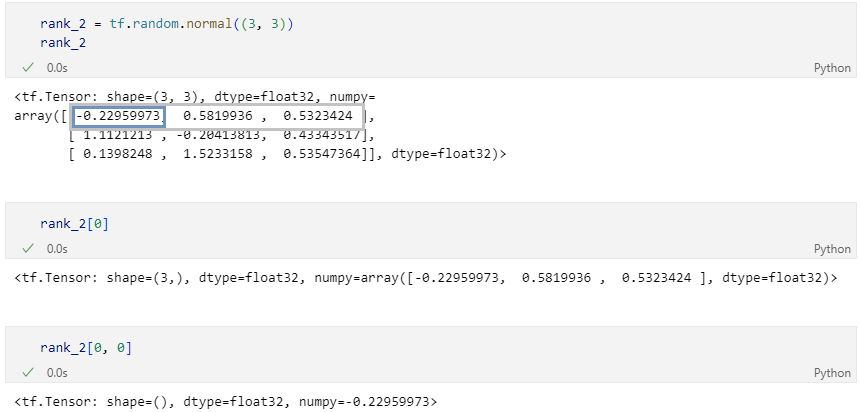
- 3 차원
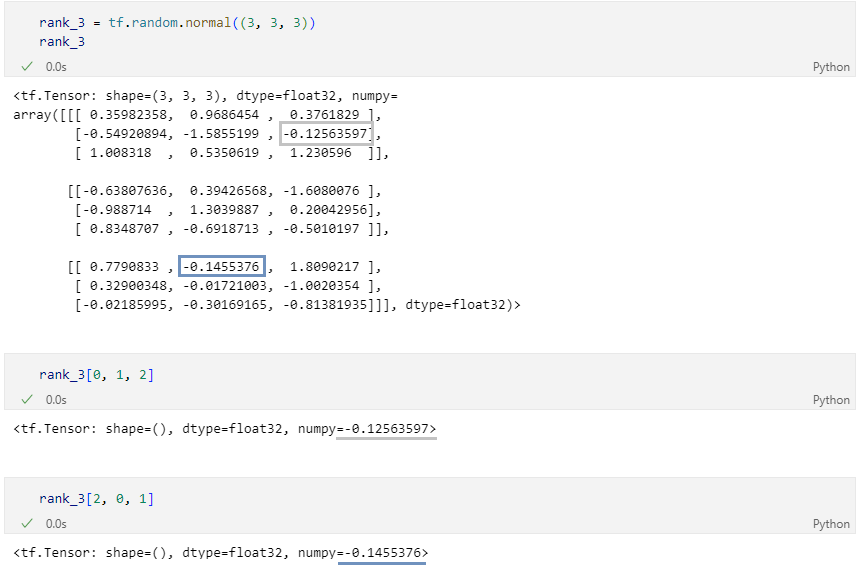
- 4 차원
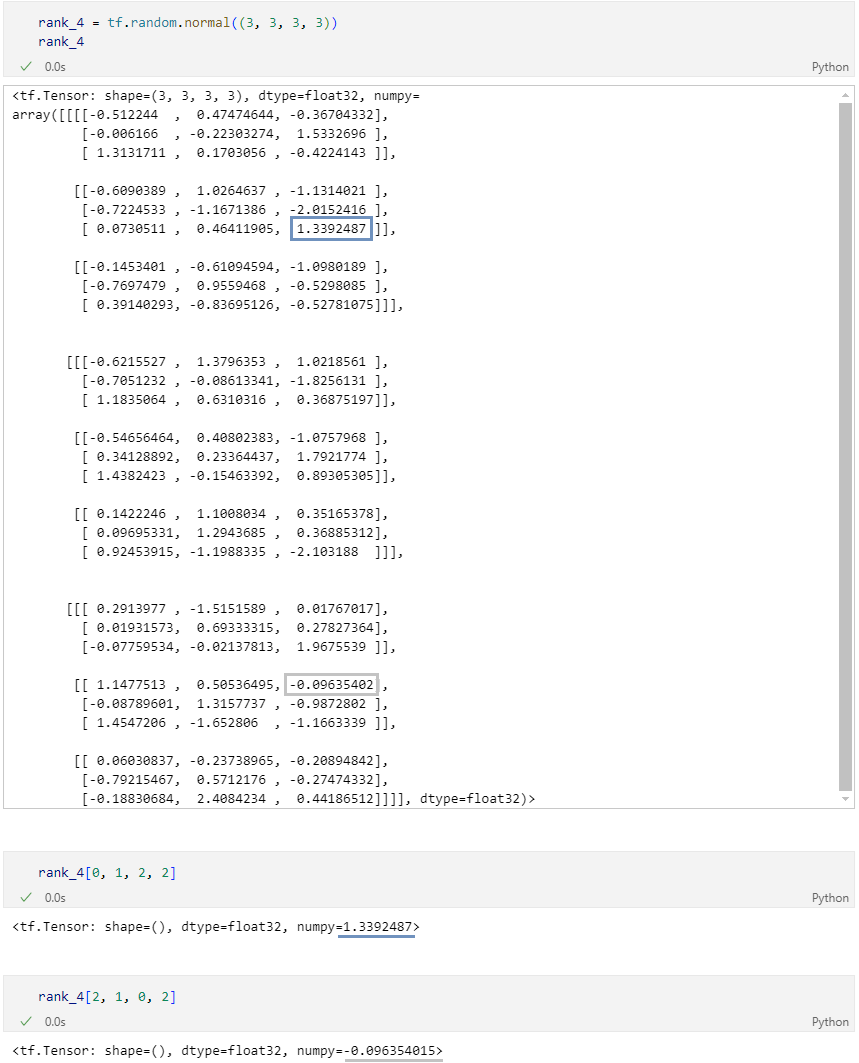
차원 축소 연산
tf.reduce_mean: 설정한 축의 평균을 구한다.tf.reduce_max: 설정한 축의 최댓값을 구한다.tf.reduce_min: 설정한 축의 최솟값을 구한다.tf.reduce_prod: 설정한 축의 요소를 모두 곱한 값을 구한다.tf.reduce_sum: 설정한 축의 요소를 모두 더한 값을 구한다.

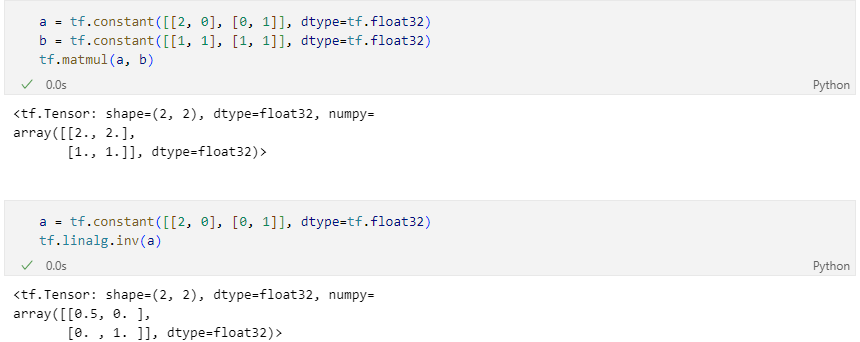
행렬과 관련된 연산
tf.matmul: 내적tf.linalg.inv: 역행렬
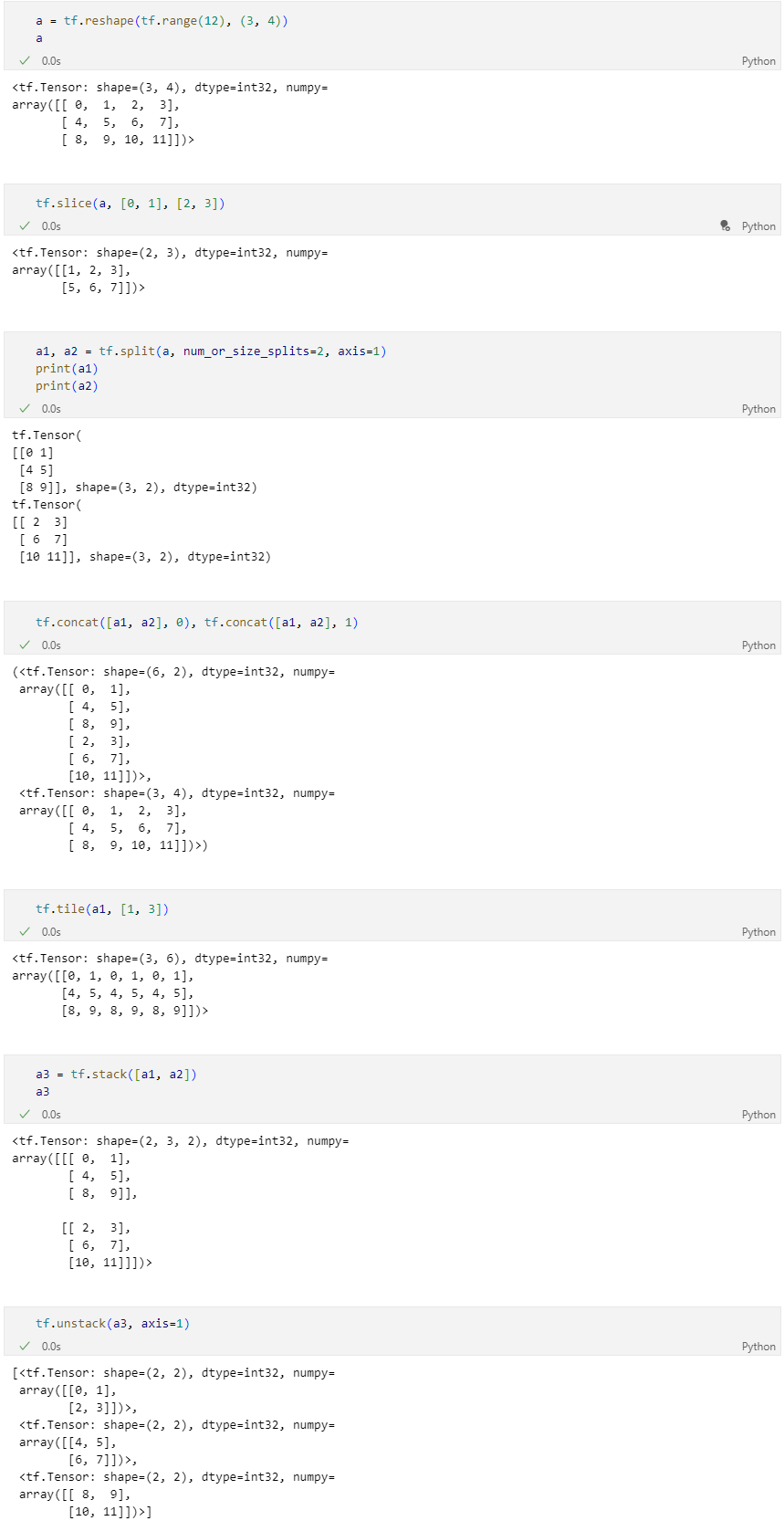
크기 및 차원을 바꾸는 명령
(잘 사용됩니다!!)
이를 사용 할 때는 축을 잘 이해하고 사용하시면 좋습니다.
tf.reshape: 벡터 행렬의 크기 변환tf.transpose: 전치 연산tf.expand_dims: 지정한 축으로 차원을 추가tf.squeeze: 벡터로 차원을 축소

텐서를 나누거나 두 개 이상의 텐서를 합치는 명령
tf.slice: 특정 부분을 추출tf.split: 분할tf.concat: 합치기tf.tile: 복제-붙이기tf.stack: 합성tf.unstack: 분리
[Quiz]
Q . 다음 코드를 에러 없이 실행하라.
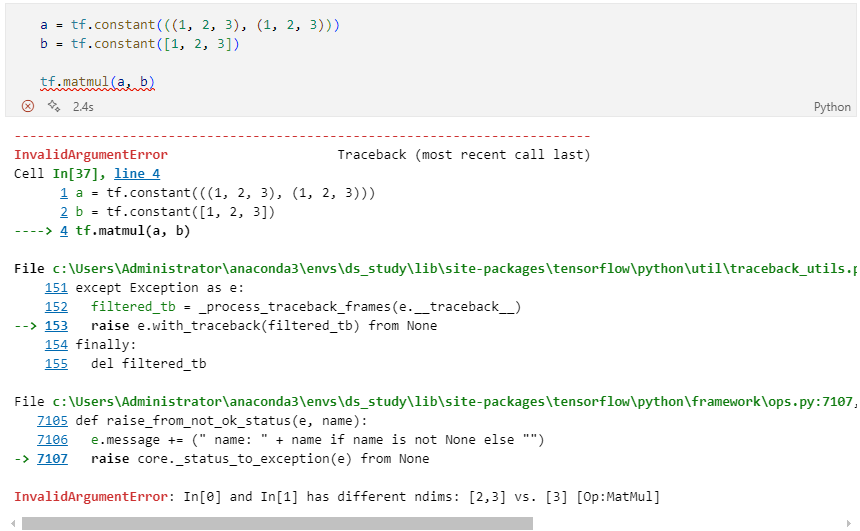
A . 작성 답안

