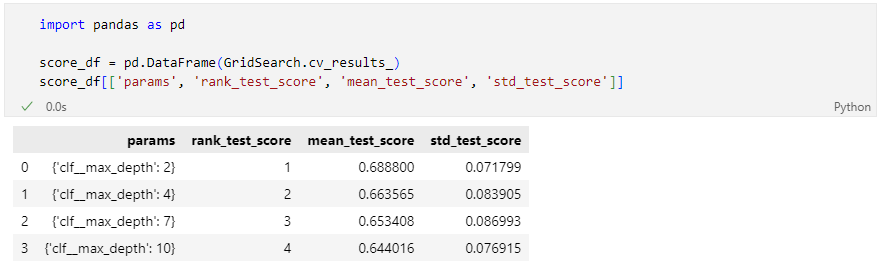
교차검증
- 교차검증
- 과적합 : 모델이 학습 데이터에만 과도하게 최적화된 현상. 그로 인해 일반화된 데이터에서는 예측 성능이 과하게 떨어지는 현상
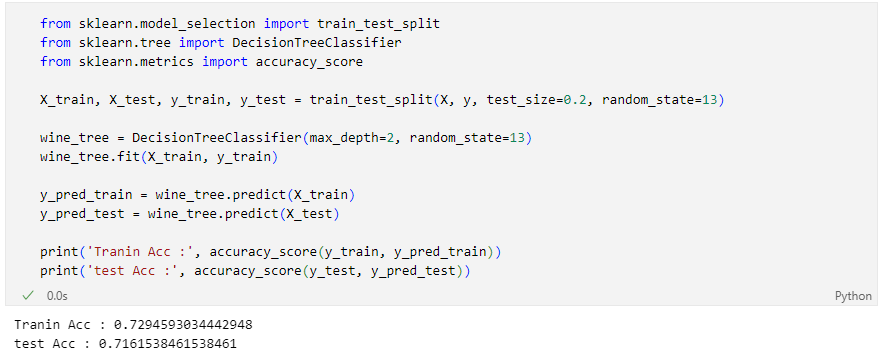
- 지난번 와인 맛 평가에서 훈련용 데이터의 Acc는 72.94, 테스트용 데이터는 Acc가 71.61%였는데, 누가 이 결과가 정말 괜찮은 것인지 묻는다면?
- 나에게 주어진 데이터에 적용한 모델의 성능을 정확히 표현하기 위해서도 유용하다
- holdout

- k-fold cross validation
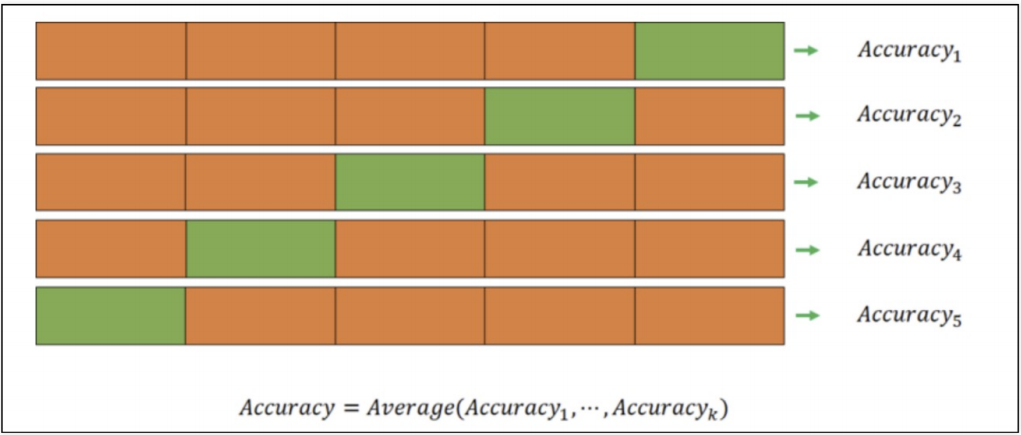
- stratified k-fold cross validation
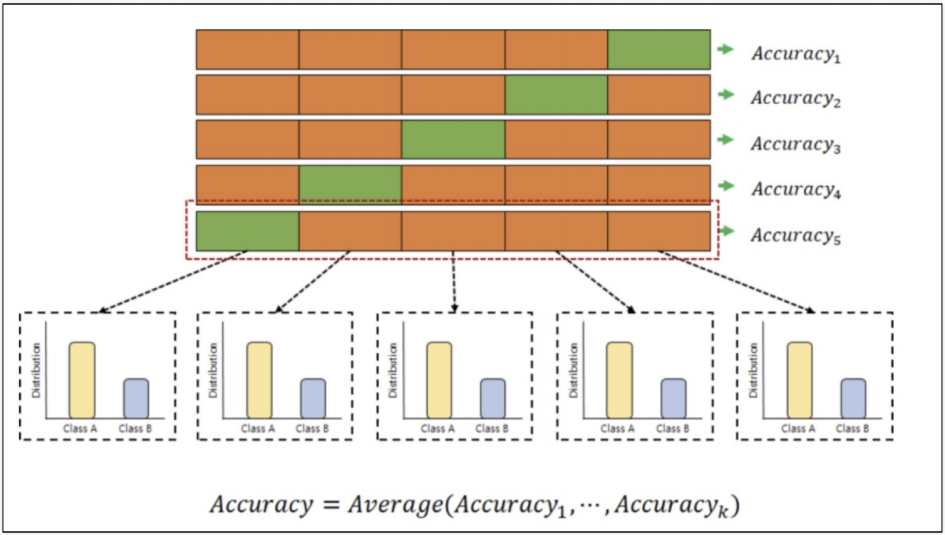
- 검증 validation이 끝난 후 test용 데이터로 최종 평가
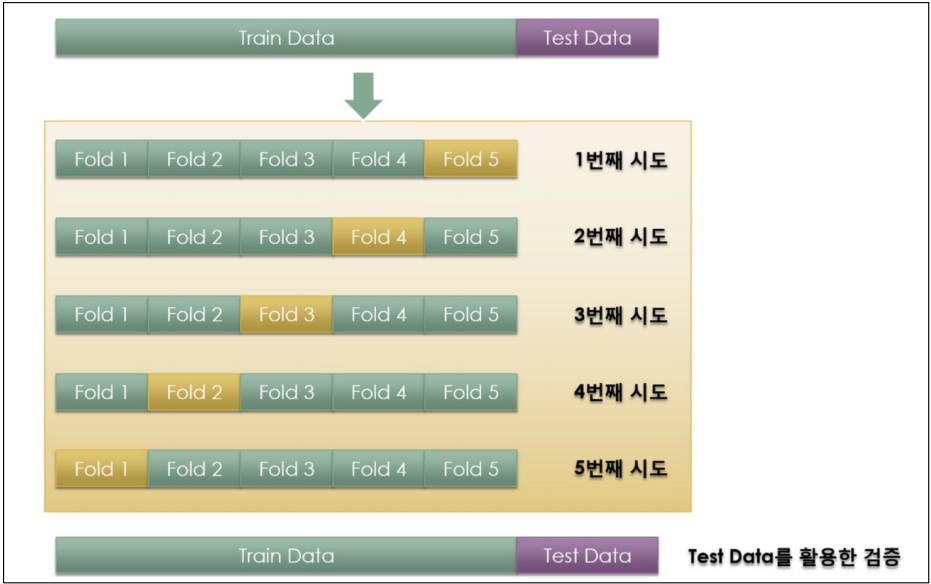
교차검증 구현하기
simple example
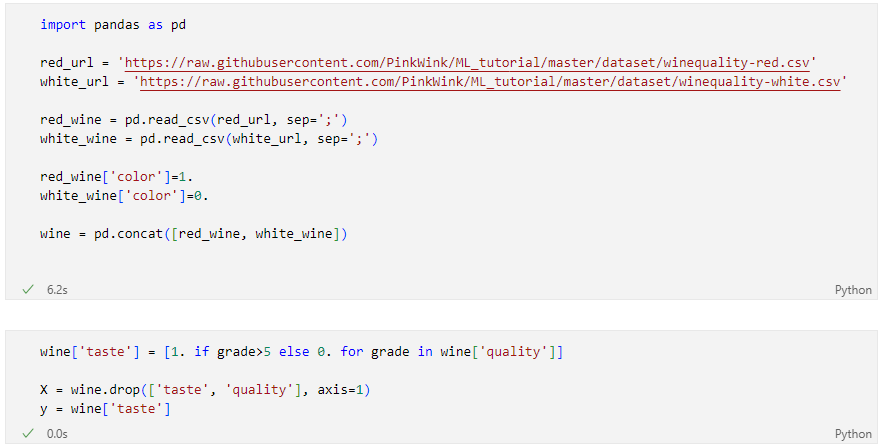
다시 와인 맛 분류하던 데이터로
지난번 의사 결정 나무 모델로는?
여기서 잠깐, 그러니까 누가, “데이터를 저렇게 분리하는 것이 최선인건가?”
“저 acc를 어떻게 신뢰할 수 있는가?” 라고 묻는다면~
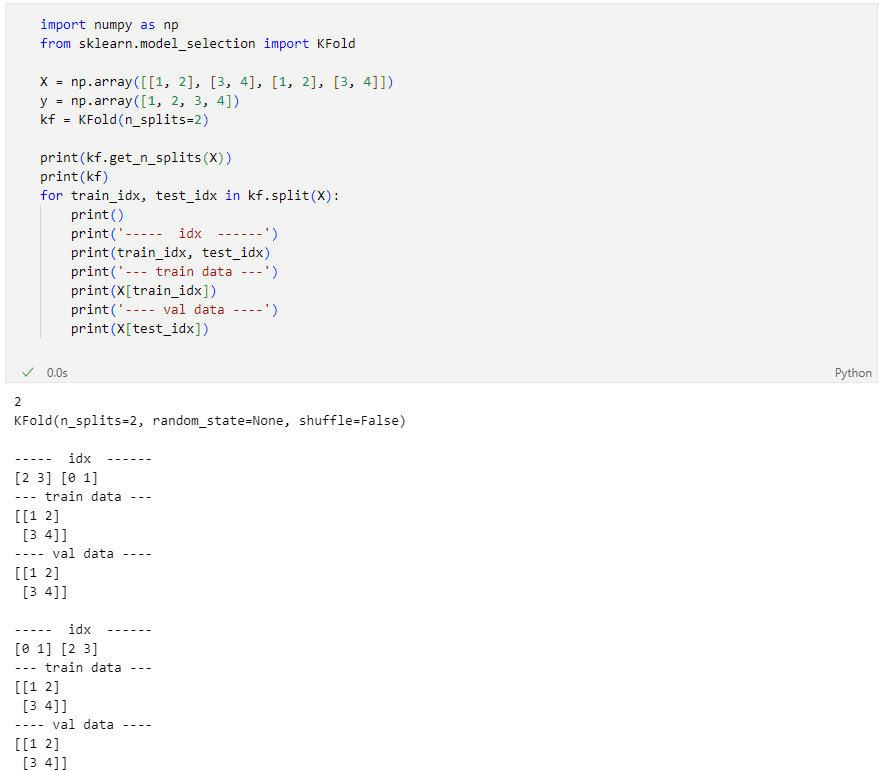
KFold
KFold는 index를 반환한다

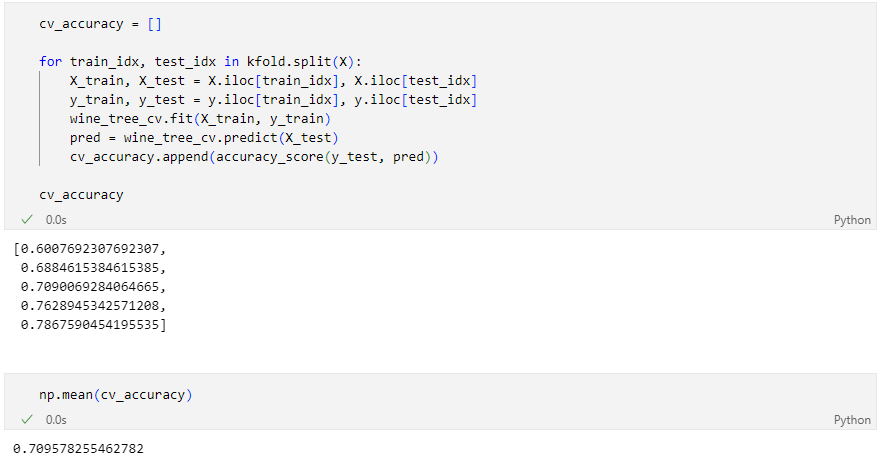
각각의 fold에 대한 학습 후 acc
각 acc의 분산이 크지 않다면 평균을 대표 값으로 한다
StratifiedKFold
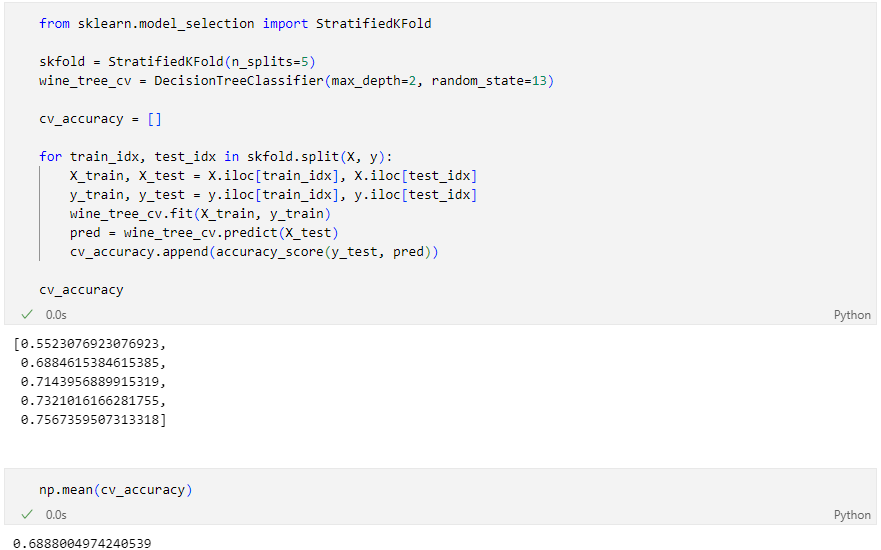
acc의 평균이 더 나쁘다
이런 경우 어떻게 해야 할까?
cross validation을 보다 간편히
depth가 높다고 무조건 acc가 좋아지는 것도 아니다
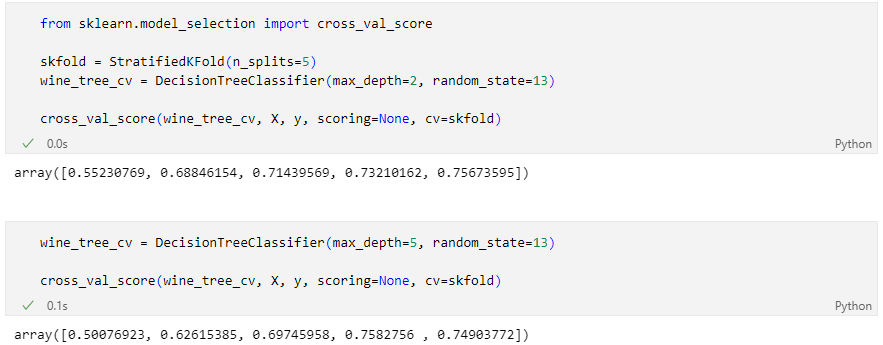
train score와 함께 보고 싶다면
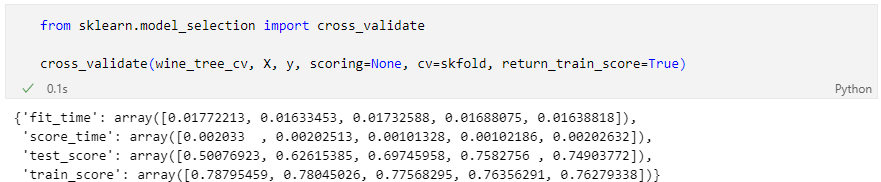
현재 우리는 과적합 현상도 함께 목격하고 있다.
하이퍼파라미터 튜닝
하이퍼파라미터 튜닝
모델의 성능을 확보하기 위해 조절하는 설정 값
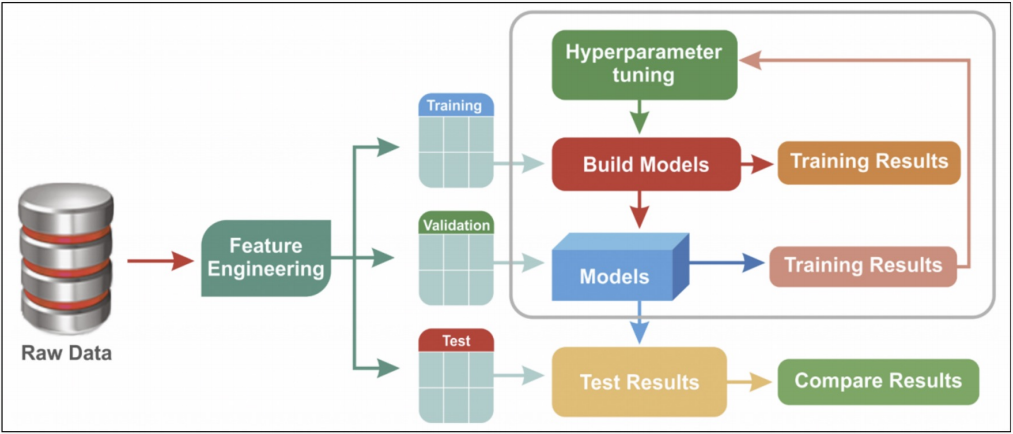
튜닝 대상
- 결정나무에서 아직 우리가 튜닝해 볼만한 것은 max_depth이다.
- 간단하게 반복문으로 max_depth를 바꿔가며 테스트해볼 수 있을 것이다.
- 그런데 앞으로를 생각해서 보다 간편하고 유용한 방법을 생각해보자
일단 다시 새파일에서 작업

GridSearchCV
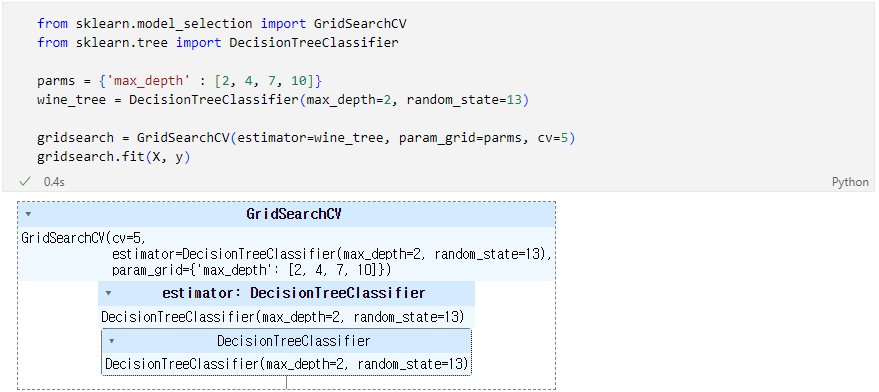
- (참고) 여기서 n_jobs 옵션을 높여주면 CPU의 코어를 보다 병렬로 활용함. Core가 많으면 n_jobs를 높이면 속도가 빨라짐
GridSearchCV의 결과
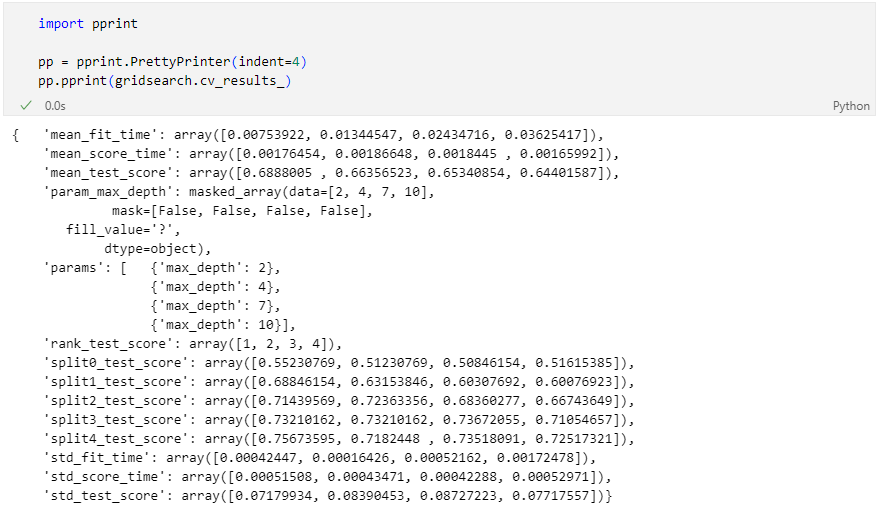
최적의 성능을 가진 모델은?

만약 pipeline을 적용한 모델에 GridSearch를 적용하고 싶다면
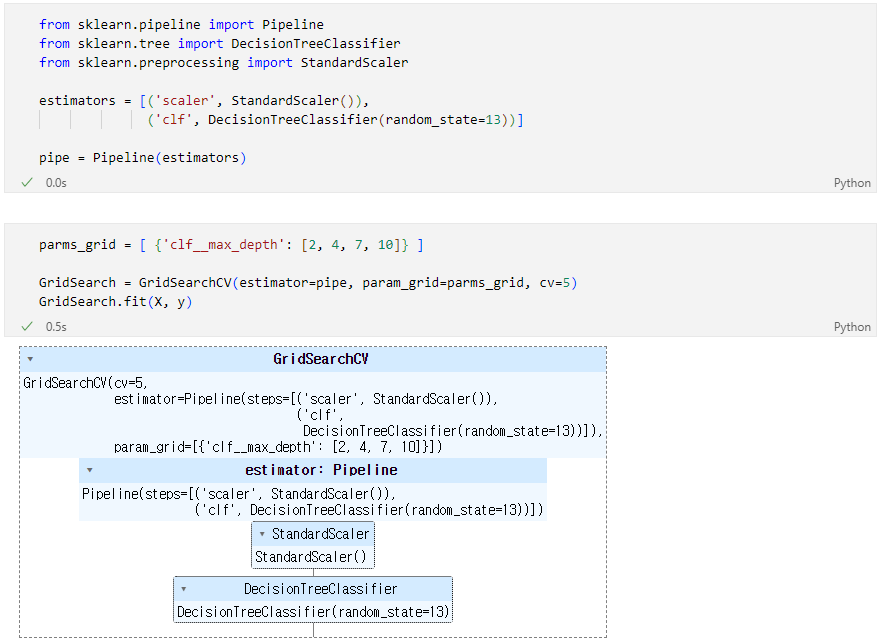
best 모델은?

bestscore
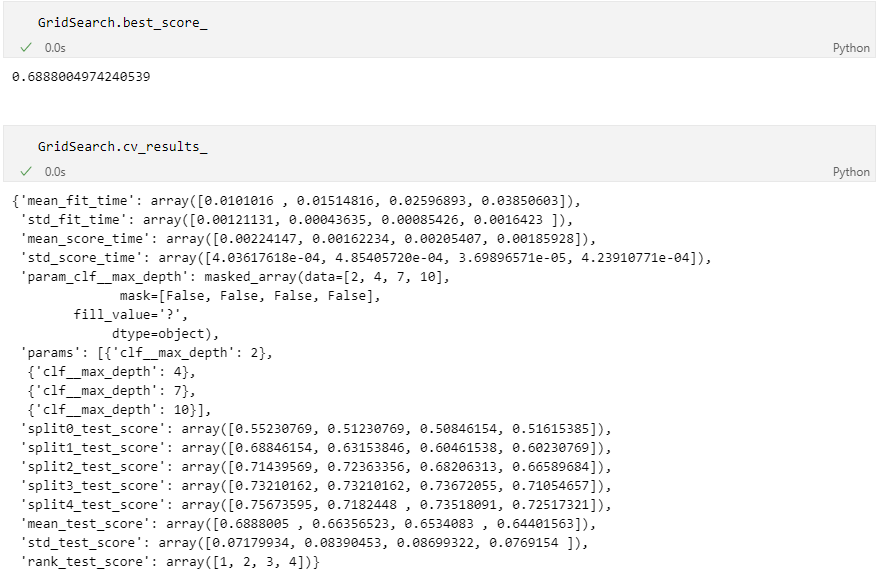
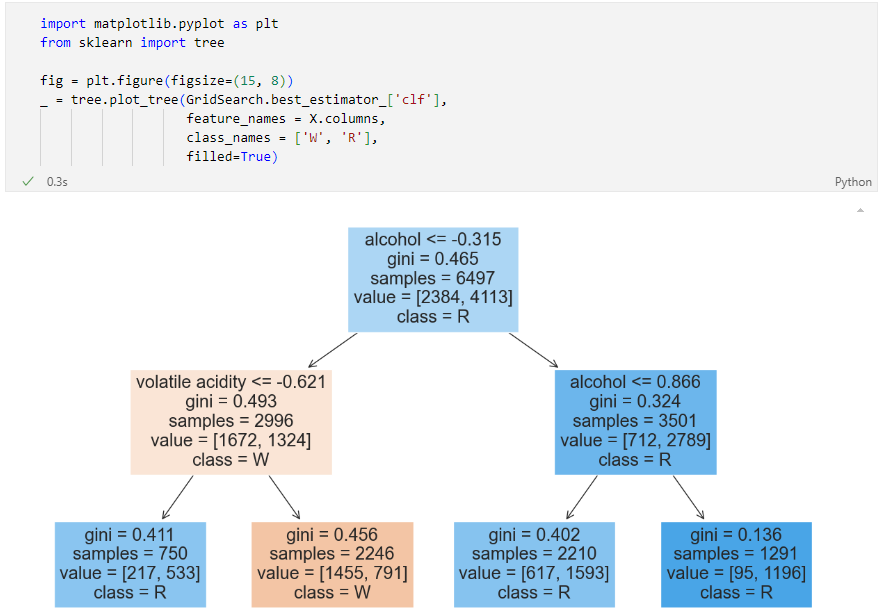
Tree 확인해보기
표로 성능 결과를 정리