EDA Level Test 01 ⭐️
| Week | Data Analysis | Difficulty | This Notebook |
|---|---|---|---|
| 1 | 서울시 인구 데이터 | ⭐️ | 👈 |
| 2 | 화장품 성분 데이터 | ⭐️⭐️⭐️ | |
| 3 | 올림픽 데이터 | ⭐️⭐️ | |
| 4 | 국가별 인터넷 사용률 데이터 | ⭐️⭐️ | |
| 5 | 전국 박물관/미술관 정보 표준 데이터 | ⭐️⭐️⭐️ | |
| 6 | 서울시 흡연율 통계 데이터 | ⭐️⭐️ | |
| 7 | 웹크롤링 | ⭐️ | |
| 8 | 서울시 지하철 호선별 역별 유/무임 승하차 인원 정보 데이터 | ⭐️⭐️ | |
| 9 | 서울시 교통사고 현황 (사고유형별) 통계 데이터 | ⭐️⭐️ | |
| 10 | 서울시 교통사고 현황 (사고유형별) 통계 + 서울시 차량통행속도 (구별/월별) 통계 + 서울시 인구밀도 (구별) 통계 | ⭐️⭐️⭐️ |
문제 소개 및 데이터 준비 단계
문제 소개
- 총 3단계 데이터 분석 상황 제시 (총 100점)
- 1단계 DataFrame 불러오기 & 전처리 (30점)
- 2단계 원하는 정보 얻기 (30점)
- 3단계 시각화 (40점)
- 시각화 단계는 채점 코드가 없습니다. 요구 조건에 맞는 그래프를 작성해주신 후 제출해주세요!
Data 원본 출처
- Source: 서울시 열린데이터
- Data Download: PinkWink Blog
참고사항
- 데이터는 탭으로 구분하여 TXT 파일 형식으로 제공
- 외국인 세대수 제외
- 65세이상 고령자 수: 외국인 포함
문제 시작! 🏃🏻
1단계: DataFrame 불러오기 & 전처리
문제 1-1) 0, 1, 2번 index의 row를 제거하고 index를 초기화 하세요(기존 index는 삭제(drop)하세요). (10점)
-
예시: 0,1,2번 index 제거

-
예시: index 초기화

-
완료 후 결과 dataframe 변수를 check_01_01 함수에 입력하여 채점하세요.
채점 방법
- grading 모듈 불러오기
from grading import *- 채점 코드 통과
- 각 문제마다 번호에 맞는 채점 코드를 통과시켜주세요
- check_01_01(df), check_01_02(df) ...
- 채점 코드까지 통과시킨 후, 제출!
사용 예시
check_01_01(df)
정답입니다! 10점 누적 되었습니다!
현재 누적 점수: 10 / 100from grading import *
import pandas as pd
import numpy as npdf = pd.read_csv('./datas/report.txt', sep='\t')
df.head()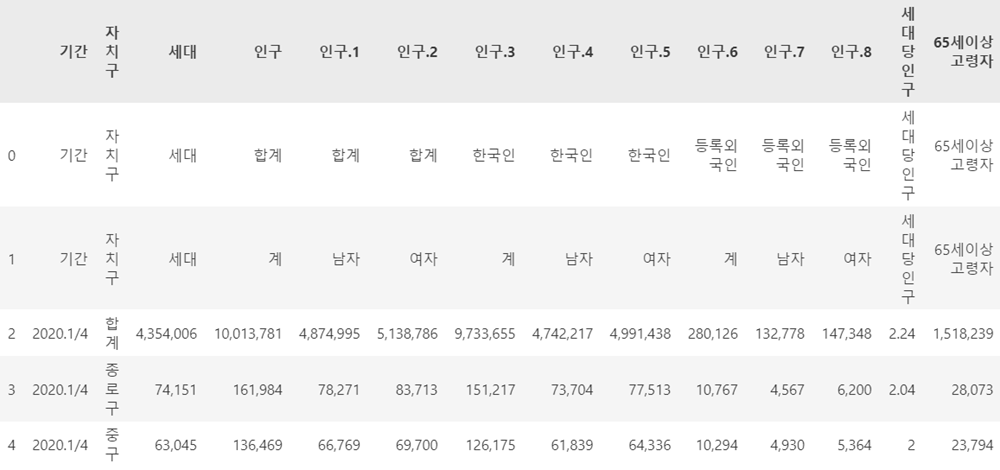
df = df.drop(index=[0, 1, 2])
df = df.reset_index(drop=True)
df.head()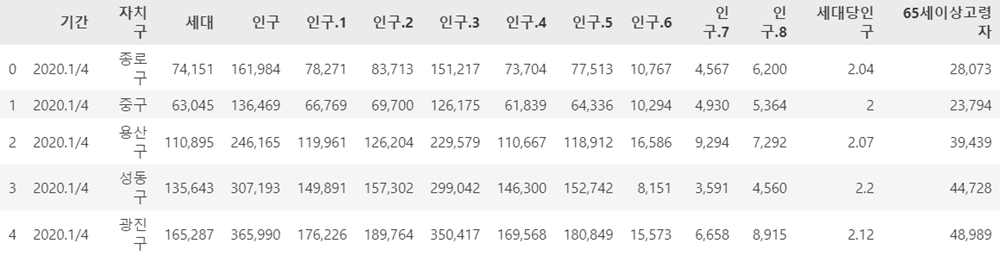
문제 1-2) 현재의 컬럼명(current_columns)을 아래 new_columns와 같이 변경하세요. (10점)
-
current_columns = ['기간', '자치구', '세대', '인구', '인구.1', '인구.2', '인구.3', '인구.4', '인구.5', '인구.6', '인구.7', '인구.8', '세대당인구', '65세이상고령자']
-
new_columns = ['기간', '자치구', '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '세대당인구', '65세이상고령자']
-
예시
-
완료 후 결과 dataframe 변수를 check_01_02 함수에 입력하여 채점하세요.
df.rename(
columns={
df.columns[3] : '합계',
df.columns[4] : '남자',
df.columns[5] : '여자',
df.columns[6] : '한국인 계',
df.columns[7] : '한국인 남자',
df.columns[8] : '한국인 여자',
df.columns[9] : '등록외국인 계',
df.columns[10] : '등록외국인 남자',
df.columns[11] : '등록외국인 여자',
},inplace=True
)
df_target = dfdf_target.head()
문제 1-3) 천단위 구분자 " , "를 제거하고, data의 type을 int 또는 float으로 변경하세요. (10점)
- 기간, 자치구: 변경 없음
- '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '65세이상고령자': 천단위 구분자 "," 제거 및 int로 타입 변경
- 예시

- '세대당인구': float으로 타입 변경
- 예시
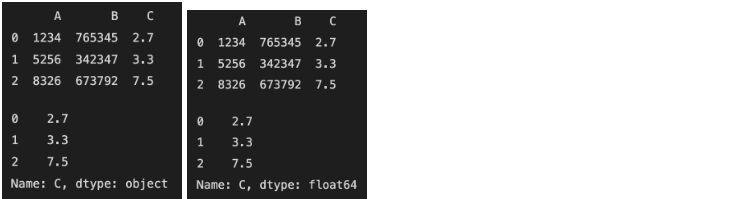
- 완료 후 결과 dataframe 변수를 check_01_03 함수에 입력하여 채점하세요.
columns = ['세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자',
'등록외국인 계', '등록외국인 남자', '등록외국인 여자', '65세이상고령자', '세대당인구']
for col in columns:
df_target[col] = df_target[col].str.replace(',', '')
if col == '세대당인구':
df_target[col] = df_target[col].astype('float64')
else:
df_target[col] = df_target[col].astype('int64')
df_target.head()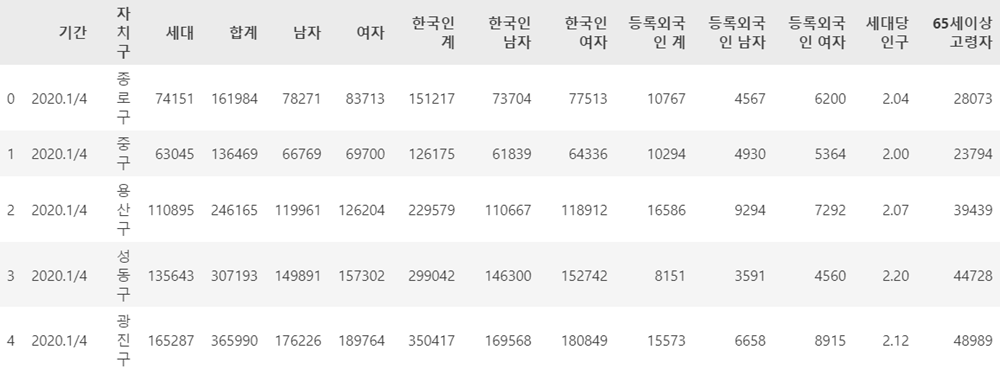
df_target.info()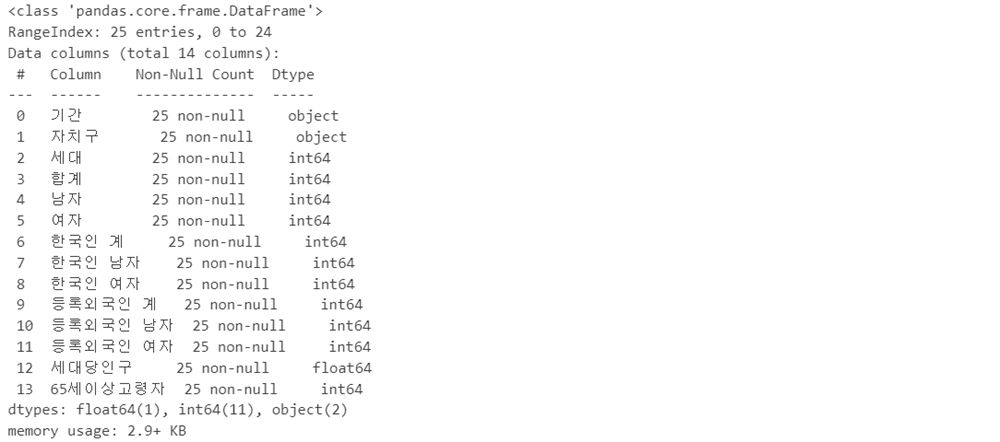
2단계: 원하는 정보 얻기
Pandas DataFrame의 기능을 이용하여 아래 문제의 답을 구하세요.
서울시는 아래와 같이 5개의 권역으로 구분됩니다.
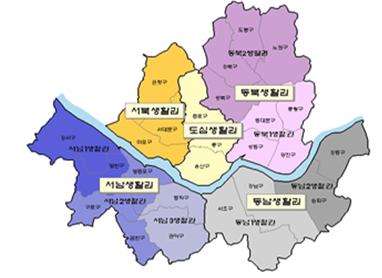
-
ref: 서울시-도시계획체계
-
도심권: ['종로구', '중구', '용산구']
-
동북권: ['성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구']
-
서북권: ['은평구', '서대문구', '마포구']
-
서남권: ['양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구']
-
동남권: ['서초구', '강남구', '송파구', '강동구']
문제 2-1) 1단계에서 구한 DataFrame에 '권역' column을 추가하여 해당 구에 맞는 권역을 입력하세요. (5점)
- 예시
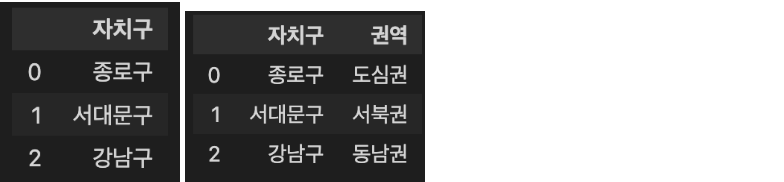
- 완료 후 결과 dataframe 변수를 check_02_01 함수에 입력하여 채점하세요.
region_dict = {'도심권': ['종로구', '중구', '용산구'],
'동북권': ['성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구'],
'서북권': ['은평구', '서대문구', '마포구'],
'서남권': ['양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구'],
'동남권': ['서초구', '강남구', '송파구', '강동구']
}tmp_gu = []
for gu in df_target['자치구']:
for region, gu_list in region_dict.items():
if gu in gu_list:
tmp_gu.append(region)len(df_target.index), len(tmp_gu)
df_target['권역'] = tmp_gudf_target.head()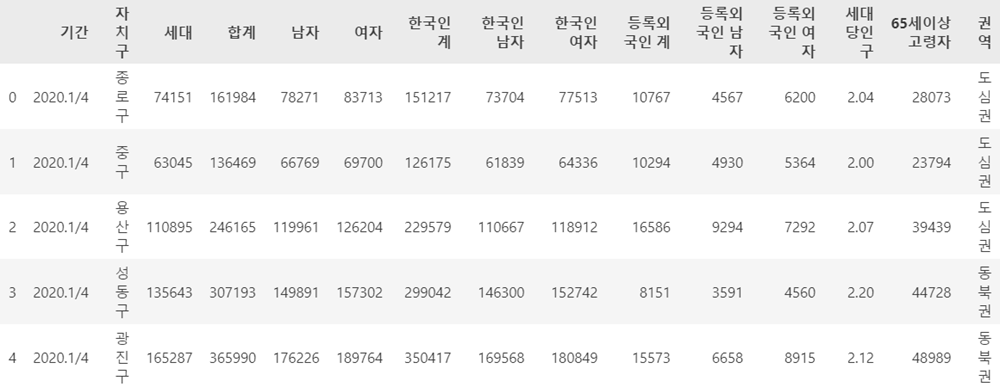
문제 2-2) 2-1에서 만든 DataFrame을 이용하여 Pandas의 pivot_table 메소드를 활용하여 각 권역별 아래 값의 합을 구하고, '합계'를 기준으로 내림차순 정렬하세요. (5점)
-
구할 값: ['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자']
-
참고: Pivot Table
- 예시
-
완료 후 결과 dataframe 변수를 check_02_02 함수에 입력하여 채점하세요.
df_pivot = pd.pivot_table(df_target,
index='권역',
values=['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자'],
aggfunc='sum')
df_pivot = df_pivot.sort_values('합계', ascending=False)df_pivot.head()
문제 2-3) 2-2에서 만든 Pivot Table을 이용하여 각 권역별 ['고령자비율', '외국인비율', '여성비율', '세대당인구'] 컬럼을 만들어 아래와 같이 값을 입력하고 '외국인비율'을 기준으로 오름차순 정렬하세요. (5점)
-
고령자비율: 65세이상고령자 / 합계 * 100
-
외국인비율: 등록외국인 계 / 합계 * 100
-
여성비율: 여자 / 합계 * 100
-
세대당인구: (합계 - 등록외국인 계) / 세대
-
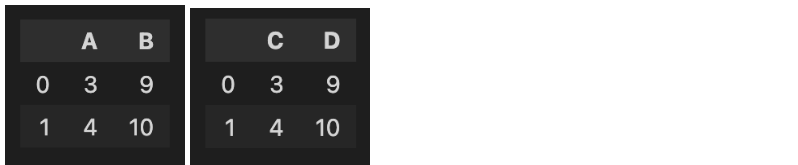
예시: B/C 비율 및 B 기준 오름차순 정렬
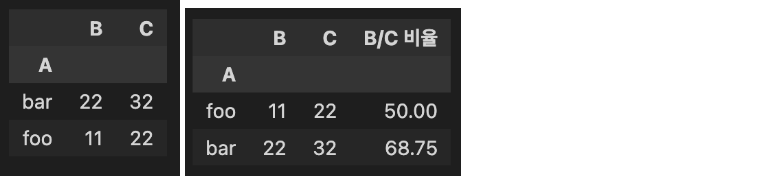
-
완료 후 결과 dataframe 변수를 check_02_03 함수에 입력하여 채점하세요.
df_pivot['고령자비율'] = df_pivot['65세이상고령자'] / df_pivot['합계'] * 100
df_pivot['외국인비율'] = df_pivot['등록외국인 계'] / df_pivot['합계'] * 100
df_pivot['여성비율'] = df_pivot['여자'] / df_pivot['합계'] * 100
df_pivot['세대당인구'] = (df_pivot['합계'] - df_pivot['등록외국인 계']) / df_pivot['세대']df_pivot = df_pivot.sort_values('외국인비율', ascending=True)df_pivot.head()
문제 2-4) 2-1에서 만든 DataFrame을 이용하여 각 구별 ['고령자비율', '외국인비율', '여성비율'] 컬럼을 만들어 아래와 같이 값을 입력하고 '세대당인구'을 기준으로 내림차순 정렬하세요. (5점)
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
- 완료 후 결과 dataframe 변수를 check_02_04 함수에 입력하여 채점하세요.
df_target['고령자비율'] = df_target['65세이상고령자'] / df_target['합계'] * 100
df_target['외국인비율'] = df_target['등록외국인 계'] / df_target['합계'] * 100
df_target['여성비율'] = df_target['여자'] / df_target['합계'] * 100df_target = df_target.sort_values('세대당인구', ascending=False)df_target.head()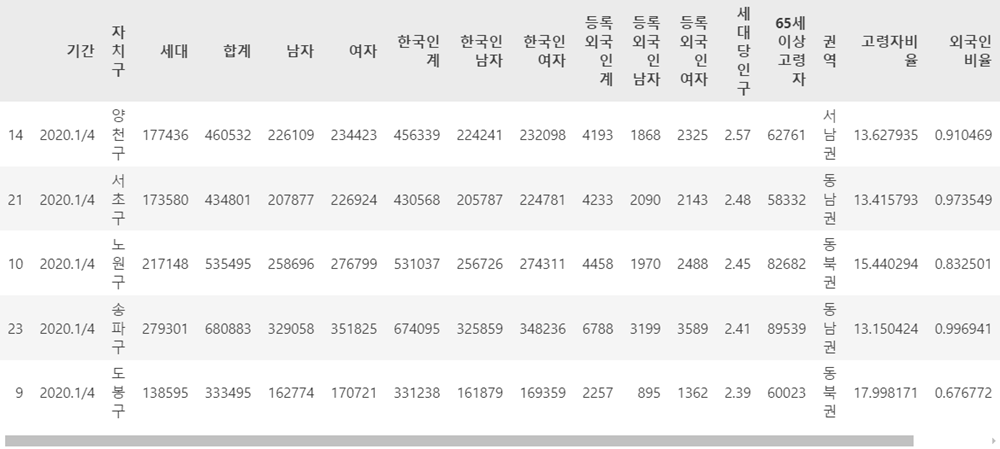
문제 2-5) 2-3에서 만든 DataFrame을 이용하여 ['고령자비율', '외국인비율', '여성비율', '세대당인구']간의 피어슨 상관계수 행렬(Correlation matrix)를 구하세요. (10점)
-
참고
-
상관계수(correlation coefficient): 두 변수가 함께 변하는 정도를 -1 ~ +1 범위의 수로 나타낸 것
-
피어슨 상관계수: 칼 피어슨(Karl Pearson)이 개발한 상관계수로, 일반적으로 상관계수라고 하면 피어슨 상관계수를 말함
- Standard Correlation Coefficient
- r(상관계수) = X와 Y가 함께 변하는 정도 / X와 Y가 각각 변하는 정도
-
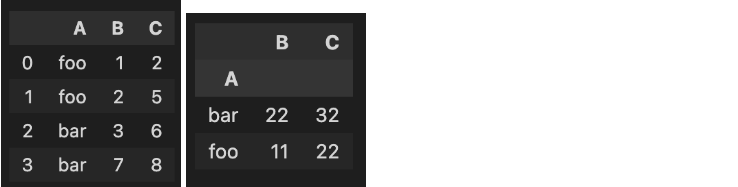
상관계수 행렬(Correlation Matrix): 변수간 상관계수를 보여주는 행렬
- 예시: dog와 cat간의 상관계수 행렬
-
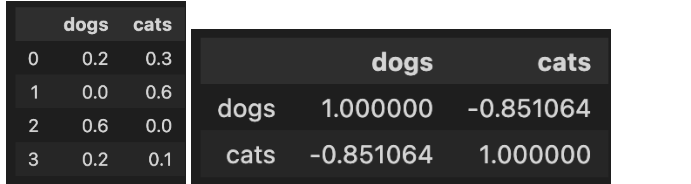
- 완료 후 결과 dataframe 변수를 check_02_05 함수에 입력하여 채점하세요.
pivot_corr = df_pivot[['고령자비율', '외국인비율', '여성비율', '세대당인구']]
pivot_corr = pivot_corr.corr()pivot_corr
3단계: 시각화
Pandas DataFrame의 Plot기능, Matplotlib.pyplot, Seaborn 등 시각화 Library를 이용하여 문제에서 제시하는 조건에 맞게 시각화하세요.
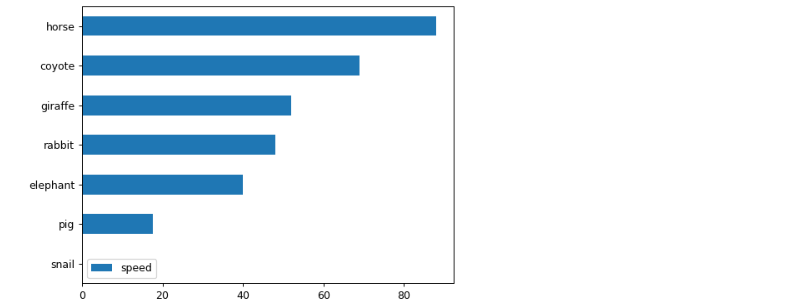
문제 3-1) 자치구별 고령자비율을 내림차순에 따라 barh 그래프로 시각화 하세요. (10점)
- 예시
# 한글 설정
import matplotlib.pyplot as plt
import seaborn as sns
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
%matplotlib inline
path = "C:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
rc("font", family="Arial Unicode MS")
elif platform.system == "Windows":
font_name = font_manager.Fontproperties(fname=path).get_name()
rc("font", family=font_name)
else:
print("Unkown system. sorry~~")df_target.sort_values(by='고령자비율').plot(
x='자치구',
y='고령자비율',
kind='barh',
grid=True,
title='자치구별 고령자비율',
figsize=(10,10));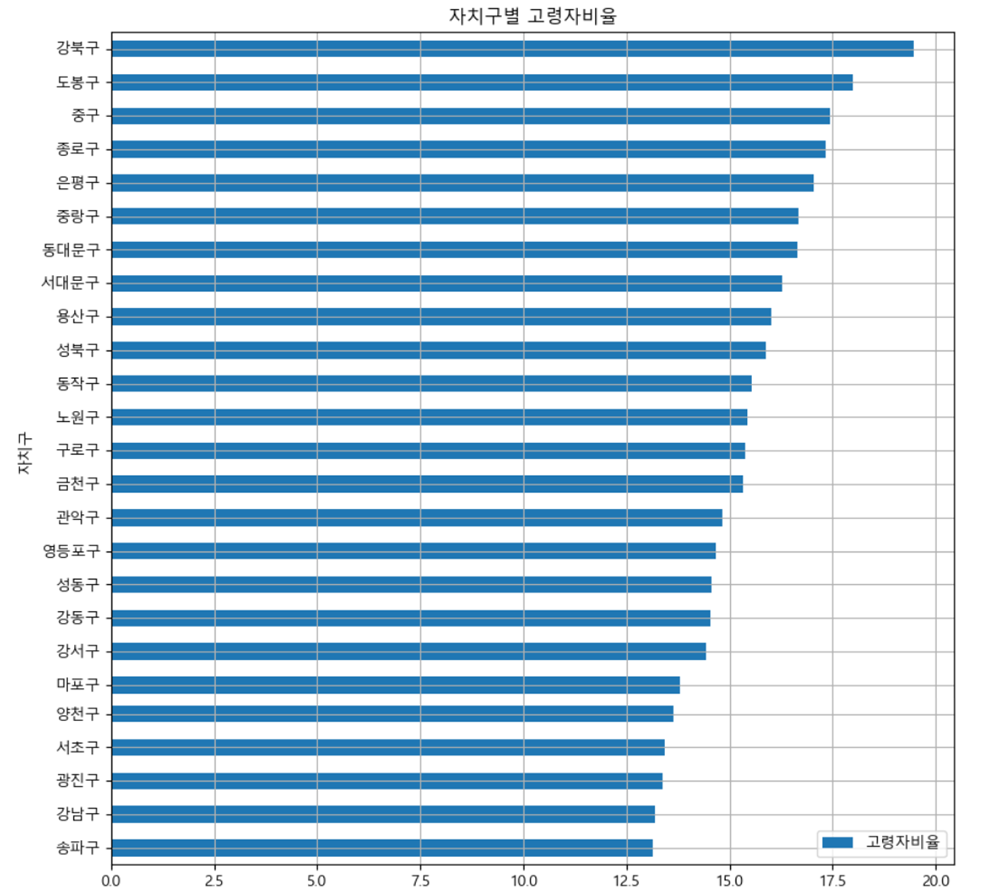
문제 3-2) 권역별 등록외국인 계를 PIE chart로 시각화 하세요. (10점)
- 예시
foreigner_count = df_target.groupby('권역').sum()['등록외국인 계']
plt.pie(foreigner_count, labels=foreigner_count.index)
plt.legend(loc=(1.0, 0.8))
plt.title('권역별 등록외국인 계')
plt.show()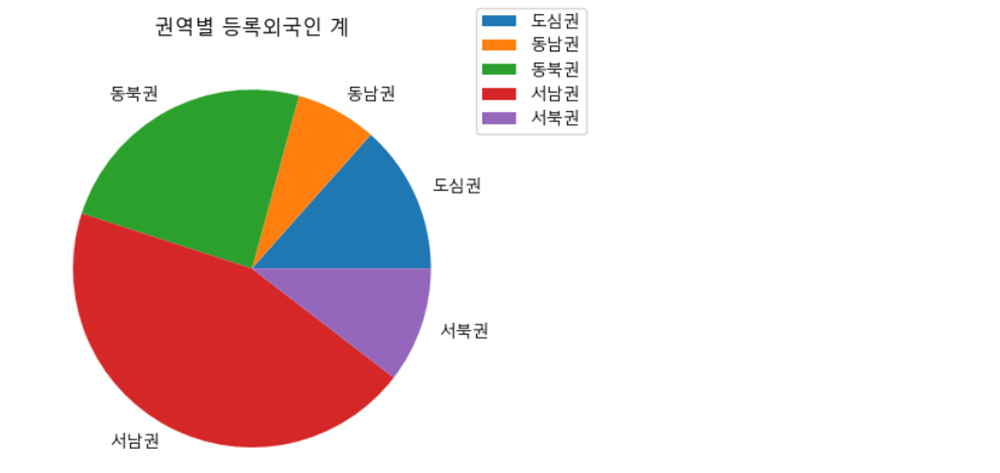
문제 3-3) 권역별 외국인비율을 Box plot으로 시각화 하세요. (10점)
- 예시
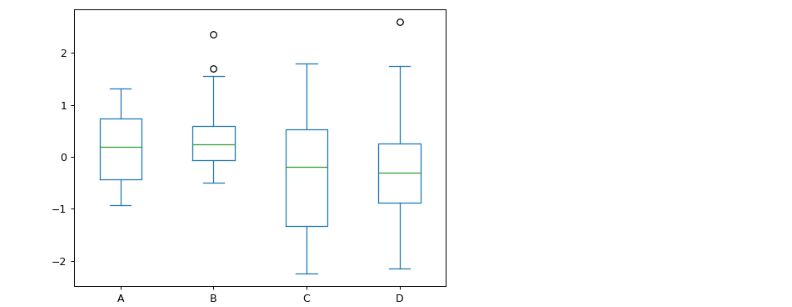
foreigner_count = df_target[['권역','외국인비율']]
plt.figure(figsize=(10, 6))
sns.boxplot(
foreigner_count,
x ='권역',
y ='외국인비율',
palette = 'Set1')
plt.title('권역별 외국인 비율')
plt.grid()
plt.show()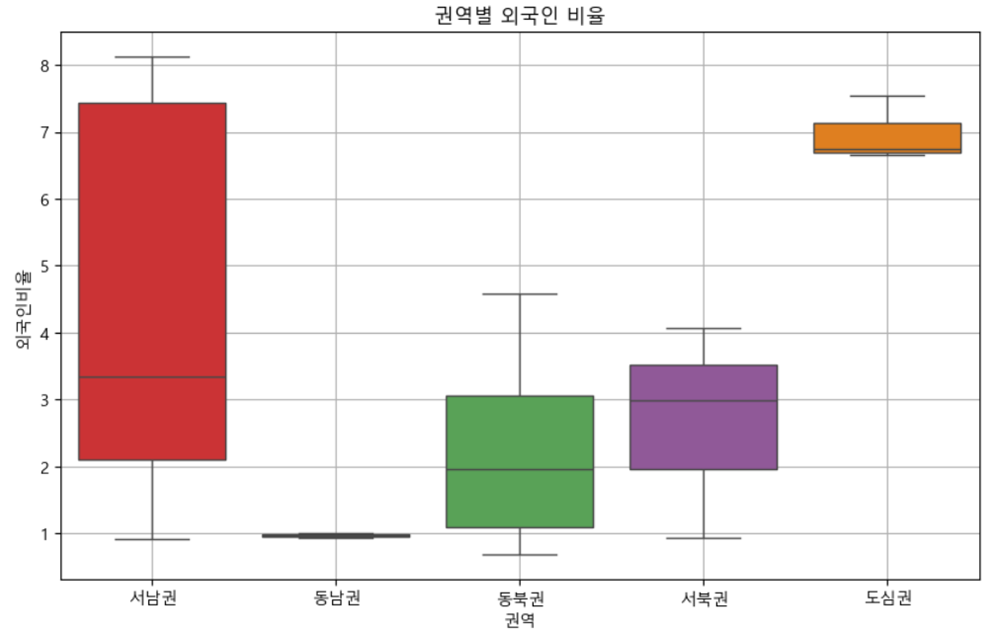
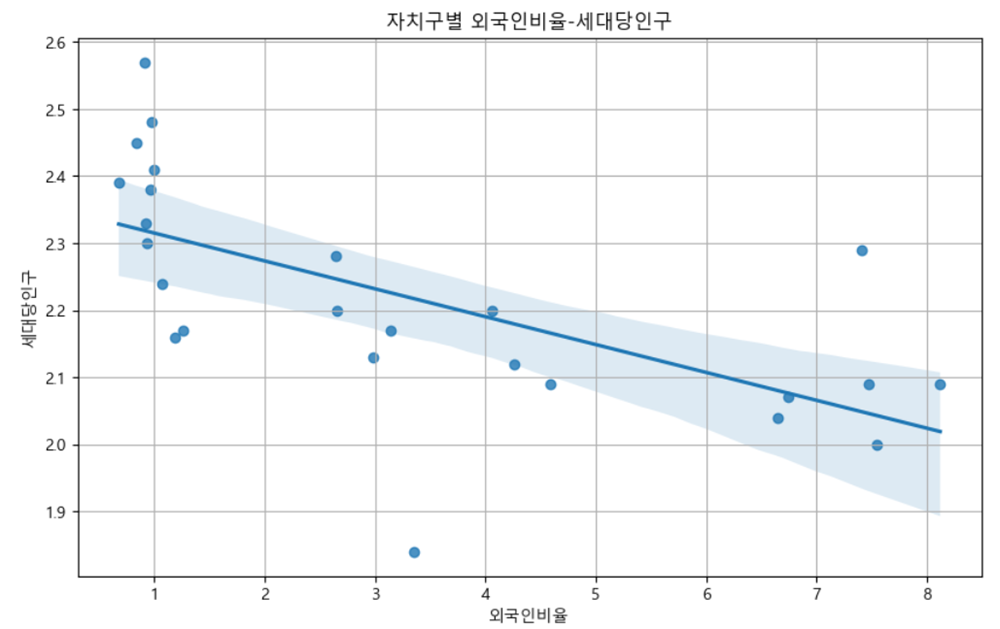
문제 3-4) 자치구별 외국인비율-세대당인구를 Scatter plot에 나타내고, 상관관계에 따른 Regression Line을 시각화 하세요. (10점)
- 예시
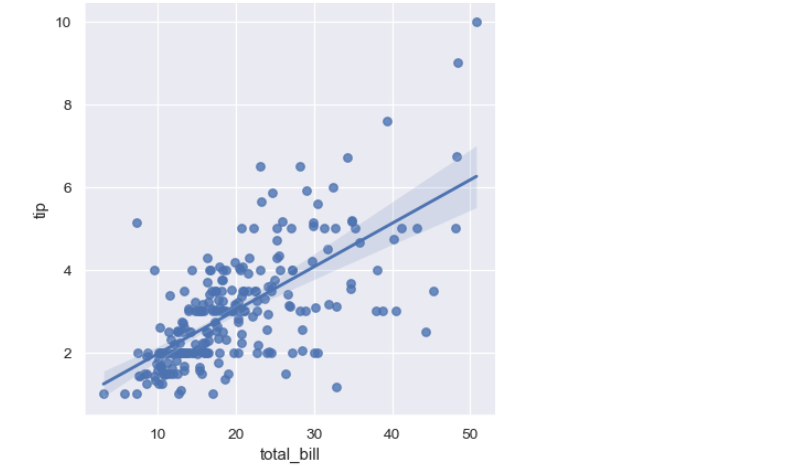
plt.figure(figsize=(10,6))
sns.regplot(
df_target,
x=df_target['외국인비율'],
y=df_target['세대당인구'])
plt.title('자치구별 외국인비율-세대당인구')
plt.grid()
plt.show()