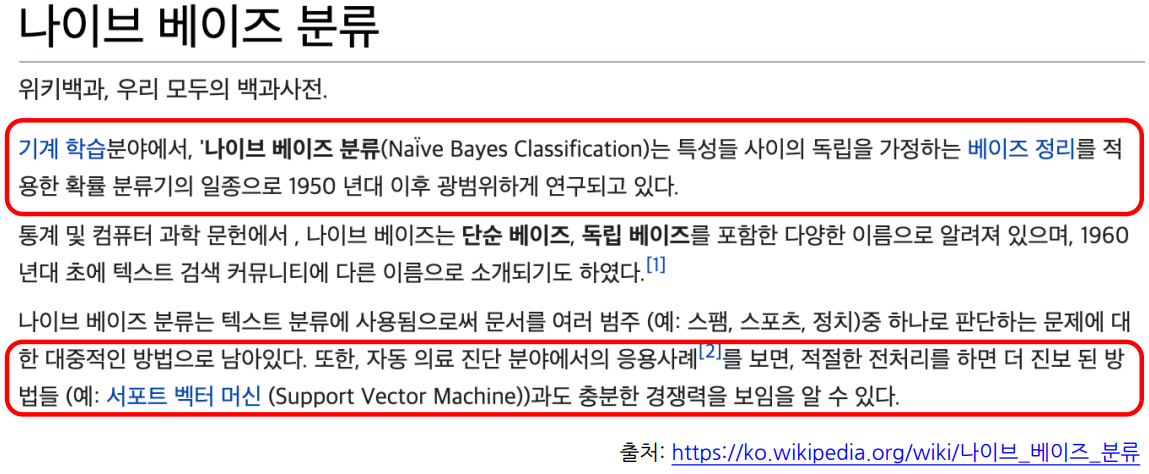
Naive Bayes Classifier
NaïveBayesClassifier - 영어
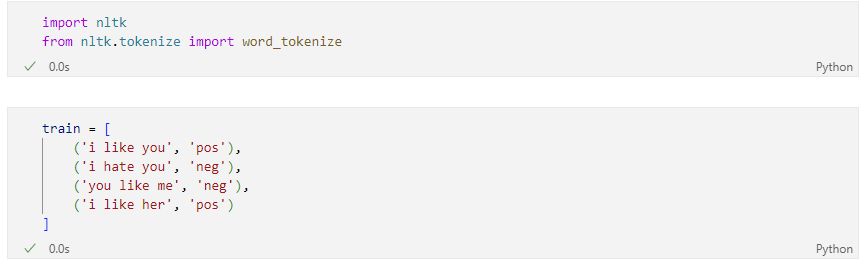
훈련용 문장 생성
NaïveBayes분류기는 지도학습이라서 라벨을 함께 지정
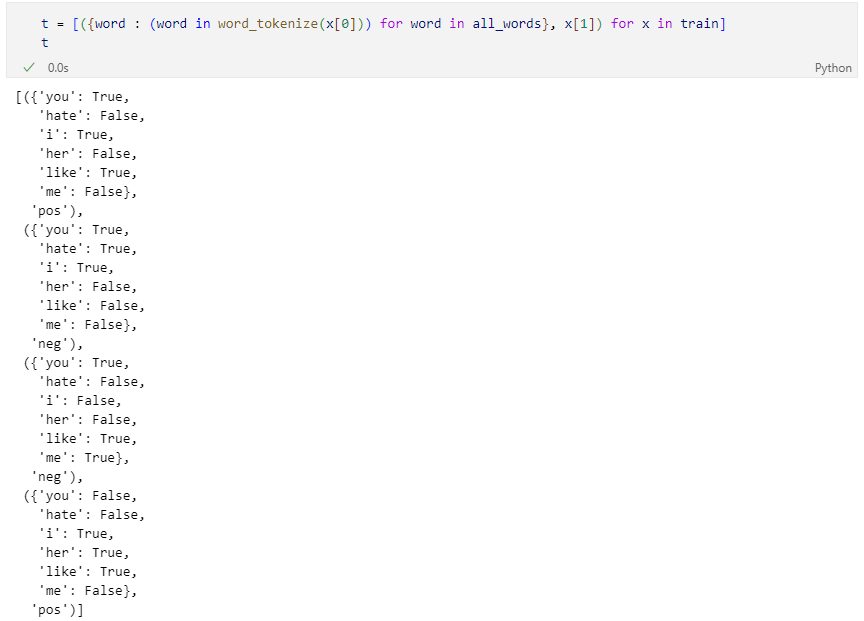
전체 말 뭉치 조회

말 뭉치 대비 단어의 유무 표기
분류 훈련
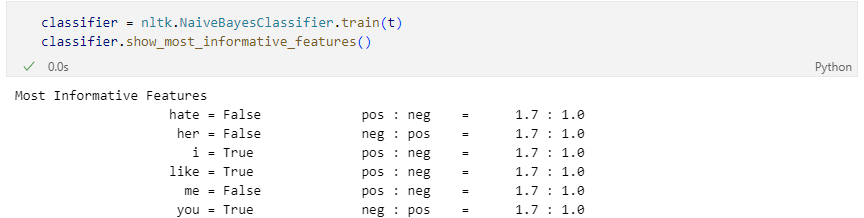
학습 결과 테스트
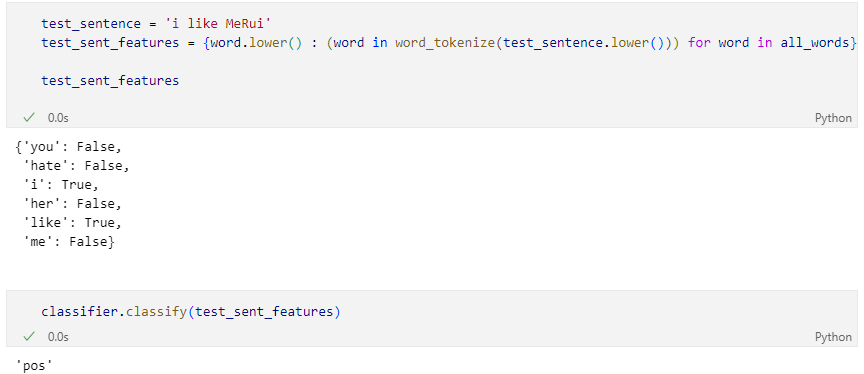
NaïveBayesClassifier - 한글
훈련용 문장 생성

전체 말 뭉치 조회
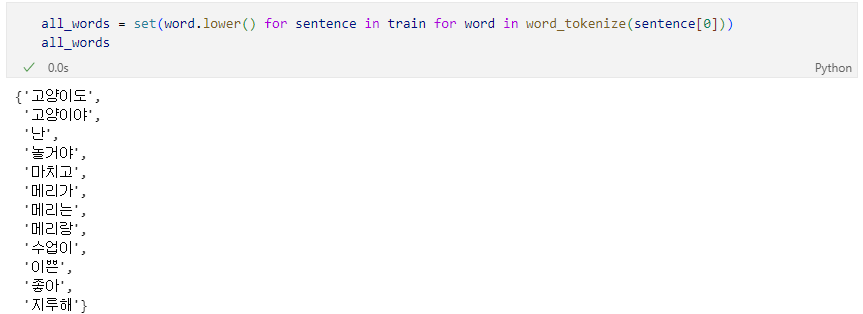
말 뭉치 대비 단어의 유무 표기
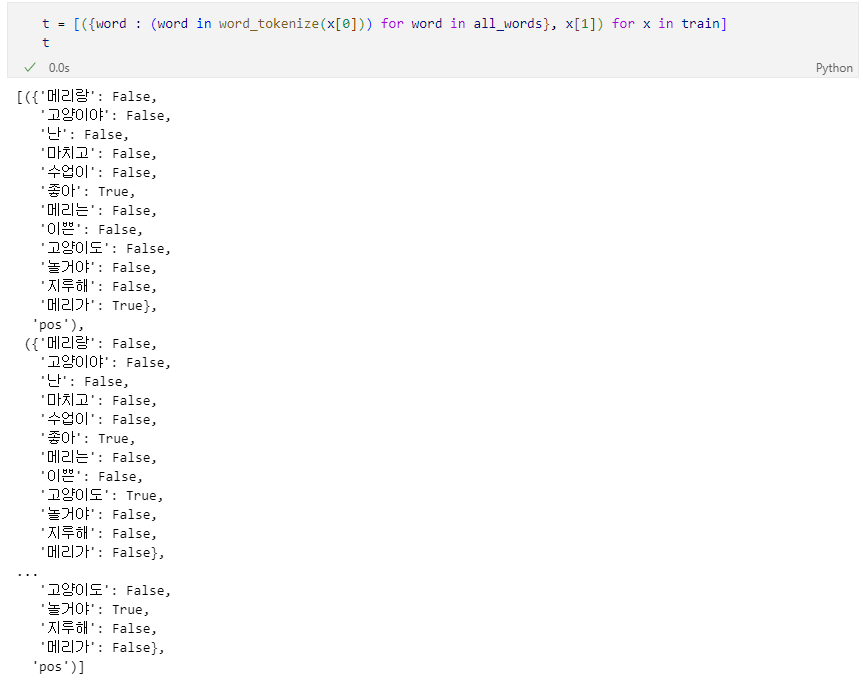
분류 훈련
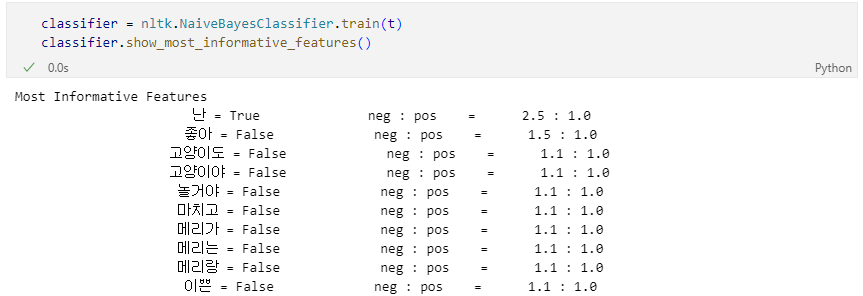
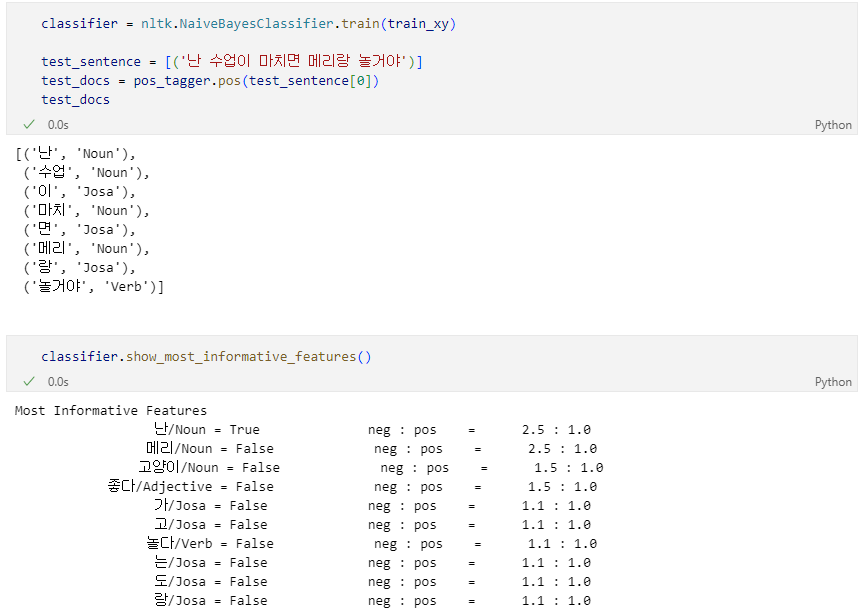
학습 결과 테스트
학습결과가 만족스럽지 못한 이유는 한글의 형태소 분석이 제외되었기 때문이다.
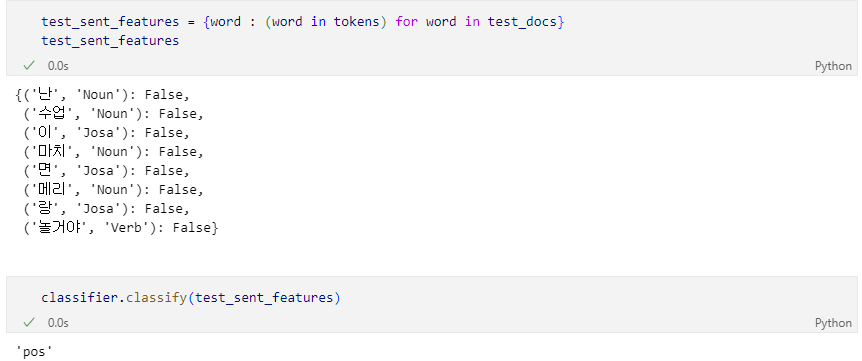
형태소 분석을 한 후 품사를 단어뒤에 덧붙이는 함수를 만들어 말뭉치 조회
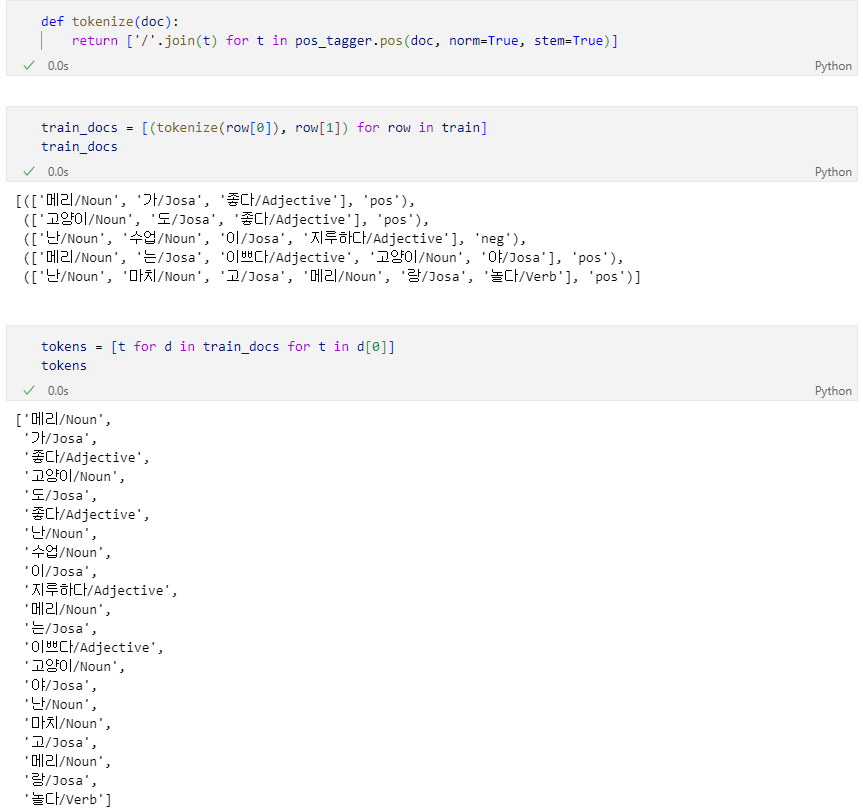
말 뭉치 대비 단어의 유무 표기
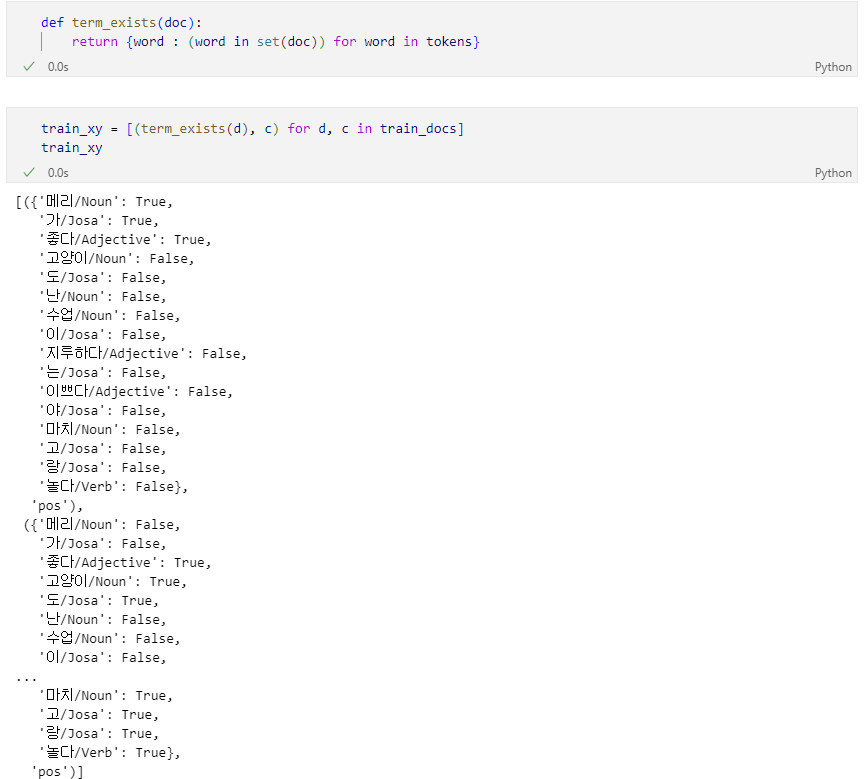
분류 훈련
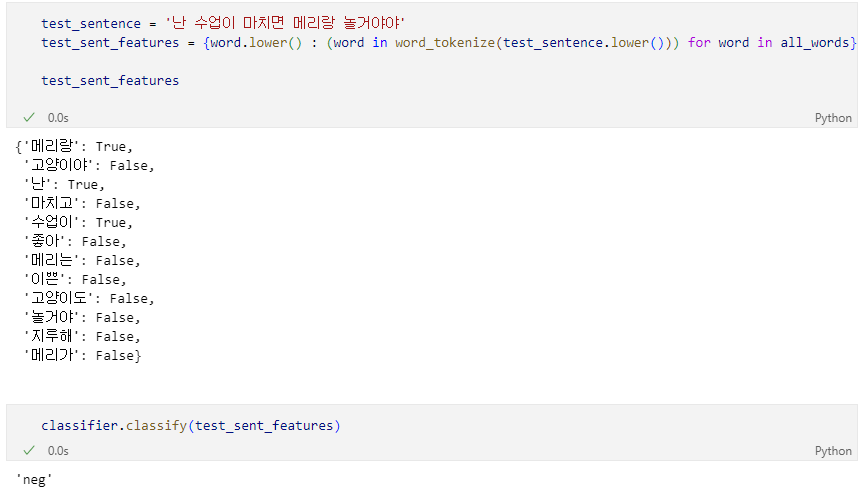
학습 결과 테스트
문장의 유사도
-
만약 문장을 점처럼 일종의 벡터로 표현할 수 있다면 두 문장 사이의 거리를 구해서 여러 문장 중 가장 유사한 문장을 찾을 수 있을까?
-
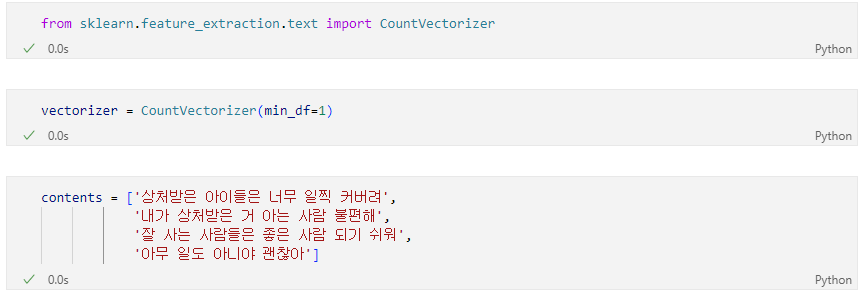
sklearn이 제공하는 문장을 벡터로 변환하는 함수 CountVectorizer
CountVectorizer
훈련용 문장
거리를 구하는 것이 목적이므로 라벨 미지정
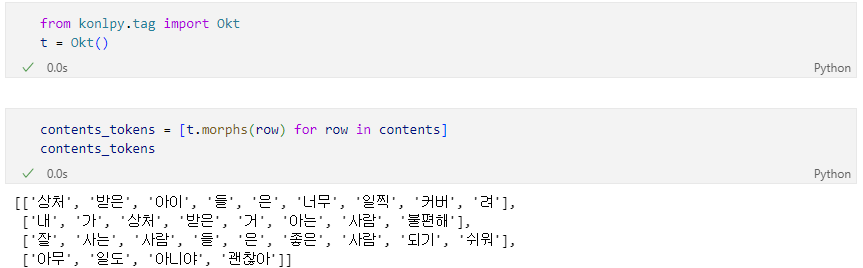
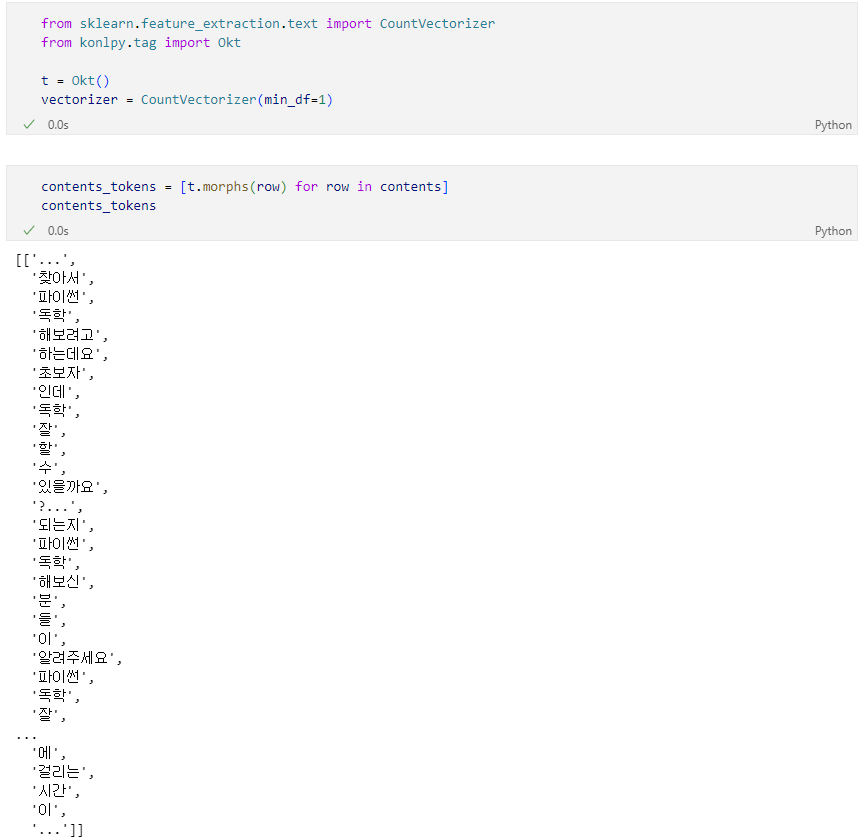
형태소 분석
형태소 분석 결과를 다시 하나의 문장으로 합침

벡터라이즈 수행
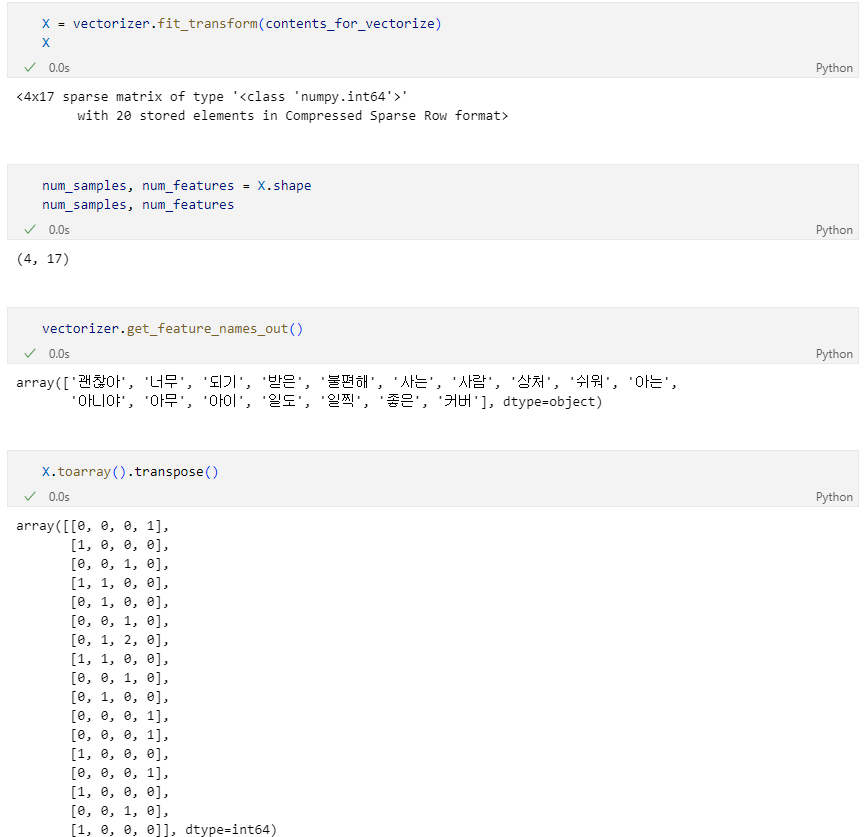
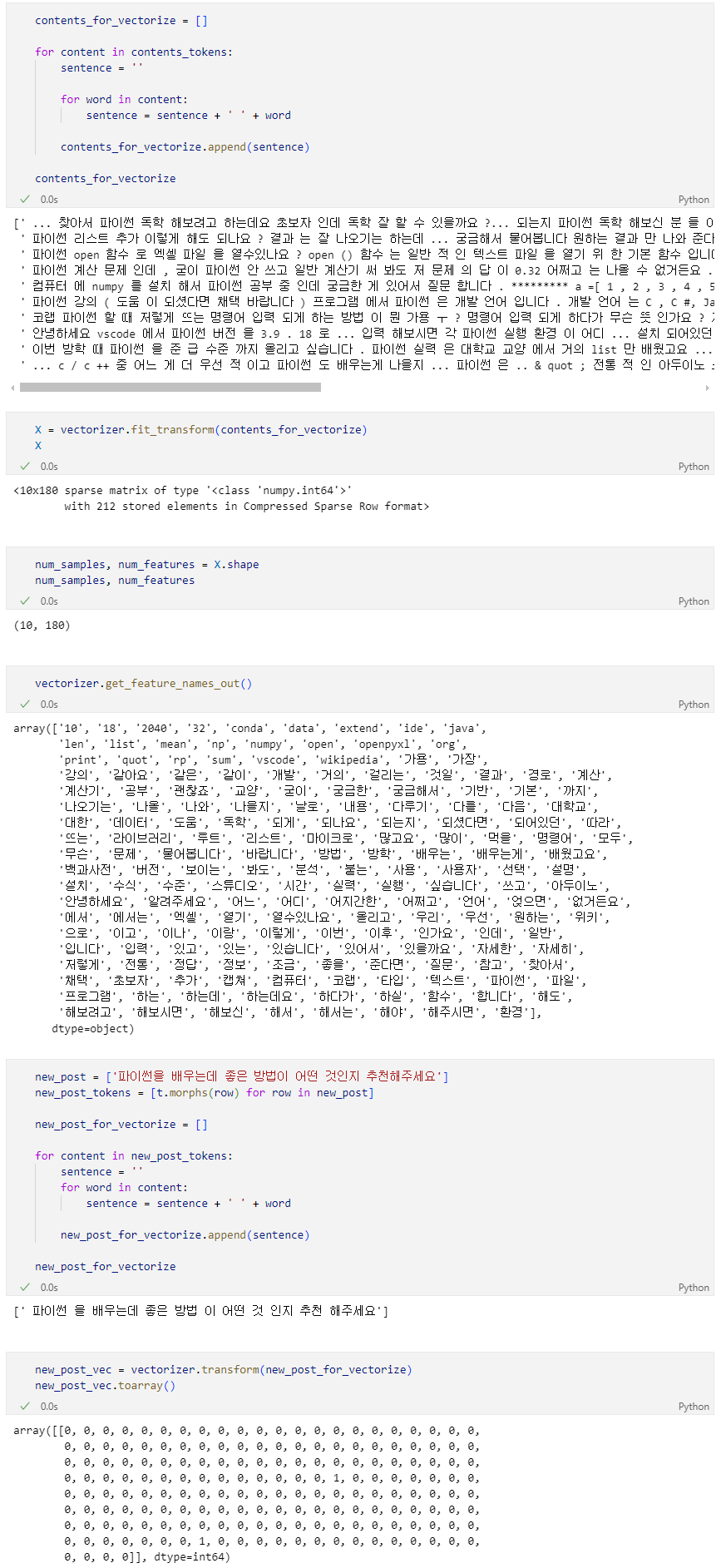
테스트용 문장
새로운 테스트용 문장을 만들고 벡터를 만들었으니 거리를 구할 수 있다.
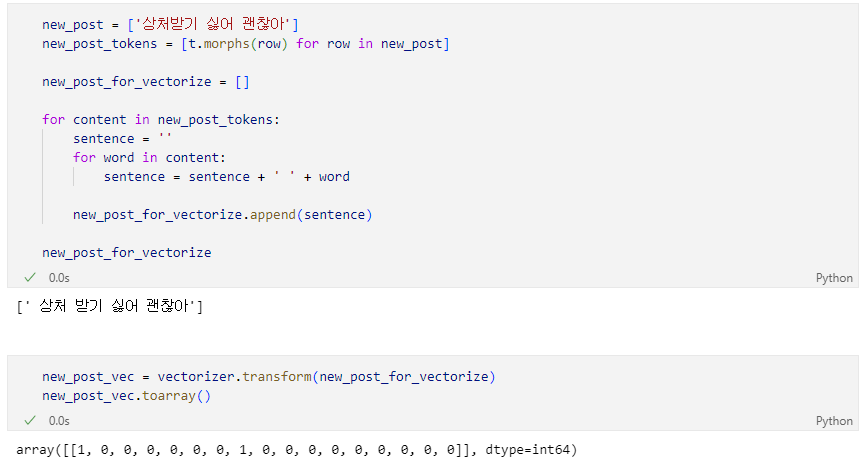
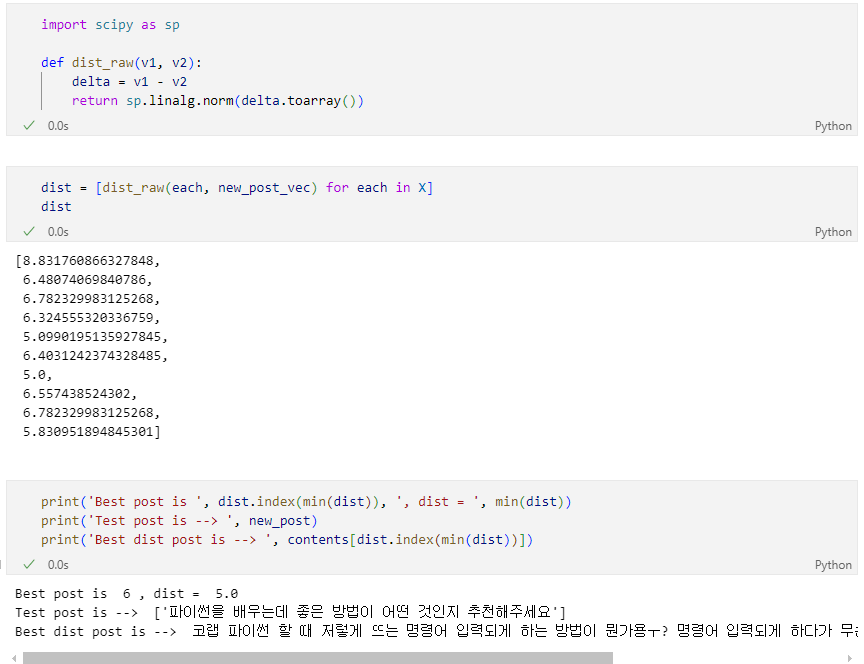
단순 기하학적인 거리를 사용하여 유사한 문장 조회
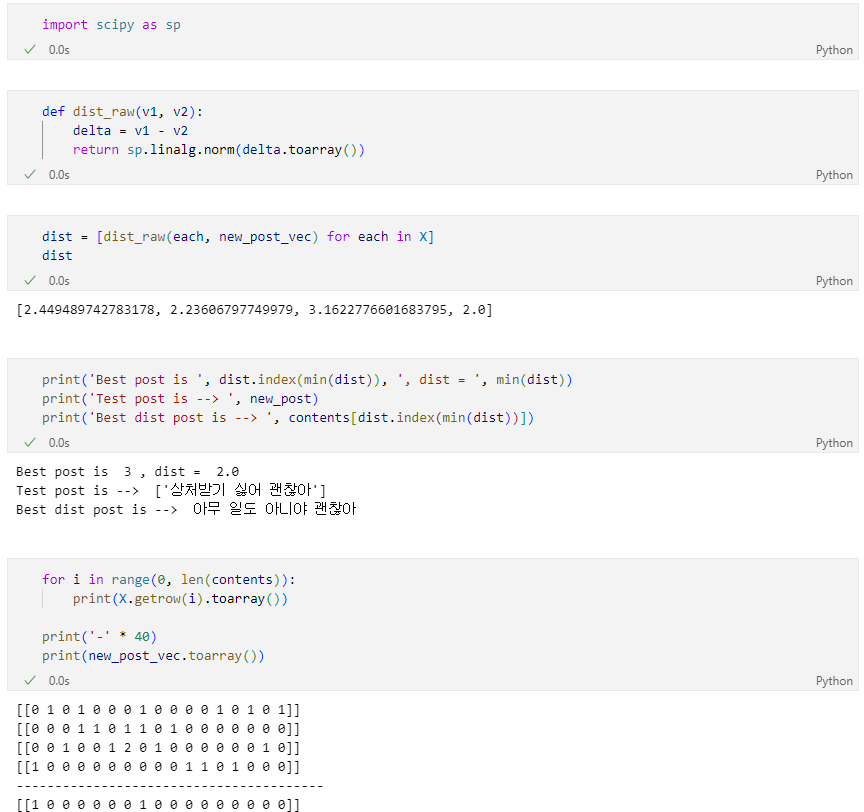
그럼 단순히 단어를 카운트하는 것
더 복잡하게는 형태소를 카운트하는 것
말고는 없을까???
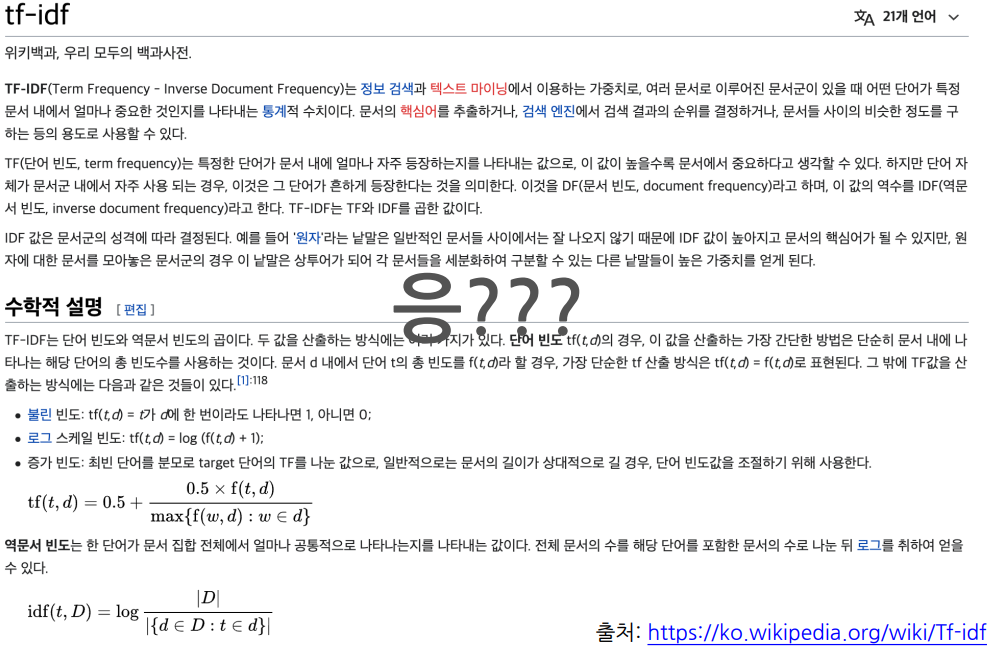
한 문서에서 많이 등장한 단어에 가중치를 주고(TermFreq.)
또 한편으로는 전체 문서에서 많이 나타나는 단어는 중요하지 않게...(InverseDocumentFreq.)
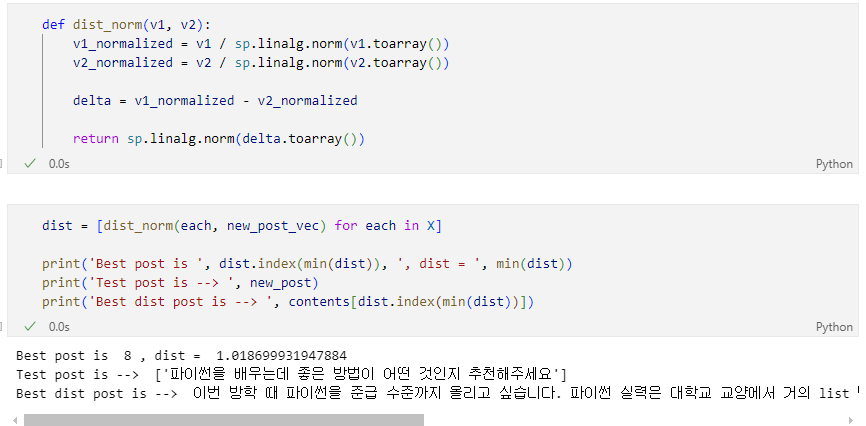
그래서 나타나는 개념 TF-IDF
TF-IDF
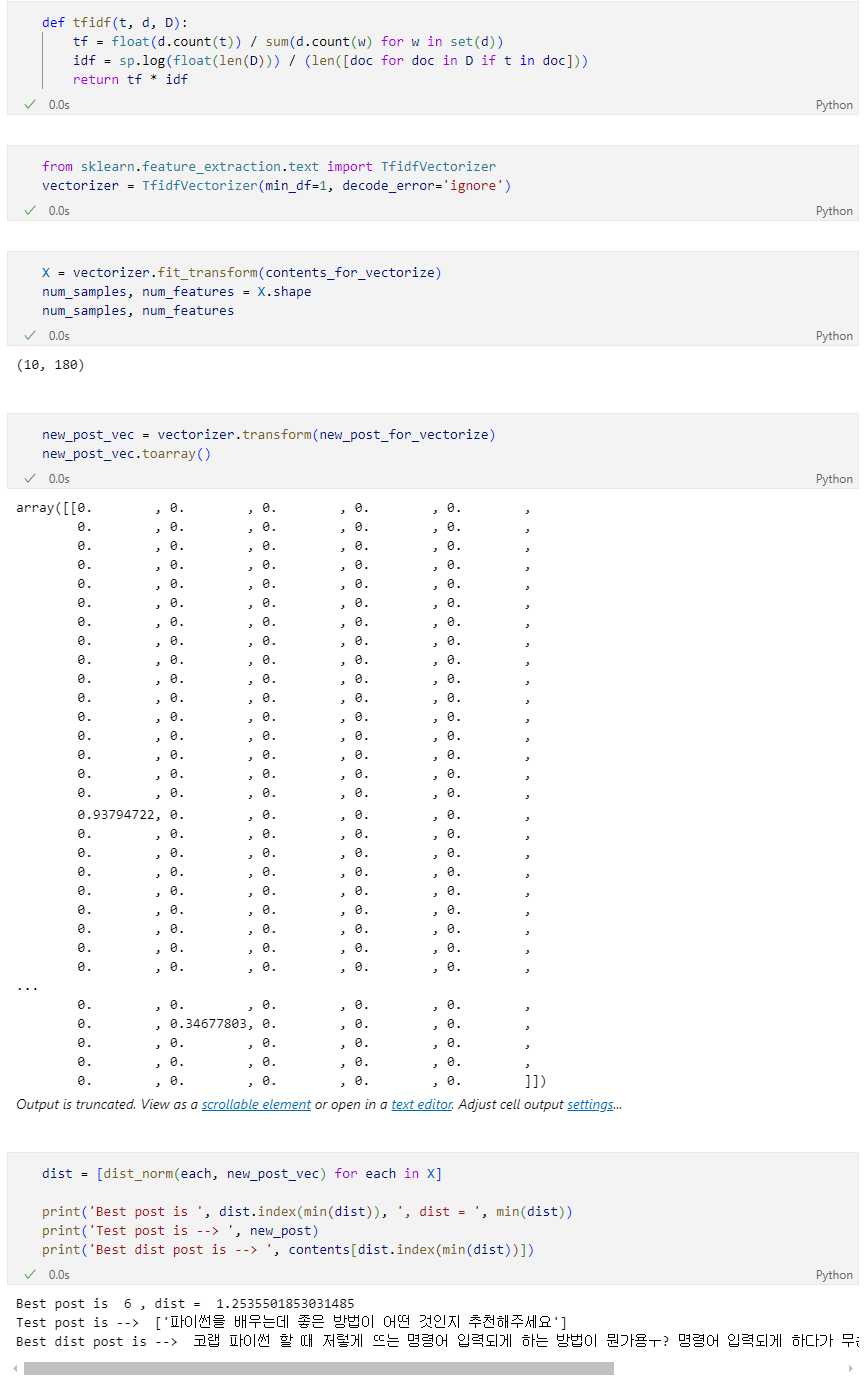
TF-IDF를 이용한 유사 문장 조회
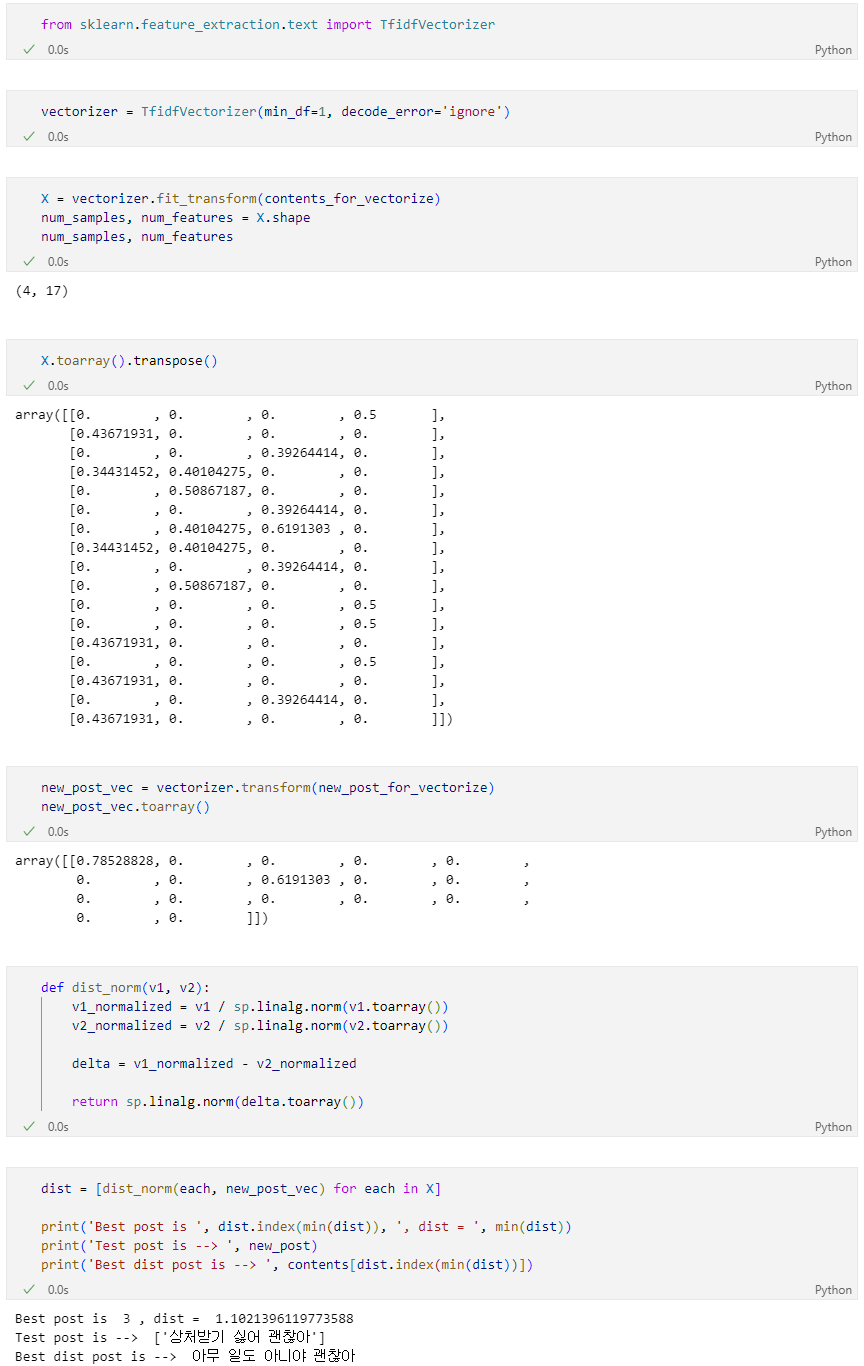
네이버 지식인 검색 결과에서 유사한 문장 찾기
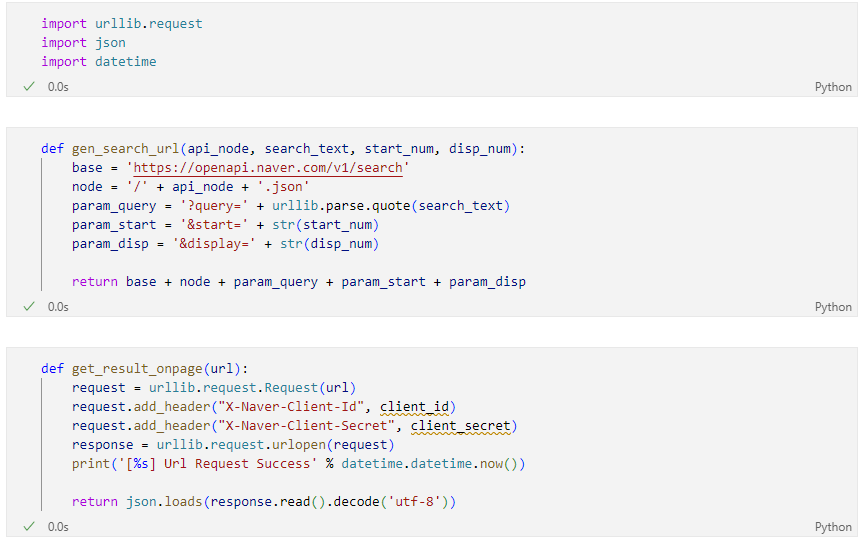
NAVER API 함수
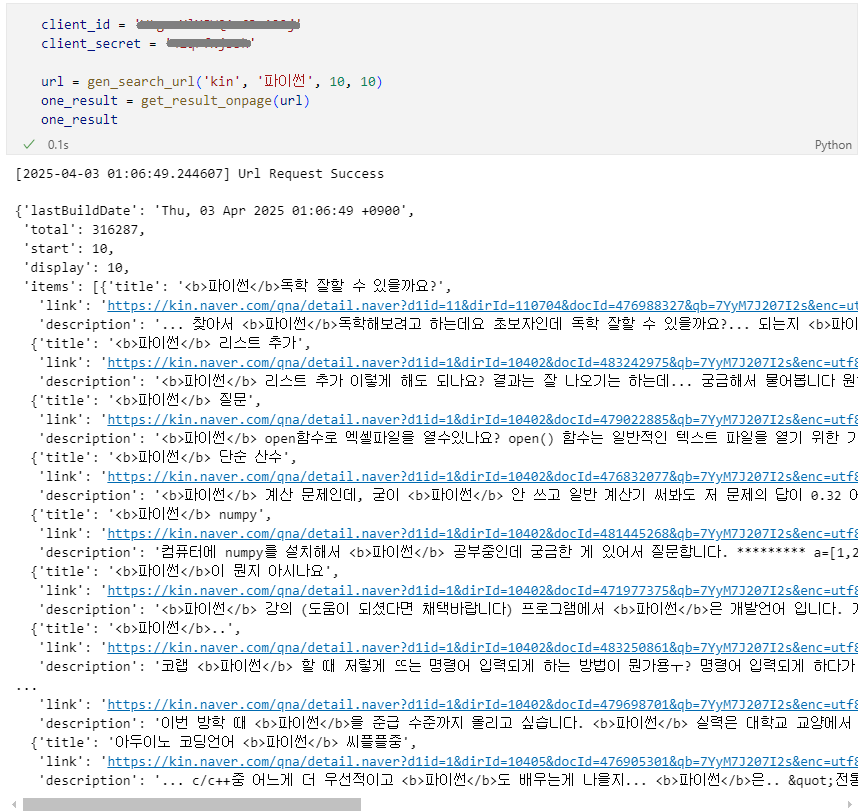
문장 수집
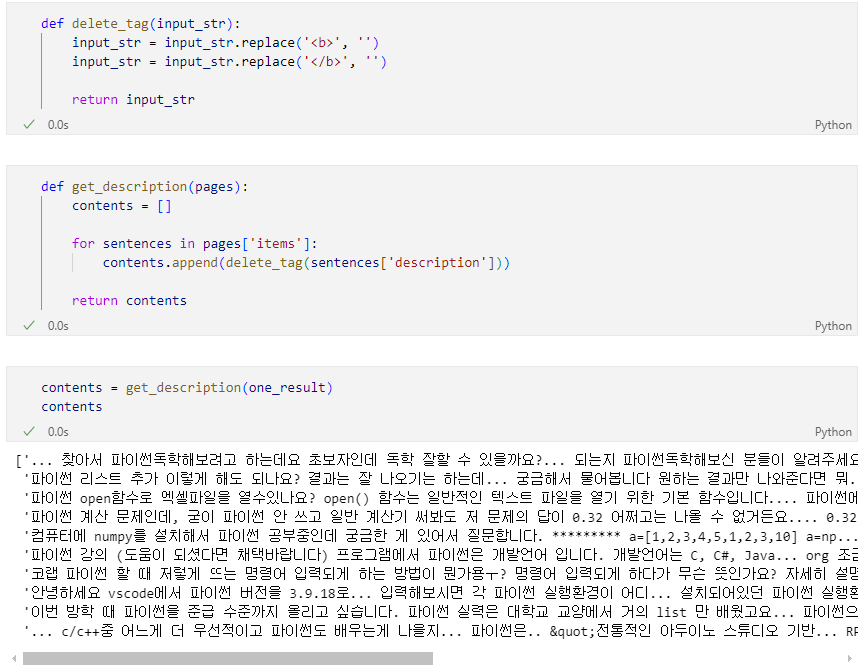
태그 제거 함수 적용 후 list 변환
형태소 분석
vectorize
유클리드 거리
Normalize
TF-IDF