
데이터 다루기
Tensorboard
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
np.random.seed(7777)
tf.random.set_seed(7777)class Cifar10DataLoader():
def __init__(self):
(self.train_x, self.train_y),(self.test_x, self.test_y) = tf.keras.datasets.cifar10.load_data()
self.input_shape = self.train_x.shape[1:]
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
(feature, target) = dataset
scaled_x = np.array([self.scale(x) for x in feature])
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in target])
return scaled_x, ohe_y.squeeze(1)
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))cifar10_loader = Cifar10DataLoader()
train_x, train_y = cifar10_loader.get_train_dataset()
print(train_x.shape, train_x.dtype)
print(train_y.shape, train_y.dtype)
test_x, test_y = cifar10_loader.get_test_dataset()
print(test_x.shape, test_x.dtype)
print(test_y.shape, test_y.dtype)''' (50000, 32, 32, 3) float32
(50000, 10) float32
(10000, 32, 32, 3) float32
(10000, 10) float32from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(16, kernel_size=3, strides=2,
padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(32, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net2)
net1_1 = Conv2D(32, kernel_size=1, padding='same')(net)
net = Add()([net1_1, net3])
net1 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(32, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net2)
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation="softmax")(net)
model = tf.keras.Model(inputs=inputs, outputs=net, name='resnet')
return model
model = build_resnet((32, 32, 3))
model.summary()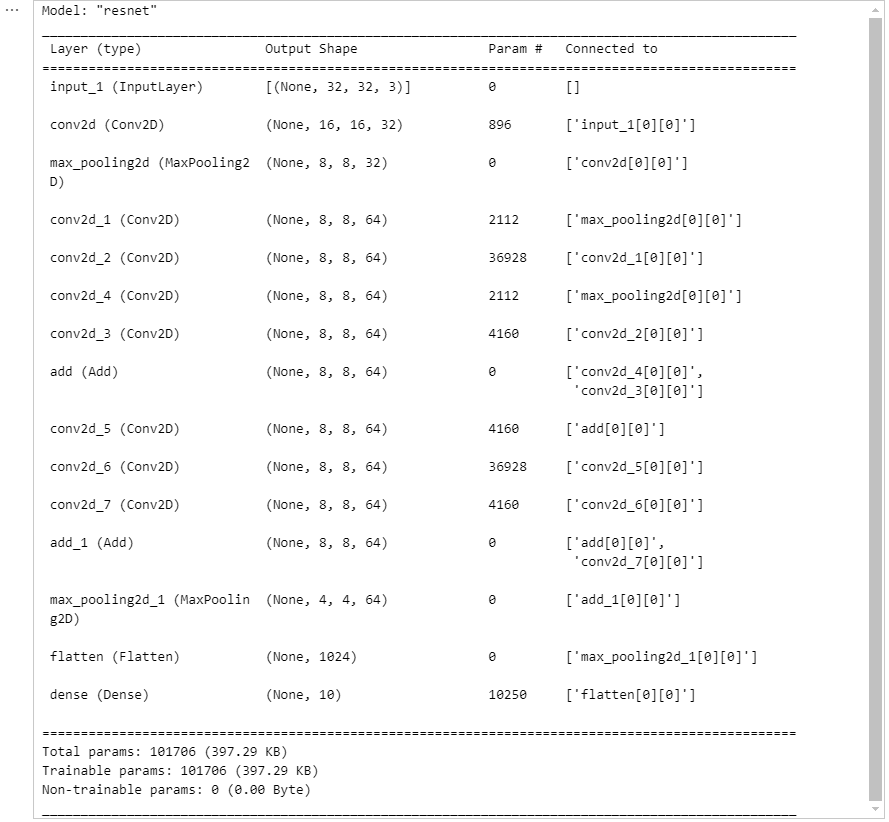
fit 함수로 학습 할 때는 callback 함수로 사용!
-
Jupyter Notebook / JupyterLab에서 실행 중인 경우
%load_ext tensorboard
%tensorboard --logdir logs/fit -
Google Colab에서 실행 중인 경우
%load_ext tensorboard
%tensorboard --logdir logs/fit -
로컬 터미널(예: VSCode, PyCharm)에서 Python 파일을 실행한 경우
tensorboard --logdir logs/fit
http://localhost:6006/
learning_rate = 0.001
opt = tf.keras.optimizers.Adam(learning_rate)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])import datetime
log_dir = "logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir)model.fit(x=train_x,
y=train_y,
epochs=30,
validation_data=(test_x, test_y),
callbacks=[tensorboard_callback])!tensorboard --logdir logs/fithttp://localhost:6006/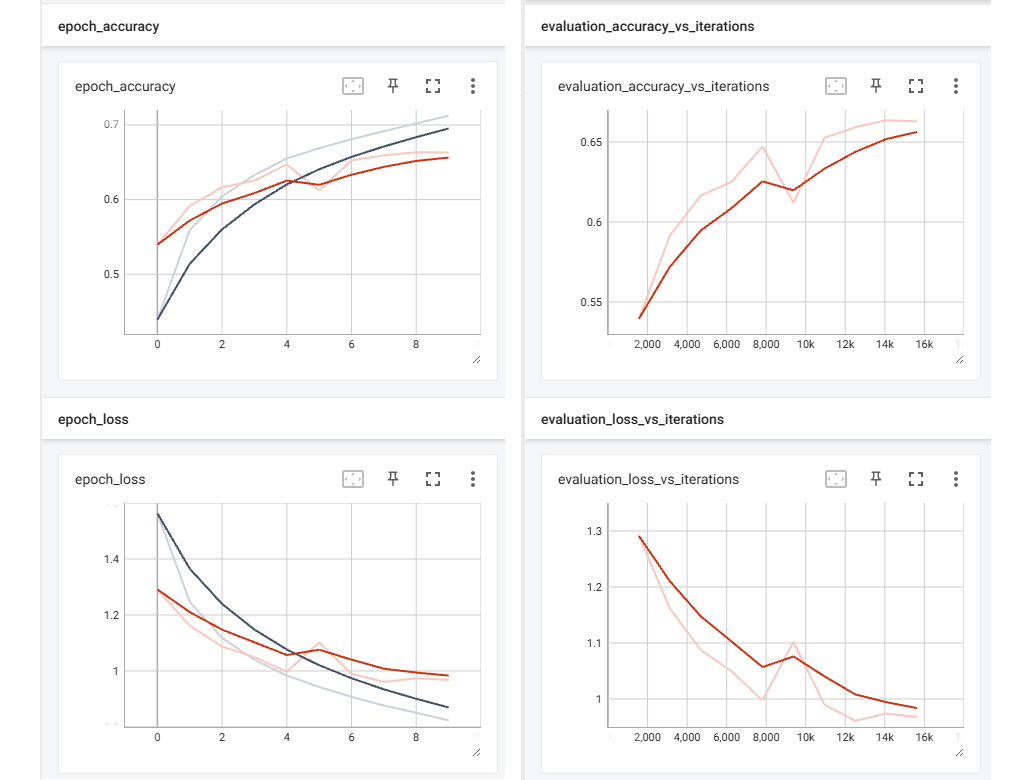
tf.summary 사용하기!
loss_fn = tf.keras.losses.categorical_crossentropy
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.CategoricalAccuracy(name='test_accuracy')
@tf.function
def train_step(x, y) :
with tf.GradientTape() as tape:
pred = model(x)
loss = loss_fn(y, pred)
gradients = tape.gradient(loss, model.trainable_variables)
opt.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(y, pred)
@tf.function
def test_step(x, y) :
pred = model(x)
loss = loss_fn(y, pred)
test_loss(loss)
test_accuracy(y, pred)current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
train_log_dir = 'logs/gradient_tape/' + current_time + '/train'
test_log_dir = 'logs/gradient_tape/' + current_time + '/test'train_summary_writer = tf.summary.create_file_writer(train_log_dir)
test_summary_writer = tf.summary.create_file_writer(test_log_dir)batch_size = 64
num_of_batch_train = train_x.shape[0] // batch_size
num_of_batch_test = test_x.shape[0] // batch_size
for epoch in range(10):
for i in range(num_of_batch_train):
idx = i * batch_size
x, y = train_x[idx:idx+batch_size], train_y[idx:idx+batch_size]
train_step(x, y)
print("Train : {} / {}".format(i, num_of_batch_train), end='\r')
for i in range(num_of_batch_test):
idx = i * batch_size
x, y = test_x[idx:idx+batch_size], test_y[idx:idx+batch_size]
test_step(x, y)
print("Test : {} / {}".format(i, num_of_batch_test), end='\r')
with train_summary_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('acc', train_accuracy.result(), step=epoch)
with test_summary_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('acc', test_accuracy.result(), step=epoch)
fmt = 'epoch {} loss: {}, accuracy: {}, test_loss: {}, test_acc: {}'
print(fmt.format(epoch+1,
train_loss.result(),
train_accuracy.result(),
test_loss.result(),
test_accuracy.result()))
train_loss.reset_states()
test_loss.reset_states()
train_accuracy.reset_states()
test_accuracy.reset_states()!tensorboard --logdir logs/gradient_tapehttp://localhost:6006/Tensorboard에 이미지 데이터 기록
img = train_x[777]img.shapeplt.imshow(img)
plt.show()logdir = "logs/train_data/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
file_writer = tf.summary.create_file_writer(logdir)
for i in np.random.randint(10000, size=10):
img = train_x[i:i+1]
with file_writer.as_default():
tf.summary.image("Training Sample data : {}".format(i), img, step=0)!tensorboard --logdir logs/train_datahttp://localhost:6006/LambdaCallback을 사용하여 Tensorboard에 Confusion Matrix 기록
import io
from sklearn.metrics import confusion_matrix
def plot_to_image(figure):
buf = io.BytesIO()
plt.savefig(buf, format='png')
plt.close(figure)
buf.seek(0)
image = tf.image.decode_png(buf.getvalue(), channels=4)
image = tf.expand_dims(image, 0)
return image
def plot_confusion_matrix(cm, class_names):
figure = plt.figure(figsize=(8, 8))
plt.imshow(cm)
plt.title("Confusion matrix")
plt.colorbar()
tick_marks = np.arange(len(class_names))
threshold = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
color = "white" if cm[i, j] > threshold else "black"
plt.text(j, i, cm[i, j], horizontalalignment="center", color=color)
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
return figure
logdir = "logs/fit/cm/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
file_writer_cm = tf.summary.create_file_writer(logdir)
test_images = test_x[:100]
test_labels = np.argmax(test_y[:100], axis=1)
def log_confusion_matrix(epoch, logs):
test_pred_raw = model.predict(test_images)
test_pred = np.argmax(test_pred_raw, axis=1)
classes = np.arange(10)
cm = confusion_matrix(test_labels, test_pred, labels=classes)
figure = plot_confusion_matrix(cm, class_names=classes)
cm_image = plot_to_image(figure)
with file_writer_cm.as_default():
tf.summary.image("Confusion Matrix", cm_image, step=epoch)cm_callback = tf.keras.callbacks.LambdaCallback(on_epoch_end=log_confusion_matrix)model.fit(x=train_x,
y=train_y,
epochs=5,
batch_size=32,
validation_data=(test_x, test_y),
callbacks=[tensorboard_callback, cm_callback])!tensorboard --logdir logs/fithttp://localhost:6006/Model Save and load
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
np.random.seed(7777)
tf.random.set_seed(7777)class Cifar10DataLoader():
def __init__(self):
(self.train_x, self.train_y),(self.test_x, self.test_y) = tf.keras.datasets.cifar10.load_data()
self.input_shape = self.train_x.shape[1:]
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
(feature, target) = dataset
scaled_x = np.array([self.scale(x) for x in feature])
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in target])
return scaled_x, ohe_y.squeeze(1)
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))cifar10_loader = Cifar10DataLoader()
train_x, train_y = cifar10_loader.get_train_dataset()
print(train_x.shape, train_x.dtype)
print(train_y.shape, train_y.dtype)
test_x, test_y = cifar10_loader.get_test_dataset()
print(test_x.shape, test_x.dtype)
print(test_y.shape, test_y.dtype)''' (50000, 32, 32, 3) float32
(50000, 10) float32
(10000, 32, 32, 3) float32
(10000, 10) float32from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(16, kernel_size=3, strides=2,
padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(32, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net2)
net1_1 = Conv2D(32, kernel_size=1, padding='same')(net)
net = Add()([net1_1, net3])
net1 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(32, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(32, kernel_size=1, padding='same', activation='relu')(net2)
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation="softmax")(net)
model = tf.keras.Model(inputs=inputs, outputs=net, name='resnet')
return model
model = build_resnet((32, 32, 3))
model.summary()
save 함수
model.save("checkpoints/sample/model.h5")model_loaded = tf.keras.models.load_model("checkpoints/sample/model.h5")model_loaded.summary()
save_weights 함수
- weights만 저장 하므로, 저장공간이 절약됨.
model.save_weights("checkpoints/sample/model.h5")new_model = build_resnet((32, 32, 3))
new_model.load_weights("checkpoints/sample/model.h5")
print(model.predict(test_x[:1]))
print(new_model.predict(test_x[:1]))''' [[0.09017159 0.06410073 0.22711207 0.12623343 0.10788547 0.07929002
0.11802228 0.08427411 0.0400762 0.06283402]]
[[0.09017159 0.06410073 0.22711207 0.12623343 0.10788547 0.07929002
0.11802228 0.08427411 0.0400762 0.06283402]]Callbacks 함수 사용하기
learning_rate = 0.03
opt = tf.keras.optimizers.Adam(learning_rate)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])save_path = 'checkpoints/{epoch:02d}-{val_loss:.2f}.h5'
checkpoint = tf.keras.callbacks.ModelCheckpoint(save_path,
monitor='val_accuracy',
save_best_only=True)model.fit(x=train_x,
y=train_y,
epochs=1,
validation_data=(test_x, test_y),
callbacks=[checkpoint])''' 1563/1563 [==============================] - 22s 14ms/step - loss: 2.3402 - accuracy: 0.1001 - val_loss: 2.3232 - val_accuracy: 0.1000
''' <keras.callbacks.History at 0x1a43df3d0>pb 형식으로 저장 하기
- 모델을 protoBuffer 형식으로 저장
save_path = 'checkpoints/{epoch:02d}-{val_loss:.2f}'
checkpoint = tf.keras.callbacks.ModelCheckpoint(save_path,
monitor='val_accuracy',
save_best_only=True)model.fit(x=train_x,
y=train_y,
epochs=1,
validation_data=(test_x, test_y),
callbacks=[checkpoint])''' 1561/1563 [============================>.] - ETA: 0s - loss: 2.3414 - accuracy: 0.0992INFO:tensorflow:Assets written to: checkpoints/01-2.32/assets
1563/1563 [==============================] - 26s 17ms/step - loss: 2.3414 - accuracy: 0.0992 - val_loss: 2.3222 - val_accuracy: 0.1000
/usr/local/lib/python3.9/site-packages/keras/engine/functional.py:1410: CustomMaskWarning: Custom mask layers require a config and must override get_config. When loading, the custom mask layer must be passed to the custom_objects argument.
layer_config = serialize_layer_fn(layer)
/usr/local/lib/python3.9/site-packages/keras/saving/saved_model/layer_serialization.py:112: CustomMaskWarning: Custom mask layers require a config and must override get_config. When loading, the custom mask layer must be passed to the custom_objects argument.
return generic_utils.serialize_keras_object(obj)
''' <keras.callbacks.History at 0x1a528b040>model = tf.saved_model.load("checkpoints/01-2.32")model(test_x[:1])''' <tf.Tensor: shape=(1, 10), dtype=float32, numpy=
array([[0.10252066, 0.11283123, 0.09969856, 0.08417574, 0.10775247,
0.0733155 , 0.124279 , 0.12868522, 0.06748725, 0.09925438]],
dtype=float32)>tf.data
import os
from glob import glob
import tensorflow as tf
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(7777)
tf.random.set_seed(7777)Read a file
- 로컬 환경에 저장되어 있는 파일을 읽어 보겠습니다.
cifar 데이터를 load하지 않고 로컬에서 읽어 온다.
os.listdir("../../datasets/")''' ['cifar', 'mnist_png']os.listdir("../../datasets/cifar/train")''' ['0_frog.png',
'10000_automobile.png',
'10001_frog.png',
'10002_frog.png',
'10003_ship.png',
'10004_ship.png',
'10005_cat.png',
'10006_deer.png',
'10007_frog.png',
'10008_airplane.png',
'10009_frog.png',
'1000_truck.png',
'10010_airplane.png',
'10011_cat.png',
'10012_frog.png',
'10013_frog.png',
'10014_dog.png',
'10015_deer.png',
'10016_ship.png',
'10017_cat.png',
'10018_bird.png',
'10019_frog.png',
'1001_deer.png',
'10020_airplane.png',
'10021_cat.png',
...
'10898_bird.png',
'10899_truck.png',
'1089_horse.png',
'108_bird.png',
...]glob("../../datasets/cifar/train/*.png")''' ['../../datasets/cifar/train\\0_frog.png',
'../../datasets/cifar/train\\10000_automobile.png',
'../../datasets/cifar/train\\10001_frog.png',
'../../datasets/cifar/train\\10002_frog.png',
'../../datasets/cifar/train\\10003_ship.png',
'../../datasets/cifar/train\\10004_ship.png',
'../../datasets/cifar/train\\10005_cat.png',
'../../datasets/cifar/train\\10006_deer.png',
'../../datasets/cifar/train\\10007_frog.png',
'../../datasets/cifar/train\\10008_airplane.png',
'../../datasets/cifar/train\\10009_frog.png',
'../../datasets/cifar/train\\1000_truck.png',
'../../datasets/cifar/train\\10010_airplane.png',
'../../datasets/cifar/train\\10011_cat.png',
'../../datasets/cifar/train\\10012_frog.png',
'../../datasets/cifar/train\\10013_frog.png',
'../../datasets/cifar/train\\10014_dog.png',
'../../datasets/cifar/train\\10015_deer.png',
'../../datasets/cifar/train\\10016_ship.png',
'../../datasets/cifar/train\\10017_cat.png',
'../../datasets/cifar/train\\10018_bird.png',
'../../datasets/cifar/train\\10019_frog.png',
'../../datasets/cifar/train\\1001_deer.png',
'../../datasets/cifar/train\\10020_airplane.png',
'../../datasets/cifar/train\\10021_cat.png',
...
'../../datasets/cifar/train\\10898_bird.png',
'../../datasets/cifar/train\\10899_truck.png',
'../../datasets/cifar/train\\1089_horse.png',
'../../datasets/cifar/train\\108_bird.png',
...]train_img = glob("../../datasets/cifar/train/*.png")TensorFlow 명령어로 Image 읽기
path = train_img[0]
print(path)''' ../../datasets/cifar/train\0_frog.pngtf.io.read_file("../../datasets/cifar/labels.txt")''' <tf.Tensor: shape=(), dtype=string, numpy=b'airplane\nautomobile\nbird\ncat\ndeer\ndog\nfrog\nhorse\nship\ntruck\n'tf.io.read_file(path)''' <tf.Tensor: shape=(), dtype=string, numpy=b'\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x00 \x00\x00\x00 \x08\x02\x00\x00\x00\xfc\x18\xed\xa3\x00\x00\x0csIDATx^c\xb4\xb6\xb3\xff\xf0\xe1\x1d;\xd3?!\xb6\xffr\xc2\\\xa2B\xdc"\x02<l\xcc\xac,\xec\x9c\x0c\xcc,\xef\xde\x7f\xf8\xf5\xe7\xbf\xa0\x00?\xd3\xdf\xdf?\x7f\xfe\xfc\xf1\xe3\x07\x07\'\xc7_\x86\xbf\xdf\xbe\x7f\xe1\x17\xe0c\xf8\xff\xf7\xd7\xcf_\xcc\x0c\xac\xcc\xcc\xcc\xbc<<\xdc\xdc\xdc\xac\xac\x1c\xdf\x7f\xfe\xfa\xcf\xc8\xc4\xc0\xc4\x02\x94\xfa\xf3\x9f\x91\xe5\xea\xb5\xab\x1f\xde\xbc\x11\xe2``\x14\xe6\x10\xf9\xcb\xcb\xc8)\xf6\xf5\xdf\xbb/\x7f\xff\xffgd\xfb\xf6\xe3\xd7\xb7\xef?\x7f\xff\xfd\xf7\x86\x99\x91\x83\xe5\xff\x9f?\xff\x98\x99X\xd8\xd9\xd9\xbf\xfd\xf8\xfa\xe7\xdf/\xc6\x1f\xc2L\xcc\x0c@k9Y8\xbe\xfc\xfc\xf5\xee\xef\x1f..nF&VFfV\x06&\xa6o?~\xff\xf9\xfd\x9b\x99\x85\x9d\x85\x93\x85\x91\x81\x9dA^\x98CA\x9c_LT\x88\x13\xa8\x88\x91\xf1;\xd0\xad\xbf\x7f\xfegdd\xe3\xe4d\xf8\xf3\xff\xff\xbf\x9f\xfcB\\\x7f~\xffgc\xe5\xfc\xfb\x97\x81\x99\x8d\xfd\xe7/\xa0\x01\x8c\\l\xec,\xdc\x9c\x1cl\xec\x7f\x18\xbf2\xfd\xff\xf7\x87\x81\x91\x99\x91\x81\x87\x9b\xeb\xcb\xd7o@\xe3\x99\x18\x19>\x7f\xfa\xc8,\xca\xcb\xce\xc7\xf2GG^X\x94\x9b\x85\x9d\xf9\xff\xef\x9f?\xbe\x7f\xfd\xf1\xe5\xe3\xf7\x7f\xff\x7f\xf3p\xb3srr\xfc\xfa\xf9\x9d\x8d\xf9\xbf\x94(\xff\xbf\xdf\xbf\xff\xfc\xfc\xf5\xfd\xdb\xb7\xbf\x7f\xfepsq\xfd\xff\xfd\x8b\x8d\x85\x99\x8d\x95\xf5\xdf\xff\xbf\x0c@\xd3\x7f\xffbea\x06Z\xf3\xef\xcf\xcf\x7f\x7f\xff020\xfcg\xf8\xf7\xfa\xfd7\x16A\xa0\'\xd8\xd9\xf9\xb99E\xf9X\xff\xfe\x03\xba\x0f\x18\xf2\xcc@?\xfe\xfc\xf7\x9b\x05\x08\xfe\xff\xfb\xfb\xf3\xfb\x7ff\xa6W\xaf>\xfc\xfd\xfd\xf7\xf37\xa0\xf1\xbfx8\xf9\x18~\xfeef\xf8\xc7\xc4\xf8\x9f\x99\x9d\x03\xe8 .V>\x96\xff\xff\x7f\xfc\xf8\xf5\xfd\xf7\x9f\x7f\x0c\xff?|\xf9\xf1\xe1\xdb\xef/\xdf\xfe\xfc\xf8\xcd\xc4"*\xc0\xc1\xcb\xca\xcc\xc1\xc1\xcc\xc4\xfc\x9f\x93\x93\xf3\xf7\x9f\xbf\xff\x18\x18\xff\xff\xff\x05\x8c\xdb\xbf\xbf~\x03\xfd\x01\x8c\xc8\xff,l\x9f\x7f}\xfd\xfb\x97\xf9\xdb\xdf\x7f@\xf9\xcf_\x7f?}\xf7\x95\x95\xe9\x1f\xdf\x17\xc6\xdf/\xde|\xff\xf8MNDELL\x86\x91\xf7\xe3\xcf\xf7o\xbf|\xf9\xfa\xf1\xf3\x8f7\x1f\xbf?x\xfc\xf1/3\x0b\xb3\x9d\xae\x94(\x1f\x0b/7;\x0b\xe3?\x90%\x7f\xff\x02\xc3\x88\xf1\xff?^n>>\x1e\xce_?\xbe\xb0\xb1s\x01-{\xfc\xe2\xdd\xb3\xb7?\xbf\x7f\xfe-\xc8\xc0\xc4\xf6\xff\xef\xe3\xb7\x9f\xde}\xfd\xf9\xfe\xe3\x97\x7f\xff\xfe\x9bj\x1a\xfd\xfe\xc8\xcc\xc1\xc2\xc0\xc7\xff\xef\xd7\xaf\x1f\xdf\xbe\x03\x93\xc5\x7f~>~\tI\x116.Nfg\x03Y\xb6\x7f\xdf9\xb98\x81i\xe0\xf7\x1f\x86\xdf\x7f\xfe\xf0\xf1\xf2p\xb0\xb3\xffg`\xfa\xff\xff7\x1b;\xdb\xdb\x8f\x7f\xef>|\xff\xfc\xdd\xafw_\x18\xf9\x19\x98\xe2m\x8d\x9c\x0c\x94\xbf\xfc\xfa\xff\xf2\xc3\xb7\xff\x0c\x7f\xb99\xd9\xf8X\xd8\xbe}\xf8\xc0\xc5\xf5\x93\x83\x0b\x18\xc2\xff\x7f\xfc\xfe\x05L\xa5\x8c\x0c\xff\xe4e%\xd8X\x99\x98\x03\xacu\x18~}gfe\xff\xf1\xf3\xcf\xd7_\xc0\x84\xc0\xf8\x0f\x98j\xfe\xfd\xff\xfe\xfb\x17\x17/\xf7\x1f\x06\xe6\xcb7\x9e\x01\xed\xf8\xc7\xc2\xfc\x9f\x85Y\x86\xf3\x9f\x9b\n\x1f70\xaa\xff\t~\xfc\xc9\xf4\x1b\x18\x90\x7f\xfe<\x7f\xfd\xf6\xfd\x97\xf7L\x9c\xbf\xd9\xb8\xb9\xff31\xb1\xb22rq\xb2\xb3\xb213\xff\xff%\xca\xcf\xcd"("*\xc8\xc3\t\x14\xff\xf0\xe9\xfd\xef\xaf_\x98\xfe\x02\xe3\xe0\xdf\x7fV\x16\x1e\x1e\x8e\xdf\x0c\x1c\xd7\xef\xdd\xfa\xfa\xf3+\x07\x07;\x07\x1b\x0b\'7\x97 \xf3\x9f\xb3w^\xfe\xf9\xc5\xf2\x93_BT\x90\x83\x91\x81\xef\xf7\x9f\x1f\xdf~}\xff\xfa\xed\xff\xaf?\x7f\x18\x7f\xffb`d`\x05F=\x130\xa3\xb2\xfc\xf9\xf9\xf3\xff\xdf\xff,\x0c\xc0\xac\xc1\xca\xca\xc0\xc0\xc0\xce\xc1\xca\xc5\xc0\r\xe4311\xfdf\xf8\xc7\xce\xc9\xff\xe6\xc5\xe7oo\xde+\tq\xfc\xfc\xc1\xc0\xc1\xcd\xa5\xae,\xcd\xf4\xf3\xc7\x1ff\xd6O\x9f\xde\xb30\x7f\xe4e\xe3\x16\x16TVV\x95\xbb\xff\xe8\xf4\x8d[O\xd9X~\xfe\xff\xff\xe5\xcf\x1f\x16&\x166V6\xd6\x7f@\xc0\xc0\xc8\xc8\xc8\xc4\xf2\xfd\xc7o\xc6\xdf\xdf\x19\x18\xfe|\xfd\xfa\xe9\xd7o\xa6?L\x1c_\xbe}\xfe\xf4\xed\xb3\xb4,0\xef~\x96\x17aT\x96b\xfd\xf6\x83QZM\x9f\xed\xff\x8f\xf7\x1f\x7fs\n\x083\xbce\x96\x95\x90\xfc\xf0\xf5\xab\x92\x86*\x9f \x17\x9f\xa0\xe6\xfb\xd7\x9f\xdf\x7f\xfc\xc8\xca\xc6\xcd\xf4\x9f\xfd\xf7\xbf\xbf\xff\xfe1\xfc\xfd\xfd\x07\x98\xd1\xfe\xff\xff\xcf\xf2\x97\xf1\xef\xff\xbf\xc0\xcc\xfa\x9f\x93\x83\x93\x87\x97\xeb\xd9\xeb\xef\xf7\x9f\xbcfa\xfd\xcf\xf6\xf2\xd9\x8f\x97\xafU\xc5X\x9d\x1dT\xef>}\xc7+-*",\xf1\xea\xf5K\x01\x01n\xa6\x7f\xaclL\xcc\xaf^?e\xe1\xf8\xf0\xfa\xc3\xf3\xa7\xcf\xbf\xb0\xb2r\t\xf0\xfd\xfb\xfe\x1dh\x1e\x13#\x13\xe3\xbf\x7f\x7f\x99@\xaeg\xfa\xfb\x9f\x81E@\x80\xe7\x0f\xcb\x9f/_~\xfc\xff\xfd\xf7\xe3\xe7\x8f\x0f\x1f\xbd\xfc\xf2\xe5\x0b\'\x07\xd3\xf3\xfb\x9f\xc49\xd8\xa4\xa5\xe5\x05\xa4\x14Y?\xffc\xe0`\x95\xd17\xe3x\xf1\x94\xf3\xcf\xeb\xbf\x0c?\xbe~\xfd!\xc9%\xfa\xeb\xef?Fn\x1e\x19n)^\x01\x89\xcfo_\xbcz\xf9\xf67#\xeb\x8f_?\x81\t\x90\x9b\x9d\xe3\xd7\xf7/\xc0\xb0b\xf9\xfc\xe1-\xcb\xaf\xcf\xac\xc0\x94\xc5\xcc\xc0\xc2\xcc\xfc\xed\xcbGA^n\x01n\x8e\xef\xef?\x89I\tK\xeb\xd9_y\xf2\xeb\xd6\x9d_V\x92B\x1f>\xfc\x12W\xd6gb\xf8\xf6\xeb\xe7k\x81\xff\xff>\xbdz\xcb\xf9\xeb\xb7\xa4\x90\xd0\x87\xbf\xec\xacz\x82\xdf?<?\xbam\xd3\x93\xc7\xaf\x81\xa5\x07\x03\x03\xe3\xf7\xff\x0c\xbf\x81\xe5\xc1\xef\xdf,\xc0\xe2\xe9\xef\xf7/\xff\x19\x806\xfc\xf9\xcb\xc8\xfc\xfe7\xc3\xa7O\xff\xff\xff\xfc%\xc9\xcfm\xea\xe8(\xa3n\xb1n\xfe<\tn\x1e\xe6_\xdf\x9f\xde\xbb+\xa1\xa4\xc5!\xac\xc2\xfd\xff\xf3\xb7w\xaf8\xff\t\x02\x0b\xa67\x9f\xbf\t\x88*\nK(|\xff\xc2\xc7\xc4\xc7\xf0\x97\xed\x070\x88~\x03\xb3\x02\xd00`\xd0\xffaaa\x04\xe6\x96\xdf\xbf\x19\x99\x98X\x98\x18\x80\x89\x9f\xf1\x1f\x83\x900\x97\x04\xd7\x1f#\x135M+\x8b\xf7\xaf\xbe\xb0\xff\xf9\xa8$#\xf3\x8f\xf1\x9f\x84\x98\xe8\x9f\x1f\x7f\xbe}\x00%\xfe\xdf\xdfY\xfe2\xf0\xdc}\xfa\xe4\xf2\x953V\x16\xbf\x84%\x84?}~\x05L\x85"\n\xdc\xff\x98\x98\xfe\xfe\xfa\x0b,\x16?\xbe\xfe\xf0\xf33\x17\x0b\xb0p\xf9\xfe\xf3\x1f\x1b7\x0f\x0b\x0b+3\xd3/\x15\tA\x0eN&\x05yY}\x1bGIu\xbd\x0b\xc7\xe7\xcb\xc9\nJh\xeb\xb2\x89*\xb3p\xf1\x7f\xfb\xf1\xe5\xfb\xa7\xcf/\x9f=~\xff\xf2\xc9\xdf\xdf\xdf8y9DDX\x1f?;/.)\xfd\xe7\xdb\x97\xff\xdf\x7f2~}\xff\xf7\xff\xf7\xff\x8c\xffAYM\x82\xf5\x13;#\xd0T\x96\xf7\x9f\xbf\xfd\xfd\xc1\x08,-\x80\xa5\xad\x980\xd7\xe3\xe7\x1f\x94\x8d<dt=\x18\x18\x04\x7f\x7f\xfe\xca\xcf\xcb/\xaaf\xf0\x95E\xe8\xea\xf9\xd3?\xbf\x7f\xfd\xf4\xe9\xc3\x9b\xa7\x8f\x98\xff\xfe\xe2\xe0`\x91V\x94\xd6SS\xf9\xc3\xcc\xcd\xca,\xc0\xca\xf6\x9b\xe5\xc7\x8fo\x0f\x9f\x02]\xfc\x87\x89\xe1\x0b33\x970\xb7\xb8\x940\xcb\xcf\xef?\xb8\x80\x05\x1d\x073+\xd3\x1f`\xa0q\xf20\xfb\x85\xfbYy:\xf3\x89\x88\xbf\xbcw\x9d\x99\xe9\xcf\x87\xcf\x1f_?\xb8\xf9\xec\xf3\xdf\x03\x1b6\xf0p\xb2\xfe\xf8\xf9EB\x9c\x9f\x8f\x97\xfb\xfe\x93\xc7\xbf\x98\xfe\x08I)\xa8\xe9\x1a3\xfce\x7f\xf7\xe1\t0\xbb\xbc\xff\xfe\x87\xf1?\xcb\x8f\xef\xff\xbe\x00\xb3\xc0\x97\x1f\x9a\x02\x0c,\xff\xfe\xffb\xf8\xf7\x97\xf1\xcf\xbf?\xff\x7f32\xfe\xe7`\xe7306fge\xbdv\xe1\xfc\xfbgw\x81\xd5\xf0\xe7\xf7\xef\x1e\xdf\xb9\xf6\xe5?\'\xeb\xdf\x1f<,\xcc|\x1c\xdc\xa2\x82\xfc\xcf_\xbe\x00\xd6\x88\xdf>\x7fy|\xff\x11\x03\xc3\xd5/_>\x83\xeaTv\xb1\xb7\x7f\xf8\x80u\x14\x17/\'\'\x0b\xfb\xe7o\x9f\x80\xa6\xb200\xfc\xfb\x07,\\X\xb9\xfe\xfe\xf9\xfb\x8b\xe1\x8f8\xbf\xe0\xceM[\x84\xc4\xaf\x8aI\xca\xfe\xfa\xf6\x91\x95\x95\x9d\x87\x9b\x8f\x85\t\x18\n\xac\x12b\xc2\xdf?\xbf\xe7df\x7f\xfb\xfa\xcd\xef_\x7fy98\x7f}\xf9r\xfb\xfc\x99\xe77n\xfd\xfc\xf3\x1dX\xf3\xff\x05*\x93\xe1f\xe0\xfe\xc5\xc4\xfe\x83\xe3\xdf\x1fA\x06NMmE\x96\x7f\xff\x18\x815\x1f\x07\xcb?\x06P\xfd\xc4\xfd\xef\xd7\xef7o^|y\xfd\x82\xf3\xf7\xa7\x7f\x0c\xccB\x82\xc2\x02R\xa2\x7f\xfe\xfe|\xfa\xec\xc5\x7f\x06`Y\xc9\x02,\xd4\x98\x19Y\xb99\xb8\x80U\x17\xf3\x1fP\xe5\xf4\xf7\xd7G\xa6\x7f\x8c\x9f\xbe\xbd\xff\xc5\xfe\x9dW\xea\xe7W\xce\x0f\x9f\xff\xfd\xfa\xf1\x95I\x98OIDL\x98\x89\x89\x91\x9d\x83\x9d\xf3?\xc3\x1f.N\x0e1a1`\xa5,\xcc\xcb\xc6\xcf\xfe\xe7\xd7\xc7\x97\xbf>\xbf\xf9\xf6\xed3;\x9f\x10\x13\xb7\xb0\xba\x9e\xc9?\x16\xce_\xff\x81F\xb1|\xf9\xf2\xed\xdf_\x066f\x16\x0eV\x96?\x7f\xfe\xdcz\xf2\xfa\xcc\xb5g\x97\xef>\x7f\xf7\xe7\x13\x87\x00\x0b+\x1b\xdb\x97/\x7f\xbe~\xff\xcf\xcd+\xfc\xfd\xdb_&6\x16\xa6_?\x7f\xfe\xfb\xcf\xf6\x8f\x99\xfd\xdb\xef\xef\xcc\xcc\xff\xb888\xb9yE\xd9\xb8\xf8\xc5\xc5D>\xbf\x7f\xfd\xed\xd7oQY\x95o\xff\xd8\xb5M\xad5\rL\x98X8\xbe~\xf9\xf9\xed\xdbw`a\x03\xacU\x9e?}\xf6\xe8\xfe\x8b/\xdf\xbes\xf2\x00\xdbTb\x8c?X\x19\x9fs\x0b\xbe\x12Q\xe3P\x94\x11\x90\xb9s\xed\x05\x8b\xb8(\xd3\xef\xb7o\xbf\xff\xfd\xf7\xf5+0\x08\xfe\x02\xeby>>a`[\x01\x98 9YY\x18~\xb1\x9c9vLI\xfd\xe5\x93\'/\x80\x9e\xe5b\x07\xb6\xb1\x80M\r\xee\xaf_\xbe\x03\xc1\x9f?\xc0\x06\x00\xbb\x95\xa1\x1a\x07/\xdf\x1f\xe6?\xc0\x9c\xf1\xfd\xf1\x0f\xa6\xcf\x1cb\\\xbc\x86j\xdab\x02\xe2g\x9f\xdfg\x91\x93e\xe3g\xe4\xb8\xf3\xf8\xdb\xcb\xd7\xff\x7f\xfde\xe7\xe1a\xf9\xfa\xed\xe3\xdf\x7f_\x80-\x8bw\xaf\xdf~\xfe\x02l\x19|d\xfe\xff\x91\x97G\xf0\xe5\x8bwO\xbe\xfe\xf8\xf7\x9fQ\\T\x98\xf1\xdf\xef\xf7\x1f\xde\xb3s\xb3\x0b\xf0\xf3\xb213\xfd\xfc\xf5\x97\x81\x85\xf5\xebO\xa6__X\x81YYEVBJB\xf8\xf1\x93\x97o_\x7fc\xe1\x13d\xfd\xfe\xfa\x9b\xa0\x183\x037\xd7\x9b\x97?\x7f\xfc\xfa\xc5\xc2\xc6\xf7\x0b\x98t\x7f\x03\x9b)??~\x7f\xcf\xcd\xc9\xfe\xe3\xdb\x8f\xef?\xde\xfc\xfa\xfd\x17(\xf4\xff?\xf3\x97O\xdf\xf8\xf88\xf9\xf8\xf8\xbf\x7f\xff\xf6\xe6\xed{`\x9b\x11X\xd20\xfe\xf9\x0f\xac\xf4\xd89\x18\xd8\xd8\x98\x15T\x14\xbe\x7f\xfb\x7f\xe8\xd0\xb5K\xb7^\xb1\xb0p\xb0p\xf0\xb1\t\xf1\x00\xab\x9e\x9f\xac\x9c\xff\x80\x95\x15\xc3_&`|\xffe\x05\xb6\x88>\xb0q\xb1\xb0\xb2\x00\xabW\xae\x9f\xff\x81\xe9\xeb\x17\xb0A\t,\xbb\xfe\xff\xfa\xf1\xf7\x07\x03+\x0b+\x03\x1b\xfb\x87\xf7\xef\xbf\xff\xfa\rl\xa7\xb2\x00+B`\xed\xcf\xf0\xe7\xe5\x9b\xcf\xef\xbf\xfc\xf9\xfc\xf5\xe3\x9e\x037^~c\x00&\tV\x06f\xa0#~\xb0r\xfe\x07\x16\xe2\xfc\xfc\xff\xbe|\xfa\xfe\xe5\xd3\xcb/\xdf\xfe\xfe\xfe\xf1\x97\x97M\x98\x83\x95\x15X\xbb\xb2\xb00\xb111\xb0\xb23\x03kA.\x1e`\xbd\xc8\xf0\xe7\xef\x1f6N\x16>\x01\xaew\xef>\x7f\xfe\xff\x8fOH\xf8\xdb\x9f_\xb7\x1f\xbc\xbdq\xf9\xb1\xb8\x10\x9f\xb8\x0c\x17\x03\xd3?\x11~^\x96\'\x0f\x19~~\xe0\xe0\x15\xfd\xc3\xc1\xf9\x9b\x9f\x87AH\x88\x05\xd8\xb2\xfc\xf0\xe1\xdb\xfb\xb7l\xef\xdf20\xffc\x0662\xfe\x02\x9b#\xc0J\nX\xcc312\xb3\xb0|\xff\xcb\xf4\xff\x0f\x03\xeb\xbf\xdf\x7f\xbe\xbd\xfb\x0bL\x89,\xac\x1f\xbe|\x03\xc6\xc2\xbbO\xdf\x1f\xdcy\xfb\xe1\xedW`#M\x82_BS^\xfa\xd3w\x06\x96\xbf\xac"\xbf\xd9L~\xfe\xfb\xc9\xf4\xe7\r\x07?\xa3\x80(\x87 \xb0\x84\xf9\xf6\xef\xc3;\xce\x0fo\x98\xbf\x7fe\x01:\x14\x98\xbc\xfe\xfd\xf9\x07\x8c\x076`\x00\xb30\x7f\xfe\xf1\xef\xfb\x97\x1f\xac\xff\x7f\xf12\xf1\xfec\xfa\x04\xacT\xd8\xb9\xffs\xb0\xb2\x0b\xb0\xfdRb\x10\xd0\xd5\xe7V\xd7\xd3WPQ1\xb3\xf8\xf6\xe4\xd9\x17\x009\xb7\xe5\x9e\xe3\xffx\xcd\x00\x00\x00\x00IEND\xaeB`\x82'>tf.io.decode_image(tf.io.read_file(path))''' <tf.Tensor: shape=(32, 32, 3), dtype=uint8, numpy=
array([[[ 59, 62, 63],
[ 43, 46, 45],
[ 50, 48, 43],
...,
[158, 132, 108],
[152, 125, 102],
[148, 124, 103]],
[[ 16, 20, 20],
[ 0, 0, 0],
[ 18, 8, 0],
...,
[123, 88, 55],
[119, 83, 50],
[122, 87, 57]],
[[ 25, 24, 21],
[ 16, 7, 0],
[ 49, 27, 8],
...,
[118, 84, 50],
[120, 84, 50],
[109, 73, 42]],
...
[179, 142, 87],
...,
[216, 184, 140],
[151, 118, 84],
[123, 92, 72]]], dtype=uint8)>gfile = tf.io.read_file(path)
image = tf.io.decode_image(gfile)print(image.shape)
print(image.dtype)''' (32, 32, 3)
<dtype: 'uint8'>plt.imshow(image)
plt.show()
def read_image(path):
gfile = tf.io.read_file(path)
image = tf.io.decode_image(gfile, dtype=tf.float32)
return image만약에, 이미지가 수백만 장 이라면??
imgs = []
for path in train_img:
imgs.append(read_image(path))- 위 코드는 메모리 용량 문제로 실제 사용 X
이럴 때 필요한게 tf.data API!
- 미리 이미지 데이터를 모두 불러오는게 아니라 그 때 그 떄 처리를 하는 것
- 속도도 더 빨라요!
dataset = tf.data.Dataset.from_tensor_slices(train_img)- num_parallel_calls : 병렬처리 수준을 정하는 것
AUTOTUNE으로 해두면 자동으로 정해진다.
AUTOTUNE = tf.data.experimental.AUTOTUNE
dataset = dataset.map(read_image, num_parallel_calls=AUTOTUNE)next(iter(dataset))''' <tf.Tensor: shape=(32, 32, 3), dtype=float32, numpy=
array([[[0.23137255, 0.24313726, 0.24705882],
[0.16862746, 0.18039216, 0.1764706 ],
[0.19607843, 0.1882353 , 0.16862746],
...,
[0.61960787, 0.5176471 , 0.42352942],
[0.59607846, 0.49019608, 0.4 ],
[0.5803922 , 0.4862745 , 0.40392157]],
[[0.06274509, 0.07843138, 0.07843138],
[0. , 0. , 0. ],
[0.07058824, 0.03137255, 0. ],
...,
[0.48235294, 0.34509805, 0.21568628],
[0.46666667, 0.3254902 , 0.19607843],
[0.47843137, 0.34117648, 0.22352941]],
[[0.09803922, 0.09411765, 0.08235294],
[0.06274509, 0.02745098, 0. ],
[0.19215687, 0.10588235, 0.03137255],
...,
[0.4627451 , 0.32941177, 0.19607843],
[0.47058824, 0.32941177, 0.19607843],
[0.42745098, 0.28627452, 0.16470589]],
...
[0.7019608 , 0.5568628 , 0.34117648],
...,
[0.84705883, 0.72156864, 0.54901963],
[0.5921569 , 0.4627451 , 0.32941177],
[0.48235294, 0.36078432, 0.28235295]]], dtype=float32)>dataset = dataset.batch(128)next(iter(dataset)).shape''' TensorShape([128, 32, 32, 3])- 매번 1 batch 씩 미리 불러 메모리를 더 쓰지만, 자원을 더 효율적으로 활용할 수 있음. → 속도 향상
- dataset = dataset.prefetch(AUTOTUNE)
TF가 자동으로(동적으로)할당 한다.
dataset = dataset.prefetch(1)dataset = dataset.shuffle(buffer_size=10)- 여러 Epoch 를 돌 때
dataset = dataset.repeat()ds = tf.data.Dataset.from_tensor_slices([1, 2, 3])
ds = ds.repeat(3)
list(ds.as_numpy_iterator())''' [1, 2, 3, 1, 2, 3, 1, 2, 3]ds = ds.shuffle(buffer_size=100)list(ds.as_numpy_iterator())''' [1, 3, 1, 3, 2, 2, 1, 3, 2]Label도 같이 넘겨주기
train_img[0].split("/")[-1].split(".")[0].split("_")[-1]''' 'frog'tf.io.read_file("../../datasets/cifar/labels.txt").numpy().decode('ascii').strip().split("\n")''' ['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']label_txt = tf.io.read_file("../../datasets/cifar/labels.txt")
label_names = np.array(label_txt.numpy().decode('ascii').strip().split("\n"))
def parse_label(path):
name = path.split("/")[-1].split(".")[0].split("_")[-1]
return np.array(name == label_names, dtype=np.float32)train_y = [parse_label(y) for y in train_img]def read_data(path, label):
img = read_image(path)
return img, labeldataset = tf.data.Dataset.from_tensor_slices((train_img, train_y))
dataset = dataset.map(read_data, num_parallel_calls=AUTOTUNE)
dataset = dataset.prefetch(1)
dataset = dataset.batch(4)
dataset = dataset.shuffle(buffer_size=1)
dataset = dataset.repeat() # 인수를 안넣으면 무한히 반복next(iter(dataset))''' (<tf.Tensor: shape=(4, 32, 32, 3), dtype=float32, numpy=
array([[[[0.23137255, 0.24313726, 0.24705882],
[0.16862746, 0.18039216, 0.1764706 ],
[0.19607843, 0.1882353 , 0.16862746],
...,
[0.61960787, 0.5176471 , 0.42352942],
[0.59607846, 0.49019608, 0.4 ],
[0.5803922 , 0.4862745 , 0.40392157]],
[[0.06274509, 0.07843138, 0.07843138],
[0. , 0. , 0. ],
[0.07058824, 0.03137255, 0. ],
...,
[0.48235294, 0.34509805, 0.21568628],
[0.46666667, 0.3254902 , 0.19607843],
[0.47843137, 0.34117648, 0.22352941]],
[[0.09803922, 0.09411765, 0.08235294],
[0.06274509, 0.02745098, 0. ],
[0.19215687, 0.10588235, 0.03137255],
...,
[0.4627451 , 0.32941177, 0.19607843],
[0.47058824, 0.32941177, 0.19607843],
[0.42745098, 0.28627452, 0.16470589]],
...
<tf.Tensor: shape=(4, 10), dtype=float32, numpy=
array([[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.]], dtype=float32)>)Label parsing 하는 것도 map 함수로 처리 해보겠습니다.
path''' '../../datasets/cifar/train\\0_frog.png'fname = tf.strings.split(path, '_')[-1]
lbl_name = tf.strings.regex_replace(fname, '.png', '')
lbl_name''' <tf.Tensor: shape=(), dtype=string, numpy=b'frog'>onehot = tf.cast(lbl_name == label_names, tf.uint8)
onehot''' <tf.Tensor: shape=(10,), dtype=uint8, numpy=array([0, 0, 0, 0, 0, 0, 1, 0, 0, 0], dtype=uint8)>def get_label(path):
fname = tf.strings.split(path, '_')[-1]
lbl_name = tf.strings.regex_replace(fname, '.png', '')
onehot = tf.cast(lbl_name == label_names, tf.uint8)
return onehotdef load_image_label(path):
gfile = tf.io.read_file(path)
image = tf.io.decode_image(gfile, dtype=tf.float32)
label = get_label(path)
return image, labeldataset = tf.data.Dataset.from_tensor_slices(train_img)
dataset = dataset.map(load_image_label, num_parallel_calls=AUTOTUNE)
dataset = dataset.prefetch(1)
dataset = dataset.batch(4)
dataset = dataset.shuffle(buffer_size=1)
dataset = dataset.repeat()next(iter(dataset))''' (<tf.Tensor: shape=(4, 32, 32, 3), dtype=float32, numpy=
array([[[[0.23137255, 0.24313726, 0.24705882],
[0.16862746, 0.18039216, 0.1764706 ],
[0.19607843, 0.1882353 , 0.16862746],
...,
[0.61960787, 0.5176471 , 0.42352942],
[0.59607846, 0.49019608, 0.4 ],
[0.5803922 , 0.4862745 , 0.40392157]],
[[0.06274509, 0.07843138, 0.07843138],
[0. , 0. , 0. ],
[0.07058824, 0.03137255, 0. ],
...,
[0.48235294, 0.34509805, 0.21568628],
[0.46666667, 0.3254902 , 0.19607843],
[0.47843137, 0.34117648, 0.22352941]],
[[0.09803922, 0.09411765, 0.08235294],
[0.06274509, 0.02745098, 0. ],
[0.19215687, 0.10588235, 0.03137255],
...,
[0.4627451 , 0.32941177, 0.19607843],
[0.47058824, 0.32941177, 0.19607843],
[0.42745098, 0.28627452, 0.16470589]],
...
<tf.Tensor: shape=(4, 10), dtype=uint8, numpy=
array([[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0]], dtype=uint8)>)학습
from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(32, kernel_size=3, strides=2,
padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net1_1 = Conv2D(64, kernel_size=1, padding='same')(net)
net = Add()([net1_1, net3])
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation="softmax")(net)
model = tf.keras.Model(inputs=inputs, outputs=net, name='resnet')
return model
model = build_resnet((32, 32, 3))
model.summary()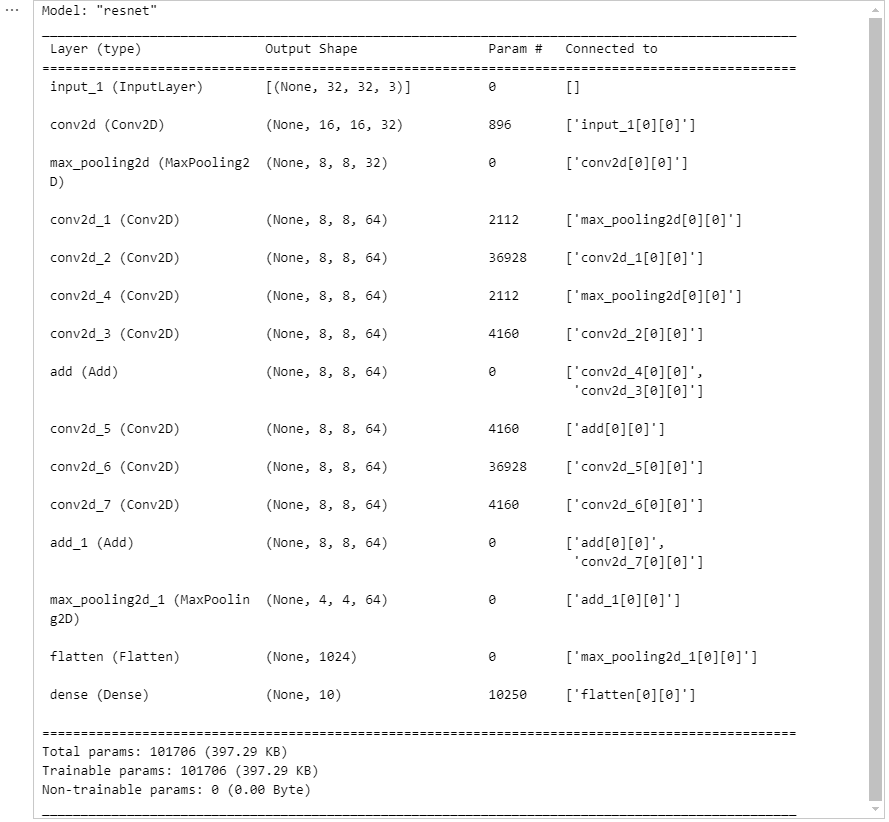
learning_rate = 0.03
opt = tf.keras.optimizers.Adam(learning_rate)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])len(train_img) // 4''' 12500- 무한히 반복하는 데이터셋의 경우는 한 epoch당 몇번의 batch를 사용할지를 정해줘야 함
model.fit(dataset, epochs=5, steps_per_epoch=12500)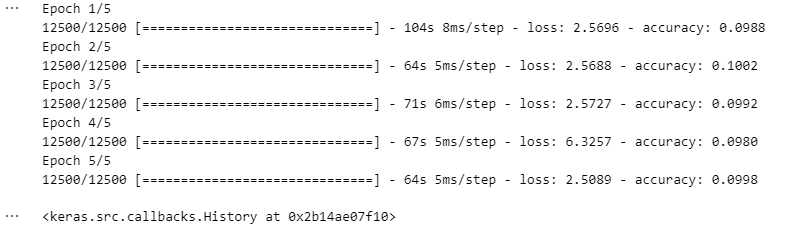
ImageDataGenerator
import os
from glob import glob
import tensorflow as tf
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
%matplotlib inlineImageDataGenerator
- 데이터를 불러오는 동시에 여러가지 전처리를 쉽게 구현 할 수 있는 tf.keras의 기능!
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)flow
- 데이터를 모두 메모리에 불러두고 사용 할 때
class Cifar10DataLoader():
def __init__(self):
# data load
(self.train_x, self.train_y),(self.test_x, self.test_y) = tf.keras.datasets.cifar10.load_data()
self.input_shape = self.train_x.shape[1:]
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
(feature, target) = dataset
# scaling
scaled_x = np.array([self.scale(x) for x in feature])
# label encoding
ohe_y = np.array([tf.keras.utils.to_categorical(
y, num_classes=10) for y in target])
return scaled_x, ohe_y.squeeze(1)
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))cifar10_loader = Cifar10DataLoader()
train_x, train_y = cifar10_loader.get_train_dataset()
print(train_x.shape, train_x.dtype)
print(train_y.shape, train_y.dtype)''' (50000, 32, 32, 3) float32
(50000, 10) float32 - 이코드를 여러번 실행해보면 데이터가 바뀌어서 출력
result = next(iter(datagen.flow((train_x, train_y))))
x, y = result
# print(np.min(result), np.max(result), np.mean(result))
print(np.min(x), np.max(x), np.mean(x))
print(y[0])
plt.imshow(x[0, :, :, 0], 'gray')
plt.show()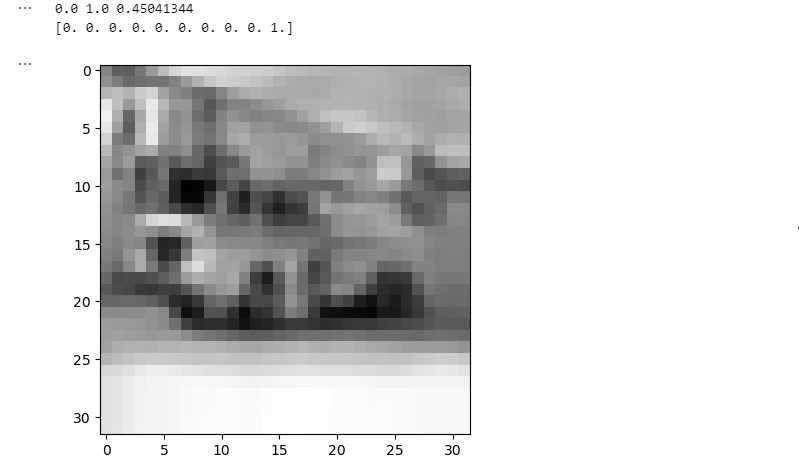
x = next(iter(datagen.flow(train_x[:1])))
# print(np.min(result), np.max(result), np.mean(result))
print(np.min(x), np.max(x), np.mean(x))
print(y[0])
plt.imshow(x[0, :, :, 0], 'gray')
plt.show()
flow_from_directory
train_dir = "../../datasets/mnist_png/training"
input_shape = (28, 28, 1)
batch_size = 32datagen.flow_from_directory(
train_dir,
target_size=input_shape[:2],
batch_size=batch_size,
color_mode='grayscale',#rgb, rgba
)''' Found 60000 images belonging to 10 classes.
''' <keras.src.preprocessing.image.DirectoryIterator at 0x217485fd520>x, y = next(iter(datagen.flow((train_x, train_y))))
print(x.shape)
print(y.shape)''' (32, 32, 32, 3)
(32, 10)flow_from_DataFrame
train_data = pd.read_csv("../../datasets/cifar/train_dataset.csv")datagen.flow_from_dataframe(
train_data,
x_col="path",
y_col="class_name",
target_size=(32, 32),
color_mode="rgb",
class_model="categorical",
batch_size=32
)''' Found 50000 validated image filenames belonging to 10 classes.
''' <keras.src.preprocessing.image.DataFrameIterator at 0x2174a605be0>x, y = next(iter(datagen.flow((train_x, train_y))))
print(x.shape)
print(y.shape)''' (32, 32, 32, 3)
(32, 10)학습
from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(32, kernel_size=3, strides=2,
padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net1_1 = Conv2D(64, kernel_size=1, padding='same')(net)
net = Add()([net1_1, net3])
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation="softmax")(net)
model = tf.keras.Model(inputs=inputs, outputs=net, name='resnet')
return model
model = build_resnet((32, 32, 3))
model.summary()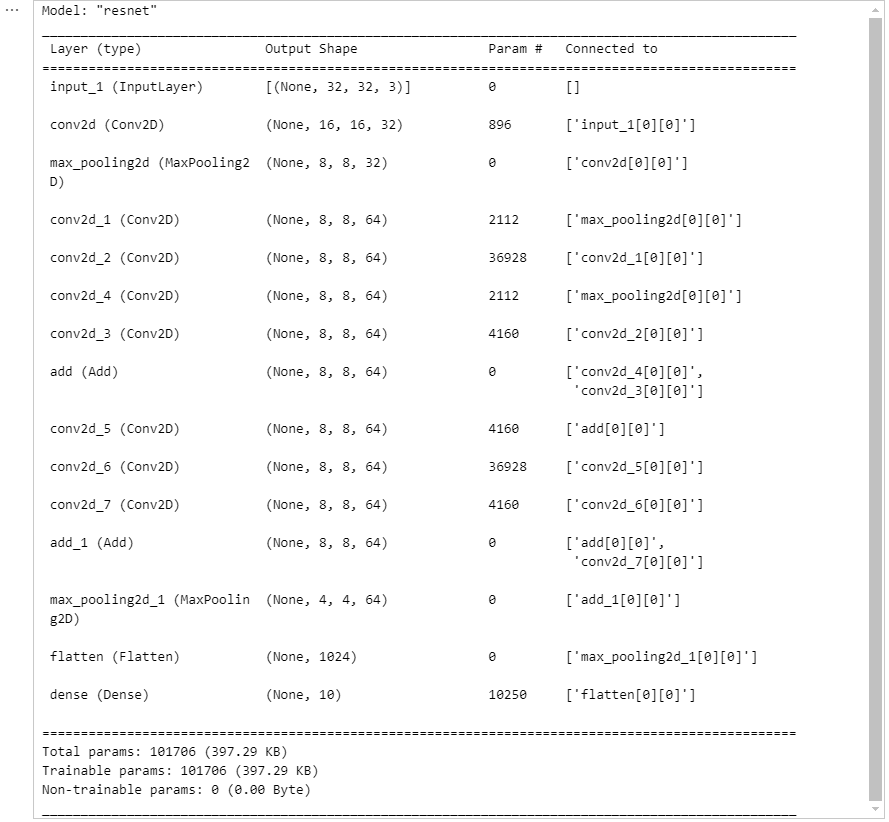
learning_rate = 0.03
opt = tf.keras.optimizers.Adam(learning_rate)
loss = tf.keras.losses.categorical_crossentropy
model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])model.fit(datagen.flow((train_x, train_y)))''' 1563/1563 [==============================] - 36s 22ms/step - loss: 2.5446 - accuracy: 0.1000
''' <keras.src.callbacks.History at 0x217722258e0>