Training
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlinenp.random.seed(7777)
tf.random.set_seed(7777)class Cifar10DataLoader():
def __init__(self):
(self.train_x, self.train_y),(self.test_x, self.test_y) = tf.keras.datasets.cifar10.load_data()
self.input_shape = self.train_x.shape[1:]
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
(feature, target) = dataset
scaled_x = np.array([self.scale(x) for x in feature])
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in target])
return scaled_x, ohe_y.squeeze(1)
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))cifar10_loader = Cifar10DataLoader()
train_x, train_y = cifar10_loader.get_train_dataset()
print(train_x.shape, train_x.dtype)
print(train_y.shape, train_y.dtype)
test_x, test_y = cifar10_loader.get_test_dataset()
print(test_x.shape, test_x.dtype)
print(test_y.shape, test_y.dtype)''' (50000, 32, 32, 3) float32
(50000, 10) float32
(10000, 32, 32, 3) float32
(10000, 10) float32from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(32, kernel_size=3, strides=2, padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net1_1 = Conv2D(64, kernel_size=1, padding='same')(net)
net = Add()([net1_1, net3])
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation="softmax")(net)
model = tf.keras.Model(inputs=inputs, outputs=net, name='resnet')
return model
model = build_resnet((32, 32, 3))
model.summary()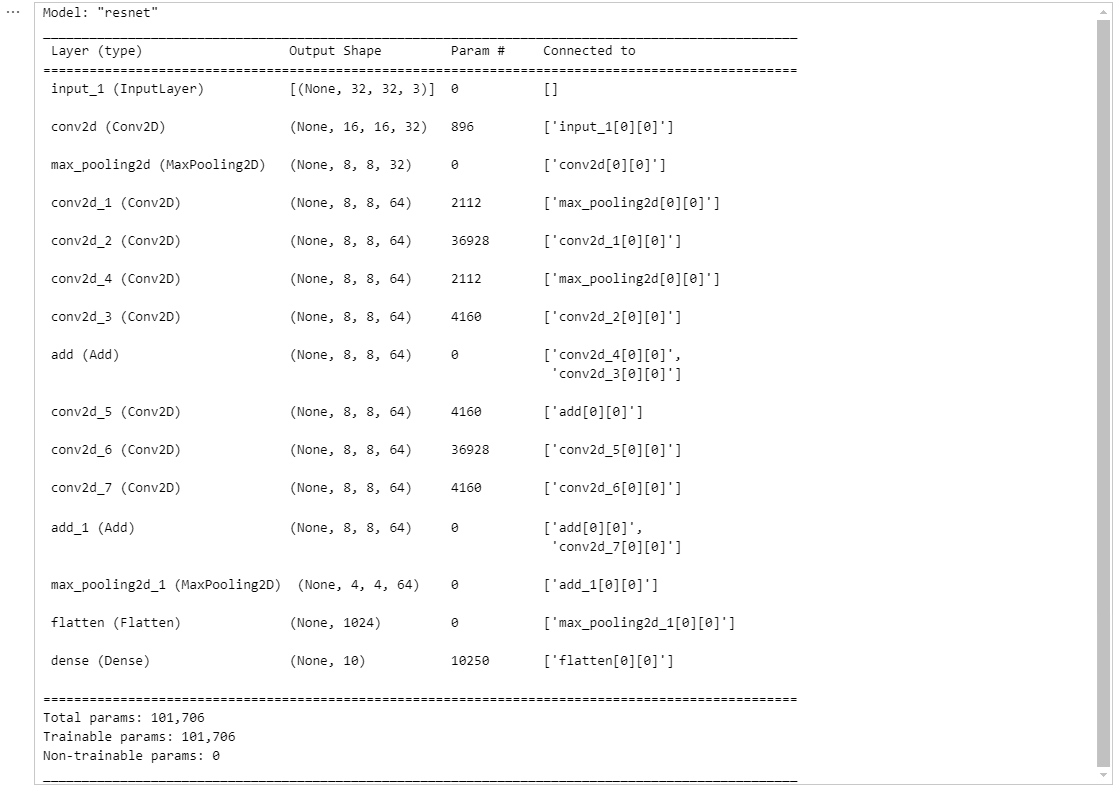
fit 함수 사용
compile의 입력값
- optimizer='rmsprop' : Optimizer
- loss=None : Loss function
- metrics=None : Metrics
- loss_weights=None : loss가 여러 개인 경우 각 로스마다 다르게 중요도를 설정 할 수 있다.
learning_rate = 0.001
opt = tf.keras.optimizers.Adam(learning_rate)
loss = tf.keras.losses.categorical_crossentropymodel.compile(optimizer=opt, loss=loss, metrics=["accuracy"])loss
직접 개발한 loss 사용
def custom_loss(y_true, y_pred):
return tf.reduce_mean(tf.square(y_true - y_pred))model.compile(optimizer=opt, loss=custom_loss, metrics=["accuracy"])여러 개의 Loss 사용(+ loss weights)
model.compile(optimizer=opt, loss=[loss, custom_loss], metrics=["accuracy"])model.compile(optimizer=opt, loss=[loss, custom_loss], loss_weights=[0.7, 0.3], metrics=["accuracy"])텍스트로 불러온 뒤 사용(기존에 구현되어 있는 함수)
loss = "categorical_crossentropy"
model.compile(optimizer=opt, loss=loss, metrics=["accuracy"])Accuracy
여러 개의 Accuracy 사용가능
acc = tf.keras.metrics.Accuracy()
auc = tf.keras.metrics.AUC()
model.compile(optimizer=opt, loss=loss, metrics=[acc, auc])직접 개발한 Accuracy 사용
def custom_metric(y_true, y_pred):
true = tf.argmax(y_true, axis=-1)
pred = tf.argmax(y_pred, axis=-1)
return tf.reduce_sum(tf.cast(tf.equal(y_true, y_pred), tf.int32))model.compile(optimizer=opt, loss=loss, metrics=[custom_metric])model.compile(optimizer=opt, loss=loss, metrics=["accuracy", custom_metric])fit의 입력값
- x=None
- y=None
- batch_size=None
- epochs=1
- verbose='auto' : 학습과정 출력문의 모드
- callbacks=None : Callback 함수
- validation_split=0.0 : 입력데이터의 일정 부분을 Validation 용 데이터로 사용함
- validation_data=None : Validation 용 데이터
- shuffle=True : 입력값을 Epoch 마다 섞는다.
- class_weight=None : 클래스 별로 다른 중요도를 설정한다.
hist = model.fit(train_x,
train_y,
epochs=10,
batch_size=128,
validation_split=0.3,
verbose=1)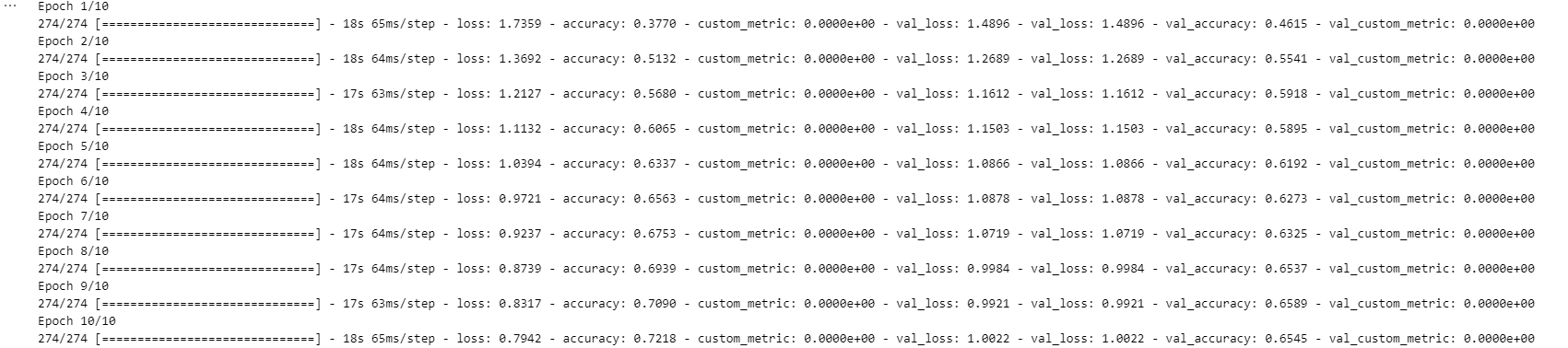
Callback 함수 활용하기
-
Callback 함수를 활용하면, fit() 함수가 돌아가는 와중에도 특정한 주기로 원하는 코드를 실행 시킬 수 있음.
ex> 학습이 진행되면, Learning rate를 점점 줄여서 더 세밀하게 모델의 웨이트가 조정 될 수 있도록 하고 싶다.
def scheduler(epoch, lr):
if epoch > 10:
return lr * (0.9**(epoch - 10))
else:
return lr
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(scheduler)hist = model.fit(train_x,
train_y,
epochs=10,
batch_size=128,
validation_split=0.3,
verbose=1,
callbacks=[lr_scheduler])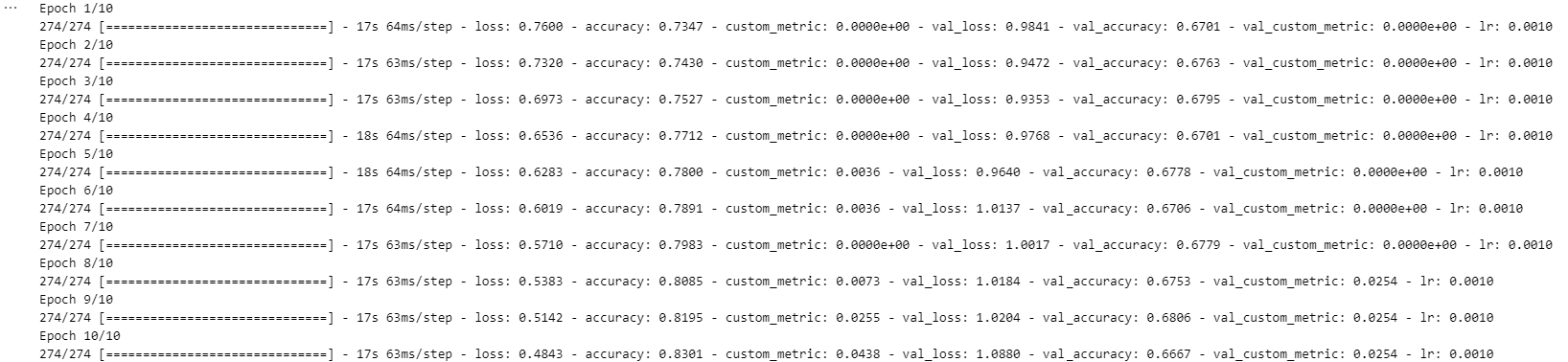
Training Logic
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlinenp.random.seed(7777)
tf.random.set_seed(7777)class Cifar10DataLoader():
def __init__(self):
(self.train_x, self.train_y),(self.test_x, self.test_y) = tf.keras.datasets.cifar10.load_data()
self.input_shape = self.train_x.shape[1:]
def scale(self, x):
return (x / 255.0).astype(np.float32)
def preprocess_dataset(self, dataset):
(feature, target) = dataset
scaled_x = np.array([self.scale(x) for x in feature])
ohe_y = np.array([tf.keras.utils.to_categorical(y, num_classes=10) for y in target])
return scaled_x, ohe_y.squeeze(1)
def get_train_dataset(self):
return self.preprocess_dataset((self.train_x, self.train_y))
def get_test_dataset(self):
return self.preprocess_dataset((self.test_x, self.test_y))cifar10_loader = Cifar10DataLoader()
train_x, train_y = cifar10_loader.get_train_dataset()
print(train_x.shape, train_x.dtype)
print(train_y.shape, train_y.dtype)
test_x, test_y = cifar10_loader.get_test_dataset()
print(test_x.shape, test_x.dtype)
print(test_y.shape, test_y.dtype)''' (50000, 32, 32, 3) float32
(50000, 10) float32
(10000, 32, 32, 3) float32
(10000, 10) float32from tensorflow.keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Add
def build_resnet(input_shape):
inputs = Input(input_shape)
net = Conv2D(32, kernel_size=3, strides=2,
padding='same', activation='relu')(inputs)
net = MaxPool2D()(net)
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net1_1 = Conv2D(64, kernel_size=1, padding='same')(net)
net = Add()([net1_1, net3])
net1 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net)
net2 = Conv2D(64, kernel_size=3, padding='same', activation='relu')(net1)
net3 = Conv2D(64, kernel_size=1, padding='same', activation='relu')(net2)
net = Add()([net, net3])
net = MaxPool2D()(net)
net = Flatten()(net)
net = Dense(10, activation="softmax")(net)
model = tf.keras.Model(inputs=inputs, outputs=net, name='resnet')
return model
model = build_resnet((32, 32, 3))
model.summary()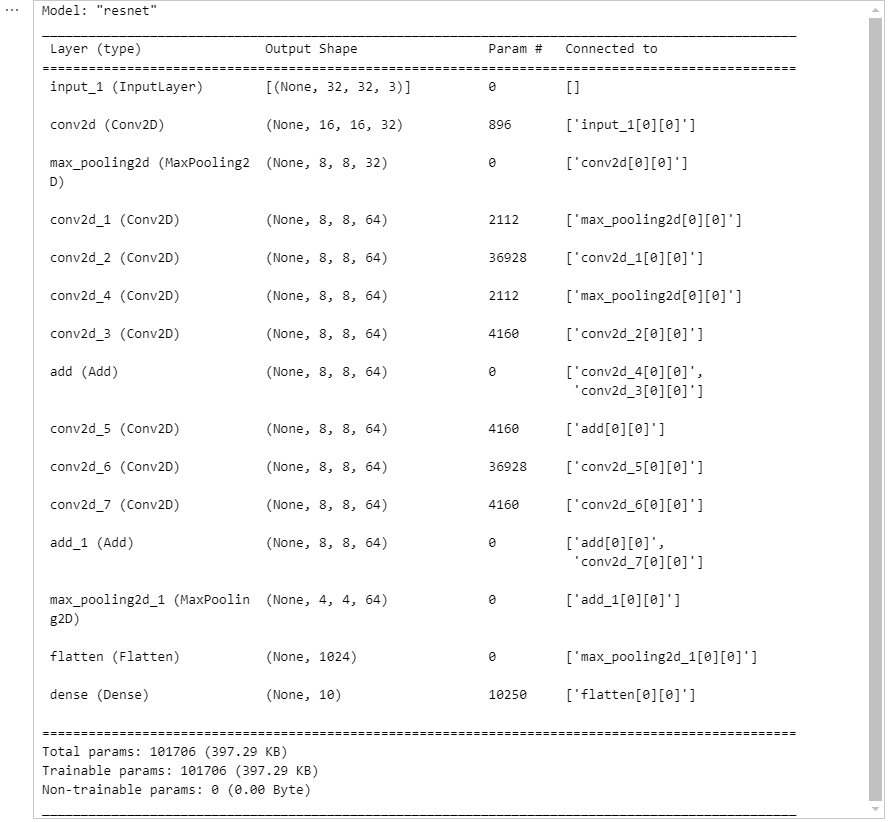
학습하는 과정을 직접 만들어보자!
learning_rate = 0.001
opt = tf.keras.optimizers.Adam(learning_rate)
loss_fn = tf.keras.losses.categorical_crossentropy
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy')def train_step(x, y) :
with tf.GradientTape() as tape:
pred = model(x)
loss = loss_fn(y, pred)
gradients = tape.gradient(loss, model.trainable_variables)
opt.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(y, pred)batch_size = 64
for epoch in range(10):
for i in range(train_x.shape[0] // batch_size):
idx = i * batch_size
x, y = train_x[idx:idx+batch_size], train_y[idx:idx+batch_size]
train_step(x, y)
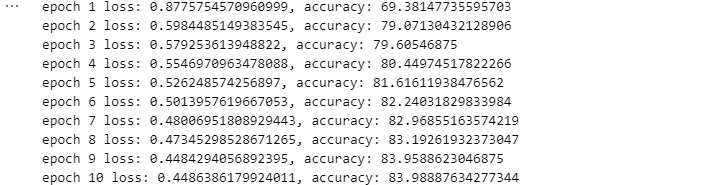
print("\r {} / {}".format(i, train_x.shape[0] // batch_size), end='\r')
fmt = 'epoch {} loss: {}, accuracy: {}'
print(fmt.format(epoch+1,
train_loss.result(),
train_accuracy.result() * 100))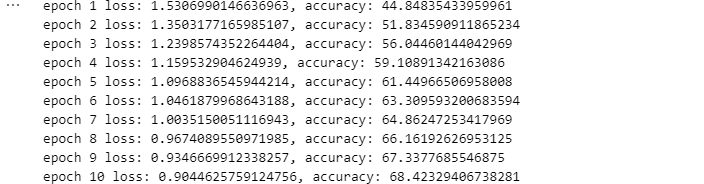
@tf.function
def train_step(x, y) :
with tf.GradientTape() as tape:
pred = model(x)
loss = loss_fn(y, pred)
gradients = tape.gradient(loss, model.trainable_variables)
opt.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(y, pred)batch_size = 64
num_of_batch_train = train_x.shape[0] // batch_size
for epoch in range(10):
for i in range(num_of_batch_train):
idx = i * batch_size
x, y = train_x[idx:idx+batch_size], train_y[idx:idx+batch_size]
train_step(x, y)
print("\r {} / {}".format(i, num_of_batch_train), end='\r')
fmt = 'epoch {} loss: {}, accuracy: {}'
print(fmt.format(epoch+1,
train_loss.result(),
train_accuracy.result() * 100))
# Reset metrics every epoch
train_loss.reset_states()
train_accuracy.reset_states()