통계 분석의 기초
데이터 유형
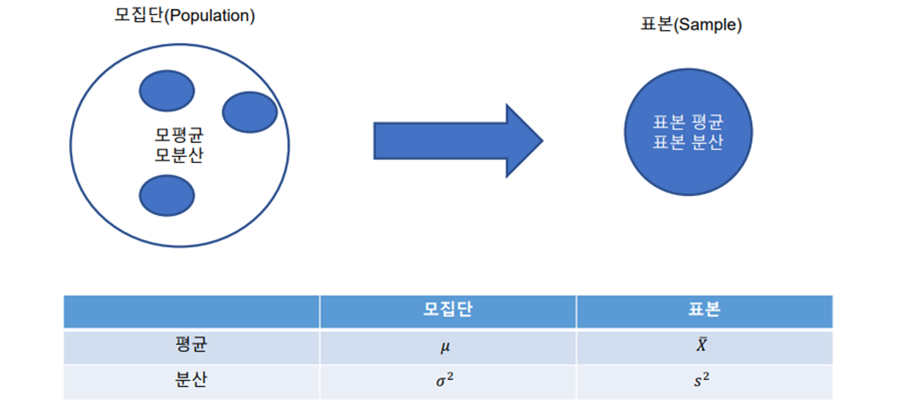
1. 모집단(Population), 표본(Sample)
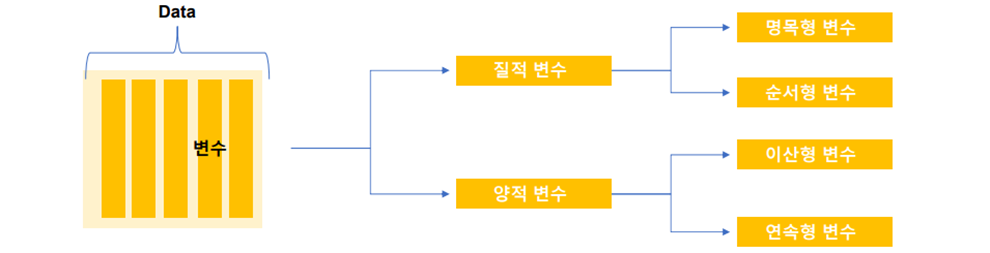
2. 변수(Variable)
- 수학에서의 변수란, 어떤 정해지지 않은 임의의 값을 표현하기 위해 사용된 '기호' 이다. 보통 쉽게 설명하기 위해서 '변하는 숫자' 라는 표현을 자주 쓰고는 한다 (출처: 나무 위키)
- 통계학에서는 조사 목적에 따라 관측된 자료값을 변수라고 함, 해당 변수에 대하여 관측된 값들이 바로 자료(Data)가 됨
질적 자료
- 관측된 데이터가 성별, 주소지(시군구), 업종 등과 같이 몇 개의 범주로 구분하여 표현할 수 있는 데이터를 의미함
- 데이터 입력시 1은 남자, 2는 여자로 표현 가능하나 여기서 숫자의 의미는 없음(순서형 변수: 교육수준, 건강상태)
양적 자료
- 관측된 데이터가 숫자의 형태로 숫자의 크기가 의미를 갖고 있음
- 숫자를 표현할 때는 이산형 데이터와 연속형 데이터로 구분할 수 있음
변수의 유형
통계량
1. 데이터의 기초 통계량
1 ) 기초 통계량
- 통계량(statistic)은 표본으로 산출한 값으로, 기술 통계량이라고도 표현함
- 통계량을 통해 데이터(표본)가 갖는 특성을 이해 할 수 있음
2 ) 중심 경향치
-
표본(데이터)를 이해하기 위해서는 표본의 중심에 대해서 관심을 갖기 때문에 표본의 중심을 설명하는 값을 대표값이라 하며 이를 중심경향치라고 함
-
대표적인 중심 경향치는 평균이며, 중앙값, 최빈값, 절사 평균 등이 있음
(1) 평균(mean)
-
평균은 모집단으로 부터 관측된 n개의 x가 주어 졌을때 아래와 같이 정의됨
-
평균은 표본으로 추출된 표본 평균(sample mean, 로 표기)이라고하며, 모집단의 평균을 모평균이라고 하며 라고 표기함
(2) 중앙값(median)
-
평균과 같이 자주 사용하는 값으로 표본으로 부터 관측치를 크기순으로 나열 했을 때, 가운데 위치하는 값을 의미함
-
관측치가 홀수 일 경우 중앙에 취하는 값이고, 짝수 일 경우 가운데 두개의 값을 산술 평균한 값임
-
이상치가 포함된 데이터에 대해서 사용함
-
관측치를 크기순으로 나열 했을 때, 중앙값 m은
(3) 최빈값(mode)
- 관측치 중에서 가장 많이 관측되는 값
- 옷사이즈와 같이 명목형 데이터의 경우 사용
(4) 분포 형태별 대표값
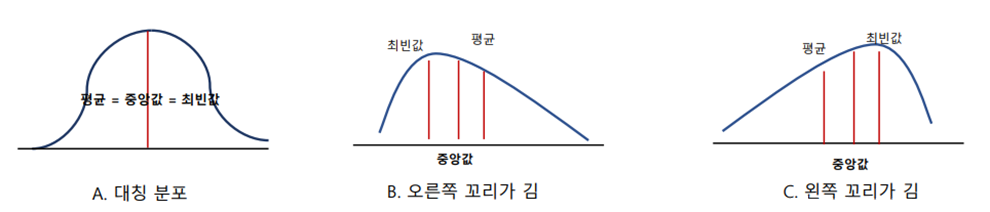
-
3 ) 산포도
-
데이터가 어떻게 흩어져 있는지를 확인하기 위해서는 중심경향치와 함께 산포에 대한 측도를 같이 고려해야 함
-
데이터의 산포도를 나타내는 측도로는 범위, 사분위수, 분산, 표준편차, 변동 계수 등이 있음
(1) 범위(Range)
- 데이터의 최대값과 최소값의 차이를 의미함
(2) 사분위수(quartile)
- 전체 데이터를 오름차순으로 정렬하여 4등분을 하였을 때, 첫 번째를 제1사분위수(Q1), 두 번째를 제2사분위수(Q2), 세 번째를 제3사분위수(Q3)이라고 함
- 사분위수 범위(interquartile range)
IQR = 제 3사분위수(Q3) – 제1사분위수(Q1)
(3) 백분위수(percentile)
- 전체 데이터를 오름차순으로 정렬하여 주어진 비율에 의해 등분한 값을 말하며, 제p백분위수는 p%에 위치한 자료 값을 말함
- 데이터를 오름차수로 배열하고 자료가 n개가 있을 때, 제(100*p) 백분위수는 아래와 같음
1) np가 정수이면, np번째와 (np + 1)번째 자료의 평균
2) np가 정수가 아니면, np보다 큰 최소의 정수를 m이라고 할 때 m번째 자료
(4) 분산(variance)
-
데이터의 분포가 얼마나 흩어져 있는지를 알 수 있는 측도 임
-
데이터의 각각의 값들의 편차 제곱합으로 계산하며 수식은 아래와 같음
표본 분산 :
(5) 표준 편차(standard deviation)
- 분산의 제곱근으로 정의하며 수식은 아래와 같음
표본 표준 편차 :
(6) 모분산 / 모표준편차
-
크기가 n인 모집단의 평균을 라고 할 때 모평균과 모분산은 다음과 같음
모분산 :모표준편차 :
(7) 변동계수(Coefficient of Variation: CV)
- 평균이 다른 두개 이상의 그룹의 표준편차를 비교할 때 사용함
- 변동계수는 표준편차를 평균으로 나누어서 산출하여 단위나 조건에 상관 없이 서로 다른 그룹의 산포를 비교하며 실제 분석에서 자주 사용함
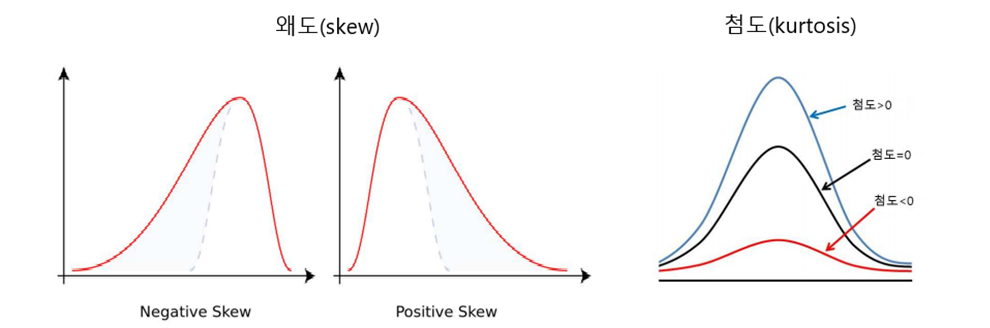
(8) 왜도(skew)
- 자료의 분포가 얼마나 비대칭적인지 표현하는 지표임
- 왜도가 0이면 좌우가 대칭이고, 0에서 클수록 우측꼬리가 길고 0에서 작을수록 좌측 꼬리가 김
(9) 첨도(kurtosis)
- 확률분포의 꼬리가 두꺼운 정도를 나타내는 척도임
- 첨도값(K)이 3에 가까우면 산포도가 정규분포에 가까움
- 첨도값이 3보다 작을 경우에는(K<3) 산포는 정규분포보다 꼬리가 얇은 분포로 판단
- 첨도값이 3보다 큰 양수이면(K>3) 정규분포보다 꼬리가 두꺼운 분포로 판단
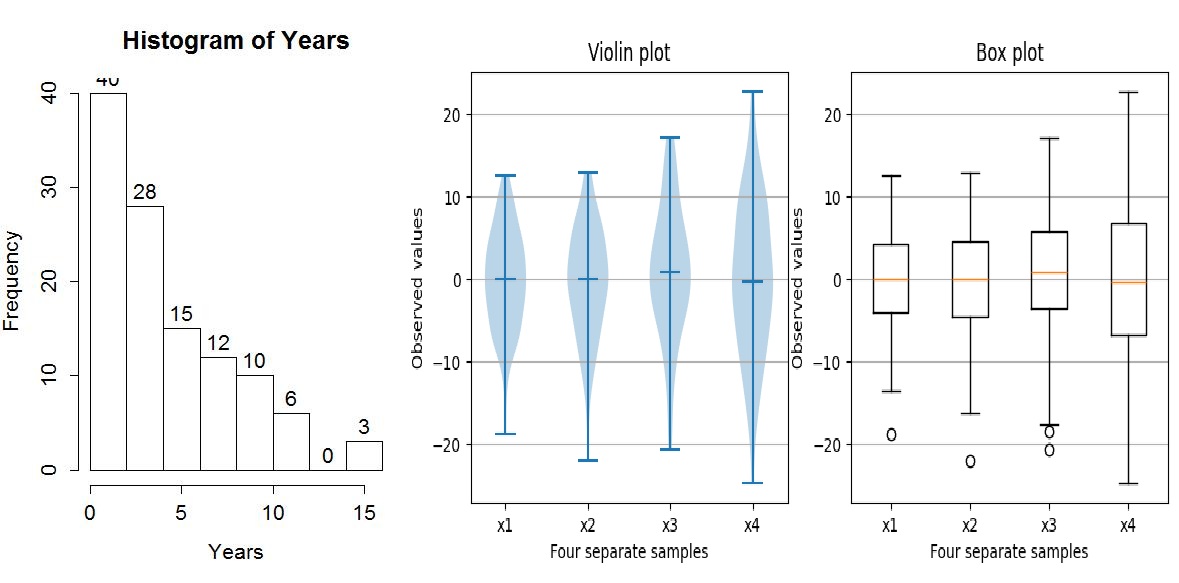
2. 데이터 분포 시각화
| 시각화 기법 | 특징 및 용도 |
|---|---|
| 히스토그램 | 데이터의 빈도나 분포 밀도 파악에 유용. 왜도(skewness), 첨도(kurtosis), 모드 수 등을 직관적으로 확인 가능. |
| 박스플롯 | 중앙값, 사분위수, 이상치 등을 요약하여 보여주는 요약형 시각화. 여러 그룹 간 분포 비교에 최적. |
| 바이올린 플롯 | 히스토그램의 밀도 정보를 포함하면서 박스플롯의 요약 정보를 함께 제공. 분포 형태 분석에 탁월, 모드 발견에 도움. |
확률
확률 (probability)
모든 경우의 수에 대한 특정 사건이 발생하는 비율이다. 대체로 수학 외에서는, 0과 1 사이의 소수 혹은 분수나 순열 등으로 나타내기보다는, 다른 비율을 나타낼 때처럼 0과 1 사이의 확률에 100을 곱하여 0과 100 사이의 백분율(%)로 나타내거나 옛날처럼 할·푼·리로 나타내기도 한다. (출처: 나무위키)
표본 공간(Sample Space)
표본 공간이란 어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합
-
동전 던지기의 경우 S = {앞면, 뒷면} , 주사위던지기 S = {1,2,3,4,5,6}
-
사건 A가 일어날 확률을 P(A)라고 하고, 표본 공간(S)가 유한집합일때 표본 공간의 모든 원소들이 일어날 확률이 같으면
-
확률 변수(random variable)
-
표본공간에서 각 사건에 실수를 대응시키는 함수를 확률 변수라고 함
-
확률 변수의 값은 하나의 사건에 대하여 하나의 값을 가지며, 실험의 결과에 의하여 변함
-
일반적으로 확률 변수는 대문자로 표현하며, 확률변수의 특정값을 소문자로 표현함
- 확률 변수: X, Y 등 대문자 표현
- 확률 변수의 특정값: x, y등 소문자로 표현
- 이산 확률 변수(discrete random variable): 셀 수 있는 값들로 구성되거나 일정 범위로 나타나는 경우
- 연속 확률 변수(continuous random variable): 연속형 또는 무한대와 같이 셀 수 없는 경우
- 확률 변수 예시
(a) 반도체 1000개의 wafer중 불량품의 수 X
(b) 공장에서 생산하는 전구의 수명 T
(c) 주사위를 던질 때 나오는 눈의 수 V
-
확률 변수의 평균 : 기대값 이라고 표현하기도 하며, 수식은 아래와 같음
-
확률 변수의 분산
이론적인 확률 분포
6. 정규분포
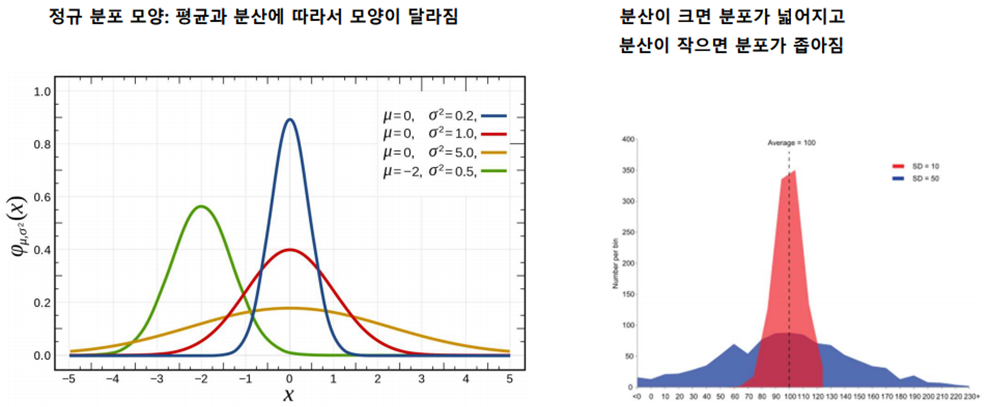
(1) 정규분포(Normal Distribution)
정규분포는 통계학과 데이터 분석에서 가장 중요한 확률분포 중 하나입니다.
이 분포는 평균(μ)을 중심으로 좌우가 대칭인 종 모양(Bell curve)을 띠며, 많은 자연 현상과 측정 데이터가 이 분포를 따르는 경향이 있습니다.
- 특징
- 평균(μ), 표준편차(σ) 두 가지 매개변수로 정의됨
- 평균을 중심으로 좌우 대칭
- 평균 = 중앙값 = 최빈값
- 약 68%의 데이터가 μ ± 1σ 범위에 존재
- 약 95%의 데이터가 μ ± 2σ 범위에 존재
- 약 99.7%의 데이터가 μ ± 3σ 범위에 존재
→ 이를 68–95–99.7 법칙이라고 함
(2) 표준정규분포(Standard Normal Distribution)
- 평균 μ = 0, 표준편차 σ = 1인 정규분포
- 모든 정규분포 데이터는 표준화(standardization)를 통해 표준정규분포로 변환 가능
- 변환 후 값은 Z-점수(Z-score)라고 부름
- X: 원본 데이터 값
- μ: 원본 데이터의 평균
- σ: 원본 데이터의 표준편차
- Z-score: 해당 값이 평균에서 몇 개의 표준편차만큼 떨어져 있는지 나타냄
3. 표준화(Standardization)
- 표준화란 데이터의 평균을 0, 표준편차를 1로 맞추는 과정
→ 단위와 크기가 다른 데이터를 동일한 스케일로 변환하여 비교 가능하게 함- 머신러닝에서 변수의 스케일이 다르면, 가중치 학습이 왜곡될 수 있음
(예: KNN, SVM, 로지스틱 회귀, PCA 등 거리 기반/가중치 기반 모델) - 통계 분석에서 Z-검정, t-검정 등 정규분포 가정을 만족시키기 위해 필요
- 머신러닝에서 변수의 스케일이 다르면, 가중치 학습이 왜곡될 수 있음
