
들어가며
최근 백준 온라인 저지에 올라온 서비스 종료 안내를 보게 되었습니다.
공지에 따르면 BOJ는 2026년 4월 28일 서비스를 종료할 예정입니다.오랫동안 많은 사람들이 사용하던 PS 플랫폼이었고, 개인적으로도 문제 풀이 등급인 AC RATING 기준 플레티넘 5에서 다이아까지 목표로 하고 있었기 때문에 아쉬움이 컸습니다.
이젠 추억에서 함께해야할 것 같습니다.
그렇지만, 온라인 채점 서비스는 어떻게 만들어질까요?
저는 A&I 온라인 멘토링 프로젝트에서 코드 채점 서비스를 설계하고 구현했습니다.
멘티가 제출한 코드를 비동기로 채점하고, 언어별 샌드박스에서 독립적으로 실행하며, 테스트 케이스 단위의 진행 상황을 실시간으로 전달하는 구조를 목표로 했습니다.
현재 프로젝트는 다음 기술 스택을 기반으로 구현되어 있습니다.
- Spring Boot
- Kotlin
- Coroutines
- WebFlux
- MongoDB
- Redis
- Docker
채점 대상 언어는 Python, Kotlin, Dart 세 가지이며, 실제 A&I 멘토링 과정에서 사용하고 있습니다.
온라인 저지라는 서비스가 어떤 기술적 요소로 구성되는지, 작은 규모의 멘토링 플랫폼에서 직접 구현해보며 배운 내용을 정리해보려 합니다.
먼저 정해야 하는 것
온라인 저지는 겉으로 보면 단순해 보입니다.
사용자가 코드를 제출하고, 서버가 실행한 뒤, 정답 여부를 반환하면 끝나는 것처럼 보입니다.
하지만 실제로 구현하려고 하면 생각보다 많은 질문이 생깁니다.
- 사용자 코드를 어디서 실행할 것인가?
- 잘못된 코드나 악의적인 코드를 어떻게 격리할 것인가?
- 여러 테스트 케이스를 어떻게 실행할 것인가?
- 채점 진행 상황을 사용자에게 어떻게 보여줄 것인가?
- 같은 코드가 반복 제출되면 어떻게 처리할 것인가?
- 제출이 몰리는 시간에도 서버가 버틸 수 있는가?
- 관리자는 채점 결과를 어떻게 조회할 수 있는가?
또한, A&I 온라인 멘토링 플랫폼에서는 다음 요구사항이 있었습니다.
- 사용자는 문제의 풀이 코드를
solution()함수 형식으로 제출한다.- 사용자는 각자 선택한 코스에 따라 Kotlin, Dart, Python으로 풀이할 수 있어야 한다.
- 사용자는 각 테스트 케이스에 대한 채점 결과를 실시간으로 확인할 수 있어야 한다.
- 관리자는 사용자별 채점 결과를 조회할 수 있어야 한다.
- 제출 기한 근처에 요청이 몰려도 시스템이 안정적으로 동작해야 한다.
그래서 단순히 코드를 실행하는 서버가 아니라, 다음 요소를 갖춘 채점 시스템이 필요했습니다.
- 언어별 Docker 샌드박스
- 비동기 채점 처리
- Redis 기반 중복 제출 방지
- 세마포어 기반 동시성 제어
- Redis Pub/Sub + SSE 기반 실시간 결과 전달
- MongoDB 기반 제출 결과 저장
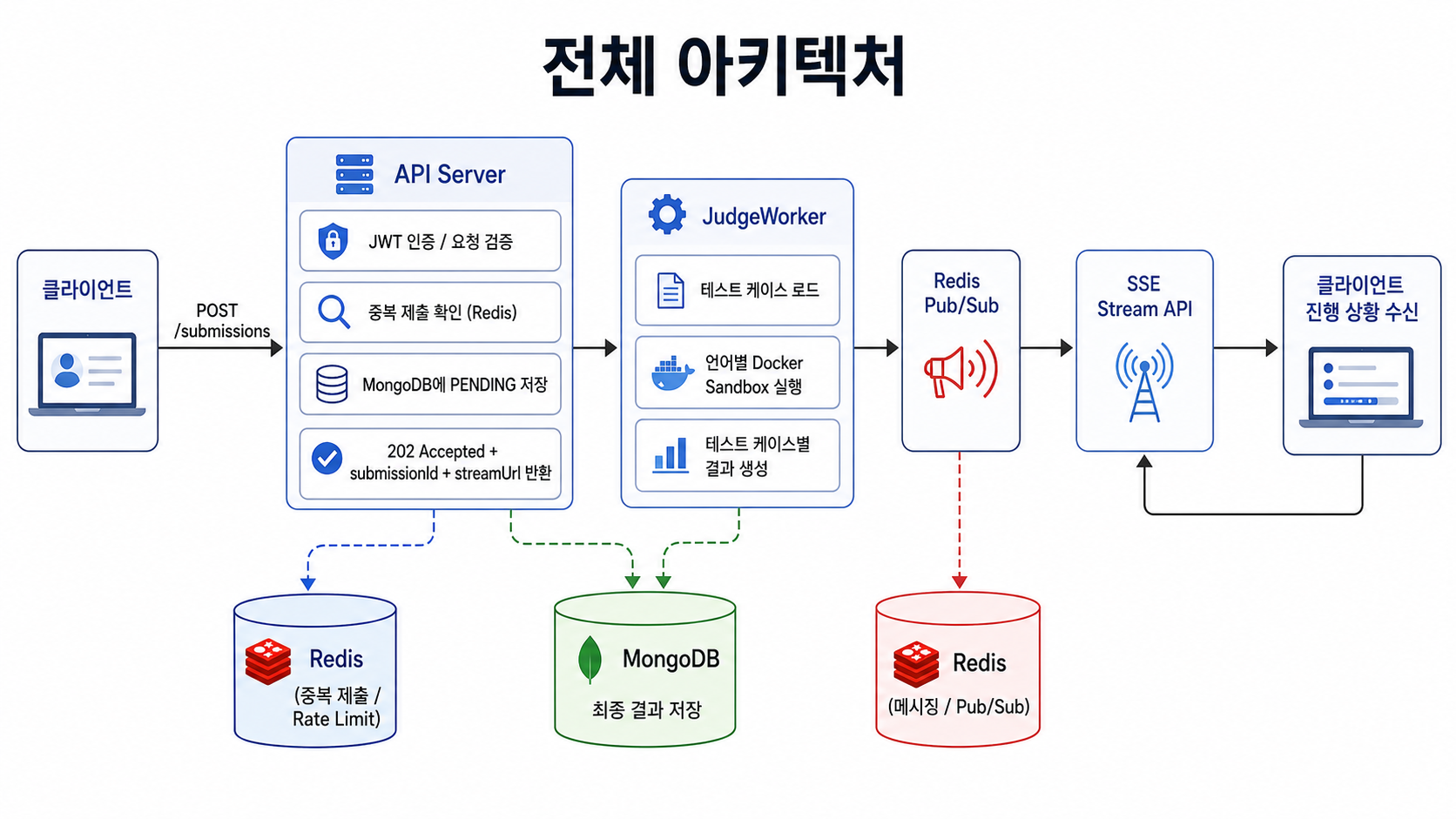
전체 아키텍처
먼저 전체 흐름을 단순화하면 다음과 같습니다.
사용자가 제출 API를 호출했을 때, 서버는 채점이 끝날 때까지 HTTP 요청을 붙잡고 있지 않습니다.
대신 제출을 접수한 뒤 응답과 응답코드를 반환하고, 실제 채점은 백그라운드에서 비동기로 수행합니다.
사용자는 응답에 포함된
streamUrl을 통해 SSE 연결을 열고, 테스트 케이스별 진행 상황을 실시간으로 받아봅니다.물론 스트림 조회 시에도 제출자 본인 또는 관리자 권한을 확인해, 다른 사용자의 채점 진행 상황을 임의로 구독할 수 없도록 제한했습니다.
제출 요청 처리
채점은 테스트 케이스 수, 언어별 컴파일 여부, 실행 시간 제한 등에 따라 오래 걸릴 수 있습니다.
따라서 요청-응답 생명주기 안에서 모든 채점을 끝내는 방식은 적절하지 않다고 판단했습니다.
1. 제출 접수
클라이언트는 사용자 정보, 문제 ID, 언어, 제출 코드를 서버에 보냅니다.
서버는 먼저 다음 작업을 수행합니다.
- JWT 인증
- 요청 유효성 검사
- 문제 및 언어 정보 검증
- 제출 코드 해시 생성
- MongoDB에
PENDING상태로 제출 저장그리고 즉시 다음 응답을 반환합니다.
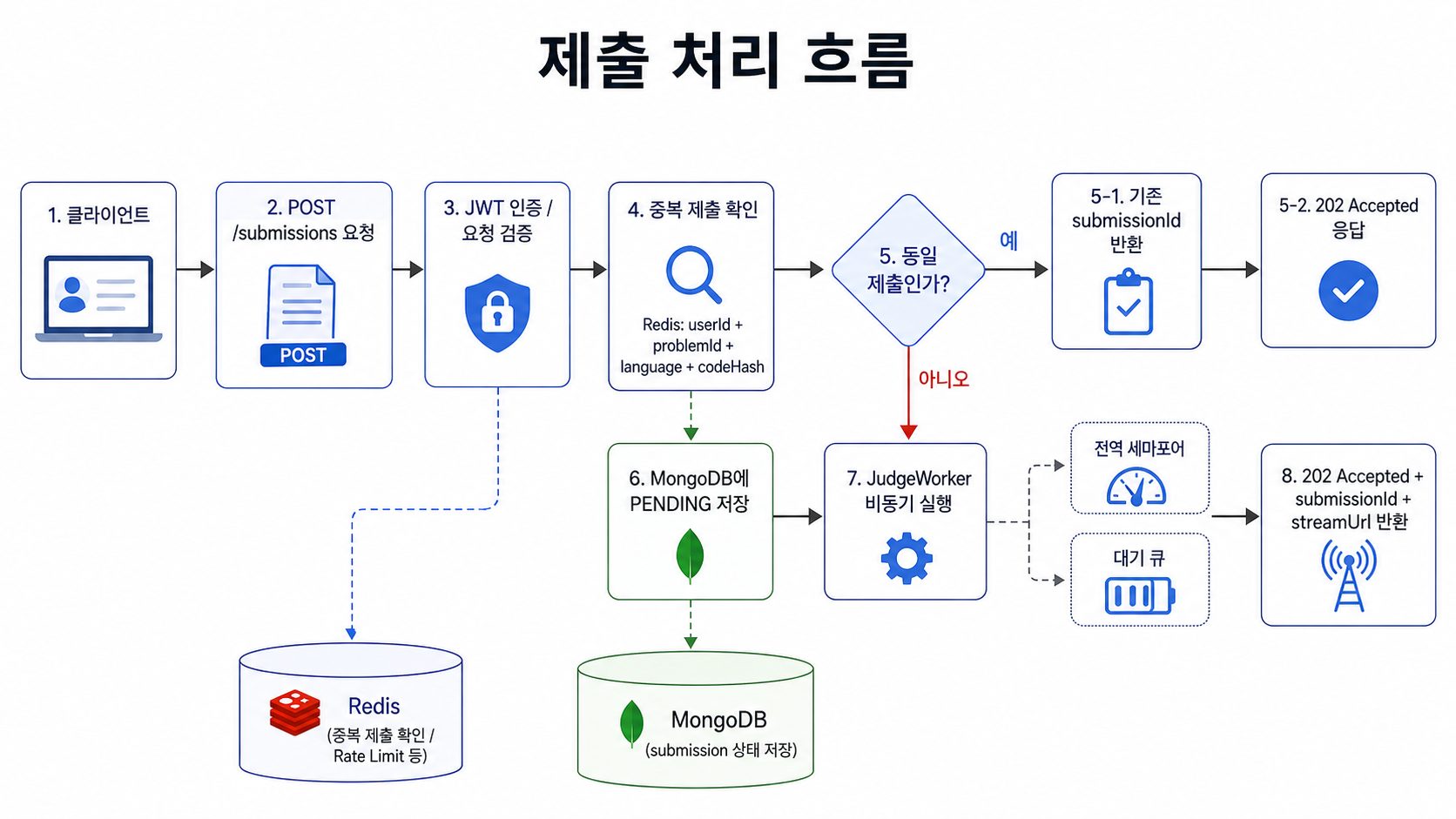
202 Accepted응답에는 다음 정보가 포함됩니다.
{
"submissionId": "sub_123456",
"streamUrl": "/submissions/sub_123456/stream"
}위 정보를 통해서 채점 결과를 반환하는 Stream을 구독해서 클라이언트는 각 테스트케이스에 대한 결과를 실시간으로 전달받을 수 있게 하였습니다.
온라인 저지처럼 시간이 걸리는 작업에서는 이 방식이 더 자연스럽다고 판단했습니다.
2. 중복 제출 방지
같은 사용자가 같은 문제에 같은 언어로 같은 코드를 반복 제출하는 경우는 생각보다 자주 발생합니다.
예를 들면 다음과 같은 상황입니다.
- 사용자가 제출 버튼을 두 번 누른 경우
- 네트워크 오류로 인해 프론트엔드에서 재요청한 경우
- 응답이 늦어서 사용자가 다시 제출한 경우
- 악의적으로 동일 요청을 반복한 경우
이때 모든 요청을 새 채점으로 처리하면 불필요한 Docker 실행이 늘어납니다.
온라인 저지에서 채점 작업은 상대적으로 비싼 작업이기 때문에, 동일 요청은 최대한 초기에 걸러내는 것이 좋습니다.멱등성의 원칙에 대해서 알고 계신가요?
엘레베이터는 버튼을 여러번 눌러도 해당 층을 한번만 방문하게 됩니다. 채점도 마찬가지입니다. 요청은 여러번 있었어도 결과가 반환되기 전까지는 모두 같은 요청입니다.
다만, 이미 결과가 반환되었더라도 역시나 동일 요청은 불필요한 채점이 필요하지 않습니다.그래서 제출 코드 정보로 SHA-256 해시를 만들고,TTL은 5분으로 설정하여 Redis에 저장했습니다.
같은 조합의 요청이 다시 들어오면 새 채점을 만들지 않고, 기존
submissionId를 그대로 반환합니다.온라인 저지에서 가장 비싼 작업은 결국 사용자 코드를 실행하는 것입니다.
따라서 같은 코드를 반복해서 실행하지 않는 것만으로도 시스템 부하를 줄일 수 있습니다.
3. 과도한 요청 차단
중복 제출 방지만으로는 충분하지 않습니다.
서로 다른 코드를 계속 제출하는 경우에는 dedup으로 막을 수 없기 때문입니다.
그래서 제출 엔드포인트에는 별도의 rate limit 필터를 두었습니다.기본값은 다음과 같이 설정했습니다.
1분에 30회구현은 단순한 윈도우 카운터 방식입니다.
val now = clock.instant().epochSecond
val state = counters.compute(clientKey) { _, current ->
if (current == null || now - current.windowStartEpochSecond >= properties.windowSeconds) {
WindowCounter(now, 1)
} else {
current.copy(count = current.count + 1)
}
} ?: WindowCounter(now, 1)
if (state.count <= properties.submitRequests) {
return chain.filter(exchange)
}여기서 핵심은 비싼 채점 작업으로 들어가기 전에, 입구에서 먼저 요청량을 제한한다는 점입니다.
채점 서버 내부에서 Docker 실행까지 시작한 뒤 제어하면 이미 늦습니다.
따라서 제출 API 레벨에서 먼저 폭주를 차단하는 구조로 만들었습니다.다만 위 예시는 단일 인스턴스 기준의 단순 윈도우 카운터입니다.
여러 API 서버 인스턴스로 확장한다면 Redis 기반 카운터로 옮겨 전역 rate limit을 적용하는 것이 더 적절합니다.
4. 비동기 채점 시작
제출이 MongoDB에 저장되면
JudgeWorker가 비동기로 실행됩니다.다만 요청이 들어오는 대로 무제한 병렬 실행하지는 않았습니다.
Docker 컨테이너 실행은 CPU와 메모리를 많이 사용합니다.
따라서 동시에 너무 많은 채점이 실행되면 서버 전체가 불안정해질 수 있습니다.그래서 전역 세마포어를 두고, 동시에 실행 가능한 워커 수를 제한했습니다.
workerSemaphore.withPermit {
judgeWorker.run(submissionId)
}즉, 요청은 많이 들어올 수 있지만 실제 채점은 시스템이 감당 가능한 범위 안에서만 실행됩니다.
동시 실행 범위를 초과한 제출은 Redis 기반 큐에 대기시키고, 기존 채점이 완료되면 다음 제출을 꺼내 처리하는 방식으로 구성했습니다.
다만 이 구조에는 한계도 있습니다.
현재 구조는 서버 내부 코루틴 기반으로 채점을 시작하기 때문에, 프로세스가 비정상 종료되면 진행 중인 작업 복구는 별도 처리가 필요합니다.
현재 A&I 멘토링 플랫폼 규모에서는 단순성과 구현 속도를 우선했지만, 더 큰 규모로 확장한다면 작업 자체를 durable queue 기반으로 분리하는 것이 더 안전합니다.
예를 들면 다음 선택지를 고려할 수 있습니다.
- Redis Stream
- AWS SQS
- Kafka
- RabbitMQ
즉, 현재 구조는 “작은 규모에서 빠르게 안정성을 확보하는 구조”에 가깝고, 대규모 운영 환경이라면 작업 큐의 내구성까지 함께 고려해야 합니다.
채점 워커 구조
실제 채점은
JudgeWorker가 담당합니다.
JudgeWorker는 단순히 코드를 실행하는 계층이 아닙니다.
다음 역할을 함께 수행합니다.
- 제출 정보 조회
- 테스트 케이스 로드
- 언어별 샌드박스 실행
- 테스트 케이스별 결과 생성
- 진행 이벤트 발행
- 최종 판정 계산
- MongoDB에 최종 결과 저장
1. 테스트 케이스 로드
워커는 먼저 문제의 테스트 케이스를 가져옵니다.
A&I 플랫폼에서는 문제와 테스트 케이스 관리가 채점 서버 안에만 고정되어 있지 않습니다.
문제 등록은 과제 서비스에서 담당하고, 테스트 케이스가 등록되면
테스트 케이스 등록 이벤트가 발행됩니다.
채점 서버는 이 이벤트를 구독한 뒤, MongoDB에 테스트 케이스를 저장합니다.현재는 테스트 케이스 등록 이벤트를 기준으로 동기화하고 있으며, 이후에는 수정/삭제 이벤트까지 처리할 수 있도록 확장 가능성을 열어두었습니다.
즉, 채점 서버는 문제 관리 시스템과 직접 강하게 결합되지 않고, 이벤트를 통해 필요한 테스트 케이스를 동기화합니다.
이 구조는 추후 과제 서비스, 채점 서비스, 결과 분석 서비스가 분리될 때 유리합니다.
2. 테스트 케이스 단위 병렬 채점
테스트 케이스가 여러 개라면 하나씩 순차 실행하는 방식은 느릴 수 있습니다.
그래서 테스트 케이스 단위로 병렬 실행할 수 있도록 구성했습니다.
다만 여기서도 병렬성을 무제한으로 열어두지는 않았습니다.
하나의 제출이 서버 전체 자원을 독점하면 안 되기 때문입니다.그래서 테스트 케이스 실행에도 별도의 세마포어를 두었습니다.
val limiter = Semaphore(caseConcurrency)
val results = coroutineScope {
testCases.map { testCase ->
async {
limiter.withPermit {
val output = runInSandbox(testCase)
toJudgeResult(testCase, output)
}
}
}.awaitAll()
}이 구조는 다음 의미를 가집니다.
- 테스트 케이스는 병렬로 실행한다.
- 하지만 동시에 실행 가능한 테스트 케이스 수는 제한한다.
- 워커 단위 동시성과 테스트 케이스 단위 동시성을 분리한다.
또한, 실행 완료 순서와 최종 결과 순서를 분리합니다.
빠르게 끝난 테스트 케이스는 먼저 SSE로 전달합니다.
하지만 최종 저장 결과는 원래 테스트 케이스 순서를 유지합니다.사용자 입장에서는 진행 상황을 빠르게 볼 수 있고, 시스템 입장에서는 결과 정렬의 일관성을 유지할 수 있습니다.
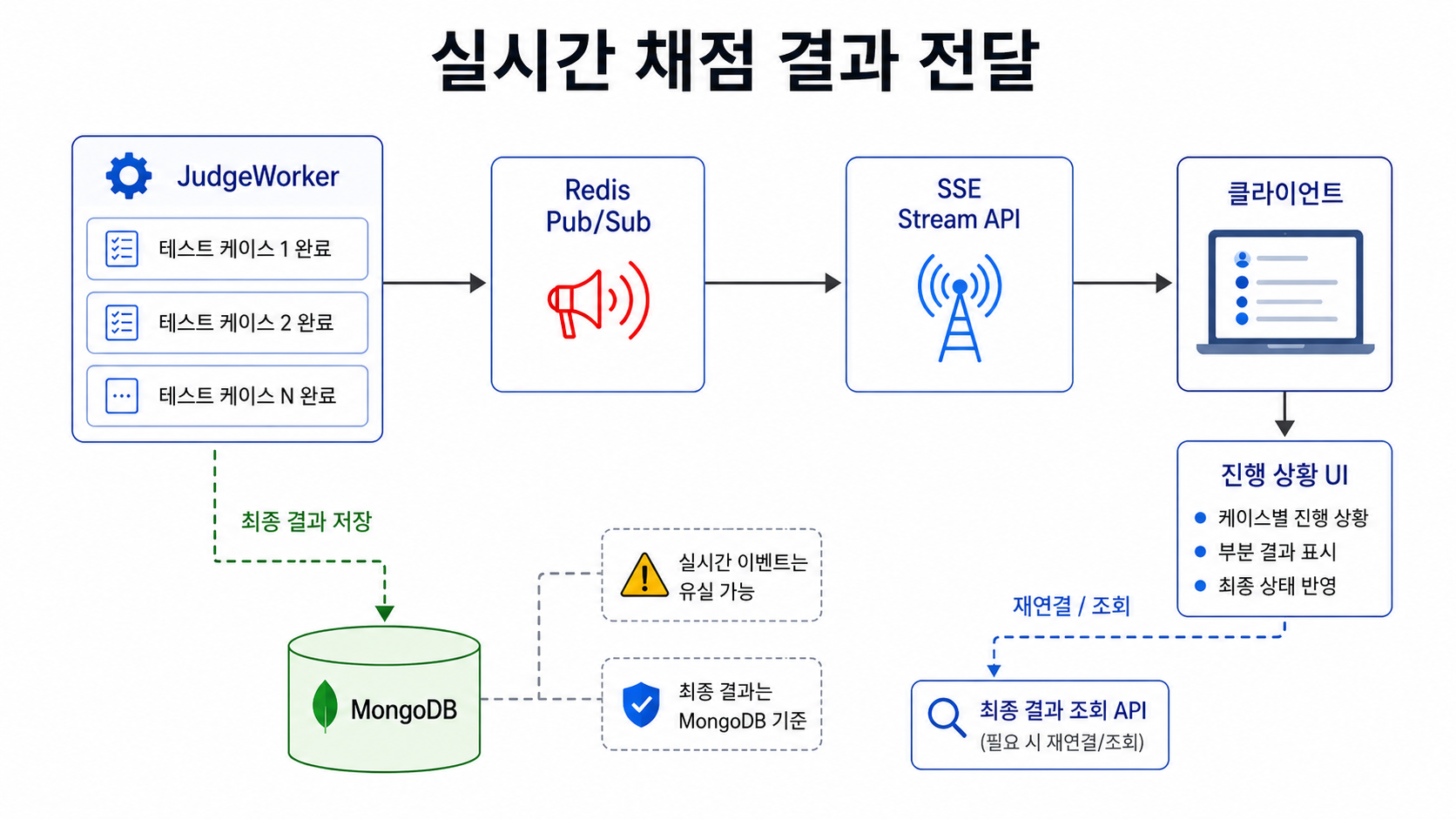
3. 실시간 결과 전달
각 테스트 케이스가 끝날 때마다 워커는 Redis Pub/Sub으로 진행 이벤트를 발행합니다.
API 서버는 해당 이벤트를 구독하고, 클라이언트에는 SSE로 전달합니다.
이 구조의 장점은 워커와 API 서버가 직접 강하게 결합되지 않는다는 점입니다.
워커는 결과 이벤트를 발행하기만 하면 됩니다.
API 서버는 이벤트를 받아 SSE로 흘려보내기만 하면 됩니다.또한 이후에 WebSocket이나 다른 이벤트 시스템으로 전환하더라도, 워커의 핵심 채점 로직은 크게 바꾸지 않아도 됩니다.
4. Redis Pub/Sub의 한계
다만 Redis Pub/Sub은 메시지를 저장하지 않습니다.
즉, 클라이언트가 잠시 연결이 끊긴 동안 발생한 진행 이벤트는 다시 받을 수 없습니다.
이 프로젝트에서는 테스트 케이스별 진행 이벤트를 “UX 개선용 실시간 이벤트”로 보고, 최종 채점 결과는 MongoDB에 저장하는 방식으로 일관성을 보장했습니다.
정리하면 다음과 같습니다.
- 테스트 케이스별 진행 이벤트는 유실될 수 있다.
- 하지만 최종 채점 결과는 MongoDB에 저장한다.
- 클라이언트는 연결이 끊겨도 최종 결과 조회 API를 통해 결과를 다시 확인할 수 있다.
이렇게 실시간 이벤트와 최종 결과 저장의 책임을 분리했습니다.
5. 최종 판정
모든 테스트 케이스가 끝나면 워커는 최종 상태를 결정합니다.
대표적인 상태는 다음과 같습니다.
ACCEPTEDWRONG_ANSWERTIME_LIMIT_EXCEEDEDMEMORY_LIMIT_EXCEEDEDRUNTIME_ERRORCOMPILE_ERROR이후 MongoDB에 최종 결과와
completedAt을 저장하고, 완료 이벤트를 발행합니다.이 구조를 확장하면 채점 완료 이벤트를 다른 서비스로 전달할 수도 있습니다.
예를 들어 다음과 같은 확장이 가능합니다.
- 과제 서비스에 제출 완료 상태 반영
- 관리자 알림 발송
- 사용자별 통계 집계
- 문제별 정답률 분석
- 랭킹 시스템 갱신
처음부터 모든 기능을 만들지는 않았지만, 채점 결과를 이벤트로 바라보면 이후 확장 가능성이 좋아집니다.
채점 샌드박스 구현
온라인 저지에서 보안 취약점 사용자 코드를 실행하는 시점입니다.
사용자 코드는 어떤 동작을 할지 알 수 없습니다.
- 무한 루프를 돌 수 있습니다.
- 메모리를 과도하게 사용할 수 있습니다.
- 파일 시스템에 접근하려 할 수 있습니다.
- 네트워크 요청을 보낼 수 있습니다.
- 프로세스를 계속 생성할 수 있습니다.
따라서 애플리케이션 프로세스 안에서 사용자 코드를 그대로 실행하는 것은 위험합니다.
이번 프로젝트에서는 언어별 Docker 이미지를 만들고, 제출 코드를 컨테이너 안에서 실행하도록 구성했습니다.
각 컨테이너는 공통적으로 비특권 사용자(
appuser)로 실행되며,docker run시점에 다음 제한을 적용했습니다.
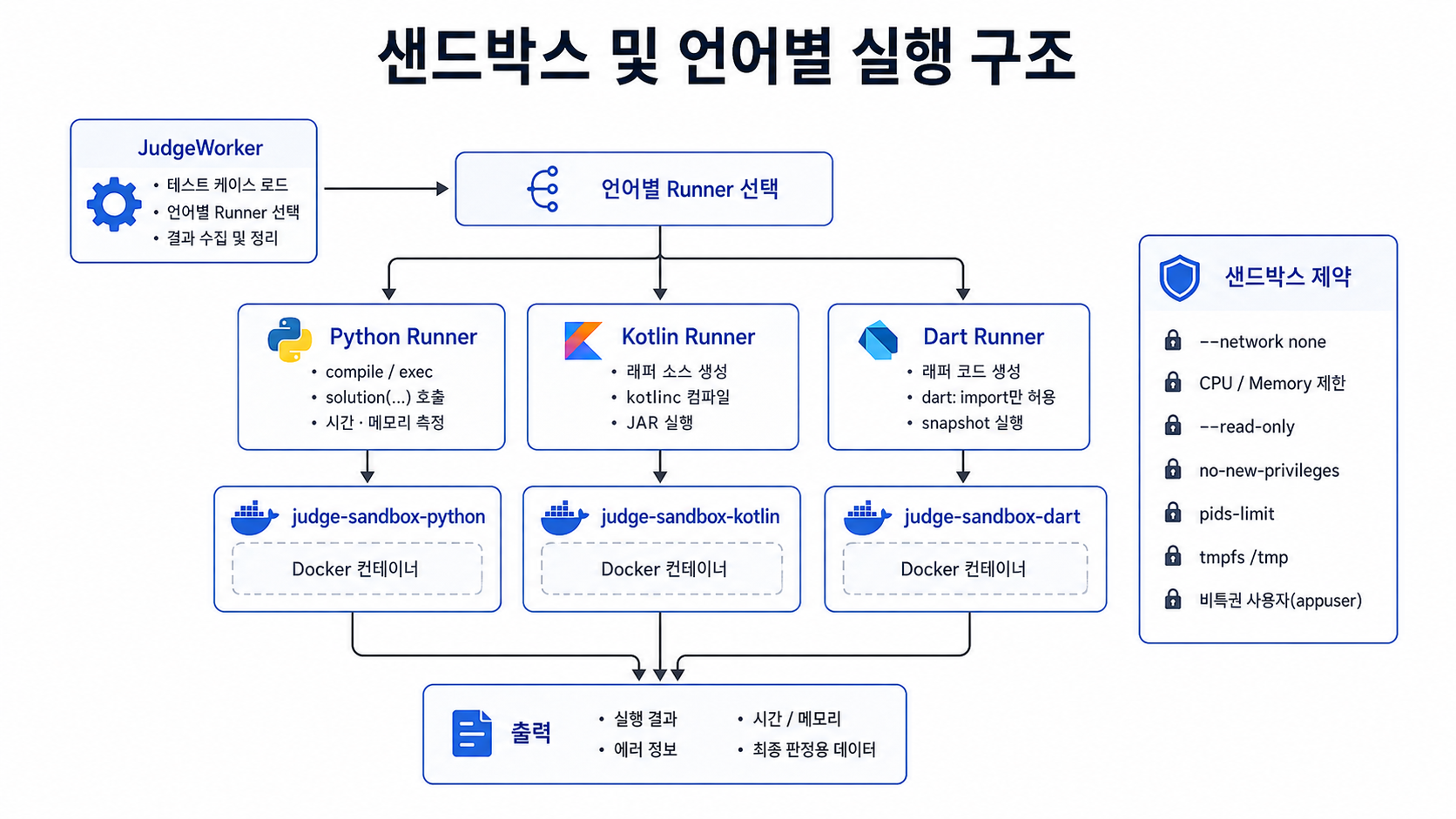
--network none
--cpus
--memory
--read-only
--security-opt no-new-privileges
--pids-limit
--tmpfs /tmp:rw,noexec,nosuid,size=64m실제 실행 옵션은 다음과 비슷합니다.
val cmd = listOf(
"docker", "run", "--rm",
"--network", "none",
"--cpus", properties.cpuLimit,
"--memory", "${properties.memoryLimitMb}m",
"--read-only",
"--security-opt", "no-new-privileges",
"--pids-limit", "${properties.pidsLimit}",
"--tmpfs", "/tmp:rw,noexec,nosuid,size=64m",
"-i", image,
)중요한 것은 Docker 컨테이너를 실행하되, 다음 요소를 함께 제한하는 것입니다.
- 네트워크
- CPU
- 메모리
- 파일시스템
- 프로세스 수
- 권한 상승
- 임시 디렉터리
다만 Docker만으로 완전한 샌드박스 보안을 보장한다고 보기는 어렵습니다.
그래서 현재 구조에서는 기본적인 실행 격리를 Docker로 구성하되, 운영 환경에서는 gVisor의
runsc같은 추가 격리 계층을 붙일 수 있도록 열어두었습니다.즉, 현재 구조는 Docker 기본 격리를 중심으로 하되, 더 강한 격리가 필요한 상황에서는 추가 런타임을 붙일 수 있는 형태입니다.
언어별 실행 방식 처리
겉으로 보면 모든 언어는 “코드를 받아 실행한다”는 점에서 비슷해 보입니다.
하지만 실제 구현에서는 언어마다 실행 전략이 꽤 달랐습니다.
Python, Kotlin, Dart는 컴파일 방식, 실행 방식, import 처리, 반환값 직렬화 방식이 다릅니다.
그래서 공통 인터페이스는 유지하되, 내부 러너 구현은 언어별로 다르게 가져갔습니다.
1. Python 러너
Python은 상대적으로 실행 구조가 단순했습니다.
사용자가 제출한 코드를
compile/exec로 로드하고,solution(...)함수를 찾습니다.
이후 테스트 케이스의 입력값을 인자로 넘겨solution(...)을 호출합니다.물론 이 코드는 애플리케이션 서버 프로세스에서 실행되는 것이 아니라, 네트워크와 파일시스템이 제한된 Python 샌드박스 컨테이너 내부에서만 실행됩니다.
중요하게 본 점은 측정 구간이었습니다.
파싱, 컴파일, 부트스트랩 시간을 포함하면 실제 사용자의 풀이 성능과 무관한 비용이 섞일 수 있습니다.
그래서 Python 러너에서는 실제solution(...)호출 구간만 시간과 메모리 측정 대상으로 잡았습니다.예시는 다음과 같습니다.
def execute_solution(namespace, args, case_id=None):
tracemalloc = __import__("tracemalloc")
tracemalloc.start()
start_ns = time.perf_counter_ns()
try:
result = namespace["solution"](*args)
output = normalize_json_value(result)
error = None
status = "PASSED"
except Exception as e:
output = None
error = f"RUNTIME_ERROR: {e}"
status = "RUNTIME_ERROR"
finally:
elapsed_ms = (time.perf_counter_ns() - start_ns) / 1_000_000.0
_, peak_bytes = tracemalloc.get_traced_memory()
tracemalloc.stop()이 구조를 통해 Python에서는 다음 상태를 비교적 명확하게 나눌 수 있었습니다.
- 문법 오류:
COMPILE_ERROR- 함수 미정의:
RUNTIME_ERROR- 실행 중 예외:
RUNTIME_ERROR- 무한 루프:
TIME_LIMIT_EXCEEDED
2. Kotlin 러너
Kotlin은 Python보다 복잡했습니다.
Python처럼 동적으로 함수를 바로 로드해서 실행하는 방식이 아니라, 사용자 코드를 포함한 Kotlin 소스를 컴파일해야 했습니다.
그래서 Kotlin 러너는 사용자 코드를 감싸는 래퍼 소스를 생성하는 방식으로 구성했습니다.
래퍼는 다음 역할을 담당합니다.
- 테스트 케이스별
solution(...)호출 코드 생성- 반환값 JSON 직렬화
- 예외 처리
- 상태 코드 변환
- 메모리 사용량 샘플링
생성된 소스는 컨테이너 안에서
kotlinc로 컴파일한 뒤 실행합니다.이때 러너 자체는 미리 JAR로 빌드해두고, 제출 시점에는 사용자 코드가 포함된 임시 소스만 추가로 컴파일하는 방식을 사용했습니다.
매번 전체 런타임을 처음부터 준비하지 않아도 되기 때문에 실행 비용을 줄일 수 있었습니다.
3. Dart 러너
Dart 역시 Kotlin과 유사하게 사용자 코드를 감싸는 방식으로 동작합니다.
다만 Dart에서는 import 제어가 중요했습니다.
사용자가 외부 패키지를 마음대로 가져오게 두면 실행 환경이 불안정해질 수 있고, 채점 재현성도 떨어질 수 있습니다.
그래서 Dart 러너에서는dart:표준 라이브러리 import만 허용했습니다.예시는 다음과 같습니다.
final importMatch = _importDirectivePattern.firstMatch(line);
if (importMatch != null) {
final uri = importMatch.group(2)!;
if (!uri.startsWith('dart:')) {
return UserCodeParts(
imports: imports,
body: code,
error: 'only Dart SDK standard library imports are allowed: $uri',
);
}
imports.add(line.trim());
continue;
}또한 Dart는 snapshot을 생성해 실행하기 때문에
/tmp임시 디렉터리가 필요했습니다.Kotlin도 컴파일 과정에서 임시 파일이 필요하기 때문에, 샌드박스 실행 시 제한된 tmpfs를 제공했습니다.
--tmpfs /tmp:rw,noexec,nosuid,size=64m결국 언어별 실행 방식은 하나의 공통 인터페이스로 추상화할 수는 있지만, 내부 구현까지 완전히 동일하게 만들기는 어렵다는 점을 느꼈습니다.
4. 입출력 매핑 테스트
온라인 저지는 “코드가 실행되는가”만으로는 부족합니다.
채점이 정확하려면 입력값과 반환값이 모든 언어에서 같은 의미로 처리되어야 합니다.
예를 들어 다음과 같은 값들이 언어별로 올바르게 매핑되어야 합니다.
- 숫자
- 문자열
- Boolean
- 배열
- 중첩 배열
- Map
- null
- 복합 구조
만약 입력 매핑이 흔들리면 사용자의 코드가 맞아도 오답으로 처리될 수 있습니다.
반대로 반환값 정규화가 흔들리면 틀린 코드가 맞는 것처럼 보일 수도 있습니다.그래서 가능한 입출력 타입에 상황에 따라 언어별 러너 테스트를 따로 작성했습니다.
- Kotlin 러너: 30개 테스트
- Dart 러너: 29개 테스트
- Python 러너: 36개 테스트
Kotlin과 Dart는 주로 인자 리터럴 변환과 반환값 직렬화/정규화를 검증했습니다.
Python은 여기에 더해solution(...)실행까지 포함해 검증했습니다.
운영하면서 얻은 교훈
이번 프로젝트에서 가장 크게 느낀 점은, 채점 시스템의 어려움이 실행 자체보다 실행을 둘러싼 운영 구조에 있다는 점이었습니다.
1. 사용자 코드는 반드시 격리되어야 한다
사용자 코드는 신뢰할 수 없습니다.
그래서 네트워크, 파일시스템, 권한, 메모리, CPU, 프로세스 수를 제한해야 했습니다.
Docker를 사용하더라도 기본 실행만으로는 부족하고, 실행 옵션을 보수적으로 구성해야 합니다.2. 실시간 UX와 데이터 일관성은 분리해야 한다
SSE로 진행 상황을 보여주는 것은 사용자 경험에 좋습니다.
하지만 실시간 이벤트를 최종 데이터의 근거로 삼으면 위험할 수 있습니다.
따라서 최종 결과는 MongoDB에 저장하고, SSE는 진행 상황 전달에 집중하도록 분리했습니다.3. 동시성 제어는 한 번으로 끝나지 않는다
전체 워커 수만 제한하면 한 제출이 너무 많은 테스트 케이스를 병렬 실행할 수 있습니다.
반대로 테스트 케이스 병렬성만 제한하면 전체 제출 수가 폭증할 수 있습니다.
그래서 워커 단위와 테스트 케이스 단위의 동시성 제어를 분리했습니다.
4. 언어별 러너는 생각보다 다르다
Python, Kotlin, Dart는 모두
solution()함수를 실행한다는 공통점이 있지만, 내부 실행 방식은 꽤 달랐습니다.
- Python은 동적 실행이 쉽다.
- Kotlin은 컴파일과 래퍼 생성이 필요하다.
- Dart는 import 제어와 snapshot 실행을 고려해야 한다.
결국 공통 인터페이스는 만들 수 있지만, 언어별 구현 차이는 인정하고 설계해야 했습니다.
AI 시대에도 온라인 저지가 필요한가
이제 AI는 코드를 잘 작성합니다.
간단한 구현 문제라면 프롬프트 몇 줄만으로도 구현이 가능합니다.
AI시대에서 개발자는 AI를 다루기 위해서 잘 명령하는 법, 잘 검증하는 법, 잘 공존하는 법을 공부해야 된다고 생각합니다.
그런 관점에서 여전히 CS와 알고리즘적 사고는 중요합니다.
- 이 풀이가 시간 제한 안에 들어오는가?
- 메모리 제한을 넘지 않는가?
- 엣지 케이스에서도 맞는가?
- 입력 크기에 맞는 알고리즘인가?
- 자료구조 선택이 적절한가?
온라인 저지는 이 질문에 가장 직접적으로 답해주는 시스템입니다.
그리고 알고리즘 공부의 본질도 비슷합니다.
문제를 추상화하고, 제약을 해석하고, 적절한 자료구조와 알고리즘을 선택하고, 반례를 견디는 해법을 만드는 과정은 AI가 등장해도 사라지지 않습니다.
마무리
직접 구현해보니 온라인 저지 안에는 꽤 많은 시스템 설계 요소가 들어 있었습니다.
- 비동기 작업 처리
- 샌드박스 격리
- 실시간 스트리밍
- 중복 제출 방지
- 요청 제한
- 동시성 제어
- 이벤트 기반 동기화
- 언어별 실행 전략
- 최종 결과 저장과 조회
현재 프로젝트가 백준 같은 대규모 온라인 저지를 대체할 수 있는 수준은 아닙니다.
하지만 작은 규모의 멘토링 플랫폼에서 온라인 저지의 핵심 구조를 직접 설계하고 구현해보며, 코드 채점 시스템이 어떤 문제들을 해결해야 하는지 경험할 수 있었습니다.
가장 크게 배운 점은 이것입니다.
"온라인 저지는 코드를 실행하는 시스템이 아니라, 신뢰할 수 없는 코드를 제한된 환경에서 안전하고 일관되게 검증하는 시스템이다."
