
이번에 학기 중 진행하는 프로젝트에서 메시지 큐 시스템을 통해 서비스를 처리하고 싶은 방법이 생겨서 kafka를 도입하는 방향으로 진행하게 되었습니다.
이를 통해, 간단하게 이벤트 기반 메시지 큐 시스템으로만 알고 있었던 카프카에 대한 개념을 자세히 정리하고, 현재 진행하는 프로젝트에서 적용하기로 하였습니다.
🤔 Kafka란?
먼저 Kafka는 Backend나 DevOps를 공부하다 보면 자주 보이는 기술입니다. 제가 처음으로 Kafka를 들었던 것은 NDC 세션에서 처음 접했던 것 같습니다. 당시에는 넥슨에서 문제를 해결할 때 도입했던 기술로만 생각하고 넘어갔었던 것 같았는데 생각보다 많은 곳에서 사용중인 프로젝트인 것은 나중에 알게 되었습니다.
본론으로 돌아가자면, Kafka는 메시지 큐 시스템으로, 높은 처리량과 확장성을 고려하여 만들어진 프로젝트입니다.
먼저 메시지 큐 시스템이 무엇이며, kafka에서는 어떻게 높은 처리량과 확장성을 고려하는지 알아보겠습니다.
1. 메시지 큐
먼저 메시지 큐는 서로 다른 프로세스가 데이터를 교환 할 때 사용하는 통신 방법입니다. 서로 다른 프로세스 사이의 미들웨어 역할을 수행하며 비동기적으로 데이터를 송수신 할 수 있습니다.
여기서 메시지는 요청, 응답, 에러 등 단순히 어떠한 정보를 저장한 데이터를 말합니다.

이렇게 중간에 메시지 큐를 통해 데이터를 송신, 수신하면 다음과 같은 이점을 얻을 수 있습니다.
1) 낮은 결합도
메시지 큐를 통해 데이터를 송신, 수신하면 낮은 결합도를 유지 할 수 있습니다. 데이터를 송신 할 때, 수신 서버에 대한 의존도가 사라집니다. 송신서버는 데이터를 일단 보내면, 메시지 큐가 이를 수신서버에 보내서 데이터 처리를 수행하기 때문입니다. 이로 인해, 각 서버는 독립적으로 수행할 수 있게 되며 결합도가 낮아지게 됩니다.
2) 비동기 처리
메시지 큐를 통해 처리하기 때문에, 비동기적인 처리가 가능합니다. 위의 설명대로 만약 메시지를 수신받는 서버가 CI/CD 과정에서 잠시 멈춰있거나, 다른 데이터를 처리하는 과정에서 병목이 생길 수 있지만, 메시지큐를 이용하면 송신자는 메시지 큐에 데이터만 넣어놓으면 됩니다. 수신자는 서버가 처리가 가능한 시점에 메시지 큐에서 데이터를 가져와 서비스를 처리하면 됩니다.
위와 같은 장점으로 메시지 큐 시스템을 도입 할 수 있으며 대표적으로 Apache Kafka, RabbitMQ, AWS SQS 같은 것들이 있습니다.
2. Kafka
Kafka는 기존 RabbitMQ와 같은 메시지 큐 시스템이 추구하는 방향과 살짝 다릅니다. RabbitMQ는 소비자 중심의 패턴으로 복잡한 routing을 목적으로 메시지 큐를 도입 할 수 있지만, kafka는 확장성과 실시간성에 가까운 높은 처리량을 목적으로 만들어졌습니다.
kafka: 높은 처리량과 확장성을 우선으로 둠.
RabbitMQ: 유연한 routing이 가능하며, 오래전부터 있었기 때문에 제품 성숙도가 높음.
즉, kafka는 기존의 메시지 큐 시스템에서 높은 처리량과 확장성을 추구하고 있습니다. kafka가 어떻게 높은 처리량을 지원하고 있는지, 또 어떤 특징을 가지고 있는지 이어서 설명하겠습니다.
kafka의 주요 특징.
- kafka는 메시지를 디스크에 영속화하여 저장한다.
- consumer group을 통해 확장성이 높다.
- Topic, partition을 통해 확장성을 높이고, 높은 처리량을 지원한다.
- 분산 환경을 지원하기 위해 zookeeper라는 분산 환경 코디네이션을 사용한다.
🖐 kafka 동작 방식.
1) zookeeper
먼저 kafka는 분산 환경에서 동작하기 때문에 zookeeper라는 코디네이션을 통해 kafka를 처리합니다.
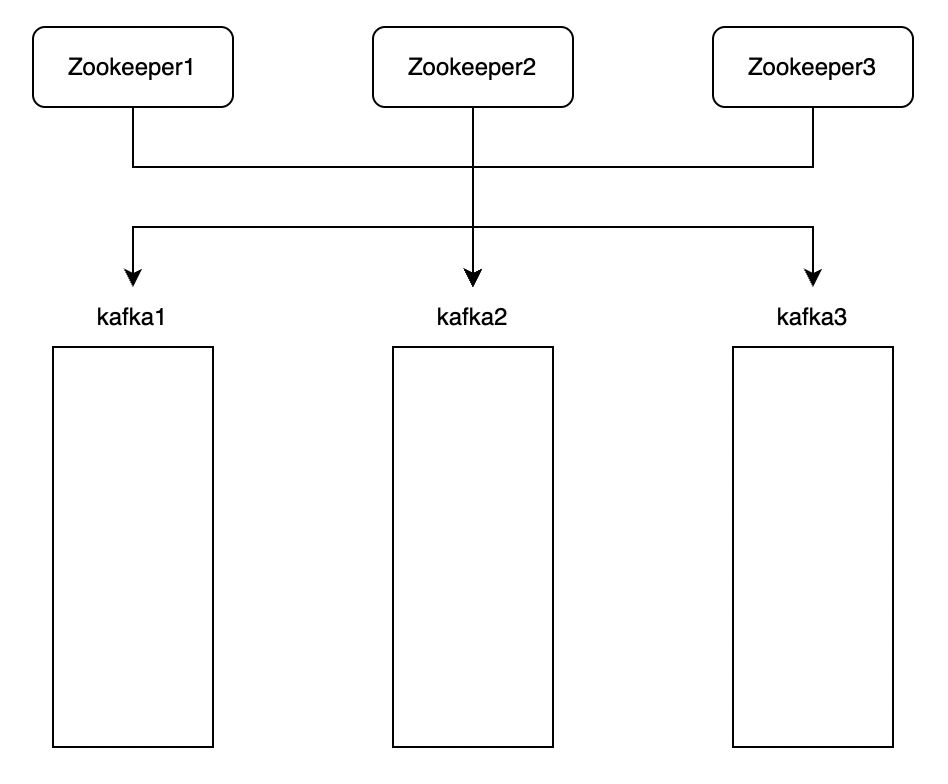
(zookeeper는 내부 기능을 수행 할 때 다수결로 정하는 방법이 있기 때문에 1, 3, 5와 같은 홀수개로 구성해야 함.)
위와 같이 먼저 zookeeper 환경을 구성하여 kafka의 설정 데이터를 저장할 환경을 만들어야 합니다.
(Apache kafka quick start 문서)

kafka 공식 홈페이지에서 zookeeper를 먼저 실행하고 kafka를 실행하는 이유가 다음과 같습니다. 즉, zookeeper를 실행하고 kafka를 실행해서 zookeeper 서버에 kafka 관련 정보를 저장하고 있습니다.
2) Topic, Partition, Replication
kafka 공식 홈페이지에서 kafka를 실행하면 Topic을 생성하라고 합니다.

(생성된 kafka Topic 정보)
해당 사진에서 확인 할 수 있는 정보는 Topic, PartitionCount, ReplicationFactor... 등이 있습니다. 차례대로 정리해보겠습니다.
2-1) Topic
Kafka에서 Topic은 Pub/Sub를 위한 구독 채널과 같습니다.
Kafka에서 Topic을 생성하면, Pub는 해당 Topic으로 메시지를 보내고 Sub에서 해당 Topic에 접근하여 메시지를 소비합니다. 즉, kafka에서 메시지를 처리하기 위한 기본적인 통로라고 생각하면 됩니다.
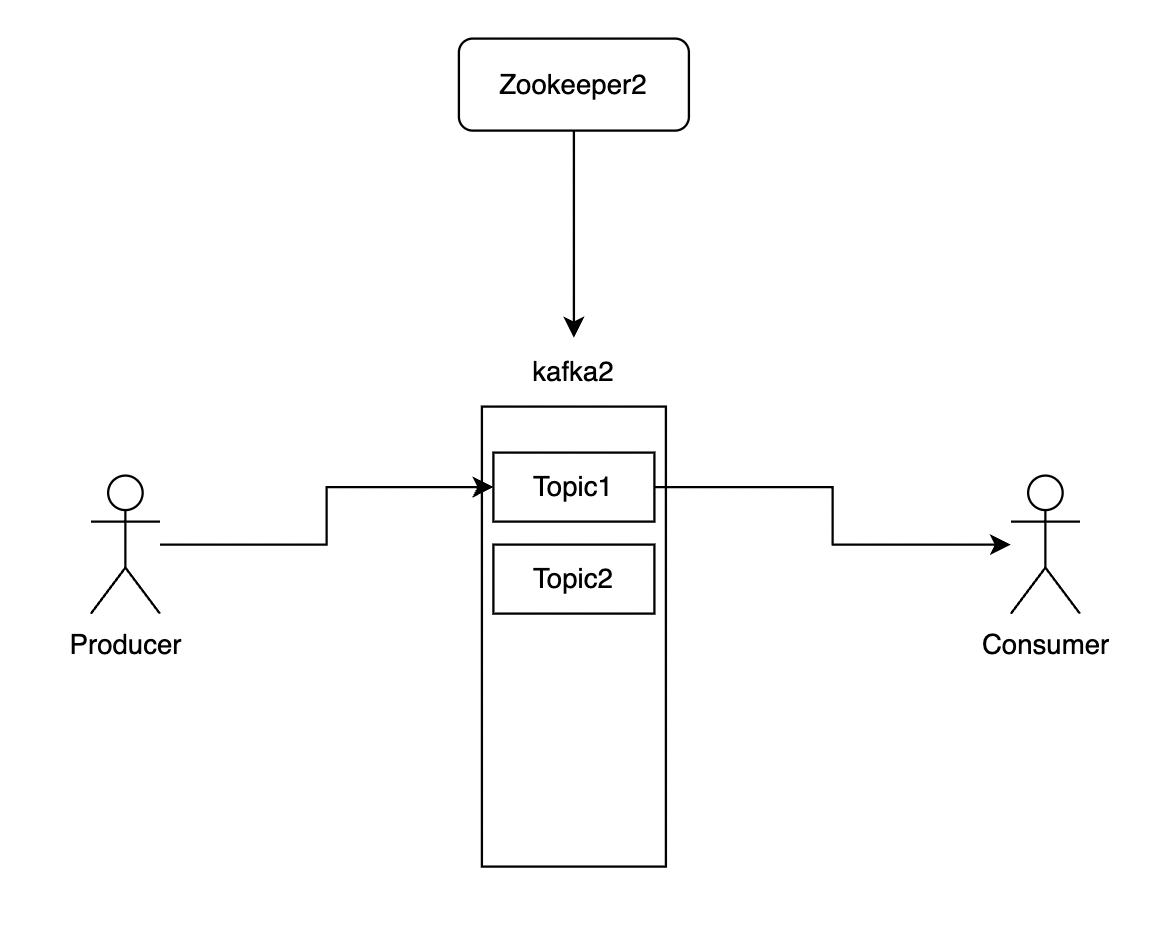
위와 같이 1개의 kafka 서버에서 Topic을 여러개 생성 할 수 있으며 Consumer는 원하는 Topic에서 데이터를 가져와서 처리 할 수 있습니다.
2-2) Partition
Partition은 Topic 내에 존재하는 queue입니다. kafka에서 높은 처리량을 지원하기 위해 Consumer Group을 지정 할 수 있는데, 이 때 Consumer Group 내에서 병렬적으로 partition에 접근하여 데이터를 처리하여 높은 처리량을 수행 할 수 있습니다.
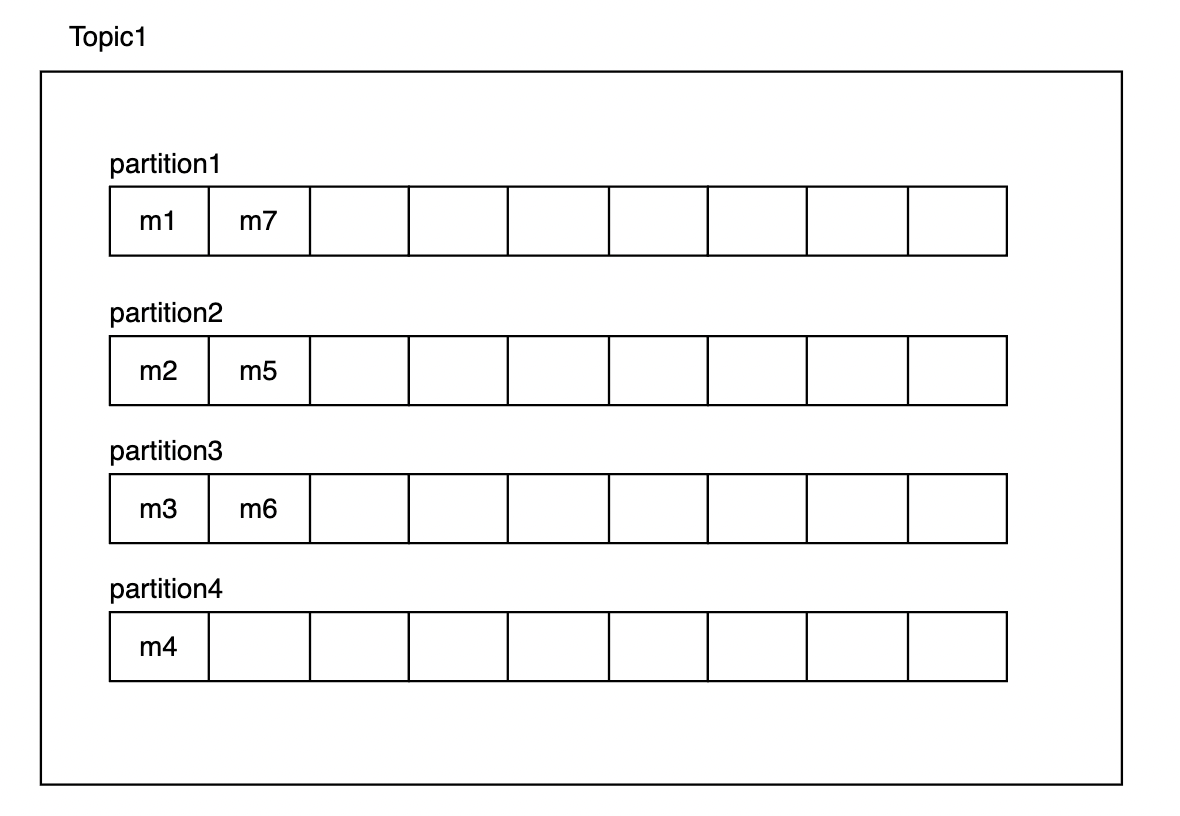
producer가 Topic1( partition 수: 4)로 m1~m7까지 메시지를 보내면 다음과 같이 각 partition에 메시지를 송신 할 수 있습니다. kafka에서는 consumer가 데이터를 처리하면 offset을 저장하여 어디까지 처리했는지 확인 할 수 있는데, 이 때 partition마다 offset을 따로 가지고 있기 때문에 병렬적인 처리가 가능합니다.
또한 partition마다 순서가 없기 때문에 해당 데이터는 m1~m7의 순서로 소비된다는 보장이 없습니다. 만약 원래 순서대로 지켜지기를 원한다면 partition을 1개로 해서 순서를 보장 받을 수 있습니다. (각 partition 내의 queue는 순서대로 처리됨.)
+ 추가로 한 Topic내 partition들이 꼭 같은 kafka 서버에 존재하는 것은 아닙니다. kafka 서버가 여러개 일 때 partition을 여러개로 주면 partition이 분산되어 있을 수 있습니다.
2-3) Replication
Replication은 Topic이 복제된 갯수를 말합니다. Topic을 복제하여 kafka 서버가 다운되어도 정상적으로 동작 할 수 있는 안전성을 확보 할 수 있습니다.
예를 들어, 3개의 kafka 서버에 Topic1의 replicaiton을 3으로 적용하면,
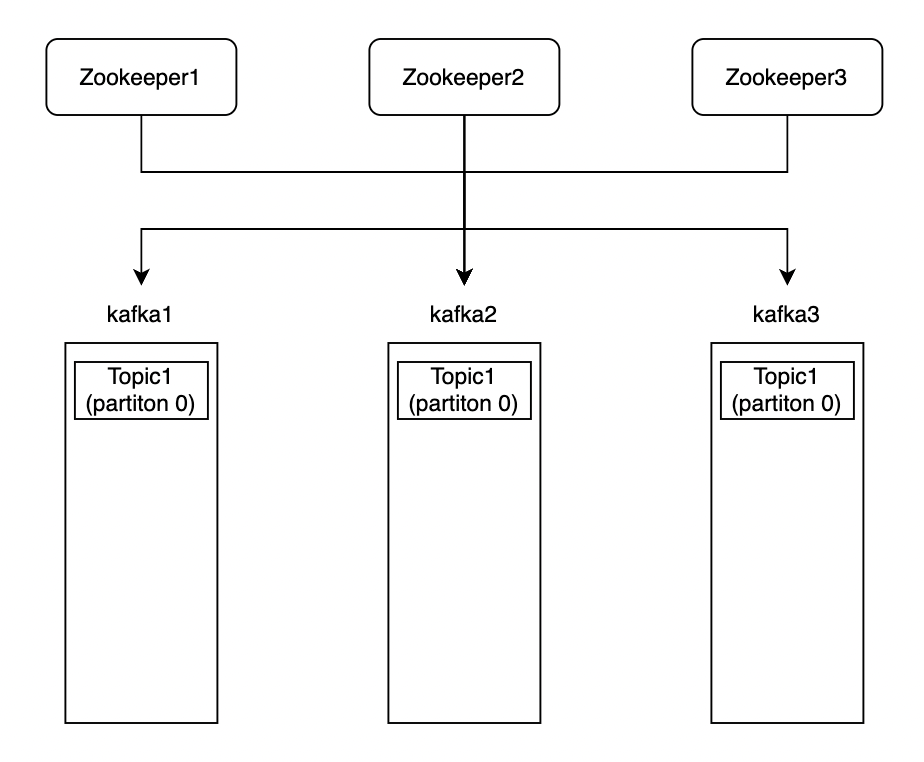
다음과 같은 형태로 존재합니다. 이 때, 위에서 확인 한 것처럼 Leader와 ISR을 확인 할 수 있습니다.
Kafka에서 Replication을 생성하면 Leader와 follower가 있는데, Leader에서만 read, write를 하고 follower는 Leader의 데이터를 복제하기만 합니다. 그러다 Leader의 서버가 죽으면 ISR에 해당하는 서버에서 임의의 서버가 Leader로 변하고 다시 동작하는 방식입니다.
위의 내용을 정리면 다음과 같은 사진을 이해 할 수 있습니다.

Topic 이름: announcement
Partiton 갯수: 1
ReplicationFactor: 3
- 한 개의 partition이 있구나.
- 해당 Topic의 partition 0은 현재 Leader가 3번 kafka server구나.
- Replication은 1, 2, 3번 kafka server에 복제되어 있구나.
- ISR을 보니 1, 2, 3번 모두 Leader가 될 수 있으니까 잘 동작하고 있구나.
3) Consumer Group
kafka에서는 Consumer Group을 통해 쉽게 확장 할 수 있습니다. Consumer Group이란 Group-Id를 통해 consumer를 그룹으로 관리하는 방법입니다.
Apache kakfa의 공식 홈페이지를 보면 kafka는 partition을 구독한 group 안에서 한 consumer가 처리하는 방식이라고 적혀 있습니다. 또한, 각 partition마다 consumer는 한 개만 두는 방식을 사용하여 message Ack를 보내는 것을 매우 가볍게 만듭니다.
즉, Consumer Group마다 독립적으로 Topic에 대한 정보를 저장하고 partition을 처리하기 때문에, group을 추가하는 방법으로 쉽게 확장성을 얻을 수 있습니다.
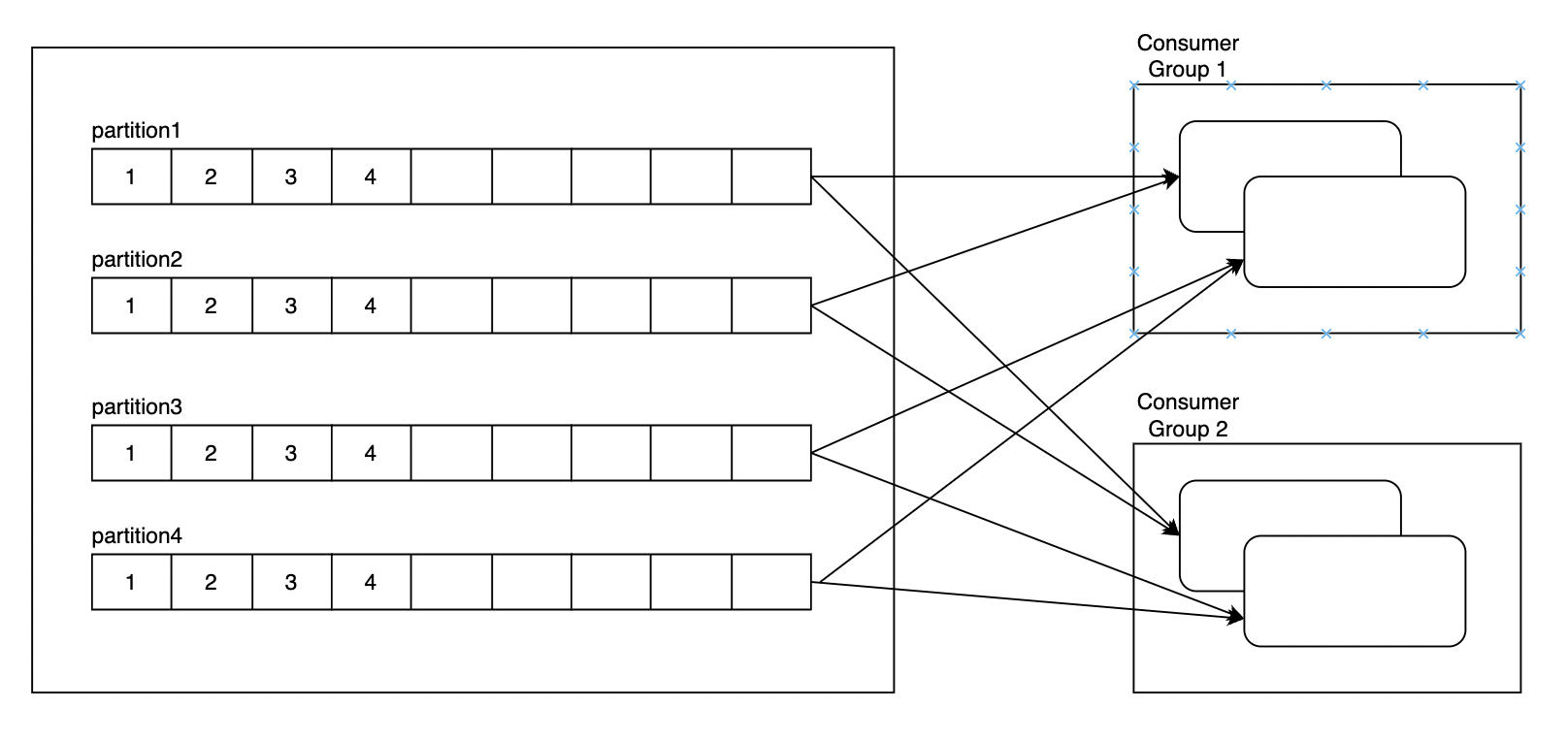
또한 Group을 통해 consumer를 여러대로 관리하면, 특정 consumer가 다운되었을 때, 다른 consumer가 partition을 처리 할 수 있게 되어 안전성도 높아집니다.
이상으로 기본적인 kafka 개념을 정리 할 수 있었습니다.
+ 추가 할 내용이나 부족한 부분이 있다면, 댓글 작성 부탁드립니다! :)
