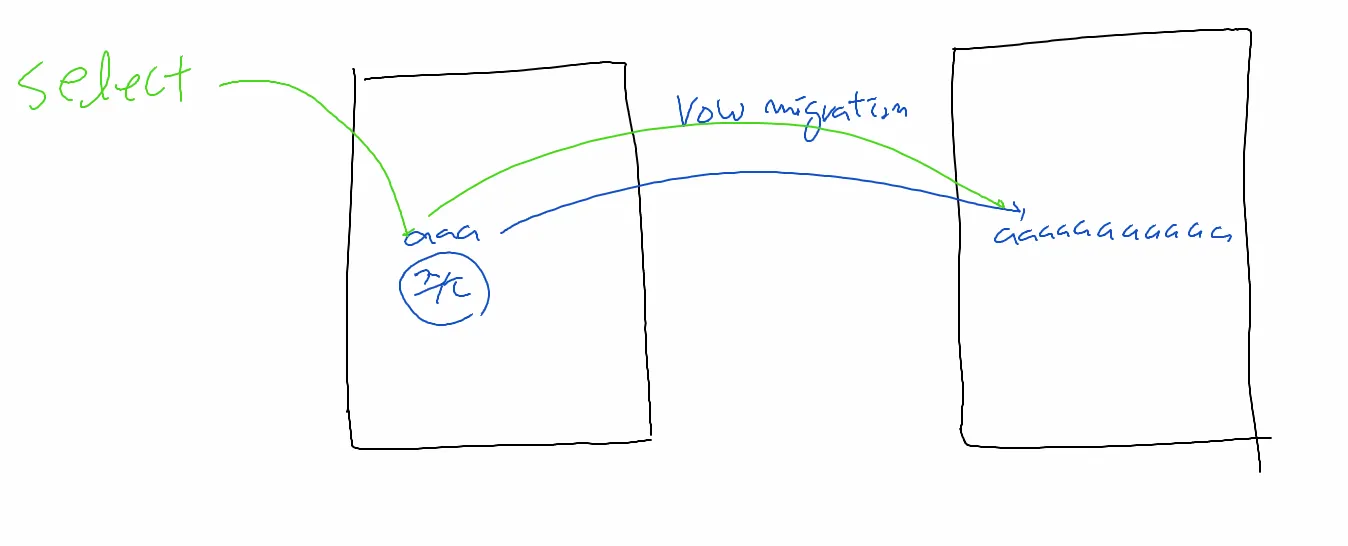
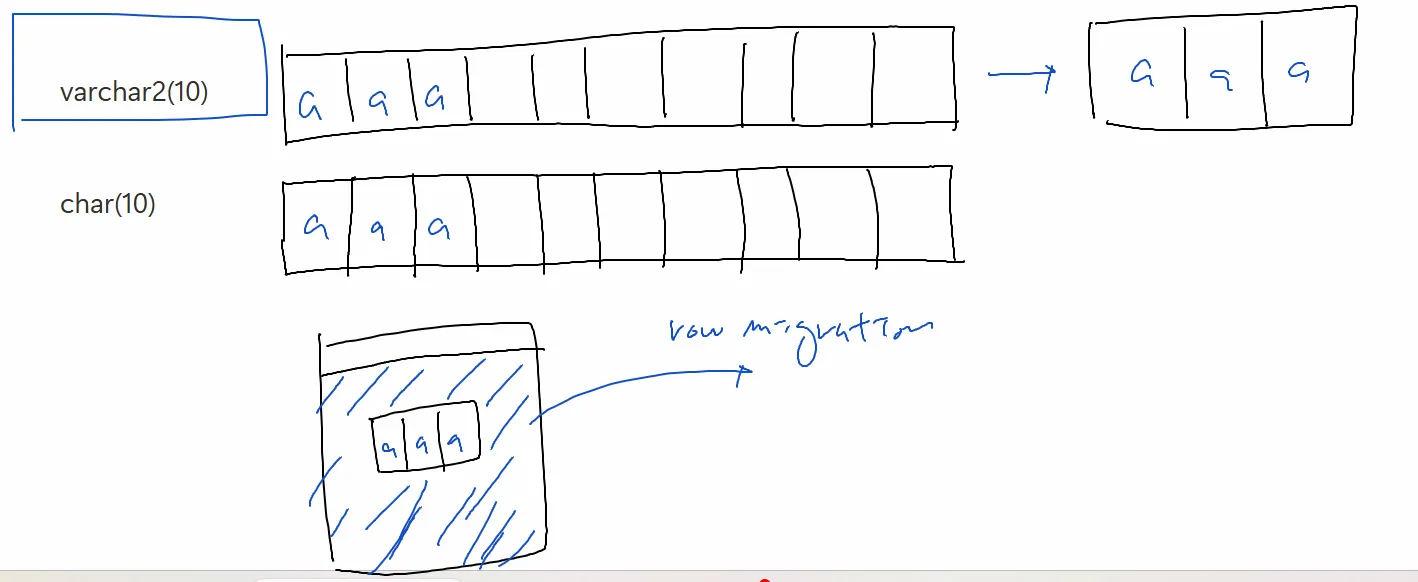
[이론1] row migration 현상이란?
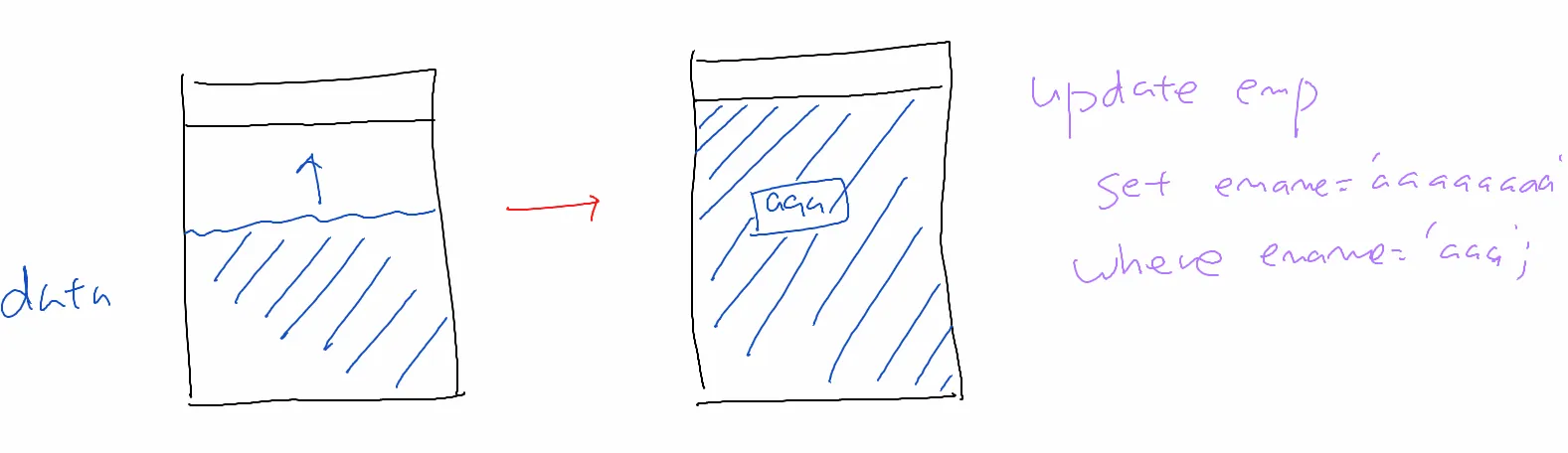
aaa를 aaaaaaaaaa로 업데이트 하게 되면 해당 블럭에 update를 하지 못하고
다른 블럭으로 가서 다시 aaaaaaaaaaaa를 구성하고
원래있던 자리에는 어느 블럭으로 이사갔다라고 적어줌
varchar2로 데이터 타입을 설정하지않고 char로 설정하면
row migration 현상을 줄일 수 있음
--> 그런데 이 이유때문에 char를 사용하지는 X. varchar2의 장점이 너무 커서 char 를 잘 쓰지 X
[이론2] pctfree와 pctused 파라미터
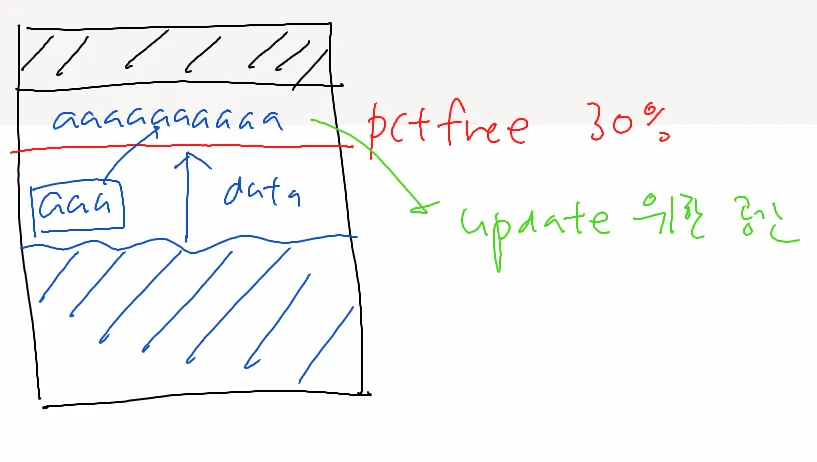
💡 pct free 영역
- 데이터 insert 안됨
- update를 위한 공간임
- 이 영역을 조금이라도 키우면 row migration 현상이 덜 발생함
- but 너무 키우면 data의 입력이 많이 안되기 때문에 공간 낭비 발생
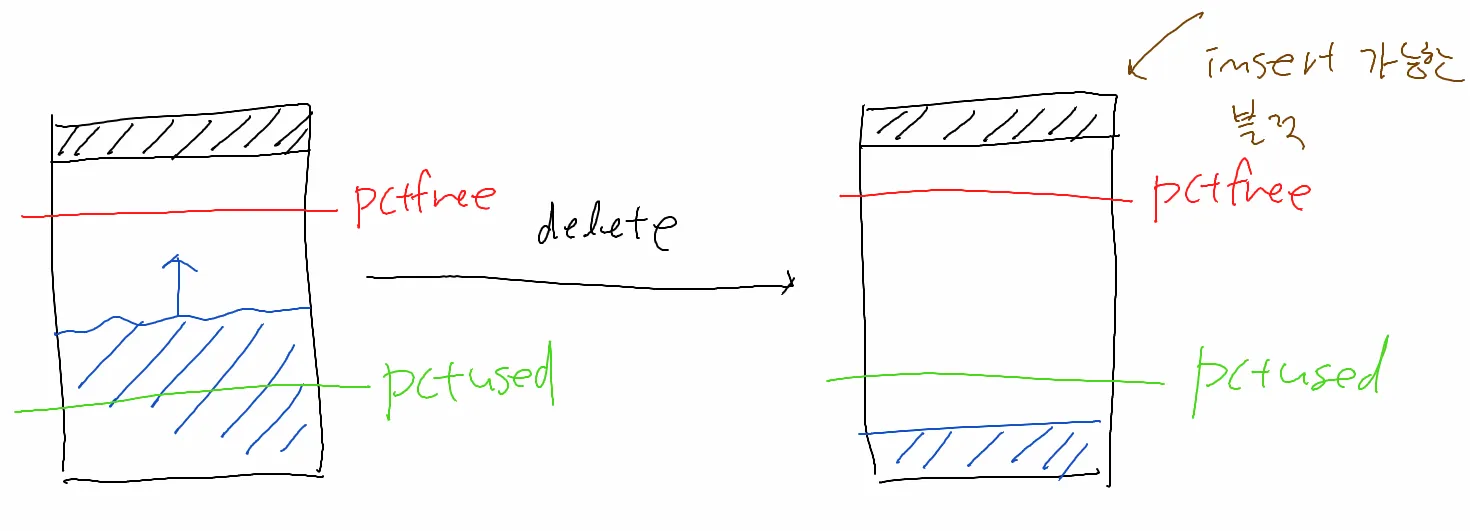
pctused 아래까지 데이터가 지워져야 insert가 가능한 블럭이 됨
[실습1] pctfree와 pctused를 설정하는 실습
select table_name, pct_free, pct_used
from user_tables;
create table emp600
( empno number(10),
ename varchar2(20),
sal number(10) )
pctfree 30
pctused 20;
select table_name, pct_free, pct_used
from user_tables;
alter table emp
pctfree 40;
select table_name, pct_free, pct_used
from user_tables;buffer busy wait라는 대기 이벤트가 일어나는 테이블이 아니라면 굳이 pctfree를 주고 만들 필요는 없음. 그냥 평상시 테이블 만들 듯이 생성하면 됨
--> 오라클이 공간관리를 자동화하면서 dba가 pctfree와 pctused를 크게 신경쓰지 않아도 되게 되었음
--> 다음과 같이 테이블스페이스를 생성하고 이 테이블스페이스에 테이블을 생성하면
오라클이 알아서 pctfree와 pctused를 자동조절 해주도록 자동화되었음
create tablespace ts400
datafile '/u01/app/oracle/oradata/ORA19/ts400.dbf' size 10m
segment space management auto;
drop emp400;
create table emp400
( empno number(10),
ename varchar2(20),
sal number(10) )
tablespace ts400;
select tablespace_name, extent_management, segment_space_management
from dba_tablespaces; 위와 같이 테이블스페이스를 만들고 테이블을 생성하면 pctfree 관련 성능이슈들이 확실히 줄어듦
[실습2] row migration 현상 테스트하기
? : 오라클 홈 디렉토리로 가는 코드
('/u01/home/oracle/...' 와 같음)
-- scott으로 접속하기
1. row migration 현상이 일어났는지 확인하기 위한 테이블을 생성합니다.
PROD> @?/rdbms/admin/utlchain.sql
Table created.
PROD> desc chained_rows
2. emp 테이블에 row migration 현상이 일어났는지 분석합니다.
PROD> analyze table emp list chained rows ;
3. 분석된 결과를 확인합니다.
PROD> select count(*) from chained_rows;
0 이 나옵니다. row migration 이 발생안했습니다.
4. row migration 현상이 발생하게끔 update를 수행
PROD> alter table emp modify job varchar2(100);
PROD> update emp
set job='aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa';
5. emp 테이블을 분석합니다.
PROD> analyze table emp list chained rows;
6. 분석된 결과를 확인합니다.
PROD> select count(*) from chained_rows;
PCT FREE 가 여유가 넘쳐서 row migration 이 발생하지 않은것 입니다.
아주 이상적인 상태입니다.
7. row migration 이 일어날 수 있도록 다시 emp 테이블을 재구성합니다.
PROD> @/home/oracle/demo.sql
8. emp 테이블의 pct free 를 1로 변경합니다.
PROD> alter table emp pctfree 1;
9. row migration 이 발생하겠금 update 를 수행합니다.
PROD> alter table emp modify job varchar2(4000);
PROD> update emp
set job='aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa';
10. emp 테이블을 분석하고 결과를 확인합니다.
PROD> analyze table emp list chained rows;
PROD> select count(*) from chained_rows;
이제 부터 emp 테이블 검색할 때 성능이 떨어지게 됩니다.
그래서 dba 나 db 엔지니어가 이 현상을 해결해줘야합니다.
11. 위의 현상을 해결하기 위해서 emp 테이블을 다른 테이블 스페이스로
move 합니다. 또는 같은 테이블 스페이스내에서 move 해도 됩니다.
PROD> select table_name, tablespace_name
from user_tables
where table_name='EMP';
PROD> alter table emp move tablespace ts07;
12. emp 테이블을 분석하고 row migration 된 row 들이 정리되었는지 확인합니다.
PROD> truncate table chained_rows;
PROD> analyze table emp list chained rows;
PROD> select count(*) from chained_rows;문제1. 다음의 테이블을 생성하고 row migration을 일으키고 해결하시오
create table EMPLOYEES
as
select *
from hr.employees;
select * from employees;
alter table employees
modify email varchar2(4000);
update employees
set email='aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa';
truncate table chained_rows;
analyze table employees list chained rows;
select * from chained_rows;
truncate table chained_rows;
select table_name, tablespace_name
from user_tables
where table_name='EMPLOYEES';
alter table employees
move tablespace users;
analyze table employees list chained rows;
select * from chained_rows;
select tablespace_name, extent_management, segment_space_management
from dba_tablespaces
where tablespace_name='USERS';MOVE한 테이블스페이스의 extent 관리방식이 local로 되어있고, segment 관리방식이 auto로 되어있는지 확인하고,
만약 안되어있다면 되어있는 다른 테이블스페이스로 이동하거나 생성해서 이동시킴
create tablespace ts708
datafile '/home/oracle/ts708.dbf' size 100m
extent management local
segment space management auto;
alter table employees
move tablespace ts708;💡 row migration 현상과 더불어 row chaining 현상이란?
: 하나의 row의 길이가 너무 길어서 하나의 row가 하나의 블럭안에 못 들어갈 때
꼬리 부분을 다른 블럭에 걸쳐서 저장하는 현상
--> row migration처럼 특정 행을 읽기 위해서 여러 개의 블럭을 읽어야하므로 성능이 느려짐
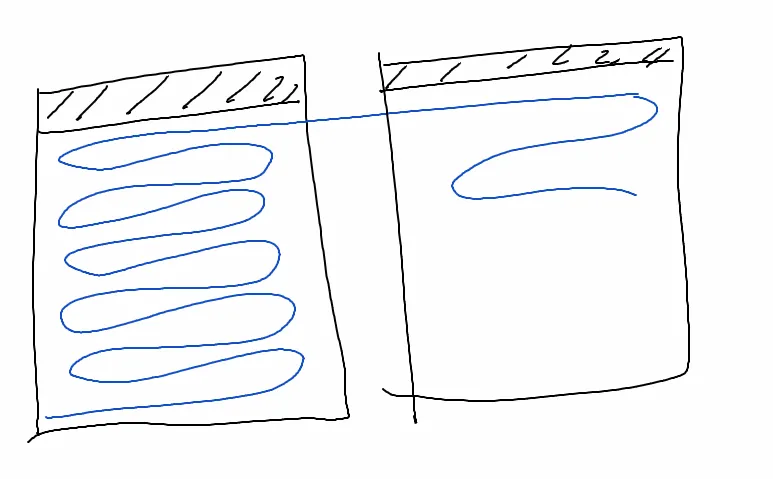
--> 블럭의 크기가 기본이 8kb 입니다. 이 블럭의 크기를 크게 만들면 어느 정도 해결할 수 있음
SCOTT @ ORA19 > show parameter db_block_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_block_size integer 8192
SCOTT @ ORA19 >
SCOTT @ ORA19 > select 8192/1024 from dual;
8192/1024
----------
8
SCOTT @ ORA19 >
alter system set db_32k_cache_size=64m;
create tablespace tsblock32
datafile '/home/oracle/tsblock01.dbf' size 10m
blocksize 32k;
create table emp32
tablespace tsblock32
as
select * from scott.emp;큰 블럭으로 테이블을 생성하면 행의 길이가 길어도 하나의 블럭안에 다 들어갈 가능성이 높아짐
문제1. 16k 블럭으로 저장할 테이블을 emp16으로 생성할 수 있게 셋팅하시오
alter system set db_16k_cache_size=64m;
create tablespace tsblock16
datafile '/home/oracle/tsblock02.dbf' size 10m
blocksize 16k;
create table emp16
tablespace tsblock16
as
select * from scott.emp;💡 지원되는 블럭의 크기:
2k, 4k, 8k, 16k, 32k
📌 row migration 현상 vs. row chaining 현상
- row migration
:update할 때 행의 길이가 길게 업데이트 돼서 발생하는 현상
- row chaining
:insert할 때 행의 길이가 너무 길어서 발생하는 현상
