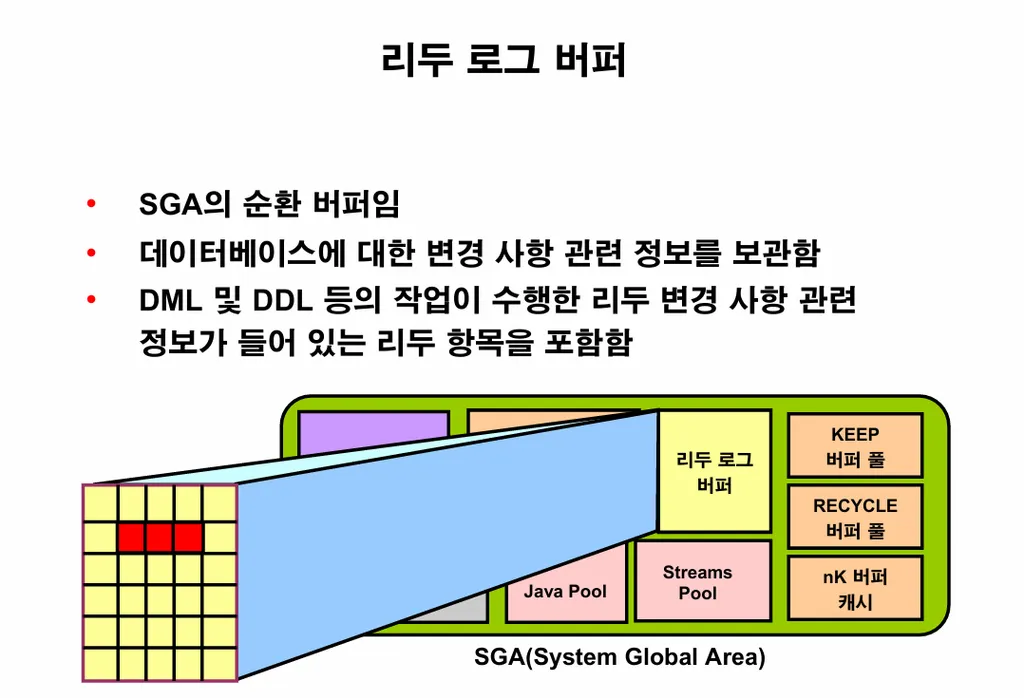
이론1. redo log buffer의 역할
💡 redo(다시하다 —> 다시 작업하다 —> 복구하다) data 를 저장하는 메모리 영역
장애가 났을 때 복구를 하기 위한 변경사항들이 적혀있는 메모리 영역
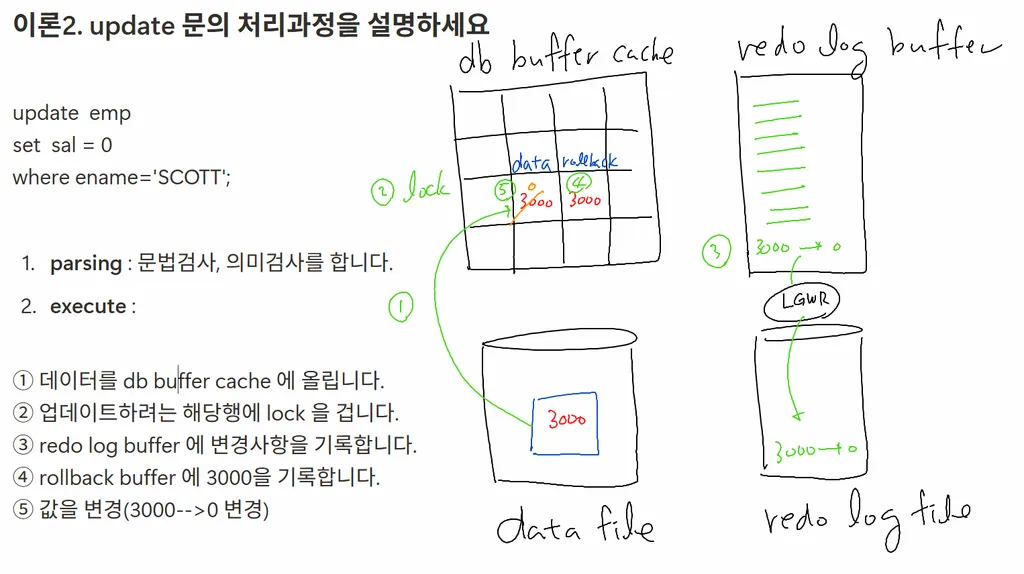
이론2. update 문의 처리과정을 설명하세요
update emp
set sal = 0
where ename='SCOTT';
- parsing : 문법검사, 의미검사를 합니다.
- execute :
① 데이터를 db buffer cache 에 올립니다.
② 업데이트하려는 해당행에 lock 을 겁니다.
③ redo log buffer 에 변경사항을 기록합니다.
④ rollback buffer 에 3000을 기록합니다.
⑤ 값을 변경(3000-->0 변경)
실습1. 리두 로그 버퍼의 크기를 확인하시오
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_buffer big integer 7360K💡 7메가 밖에 안되는 작은 메모리 공간입니다. 이 공간에 DML문장과 DDL문장들이 저장이 됩니다.
저장되면서 나중에 장애가 나서 복구할 때 이 문장들을 사용합니다. 이 공간은 순환적으로 사용되므로 이전 내용은 사라지고 새로운 내용이 계속 업데이트 됩니다. 이전 내용은 LGWR 에 의해서 리두로그 파일에 내려써집니다.
실습2. DML작업이 활발한 쿠팡같은 곳의 DB는 반드시 이 리두로그 버퍼의 사이즈를 늘려야합니다. 너무 작으면 Log buffer space 라는 대기 이벤트가 발생하면서 update 나 insert 성능이 느렵니다. 이 크기를 늘리시오
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_buffer big integer 7360K
SQL>
SQL>
SQL>
SQL> select 7360/1024 from dual;
7360/1024
----------
7.1875
SQL> alter system set log_buffer=16m scope=both;
alter system set log_buffer=16m scope=both
*
1행에 오류:
ORA-02095: 지정된 초기화 매개변수를 수정할 수 없습니다
SQL> alter system set log_buffer=16m scope=spfile;
시스템이 변경되었습니다.
SQL> shutdown immediate
데이터베이스가 닫혔습니다.
데이터베이스가 마운트 해제되었습니다.
ORACLE 인스턴스가 종료되었습니다.
SQL> SQL>
SQL>
SQL> startup
ORACLE 인스턴스가 시작되었습니다.
Total System Global Area 1979709008 bytes
Fixed Size 8898128 bytes
Variable Size 452984832 bytes
Database Buffers 1493172224 bytes
Redo Buffers 24653824 bytes
데이터베이스가 마운트되었습니다.
데이터베이스가 열렸습니다.
SQL>
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_buffer big integer 16M
SQL>💡 dba를 위한 리두로그 버퍼관련 팁
모든 DML과 DDL과 DCL작업은 전부 REDO LOG BUFFER에 변경사항이 기록됩니다. 그 기록하는 시간때문에 어떤 특정 작업이 느려질수 있습니다. 그래서 기록하지 말고 특정작업을 수행하라고 할 수 있습니다.
--> 대표적인게 인덱스 생성작업입니다.
실습3. 인덱스 생성시 리두 로그 버퍼의 기록되지 않게 하시오
-- scott 에서 작업하세요.
create index emp_sal
on emp(sal)
nologging
parallel 12;
alter index emp_sal logging;
alter index emp_sal parallel 1;
select index_name, logging, degree
from user_indexes
where index_name='EMP_SAL'; 문제1. (데이터 마이그레이션) hr 계정의 employees 테이블을 scott 계정에 만드시오
create table employees
as
select *
from hr.employees;
select * from employees;문제2. (데이터 마이그레이션2) hr 계정의 employees 테이블의 인덱스를 scott 계정에 employees 테이블에 똑같이 생성하시오
select *
from dba_ind_columns
where table_name='EMPLOYEES';
create table employees
as
select *
from hr.employees;
select * from employees;
create unique index EMP_EMAIL_UK on employees(email);
alter table employees
add constraint EMP_EMP_ID_PK primary key(EMPLOYEE_ID);
create index EMP_DEPARTMENT_IX on employees(DEPARTMENT_ID) nologging parallel 12;
create index EMP_JOB_IX on employees(job_id) nologging parallel 12;
create index EMP_MANAGER_IX on employees(manager_id) nologging parallel 12;
create index EMP_NAME_IX on employees(last_name, first_name) nologging parallel 12;
select *
from dba_ind_columns
where table_name='EMPLOYEES';문제3. (데이터 이행 프로젝트) HR 계정의 departments 테이블을 scott에 똑같이 생성하는데 인덱스와 제약도 똑같이 생성되게하시오
create table departments as select * from hr.departments;
alter table departments
add constraint DEPT_ID_PK primary key(DEPARTMENT_ID);
create index DEPT_LOCATION_IX on departments(LOCATION_ID) nologging parallel 12;
alter index DEPT_LOCATION_IX logging;
alter index DEPT_LOCATION_IX parallel 1;
select index_name, logging, degree
from user_indexes
where index_name like 'DEPT_%'; 