D+44-조건.단어찾기,NULL찾기,정렬, 함수.문자함수.대소문자변경,문자길이출력,붙이기,자르기,특정문자찾기,반복,공백제거, 숫자함수.올림,내림,버림,반올림,나머지,날짜함수.현재,미래,과거
학원 일기
조건을 붙여 조회하기(where)
like 검색 예약어
like를 이용해서 특정 단어를 포함하는 data를 검색할 수 있다. 검색 방법은 다음과 같다.
특정단어로 시작하는 data 검색
LIKE 검색시 아무단어나 올수 있다는 표시로 "%"를 해준다. 특정 단어로 시작하는 것은 '단어%'로 표현할 수 있다.
- 질의 : SELECT 컬럼 FROM 테이블명 WHERE 컬럼 LIKE '단어%';
SELECT * FROM EMPLOYEE
WHERE ENAME LIKE 'F%';F로 시작하는 데이터를 검색했다.
특정단어로 끝나는 data 검색
특정 단어로 끝나는 것은 '%단어'로 표현할 수 있다.
- 질의 : SELECT 컬럼 FROM 테이블명 WHERE 컬럼 LIKE '%단어';
SELECT * FROM EMPLOYEE
WHERE ENAME LIKE '%F';F로 끝나는 데이터를 검색했다.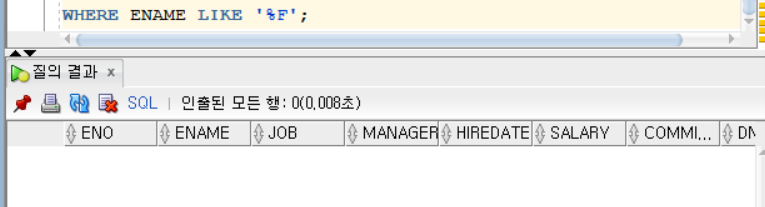
검색 결과는 없다.
특정 단어를 포함하는 데이터 검색
특정 단어를 포함하는 것은 '%단어%'로 표현할 수 있다.
- 질의 : SELECT 컬럼 FROM 테이블명 WHERE 컬럼 LIKE '%단어%';
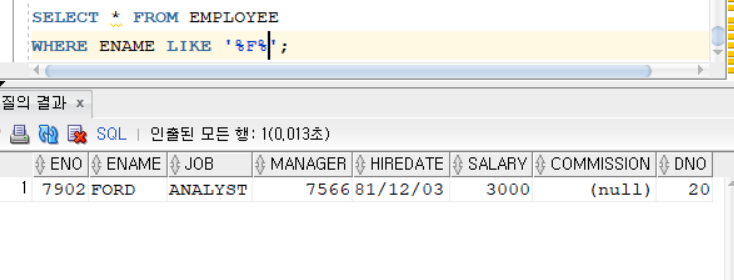
SELECT * FROM EMPLOYEE
WHERE ENAME LIKE '%F%';F로 끝나거나 시작하는 단어도 F를 포함하는 단어에 포함된다.
특정 단어가 N번째인 데이터 검색
특정 단어가 N번째인 데이터 검색은 '_(N-1만큼)단어%'를 해주면된다.
- 질의 : SELECT 컬럼 FROM 테이블명 WHERE 컬럼 LIKE '_(N-1만큼)단어%';
이름의 세번째가 A로인 데이터를 찾아보자
SELECT * FROM employee
WHERE ENAME LIKE '__A%';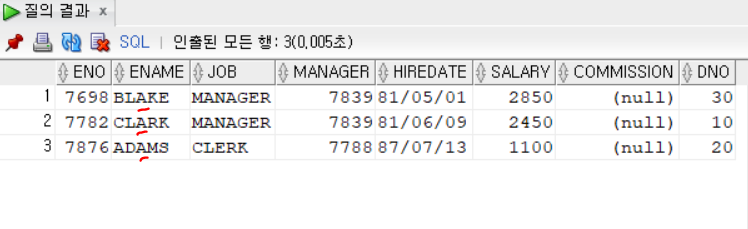
NOT LIKE 포함하지 않는단어 찾기
LIKE도 NOT을 붙이면 부정의 의미가 된다.
- 'A'로 시작하지 않는 단어
- 'A'로 끝나지 않는 단어
- 'A'를 포함하지 않는 단어
- N번째에 'A'가 오는 단어
모두 앞에 NOT만 붙이면된다.
IS, NULL 검색하기
NULL은 연산이 안되기 때문에 "="로 검색을 할 수가 없다.
예를 들어 다음과 같이 쿼리를 작성할 수 없다.
SELECT * FROM EMPLOYEE
WHERE COMMISSION = NULL; -- X (결과 없음)그래서 NULL을 찾고 싶은경우에는 IS예약어를 사용해야한다.
- 질의 : SSELECT 컬럼 FROM 테이블명 WHERE 컬럼 IS NULL;
ELECT * FROM employee
WHERE COMMISSION IS NULL;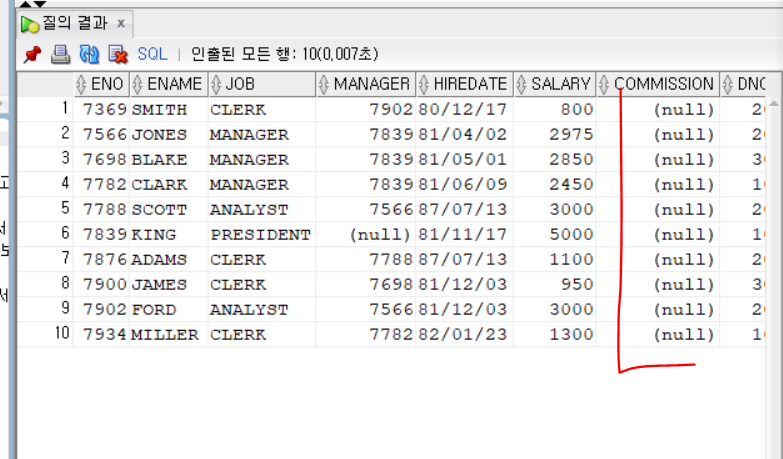 상여금이 NULL인 데이터만 검색이 되었다.
상여금이 NULL인 데이터만 검색이 되었다.
IS NOT, NULL이 아닌 검색결과
IS뒤에 NOT만 붙여주면 된다.
ORDER BY ASC 오름차순 정렬
값의 자료형과 상관없이 데이터 오름차순과 내림차순 정렬이 가능하다. 이때 오름차순과 내림차순의 차이는 ASC와 DESC의 차이만 있고 앞의 예약어는 다 똑같다.
- 질의 : SELECT 컬럼 FROM 테이블 ORDER BY 컬럼 ASC;
SELECT * FROM employee
ORDER BY SALARY ASC;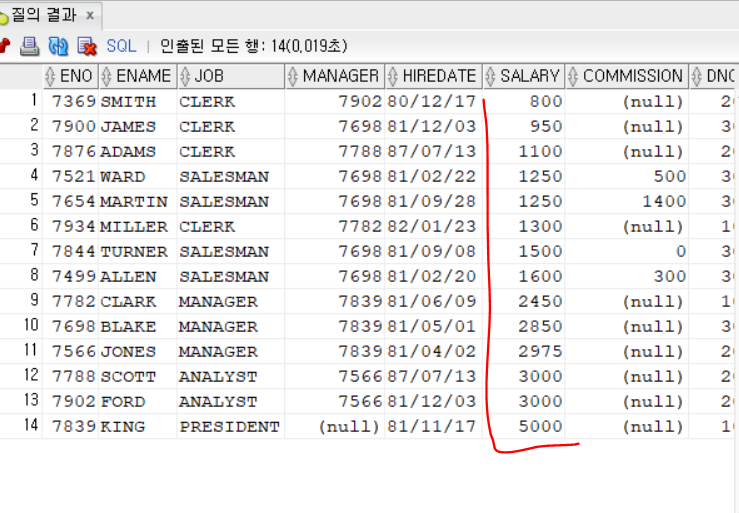
월급이 오름차순으로 정렬된 것을 볼수 있다.
여기서 ASC는 생략이 가능하다. 오름차순이 기준값이기 때문이다.
ORDER BY DESC 내림차순 정렬
내림차순은 ASC가 아닌 DESC를 해주면된다. 하지만 이것은 생략이 불가능하다.
- 질의 : SELECT 컬럼 FROM 테이블 ORDER BY 컬럼 DESC;
SELECT * FROM employee
ORDER BY ENAME DESC;이름 내림차순으로 정렬해보자.
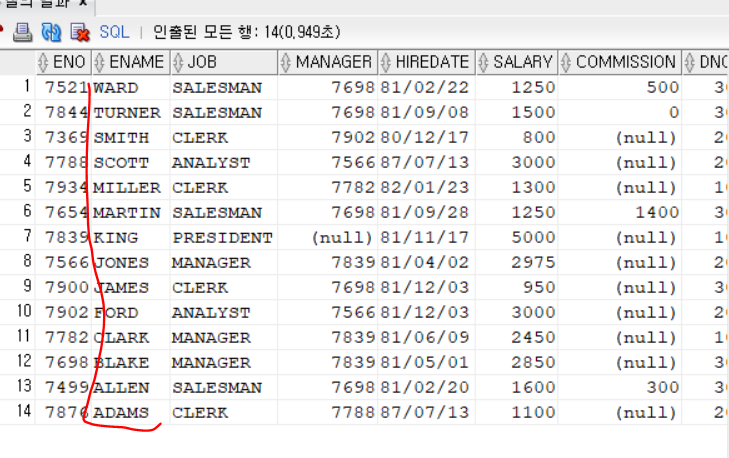 이름이 내림차순으로 정렬되었다.
이름이 내림차순으로 정렬되었다.
동일한 값에대한 정렬
만약 정렬을 했을경우 동일한 값이 있을 수가 있다. 이때 다른 조건으로 그 정렬을 세분화 할 수 있다.
- 질의 : SELECT 컬럼 FROM 테이블 ORDER BY 컬럼 ASC(DESC), 컬럼2 ASC(DESC);
SELECT * FROM employee
ORDER BY salary DESC, ENAME ASC;월급이 같을 때 이름의 내림차순으로 정렬해보자.
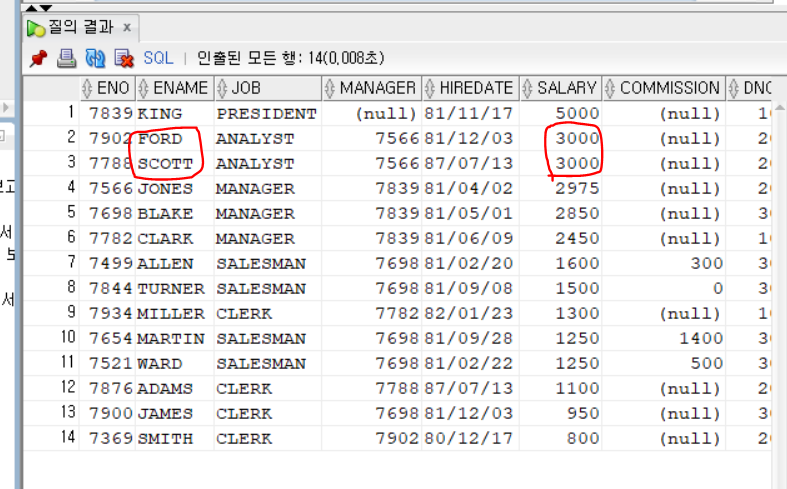 월급이 같을때 이름이 내림차순으로 정렬되었다.
월급이 같을때 이름이 내림차순으로 정렬되었다.
FUNCTION 함수
DB에도 함수가 있다.
문자함수
대소문자 변경 함수
문자를 대문자로 바꾸거나, 소문자로 바꾸거나, 첫글자만 대문자로 바꿔주는 함수들이 있다.
- 대문자 바꾸기 함수 : UPPER('문자열') OR UPPER(컬럼명)
- 소문자 바꾸기 함수 : LOWER('문자열') OR LOWER(컬럼명)
- 첫 글자만 대문자 바꾸기 함수 : INITCAT('문자열') OR LOWER(컬럼명)
문자열 문자함수 출력
SELECT 'Oracle mania', UPPER('Oracle mania') AS "대문자",
LOWER('Oracle mania') AS "소문자",
INITCAP('Oracle mania') AS "첫 글자 대문자" FROM DUAL;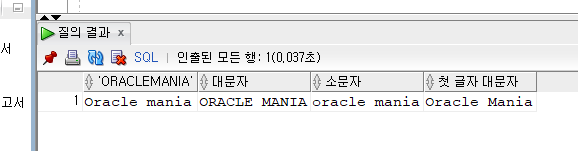
컬럼 문자함수 출력
컬럼은 따옴표를 빼주어야하고, SELECT 바로뒤에 함수를 써주면된다.
- 질의 : SELECT LOWER(컬럼명), INITCAP(컬럼명) FROM 테이블;
SELECT 'Oracle mania', UPPER('Oracle mania') AS "대문자",
LOWER('Oracle mania') AS "소문자",
INITCAP('Oracle mania') AS "첫 글자 대문자" FROM DUAL;
SELECT LOWER(ENAME), INITCAP(JOB) FROM employee;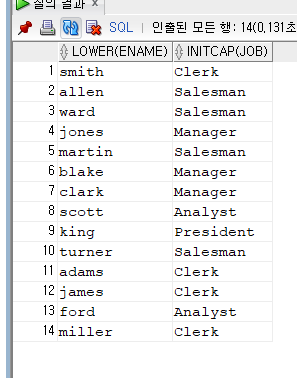 값들의 문자들이 변형되어서 나온다.
값들의 문자들이 변형되어서 나온다.
조건문에 사용
조건문에도 사용이 가능하다.
- 질의 : SELECT 컬럼 FROM 테이블 WHERE 컬럼 = UPPER('문자열');
데이터 베이스에 값들이 대문자로 되어있을때 외부에서 들어오는 값이 소문자라면 매칭이 안되니 다음과 같이 쿼리를 짜주면 매칭을 시킬 수 있다.
SELECT ENO, ENAME, DNO FROM employee
WHERE ENAME = UPPER('scott');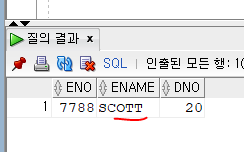
소문자로 입력이 되어도 매칭이 잘 된 것을 볼 수 있다.
LENGTH 문자의 길이 출력 함수
문자의 길이가 몇인지 출려해주는 함수가 있다.
- 함수 : LENGTH('문자열')
SELECT LENGTH('ORACLE MANAGER'),
LENGTH('오라클 매니저') FROM DUAL;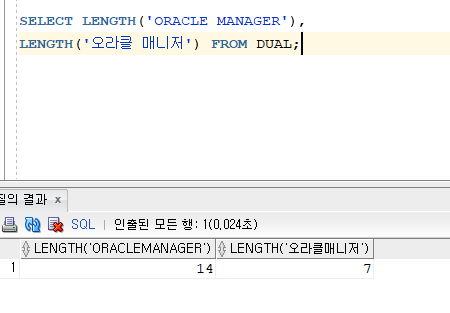
문자열의 길이가 출력된다.
CONCAT 문자열 붙이기 함수
문자열 붙이기는 두 가지 방법이 있다. 함수를 사용하거나 예약어를 사용하는 방법이 있다.
- 함수 : CONCAT('문자열', '문자열'), CONCAT('컬럼', '컬럼')
- 질의 : SELECT '문자열' || '문자열' FROM DUAL;
SELECT CONCAT('ORACLE', 'MANIA') FROM DUAL;
SELECT 'ORACLE' || 'MANIA' FROM DUAL;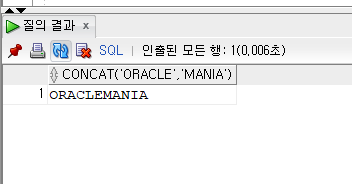 두문자열이 합쳐져서 출력된다.
두문자열이 합쳐져서 출력된다.
컬럼 붙이기
SELECT CONCAT(ENAME, SALARY) FROM employee;이름과 월급을 붙여보자
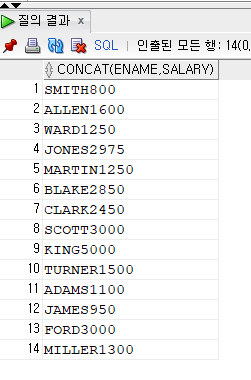 두종류의 데이터가 합쳐서 출력되었다.
두종류의 데이터가 합쳐서 출력되었다.
SUBSTR 문자열 자르기
문자열 합치기 뿐만 아니라 자르기도 가능하다.
DB에서도 인덱스 번호가 있는데 자바와는 다르게 1부터 시작이다.
- 함수 : SUBSTR('문자열', 시작지점, 자를 문자 개수)
SELECT SUBSTR('ORACLE MANIA', 4, 3),
SUBSTR('ORACLE MANIA', -1, 1) FROM DUAL;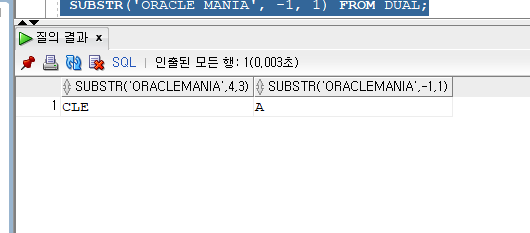
4번째 자리의 문자인 C부터 3개인 CLE가 출력되고, 음수는 거꾸로 시작되므로 뒤에서 1번째인 A부터 1개인 A가 출력된다.
INSTR 문자열에서 특정 문자 찾기
특정문자가 몇 번째 인덱스에 있는지를 찾는 함수가 있다.
- 함수 : INSTR('문자열', '문자')
SELECT INSTR('ORACLE MANIA', 'A') FROM DUAL;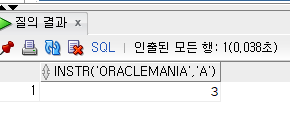 문자열에서 A가 세번째에 있다는 것을 알수있다. 이 때 젤 처음의 인덱스만 찾아주고 뒤에 A가 또 있더라도 그 값은 나오지 않는다.
문자열에서 A가 세번째에 있다는 것을 알수있다. 이 때 젤 처음의 인덱스만 찾아주고 뒤에 A가 또 있더라도 그 값은 나오지 않는다.
PAD 문자열 반복 붙이기
문자열에 특정 문자열을 반복해서 붙이는 함수가 있다. 이 함수는 특직이 있는데
- 자리수를 정해야한다.
- 반복해서 붙여준다.
이다.
붙이는 방향에 따라 RPAD, LPAD가 있다. R = RIGHT, L = LEFT
- 함수 : LPAD('문자열'(컬럼), 만들어지는 문자의 총 길이, '반복할 문자열')
SELECT LPAD(SALARY, 10, '*')
FROM EMPLOYEE;EMPLOYEE 테이블에서 월급에 별을 총 길이가 10자리가 되도록 왼쪽에 붙여보자.

TRIM 문자열 공백 제거
문자열의 공백을 제거하는 함수가 있는데, 양쪽, 오른쪽, 왼쪽의 공백을 제거할 수 있다.
- 양쪽 함수 : TRIM('문자열')
- 오른쪽 함수 : RTRIM('문자열')
- 왼 함수 : LTRIM('문자열')
SELECT 'Oracle mania'
, LTRIM(' Oracle mania ')
, RTRIM(' Oracle mania ')
, TRIM(' Oracle mania ')
FROM DUAL;
숫자함수
ROUND 반올림함수
반올림함수이다.
- 함수 : ROUND(숫자, 반올림되는 자리수)
SELECT 98.7654
, ROUND(98.7654)
, ROUND(98.7654, 2)
, ROUND(98.7654, 1)
, ROUND(98.7654, -1)
FROM DUAL;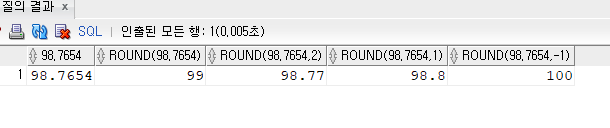
자릿수 주의
자릿수가
- 양수일 때 : 1은 소수점 두번째 자리에서 반올림한다. 첫번째가 아니니 헷갈리면 안된다.
- 음수일 때 : -1은 1의 자리에서 반올림해서 1의 자리는 0이된다.
- 아무것도 없을 때 : 소수점 첫째자리에서 반올림해서 소수점 밑의 값이 없다.
자릿수에 아무것도 안 적으면 소수점 첫째자리에서 반올림하고, -1은 일의 자리 -2는 십의 자리에서 반올림한다.
TRUNC 버림함수
- 함수 : TRUNC(수, 자릿수)
SELECT 98.7654
, TRUNC(98.7654)
, TRUNC(98.7654, 2)
, TRUNC(98.7654, -1)
FROM DUAL; 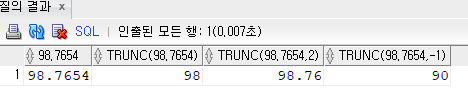
자릿수 주의
여기도 반올림과 자릿수가 같다
자릿수가
- 양수일 때 : 1은 소수점 두번째 자리에서 버림한다. 첫번째가 아니니 헷갈리면 안된다.
- 음수일 때 : -1은 1의 자리에서 버림해서 1의 자리는 0이된다.
- 아무것도 없을 때 : 소수점 첫째자리에서 버림해서 소수점 밑의 값이 없다.
FLOOR 내림함수
소수점을 다 없애버리는 함수이다. 자릿수를 정할 수 없다.
- 함수 : FLOOR(숫자)
SELECT 98.7654
, FLOOR(98.7654)
FROM DUAL;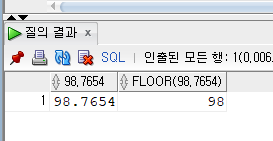
CEIL 올림함수
올림함수이다. 자릿수를 정할 수 없다.
- 함수 : CEIL(숫자)
SELECT 98.7654
,CEIL(98.7654)
FROM DUAL;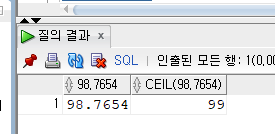
MOD 나머지 구하는 함수
DB에서는 나머지 연산자가 없어서 함수로 구해야한다.
- 함수 : MOD(나눠질 수, 나눌 수)
SELECT MOD(31,2)
FROM DUAL;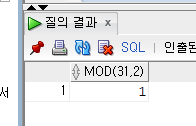
날짜함수(중요)
SYSDATE 현재 날짜 보기 함수
현재 날짜와 시간을 보여주는 함수이다.
함수라고 하지만 예약어에 가깝다.
- 질의 : SELECT SYSDATE FROM DUAL;
SELECT SYSDATE FROM DUAL;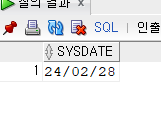
SYSDATE 에서 과거 미래 날짜 보기
SYSDATE에서 1을 하루로 계산해서 빼면 과거로, 더하면 미래로 갈 수 있다.
- 질의 : SELECT SYSDATE -1(+1) FROM DUAL;
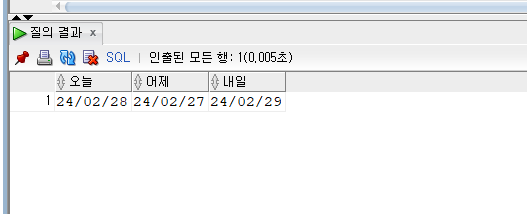
SELECT SYSDATE AS 오늘
,SYSDATE - 1 AS 어제
,SYSDATE + 1 AS 내일
FROM DUAL;