D+45-함수.날짜함수.날짜사이 개월 수,개월수 더하기,오는 요일, 달의 마지막날, 자료형변환.날짜를문자,숫자를문자,문자를날짜,문자를숫자, 일반함수.null처리,조건함수, 그룹함수.합,평균,최대,최소,갯수,중복제거,부분집계,부분집계조건절
학원 일기
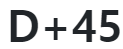
함수
날짜 함수
MONTHS_BETWEEN 날짜 사이 개월 수 구하기
날짜 사이에 개월 수를 구하는 함수가 있다. 근무 개월 수를 구할 때 사용할 수 있다.
- 함수 : MONTHS_BETWEEN(큰 날짜, 작은 날짜)
SELECT ENAME, TRUNC(MONTHS_BETWEEN(SYSDATE, HIREDATE))FROM EMPLOYEE;근무 개월 수를 구했다.
ADD_MONTHS 개월 수 더하기
특정 날짜에 월을 더하는 함수이다.
- 함수 : ADD_MONTHS(더하기 전 날짜, 더할 날짜)
SELECT ENAME, HIREDATE, ADD_MONTHS(HIREDATE,6) FROM employee;
입사일에서 6개월이 지난 시점이 언제인지 알 수 있다.
NEXT_DAY 오는 요일의 날짜 구하기
이 함수는 오는 특정 요일의 날짜를 구해주는 함수이다.
- 함수 : NEXT_DAY(특정 날짜, '오는 요일')
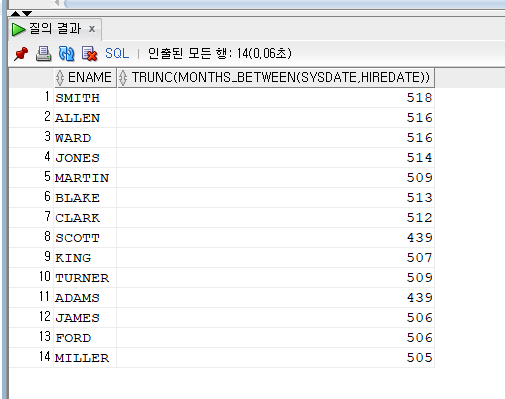
SELECT SYSDATE, NEXT_DAY(SYSDATE, '토요일') FROM DUAL;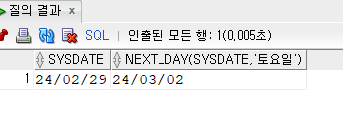
오늘로 부터 가장 가까운 토요일의 날짜를 구해준다.
LAST_DAY 달의 마지막 날 구하기
특정 날짜의 월에서 마지막 날이 28, 29, 30, 31인지 확인하고 싶을
때 사용할 수 있는 함수이다.
- 함수 : LAST_DAY(날짜)
SELECT ENAME, HIREDATE, LAST_DAY(HIREDATE)FROM employee;
월의 마지막 날짜를 보여준다.
자료형 변환 함수
DB의 자료형
문자열
- 가변 문자열 : 남은 자리수를 자동으로 축소해서 공간낭비를 안한다.
- 고정 문자열 : 자리수가 정해져 있어서 그 보다 작은 문자열에 대해서는 공간 낭비가 발생한다.
가변 문자열은 VARCHAR2이고 고정 문자열은 CHAR이다.
기타
- NUMBER로 표시하고 실수와 정수가 올 수 있다.
- 날짜 DATE로 나타낼 수 있다.
TO_CHAR 날짜를 문자형으로 바꾸는 함수
- 함수 : TO_CHAR(날짜, 원하는 날짜형식 문자형)
여기서 날짜형식 문자형은 문자로 된 날짜형식을 말한다. 예를들오 'YY-MM'등이다.
SELECT ENAME, HIREDATE, TO_CHAR(HIREDATE, 'YY-MM') AS 단축날짜,
TO_CHAR(HIREDATE, 'YYYY-MM-DD HH24:MI:SS') AS 날짜
FROM EMPLOYEE;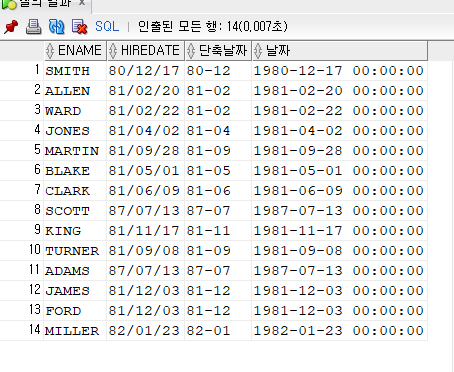
날짜 형식을 원하는 대로 나타낼 수 있다. 물론 자료형은 문자형으로 바뀌게 되지만 결과는 변하지 않는다.
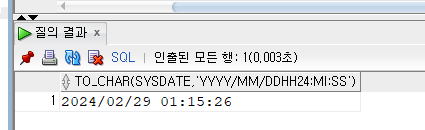
YYYY-MM-DD HH24:MI:SS 참고로 다음 날짜 형식은 24시간을 초단위까지 나타낼 수 있는 형식이다.
SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS') FROM DUAL;다음과 같이 현재날짜를 나타낼수도 있다.
TO_CHAR 숫자를 문자형으로 바꾸는 함수
TO_CHAR함수는 여러 자료형을 문자형으로 바꾸는 함수이다. 그래서 숫자도 이 함수로 문자형으로 만들 수 있다.
- 함수 : TO_CHAR(숫자, 'L999,999')
SELECT ENAME, SALARY, TO_CHAR(SALARY, 'L999,999'),
TO_CHAR(SALARY, 'L000,000')
FROM EMPLOYEE;999와 000의 차이는 000은 자릿수만큼 숫자가 채워지지 않으면 그 빈자리를 0으로 채운다. 그런데 999는 숫자만큼만 자릿수만 채워지게된다.
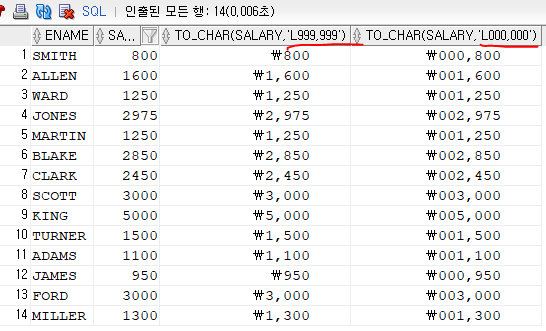
L은 소프트웨어에 저장된 국가의 통화로 나오게 하는것이고, 특정 나라의 통화를 보여주고 싶으면 그 나라의 통화를 적어주면 된다.
TO_DATE 문자형 날짜로 바꾸는 함수
문자형식으로 날짜를 입력하면 이것을 날짜 자료형으로 바꿔주는 함수이다.
- 함수 : TO_DATE('문자형식의 날짜', '날짜포맷')
여기서 날짜 포맷은 생략해도 오라클에서 알아서 해준다.
SELECT ENAME, HIREDATE FROM EMPLOYEE
WHERE HIREDATE = TO_DATE('19810220', 'YYYYMMDD');
SELECT ENAME, HIREDATE FROM EMPLOYEE
WHERE HIREDATE = TO_DATE('19810220')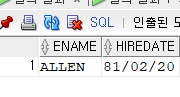 둘다 결과는 같게 나온다.
둘다 결과는 같게 나온다.
TO_NUMBER 문자형 숫자로 만들기
- 함수 : TO_NUMBER('문자형 숫자', '999,999')
SELECT
TO_NUMBER('100,000', '999,999'),
TO_NUMBER('900,000', '999,999')
FROM DUAL;문자형태를 숫자로 바꿨다. 원래 통화처럼 ","이 나와야하는데 숫자형으로 바꿔서 쉼표없이 출력된다.

일반 함수
NVL NULL을 숫자 또는 문자로 변경
전에도 했던 함수인데 전에는 숫자만 했지만 이번엔 문자를 해보자.
- 함수 : NVL(컬럼, 바꿀 문자나 숫자)
대신 문자는 문자형 숫자만 가능하다.
SELECT NVL(COMMISSION, '100')
FROM EMPLOYEE;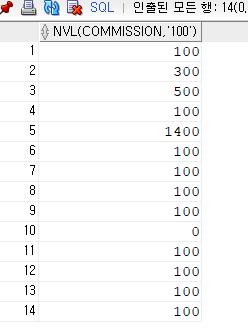
NULL값은 100으로 나타내진다.
DECODE 조건 함수
특정 값일때 특정이름으로 보이게 설정하고 싶을때 쓸 수 있다.
- 함수 : DECODE(컬럼, 값, 결과, 값2, 결과2, 기본값)
정해진 값이 없다면 기본값이 나오는 것이다. ELSE와 같다.
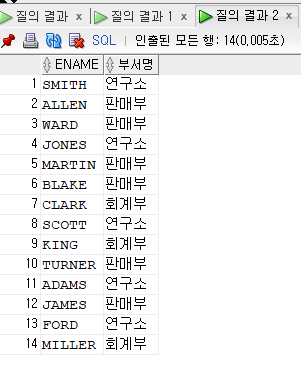
SELECT ENAME, DECODE(DNO,
10, '회계부'
, 20, '연구소'
, 30, '판매부'
, 40, '운영부'
, '디폴트') AS 부서명
FROM EMPLOYEE;DNO의 값에 따른 부서의 이름을 보여줘보자
CASE WHEN 조건 함수
이건 DECODE를 향상시킨 함수이다.
- 함수 : CASE WHEN 컬럼=값 THEN '결과' WHEN 컬럼=값2 THEN '결과2' ELSE 결과3
DECODE와는 다르게 명령어 형식이다. 좀더 직관적으로 볼 수 있다. ELSE로 기본값을 나타내고, 마지막에는 반드시 END를 해주어야한다.
SELECT ENAME, DNO
,CASE WHEN DNO=10 THEN '회계부'
WHEN DNO=20 THEN '연구소'
WHEN DNO=30 THEN '판매부'
WHEN DNO=40 THEN '운영부'
ELSE '디폴트'
END AS 부서명
FROM EMPLOYEE;
결과값에 연산도 가능하다.
SELECT ENO, ENAME, JOB, SALARY,
CASE WHEN JOB = 'ANALYST' THEN SALARY+200
WHEN JOB = 'SALESMAN' THEN SALARY+180
WHEN JOB = 'MANAGER' THEN SALARY+150
WHEN JOB = 'CLERK' THEN SALARY+100
ELSE SALARY+0
END
FROM EMPLOYEE;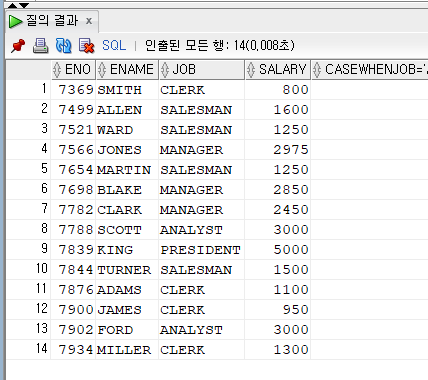
DECODE 와의 차별된 장점
DECODE는 부등호를 사용할 수 없었지만 이것은 사용이 가능하다.
그룹함수
데이터를 전체 또는 부분 집계하는 함수이다. 예를들어 최솟값, 최댓값, 평균, 총액 등이 있다.
SUM, AVG, MAX, MIN
- 함수 : 함수(컬럼)
SELECT SUM(SALARY) AS 총액
, ROUND(AVG(SALARY)) AS 평균
, MAX(SALARY) AS 최고액
, MIN(SALARY) AS 최소액
FROM EMPLOYEE;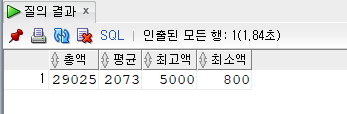
함수에 컬럼만 넣어주면 된다.
그룹함수 특징
- 참고로 그룹함수는 1건의 결과만 나오므로, 그룹함수를 제외한 다른 컬럼과는 사용이 불가능하다.
- NULL값은 계산에 포함하지 않는다.
COUNT 행의 갯수새기
- 함수 : COUNT(컬럼)
SELECT COUNT(ENAME) FROM EMPLOYEE;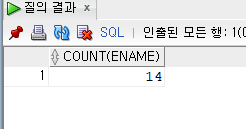
이름의 행의 갯수를 세어준다.
그런데 이 카운트 함수는 조건을 넣어서 쓸 수도 있다.
COMMISSION이 NULL인 행의 갯수를 구해보자
SELECT COUNT(*) FROM EMPLOYEE
WHERE COMMISSION IS NULL;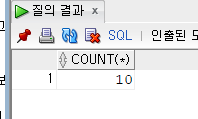
WHERE을 이용해 컬럼이 어떤 상태일때만 갯수를 셀 수 있다.
DISTINCT 중복제거로 종류세기
이 예약어와 COUNT를 사용하면 컬럼의 값의 종류를 셀 수 있다.
- 질의 : SELECT COUNT(DISTINCT 컬럼) FROM 테이블;
SELECT COUNT(DISTINCT JOB) FROM EMPLOYEE;COUNT안에 DISTINCT를 넣어주어야한다. 중복을 먼저 제거해주고 그것의 행을 세어야하기 때문이다.
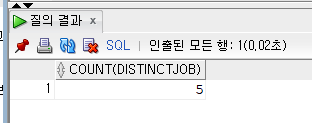 JOB에는 5종류의 직업이 있다는 것을 알 수 있다.
JOB에는 5종류의 직업이 있다는 것을 알 수 있다.
GROUP BY 부분집계하기
그룹에 따라서 그 그룹의 평균이나 총합 등을 알고 싶을 경우가 있다. 예를 들어 부서에 따른 월급의 평균을 알고 싶다고 하면 이때 부서를 나눠주는 애가 GROUP BY이다.
- 질의 : SELECT 그룹함수(컬럼) FROM 테이블 GROUP BY 컬럼;
SELECT DNO, TRUNC(AVG(SALARY)) FROM EMPLOYEE
GROUP BY DNO;여기선 특이한게 그룹함수와 컬럼을 같이 사용할 수 있다. 대신 반드시 GROUP BY에 해당하는 컬럼만 사용해야한다.
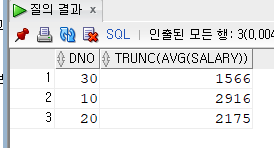 부서별 월급의 평균을 알 수 있다.
부서별 월급의 평균을 알 수 있다.
HAVING 그룹함수의 조건절
부분 집계를 한 중에서도 특정 조건의 에만 해당하는 값을 가지고 싶을 수 있다. 이때 그룹함수에 특화된 HAVING 예약어를 사용할 수 있다.
- 질의 : SELECT 컬럼, 그룹함수(컬럼) FROM 테이블 GROUP BY 컬럼 HAVING 그룹함수(컬럼) >= 3000;
SELECT DNO, MAX(SALARY)
FROM EMPLOYEE
GROUP BY DNO
HAVING MAX(SALARY) >= 3000;그룹별 최댓값을 구한 것 중에 월급의 최댓값이 3000이 넘는 그룹만 나타내보자
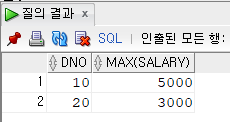
3000이 넘는 그룹별 최댓값만 출력이 됐다.
