Machine Learning, Linear Algebra, and Data Cleaning
해당 포스트에서는 머신러닝이 무엇인지, 선형대수학이 왜 머신러닝에서 중요한지를 알아보고 나아가 데이터 분석의 정의와 방법들을 간단하게 정리할 것이다.
선형대수학
선형대수학의 명확한 정의를 찾지는 못했다. 대학교재로 사용되는 선형대수학 서적들을 찾아보았으나 대부분 벡터가 무엇인지 문제를 어떻게 푸는지가 1장이었다. 가끔 보이는 서론에서도 선형대수학의 정의에 대해서는 명확한 설명이 부족했다.
하지만 이런 문서들에서 공통적으로 설명하는 것은 선형대수학이란 선형 방정식을 다루는 학문 이라는 것이다.
선형 방정식
조금 더 선형대수학 책들을 뒤지다보니 선형 계(system) 에 대해 설명을 해주는 서적을 찾았다. Jim Hefferon. Linear Algebra (4th ed.) 의 첫번째 쳅터에서는 선형 방정식 시스템은 수학과 과학에서 일반적이다 라고 시작하며 지렛대에서 서로 다른 두개의 물체간의 균형을 잡는 방법과 TNT(폭탄 원료) 합성법에서 원료 및 결과물의 비율을 알아내는 방법을 예시로 들며 선형 방정식이 수학 및 과학 분야에서 어떻게 사용되는지를 설명한다.
TNT 합성 비율 구하기
[그림1] 출처: Jim Hefferon. Linear Algebra (4th ed.). chapter 1
이렇게 봐도 잘 와닿지가 않는다. 선형 방정식과 일반 방정식의 차이가 뭔데?
개인적으로 선형대수학 이라는 명칭이 애매해서 한번에 와닿지가 않는 것 같다. 그래서 옥스퍼드 사전에 linear 를 검색해봤다
(mathematics) able to be represented by a straight line on a graph
linear equations
찾았다. 선형방정식은 (직)선형 방정식이라는 것이다.
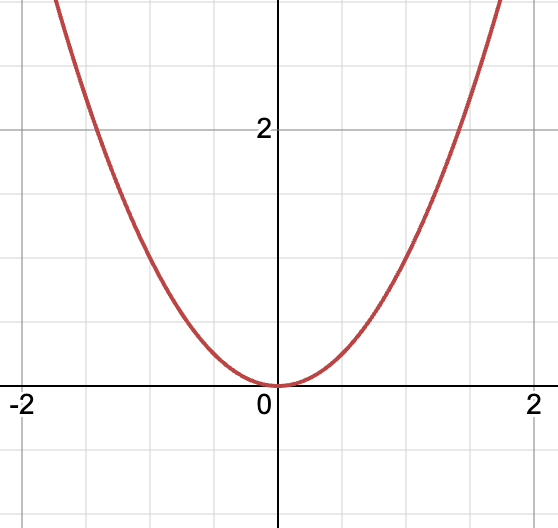
방정식에서 차수가 1보다 큰 식을 그래프로 나타내면 이 그래프들은 더이상 (직)선형적이지 않다. 추가로 한국에서는 1차식 그래프, 2차식 그래프, 3차식 그래프라고 표현하는 것이 영어로는 말 그대로 Linear equation graph, Quadratic equation graph, Cubic equation graph 이다. 표현방식과 뉘앙스가 달라서 1차식 계(system) = linear system 이라는 것을 연결시키지 못했던 것.
2차 방정식 그래프 (y = x^2)
3차 방정식 그래프 (y = x^3)
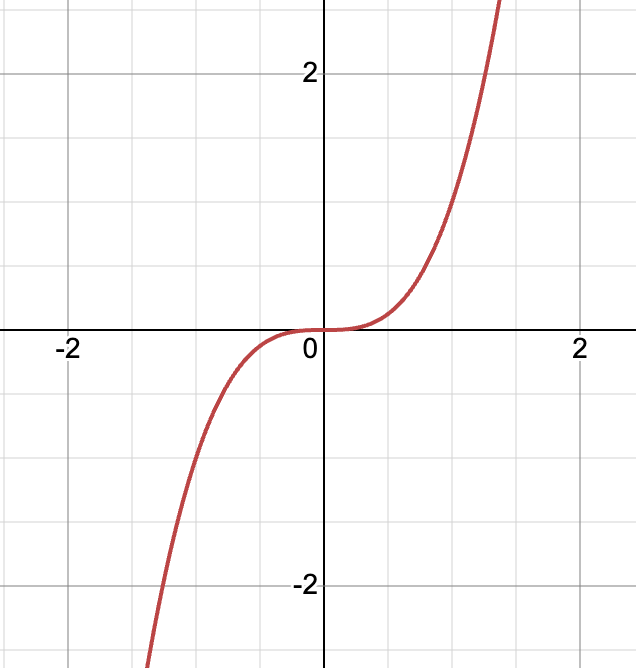
이제야 위키피디아의 선형대수학 정의가 이해가 가는 것 같다. 선형대수학(線型代數學, 영어: linear algebra)은 벡터 공간, 벡터, 선형 변환, 행렬, 연립 선형 방정식 등을 연구하는 대수학의 한 분야이다.
머신러닝에 왜 필요할까?
머신러닝은 컴퓨터라는 도구로 경험을 활용해 시스템 자체를 개선해 나가는 방법을 연구하는 학문입니다. 컴퓨터 시스템에서 일반적으로 경험은 데이터라는 형식으로 존재하고, 따라서 머신러닝이 연구하는 주요 내용은 학습 알고리즘, 즉 컴퓨터를 활용해 데이터에서 하나의 모델을 만들어내는 알고리즘이라 할 수 있습니다.[^1]
하지만 데이터의 모양은 천차만별일 수 있다. 왜 하필 선형 방정식 - 행렬 - 벡터의 모양으로 사용할까?
| 구 | 동 | 계약일 | 거래금액(만원) | 전용면적(㎡) | 층 | 건축년도 | 건물유형 |
|---|---|---|---|---|---|---|---|
| 동작구 | 신대방동 | 2025-12-31 | 73,000 | 59.76 | 4 | 1997 | 아파트 |
| 송파구 | 문정동 | 2025-12-31 | 17,050 | 19.74 | 7 | 2016 | 오피스텔 |
| 양천구 | 신정동 | 2025-12-31 | 122,800 | 113.91 | 16 | 2000 | 아파트 |
그냥 이렇게 특성마다 각각의 데이터로 저장해도 상관없는 것 아닌가?
WHEN two or more populations have been measured in several characters, xl, ... , x8, special interest attaches to certain linear functions of the measurements by which the populations are best discriminated.(Fisher, 1936, p. 179)
두 개 이상의 모집단이 여러 특성(변수)들로 측정되었을 때 그 측정값들의 특정 선형결합(linear function) 에 특별한 관심이 생긴다, 그 선형결합을 통해 모집단을 가장 잘 구분할 수 있기 때문이다.
(2026-02-13 기준 내 이해) ※ 이후 학습 후 수정 필요
특성마다 각각의 데이터로 비교를 하면 column 단위로는 비교가 되지만 해당 관측값의 row 컨텍스트를 연관짓기 힘들다. 이를 선형 결합하면 측정 값들을 전체 맥락을 이용한 비교가 가능하게 된다.
경험을 통해 시스템을 개선해나갈 때 개선하기 위한 데이터와 그 데이터들을 적절하게 분류하기 위한 기준이 필요한데 그 선형 결합 된 데이터 집단이 이 기준에 적합하기때문에 머신러닝에 선형대수학이 필요하다 라는것이 나의 결론이다.
EDA(Exploratory Data Analysis)
데이터 분석의 정의를 찾아보았을 때 위키피디아에서 아래의 논문을 인용하여 설명하고 있었다.
All in all, I have come to feel that my central interest is in data analysis, which I take to include, among other things: procedures for analyzing data, techniques for interpreting the results of such procedures, ways of planning the gathering of data to make its analysis easier, more precise or more accurate, and all the machinery and results of (mathematical) statistics which apply to analyzing data.(Tukey, 1962, p. 2)
저자는 나열되는 것들이 data analysis에 포함된다고 설명한다.
- 데이터를 분석하는 절차
- 결과를 해석하는 기술(판단 과정)
- 분석을 쉽고 정확하고 정밀하게 하기 위한 데이터 수집 계획 방법
- 데이터 분석에 적용되는 수리통계학의 이론적 도구와 체계 전반
하지만 데이터의 질(quality)이 낮으면 분석 결과 역시 부정확할 수 밖에 없다. 실제 세상(real-world) 에서 수집된 정제되지 않은 데이터들은 많은 결측값, 이상치, 중복값등을 포함하고 있으며 이런 데이터의 질을 상승시키기 위해서는 여러가지 전처리를 수행해야한다. (data cleaning)
데이터 전처리
결측값
Missing Value. 데이터에서 값이 누락되거나 기록되지 않은 경우
결측의 유형 (Missing data mechanism)
| 구분 | MCAR | MAR | MNAR |
|---|---|---|---|
| 용어 의미 | Missing Completely At Random | Missing At Random | Missing Not At Random |
| 정의 | 결측 발생 확률이 어떤 변수의 값에도 의존하지 않음 | 결측 발생 확률이 관측된 다른 변수에는 의존하지만, 결측된 값 자체에는 의존하지 않음 | 결측 발생 확률이 결측된 값 자체에 의존함 |
| 결측 예측 가능? | 불가능 | 다른 변수로 예측 가능 | 해당 값을 알지 못하면 설명 불가능 |
| 예시 | 데이터 수집 프로그램 오류로 일부 거래금액이 무작위 누락 | 3월에 계약 건수가 많아 업무 과부하로 거래금액 누락 증가 (계약일로 설명 가능) | 일정 금액 이상의 고가 거래는 신고 회피로 거래금액 누락 |
결측값을 처리하는 대표적인 방법은 아래와 같다
- 관측값 삭제 (deletion)
- 결측값 대체 (imputation)
결측값 삭제
| 구 | 동 | 계약일 | 거래금액(만원) | 전용면적(㎡) | 층 | 건축년도 | 건물유형 |
|---|---|---|---|---|---|---|---|
| 동작구 | 신대방동 | 2025-03-17 | NA | 59.76 | 4 | 1997 | 아파트 |
| 송파구 | 문정동 | 2025-12-31 | 17,050 | 19.74 | 7 | 2016 | 오피스텔 |
| 양천구 | 신정동 | 2025-12-31 | 122,800 | 113.91 | 16 | 2000 | 아파트 |
위의 데이터를 예시로 들었을 때 첫번째 row 의 거래금액이 결측값이기때문에 해당 row 전체를 삭제한다
| 구 | 동 | 계약일 | 거래금액(만원) | 전용면적(㎡) | 층 | 건축년도 | 건물유형 |
|---|---|---|---|---|---|---|---|
| 송파구 | 문정동 | 2025-12-31 | 17,050 | 19.74 | 7 | 2016 | 오피스텔 |
| 양천구 | 신정동 | 2025-12-31 | 122,800 | 113.91 | 16 | 2000 | 아파트 |
장점
- 별도의 가정 없이 단순하게 처리 가능
단점
- 표본수 감소
- 관측값의 다른 유의미한 정보가 함께 유실
- 결측이 특정 특성과 관련되어 발생하면(MAR, MNAR) 선택 편향으로 인해 통계적 왜곡이 발생할 수 있음
결측값 대치 (imputation)
단일값 대치
- 평균값으로 대치
- 회귀 대치 (Regression imputation)
- 모수에 들어맞는 회귀 모델을 구축하여 결측값을 대치
- 확률적 회귀 대치 (Stochastic regression imputation)
- 위의 회귀 대치에서 회귀 모델에 현실세계 모방을 위한 잔차(residual)(오차)값을 추가함
- 잔차는 완성된 회귀 모델과 실제 관측값의 차이에서 랜덤하게 가져옴
- Hot-Deck
- 결측치가 존재하는 같은 데이터 셋의 다른 관측값을 그대로 복사하는 방식 (donor-based imputation)
- 결측치가 있는 관측값과 다른 관측값을 사용
- Similar Response Pattern : Hot-Deck imputation 의 한 종류로 가장 유사한 응답 패턴의 값으로 결측치를 대치
- Averaging the Available Items imputation
- 결측값이 존재하는 동일 관측값의 다른 피처 값들을 사용해서 결측값을 대치
- 결측값의 비율이 클수록 무효. 보통 30% 미만의 결측값을 대치할 경우에만 사용
- 피처 간 연관성이 높을때 사용 가능 (예: 우울증 검사를 위한 다문항 척도)
- Last Observation Carried Forward
- 직전에 관측된 항목으로 결측치를 대치하는 방법
- 특정한 액션을 취하지 않으면 값의 변화가 적은 피처에 적합
Maximum Likelihood Estimation
- 관측값들의 분포를 사용해 특정 모델을 구축하고 해당 모델로서 결측치를 예측
- The Univariate Normal Distribution
- 단일 피처의 항목이 정규분포를 따를 것이라 가정
- The Sample Likelihood & Log Likelihood
- 데이터 세트에서 몇개의 샘플을 추출하여 해당 샘플이 가정한 모델에 얼마나 부합하는지 (모델에서 샘플 데이터가 나타날 확률)
- 전체 확률을 구하기 위해서 샘플 데이터간 모델 부합 확률을 다 곱해주어야 하는데 (독립&동시) 이를 컴퓨터로 연산하기에는 너무 작은 수가 발생하여 부동소수점 오류가 발생하고 연산 효율이 낮기때문에 로그로 변형하여 효율을 높임
An Illustrative Computer Simulation Study
위의 모델들을 검증하기위해 시뮬레이션을 통한 테스트 (추가 정보 & 수정 필요)
중복값
- 레코드의 명확한 식별자(id or primary key etc)가 있다면 관측값 내부 모든 값이 중복되는(레코드 중복) 관측값은 샘플간의 독립성을 파괴하면서 예측 모델에 편향을 야기하기때문에 삭제되어야 함
- 식별자가 없다면 서로 다른 레코드가 진짜 중복 레코드인지 혹은 우연의 일치로 관측값이 같은 것인지 파악해야함
- 관측 값이 완전히 동일하지 않더라도(단순 문자열 비교로 인한 차이) 오탈자, 표기 언어, 표시 방식 (연도,월,일 <-> 일,월,연도) 에 따라 중복 레코드일 수 있음
- 이를 파악하기 위해서는 관측값을 단순한 문자열 비교로 비교할 것이 아니라 패턴의 일치 정도를 구하고 이 수치가 같은 객체일 때 자연스러운지 / 다른 객체임에도 우연히 같은 관측값을 가질 수 있는지를 수치화한다. 이 수치를 분류할 오류 허용률을 지정해서 실제 같은 레코드인지(link) 비슷한 데이터의 다른 레코드인지 (non-link) 판정하고 명확하게 판단할 수 없는 레코드는 (possible-link) 추가 검토 대상으로 분리함
데이터 이상치 (outlier)
데이터 세트에서 예상되는 관측 항목에서 격차가 있는 값. 많은 데이터에서 일반적으로 관측되지 않는 값
- 데이터의 측정, 기록 또는 계산 오류로 인해 발생 => 삭제되어야 하는 값
- 낮은 확률로 자연적으로 발생할 수 있는 값
anomaly : 예상되는 행동을 따르지 않는 패턴. outlier 를 포함하는 더 넓은 개념 (추후 보충학습 필요, 이 포스팅에서는 다루지 않음)
평균이나 최소제곱선(least squares line = line of best fit = regression line)등에 큰 영향을 미치기 때문에 이상치를 발견하고 다른 주요 지표에 미치는 영향을 최소화하기 위한 방법들이 필요함
Box Plot
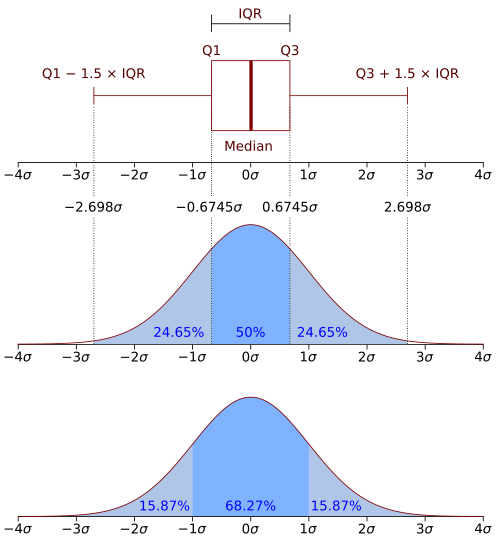 그림2. 출처: 위키피디아
그림2. 출처: 위키피디아
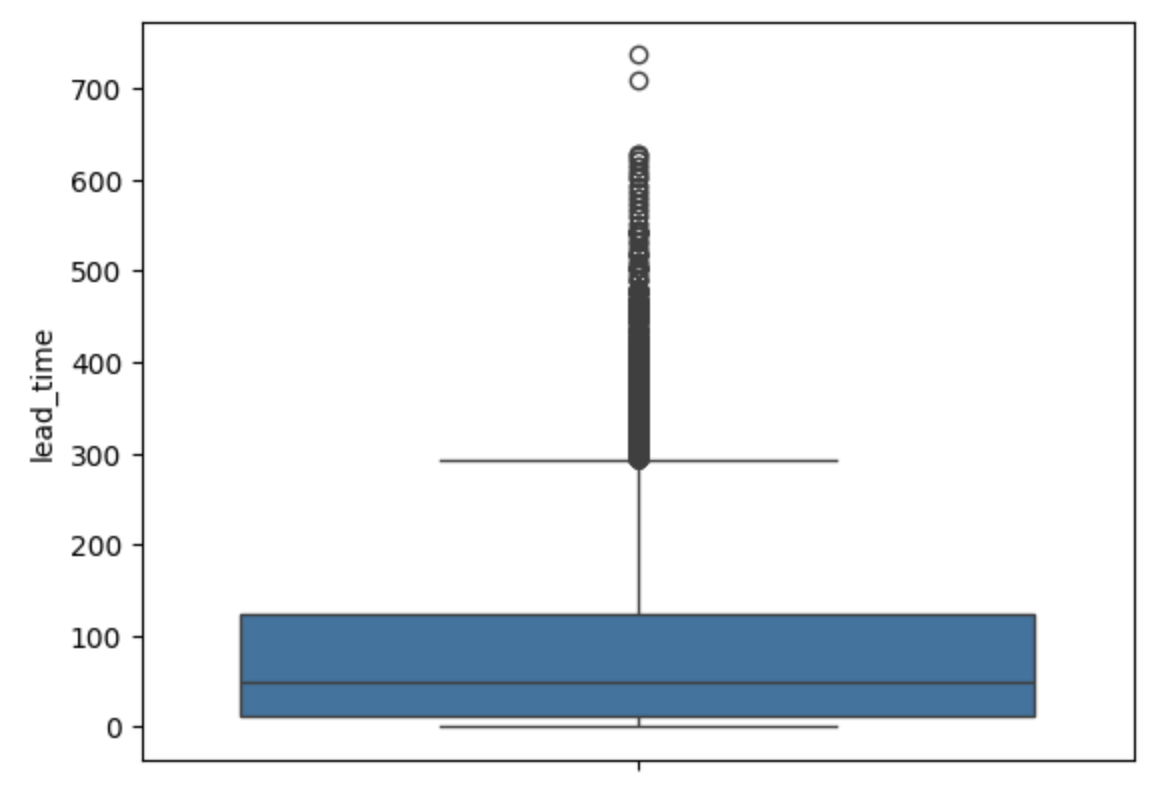 그림3
그림3
- 1사분위와 3사분위의 값으로 박스 테두리를 구성하고 중간값(2사분위)을 박스 안쪽에 추가 선으로 표현
- Whisker (포유류의 코 주위 감각 감지 털처럼 길게 뻗어나온 부분) 는 interquartile range (IQR, 1사분위와 3사분위의 차이)에 1.5배한 값을 각각 1사분위와 3사분위 범위 밖에 붙여서 표현
- 이런 whisker 를 벗어나는 값들(잠재적 이상치)은 두번째 그림과 같이 점으로 표시됨
- 데이터가 정규분포를 따를 때 이상치를 파악하기 쉬우나 두번째 그림과 같이 데이터가 한쪽으로 치우진 분포(지수 분포 등)를 따르면 정상 데이터도 잠재적 이상치로 보일 수 있음
- 비대칭형 데이터에 대해서는 로그 변환을 통해 데이터 분포를 대칭형으로 변화시킨 후 box plot 을 그리거나 Adjusted Box Plot 를 사용할 수 있음
Bag Plot
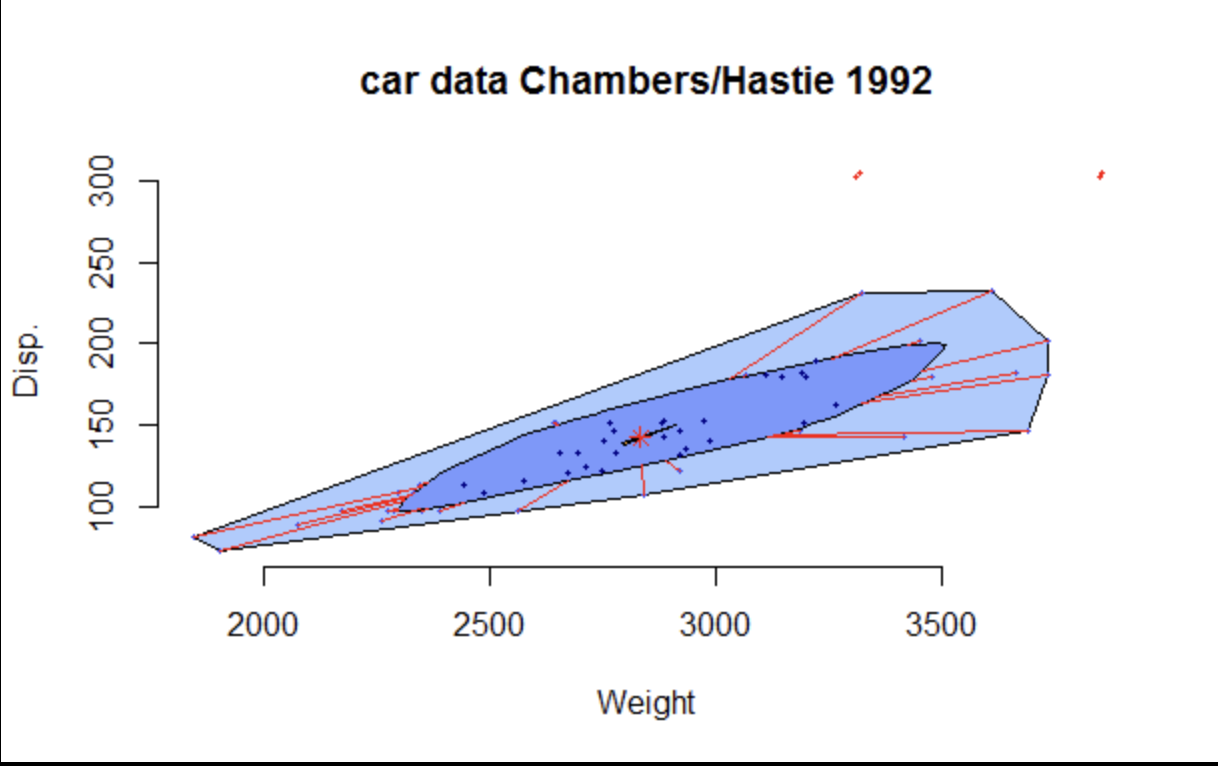 그림4. 출처: 위키피디아
그림4. 출처: 위키피디아
- box plot 이 하나의 변수에 대해서 그린 방식이라면 bag plot 은 2/3개 (2/3차)의 변수(피쳐) 의 데이터를 표현한 방식
- 산점도에 box plot 을 겹쳐 그린 것 같은 방식이며 그림4 에서 어두운 다각형 가운데 점(빨간색 별표시)이 box plot 의 박스 가운데 선 (median, 2사분위)을 의미하며 어두운 다각형은 1Q-3Q를, 붉은색 선은 whisker, 밝은 다각형 밖의 데이터는 잠재적 이상치에 해당함
Residual Plot
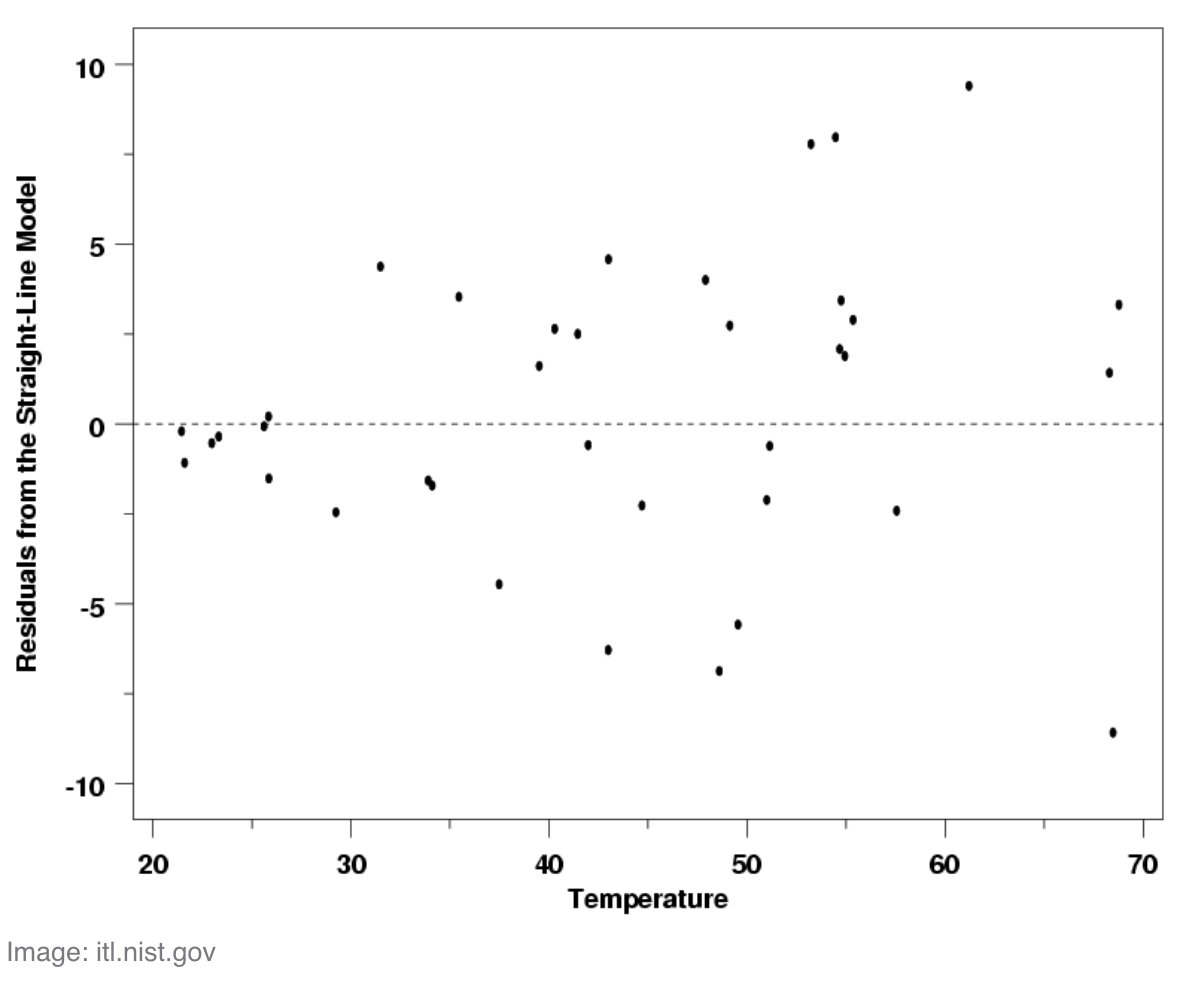 출처: statisticshowto
출처: statisticshowto
- best-fit line 을 수평선(y = 0)으로 Detrending(추세 제거)하여 실제 데이터가 이상적인 데이터와 얼마나 차이가 나는지 쉽게 확인할 수 있는 방법
- 데이터가 수평선에서 벗어난 정도가 클수록 잠재적 이상치에 해당
reference
- Hefferon, J. (2020). Linear Algebra (4th ed.).
- Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2), 179–188.
- Tukey, J. W. (1962). The future of data analysis. The Annals of Mathematical Statistics, 33(1), 1–67.
- Badie, B., Berg-Schlosser, D., & Morlino, L. (Eds.). (2011). Data analysis, exploratory. In International encyclopedia of political science (Vol. 1). SAGE Publications.
- Enders, C. K. (2010). Applied Missing Data Analysis.
- Fellegi, I. P., & Sunter, A. B. (1969). A theory for record linkage. Journal of the American Statistical Association, 64(328), 1183–1210.
- [^1] 조우쯔화 (2020). 단단한 머신러닝
- Han, J., Kamber, M., & Pei, J. (2011). Data Mining: Concepts and Techniques (3rd ed.).
- Chandola, Banerjee, Kumar (2009) — Anomaly Detection: A Survey
- Barnett, V., & Lewis, T. (1978). Outliers in Statistical Data. London: John Wiley & Sons.
