
포스팅에 앞서.... 그라운드 플립은 스토어에서 다운 받을 수 있습니다!!🔥🔥
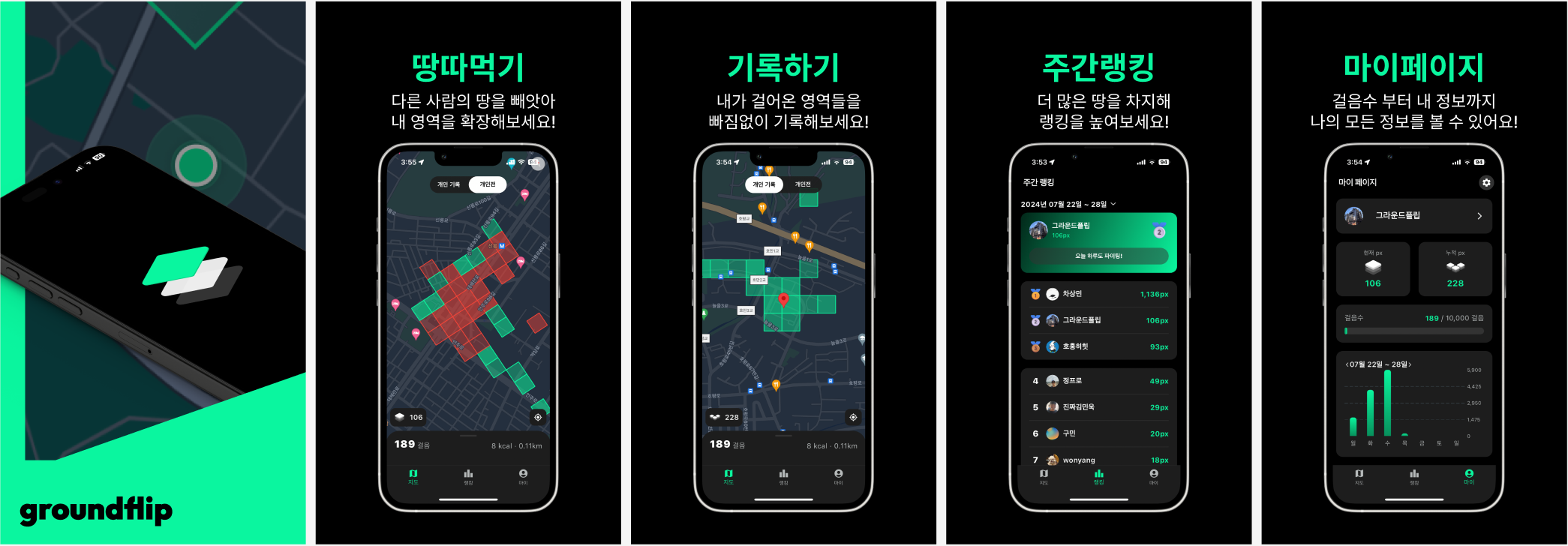
[iOS] : 앱스토어
[Android] : Play 스토어
서론
최근 그라운드 플립은 누적 가입수 1000명, DAU 400명을 달성했다.
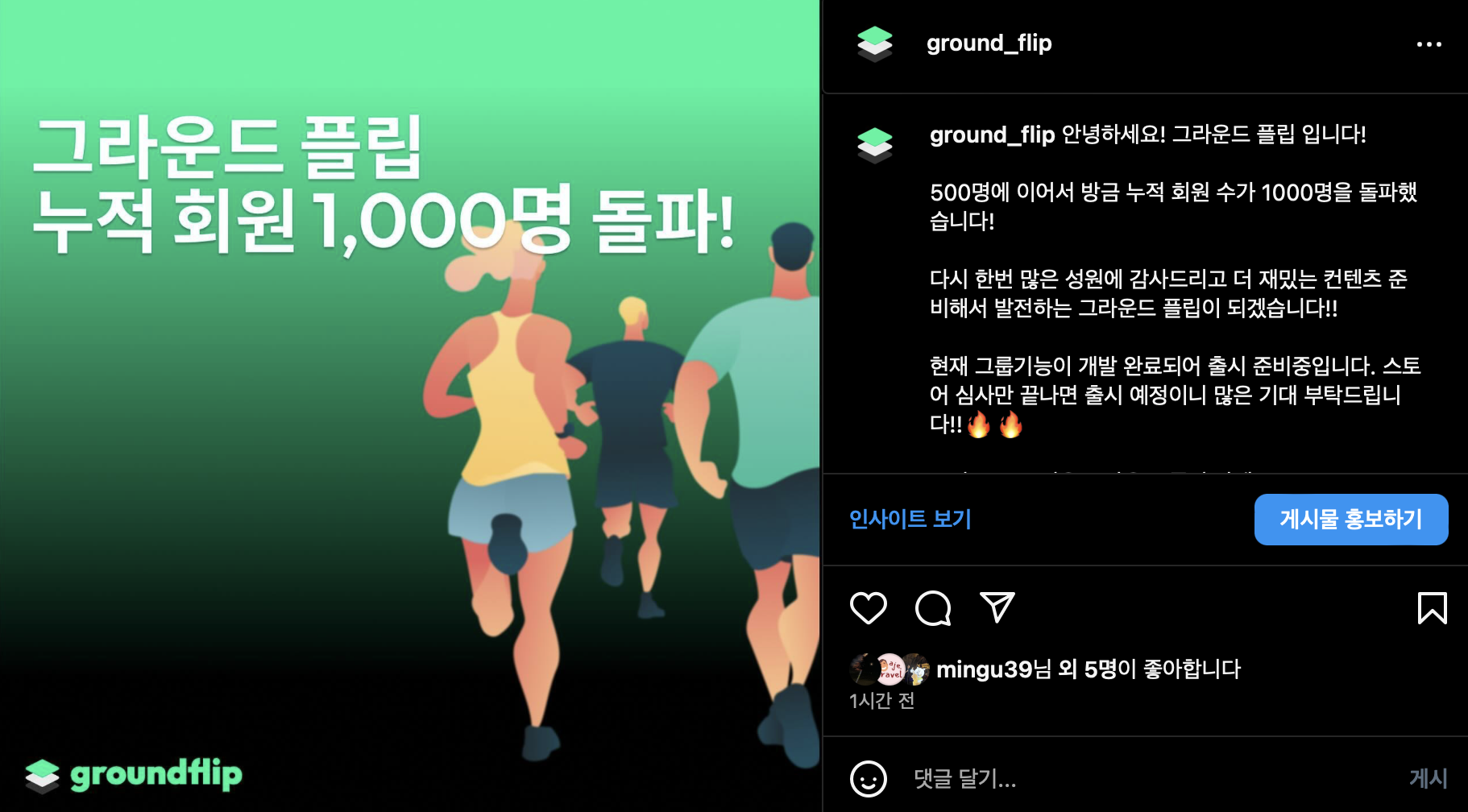
너무나 기쁘고 감사한 일이었지만, 어제(9월 27일)는 무슨 일인지 이슈가 많이 생긴 날이었다.
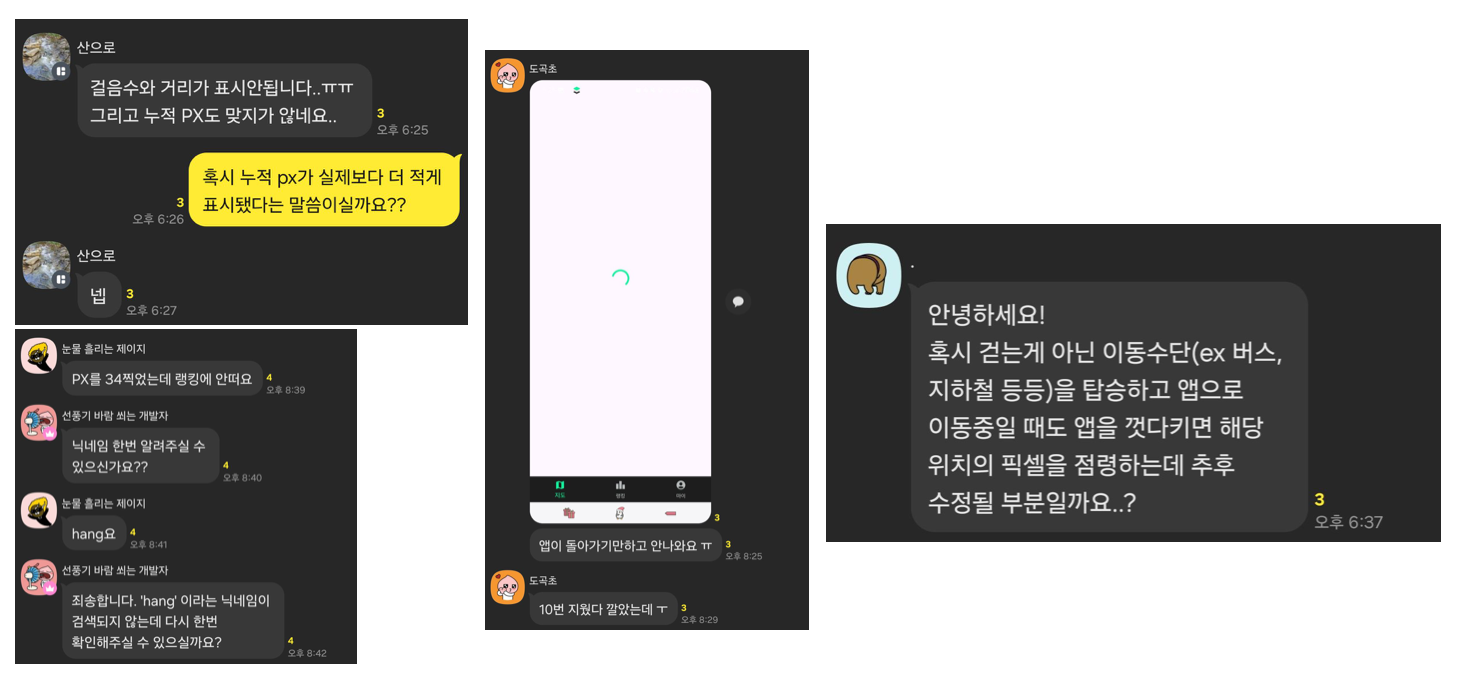
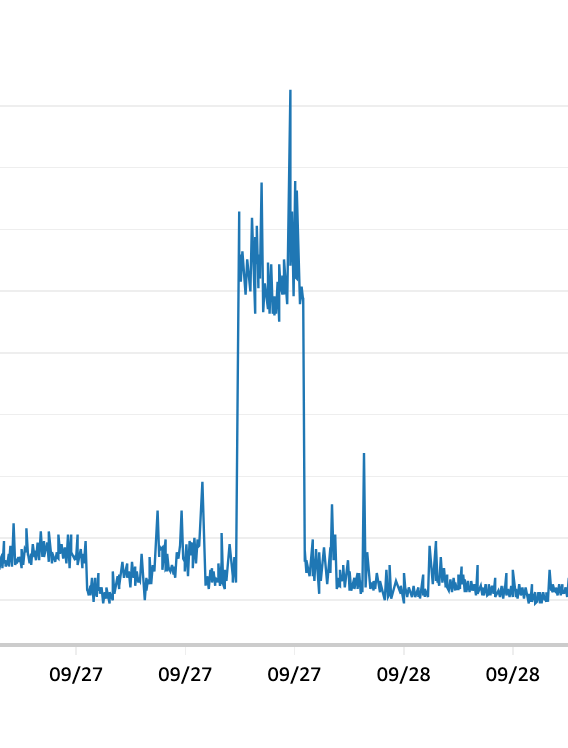
특히 밤에는 DB CPU 사용량이 90퍼센트를 넘겼던 아슬아슬한 상황이 발생하기도 했다.
원인을 알아내려 했지만...우리가 구축해놓은 모니터링 시스템은 CloudWatch의 지표들만 사용했기에 보기도 불편했고 워낙 정보가 적어 원인 파악이 어려웠다.
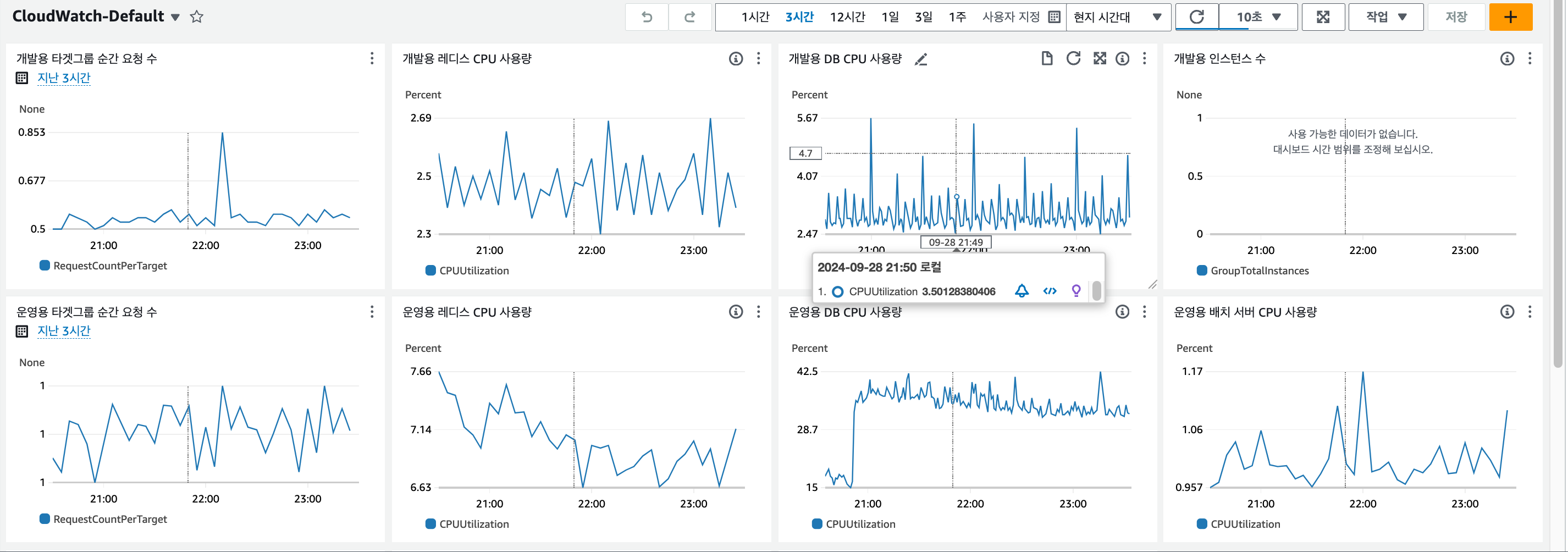
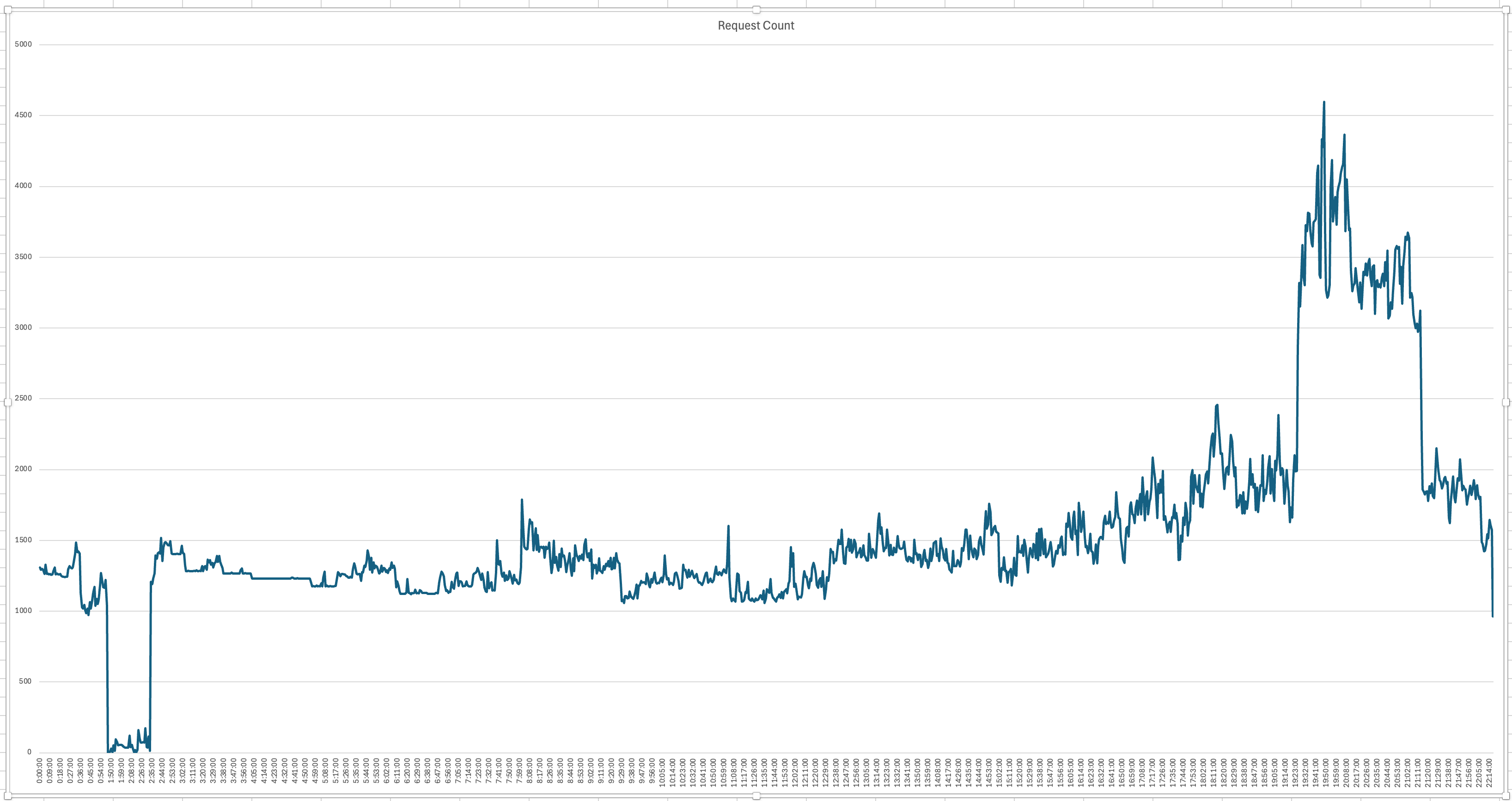
심지어 어떤 요청이 가장 많이 요청됐는지 알고싶어도 별도의 시스템이 없다보니 팀원 중 한 명이 로그 파일을 긁어 손수 파이썬을 사용해 시각화를 하느라 고생하기도 했다. (다시 한번 샤라웃 투 구민!!!)
SW 마에스트로 활동 중 모니터링 시스템 구축에 대한 특강을 들었던 경험이 있었다.
해당 특강에서 그라파나 & 프로메테우스를 활용해서 간단한 환경을 구축해봤기에, 이를 그라운드 플립에도 적용해보기로 했다.
목표
우선 수집하고 싶은 메트릭들은 다음과 같았다.
- 운영용 '스프링 컨테이너'의 메트릭
- 운영용 RDS의 메트릭
- 운영용 ElastiCache의 메트릭
또한 모니터링 환경은 별도의 EC2에서 구동되게 구축해보려 한다.
스프링 메트릭 받기
우선 스프링 프로젝트에서 메트릭을 내보낼 수 있도록 의존성을 추가한다.
implementation("org.springframework.boot:spring-boot-starter-actuator")
runtimeOnly("io.micrometer:micrometer-registry-prometheus")그리고 application.yml에 엔드포인트를 설정한다.
management:
endpoints:
web:
exposure:
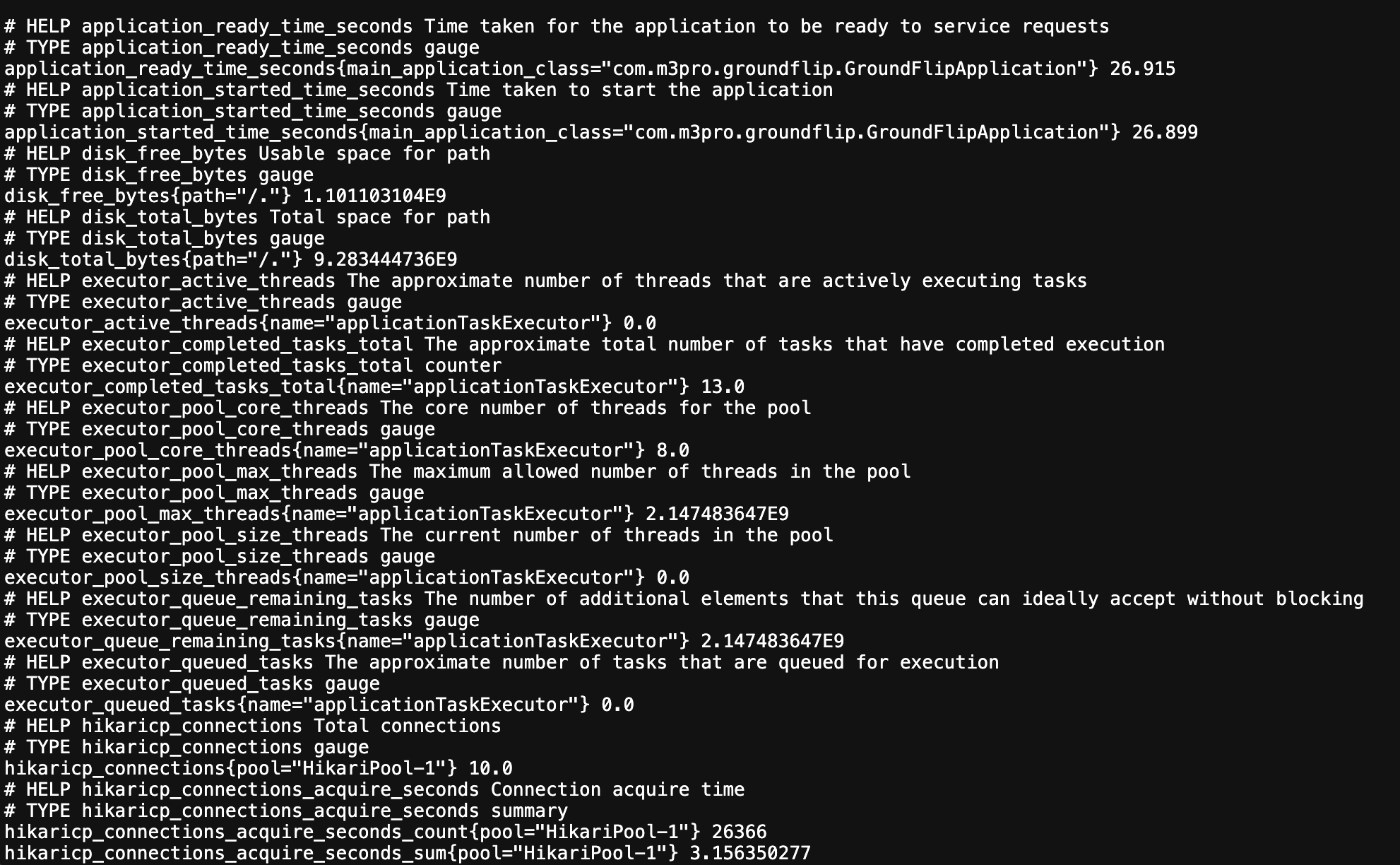
include: "*"이후 /actuator/prometheus로 접속했을 때 아래와 같이 메트릭들을 수신할 수 있다면 성공!
이후 EC2를 새로 생성한 후 docker-compose.yml과 prometheus.yml을 작성한다.
우리의 경우, t3a.micro 등급을 사용했다.
# docker-compose.yml
version: '3.8'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- "프로메테우스에 사용할 인스턴스의 포트:9090"
networks:
- monitoring-network
grafana:
image: grafana/grafana:latest
container_name: grafana
user: "$UID:$GID"
ports:
- "그라파나에 사용할 인스턴스의 포트:3000"
volumes:
- ./grafana-data:/var/lib/grafana
networks:
- monitoring-network
networks:
monitoring-network:
driver: bridge
여기서 꼭!!! 그라파나에 volume을 설정해줘야한다.
그렇지 않으면 인스턴스가 내려갈 때 기껏 세팅한 대시보드들이 전부 사라진다...
# prometheus.yml
global:
scrape_interval: 15s
scrape_configs:
- job_name: prometheus_prod_spring
metrics_path: '/actuator/prometheus'
scheme: https
tls_config:
insecure_skip_verify: true
static_configs:
- targets: ['서버 도메인:443']이후 해당 EC2의 프로메테우스 포트로 접속한다.
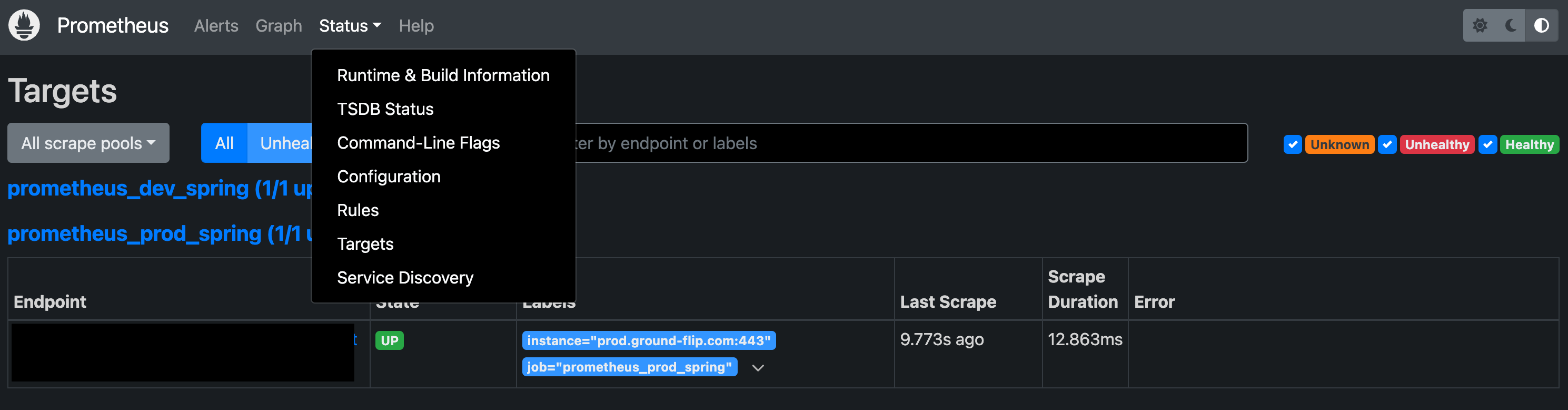
Targets 항목으로 이동 후 UP 상태라면, 프로메테우스가 스프링의 메트릭을 정상적으로 받아오고 있다는 뜻이다.
이후 그라파나 포트로 접속해 대시보드를 만든다.
-
Add new data source를 클릭

-
url을
http://prometheus:9090으로 설정 후 아래에 있는 Save&Test를 누르면 data source 등록이 완료된다.
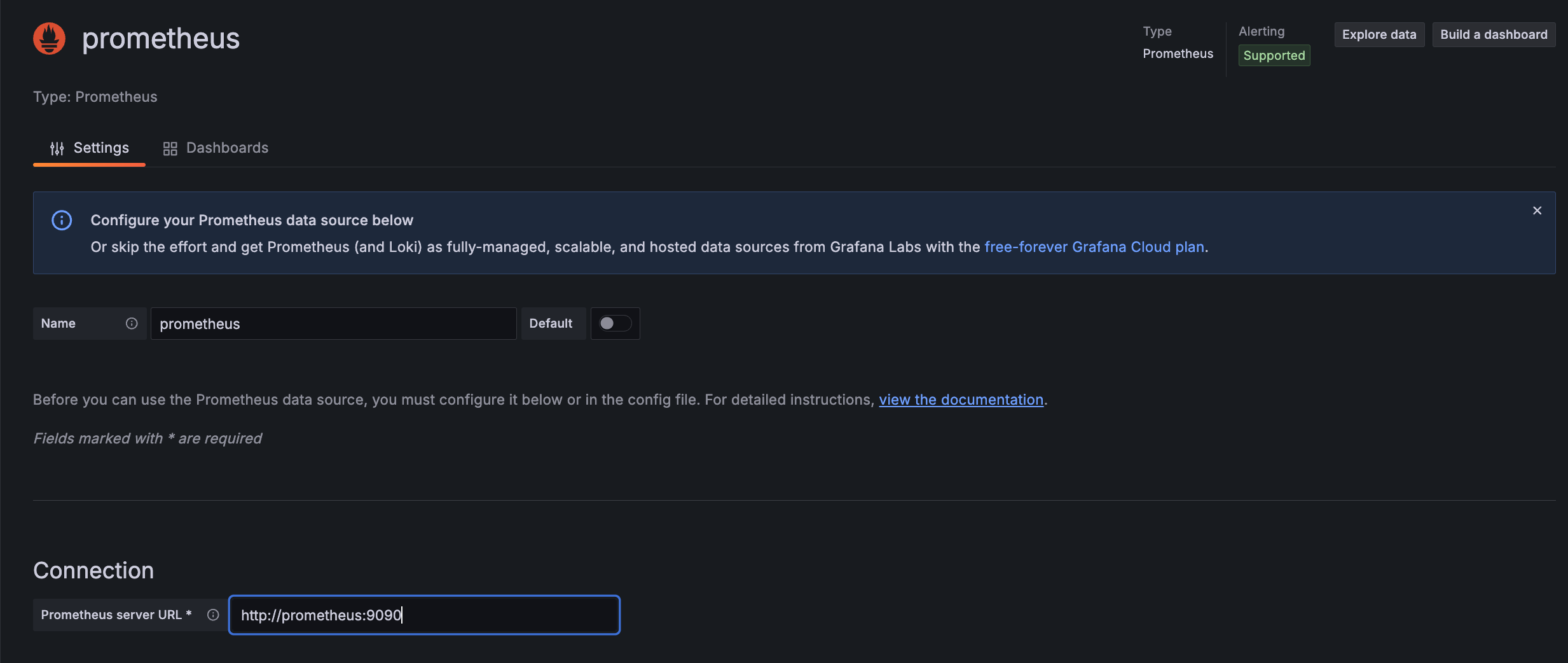
왜 localhost가 아닐까?
그라파나가 현재 컨테이너 내부에서 동작하기 때문에 여기서 localhost를 사용하게 되면 EC2 인스턴스가 아니라 '컨테이너'를 의미하게 된다.
- 이후 대시보드를 만든다.
대시보드를 직접 구성하기 보다는 이미 스프링 모니터링용으로 만들어진 대시보드를 import한다.
결과는?
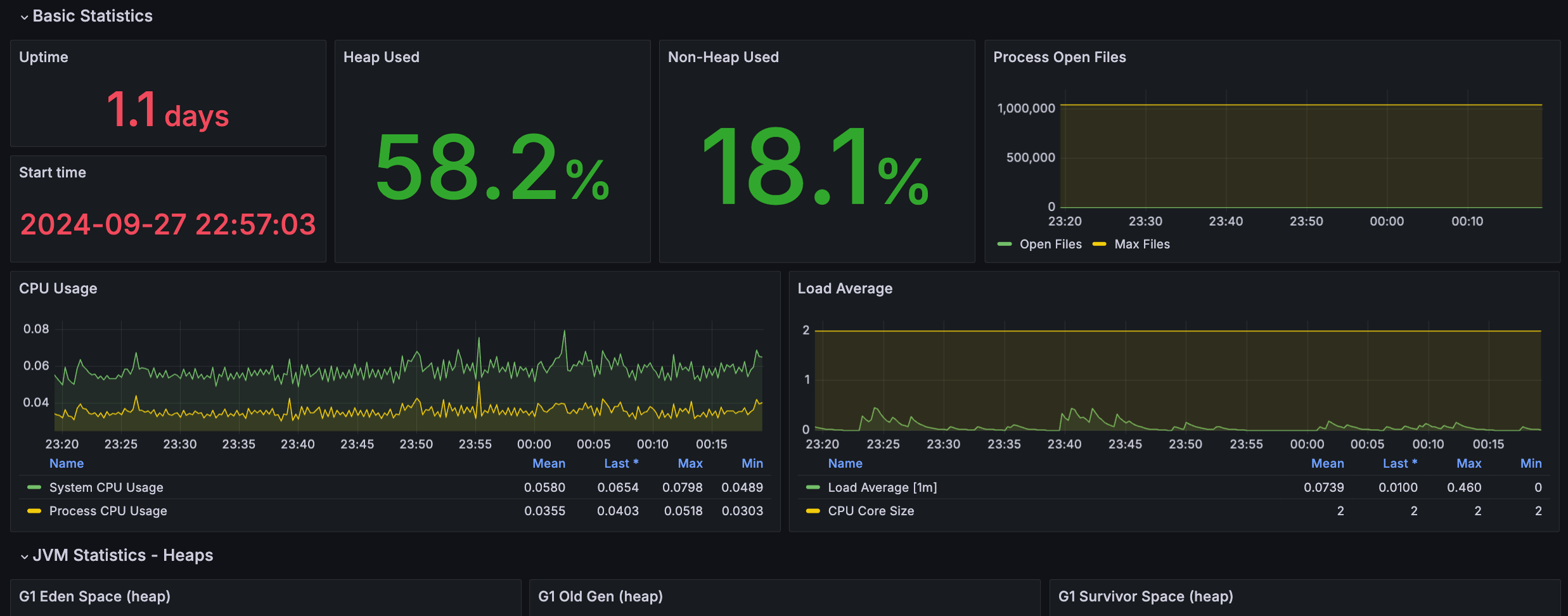
스프링의 메트릭을 잘 가져오는 것을 확인할 수 있다.
단순 자원 사용 뿐만 아니라 초당 요청 수, 요청이 많이 오는 API도 알 수 있다.
RDS, ElastiCache 메트릭 받기
RDS의 메트릭은 별도의 설정 필요 없이, IAM 시크릿 ID, Key만 있으면 된다.
- data source 중 cloudwatch를 선택한다.
- IAM 시크릿 ID, Key와 리전만 입력한 후 Save & Test를 진행하면 된다.
RDS, ElastiCache 대시보드의 ID인 707과 969로 각각 대시보드를 import한다.
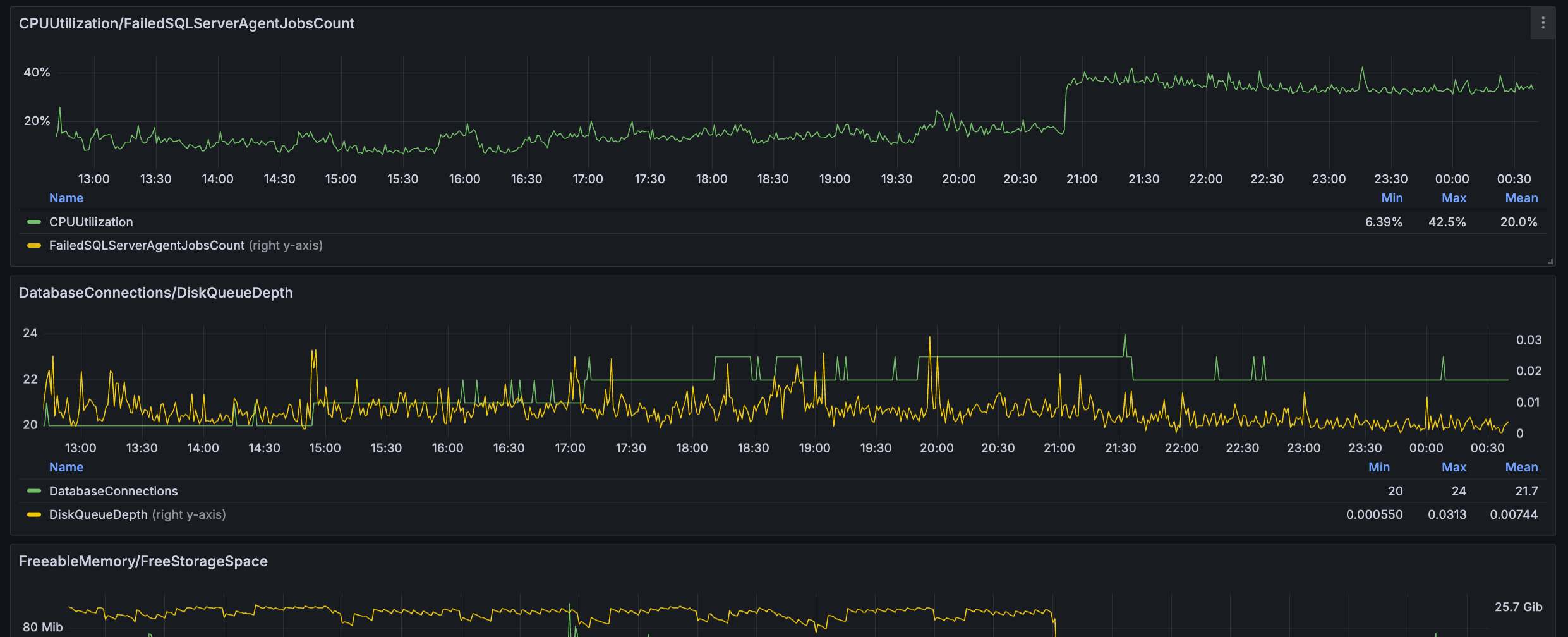
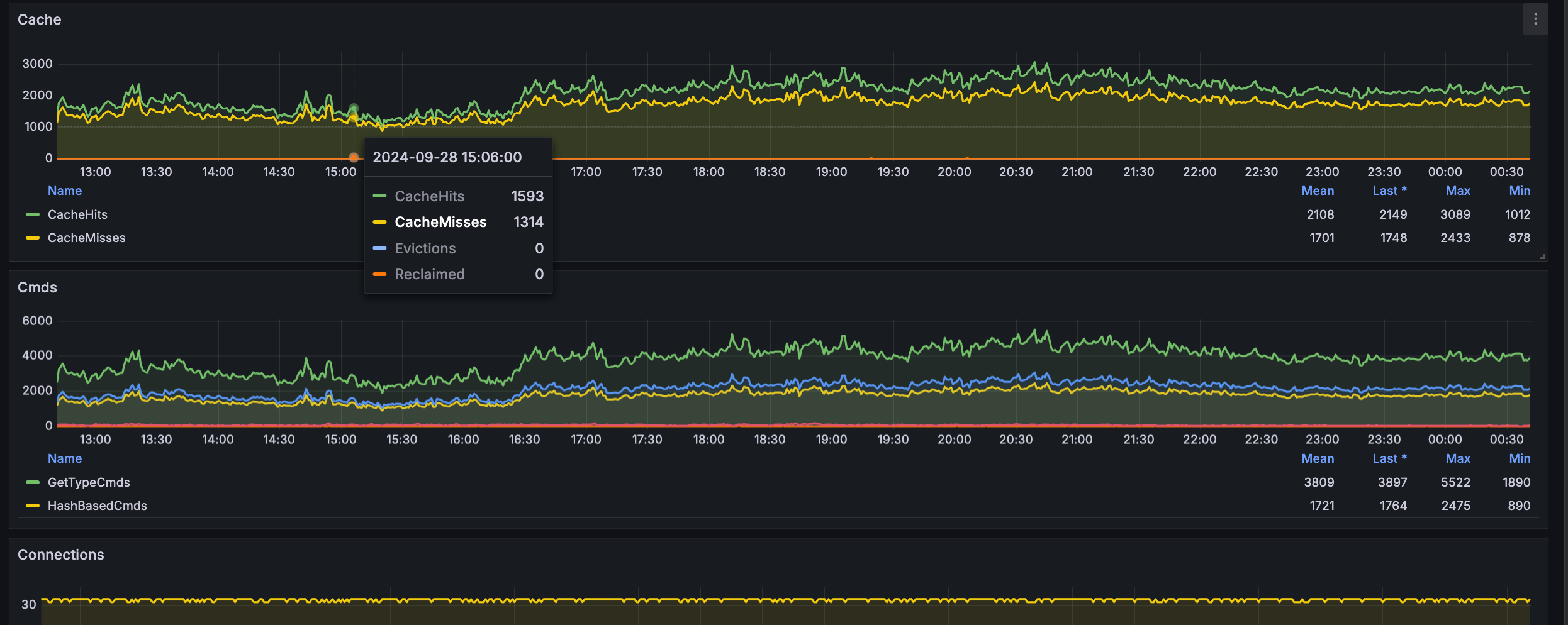
잘 나오는 것을 확인할 수 있다!!
결론
오늘도 DB 사용량이 40%까지 올랐다. 모니터링을 통해 분석한 결과, 2900만개의 행을 R-tree로 검색하는 API가 원인으로 지목됐고 최적화를 위한 대공사에 들어갈 예정이다.
그동안 CloudWatch만 쓰면 되지~ 하고 모니터링 구축을 미뤄놨었는데 이번 이슈를 통해 중요성을 느꼈다.
다음에는 그라파나를 사용한 GIS 데이터 시각화를 해보려고 한다.

아! 그래프 보기만 해도 손 떨리네요 흐흐 고생하셨습니다!