그라운드 플립 조회 시스템 개선 - 실험 편
이전 포스트에서 이어지는 글입니다.
서론
그라운드 플립은 ‘땅따먹기’ 게임에서 아이디어를 얻은 지도 기반 만보기 앱이다.
사용자는 걸음을 통해 실제 지도 위의 땅을 점령하고, 다른 사용자들과 경쟁하게 된다.
지난 글
지난 글에서는, 기존 R-Tree 기반의 공간 조회가 트래픽 증가에 따라 CPU 부하가 선형적으로 증가하는 문제를 다뤘다.
그리고 이 한계를 극복하기 위한 대안으로, 좌표를 문자열로 변환해 B-Tree 인덱스로 Range Scan하는 방식(Geohash) 을 제시했다.
이번 글에서는 그 아이디어를 실제로 구현하고, 부하 테스트를 통해 성능을 검증한 과정을 공유한다.
구체적인 아이디어
우리가 목표로 하는 조회는 “정확한 반경 내의 픽셀”이라기보다, 지정된 반경(혹은 약간 더 큰 영역)을 반드시 포함하는 픽셀 집합이다.
즉, 일부만 조회되는 것은 절대 허용할 수 없지만, 조금 더 넓게 나오는 것은 문제되지 않는다.
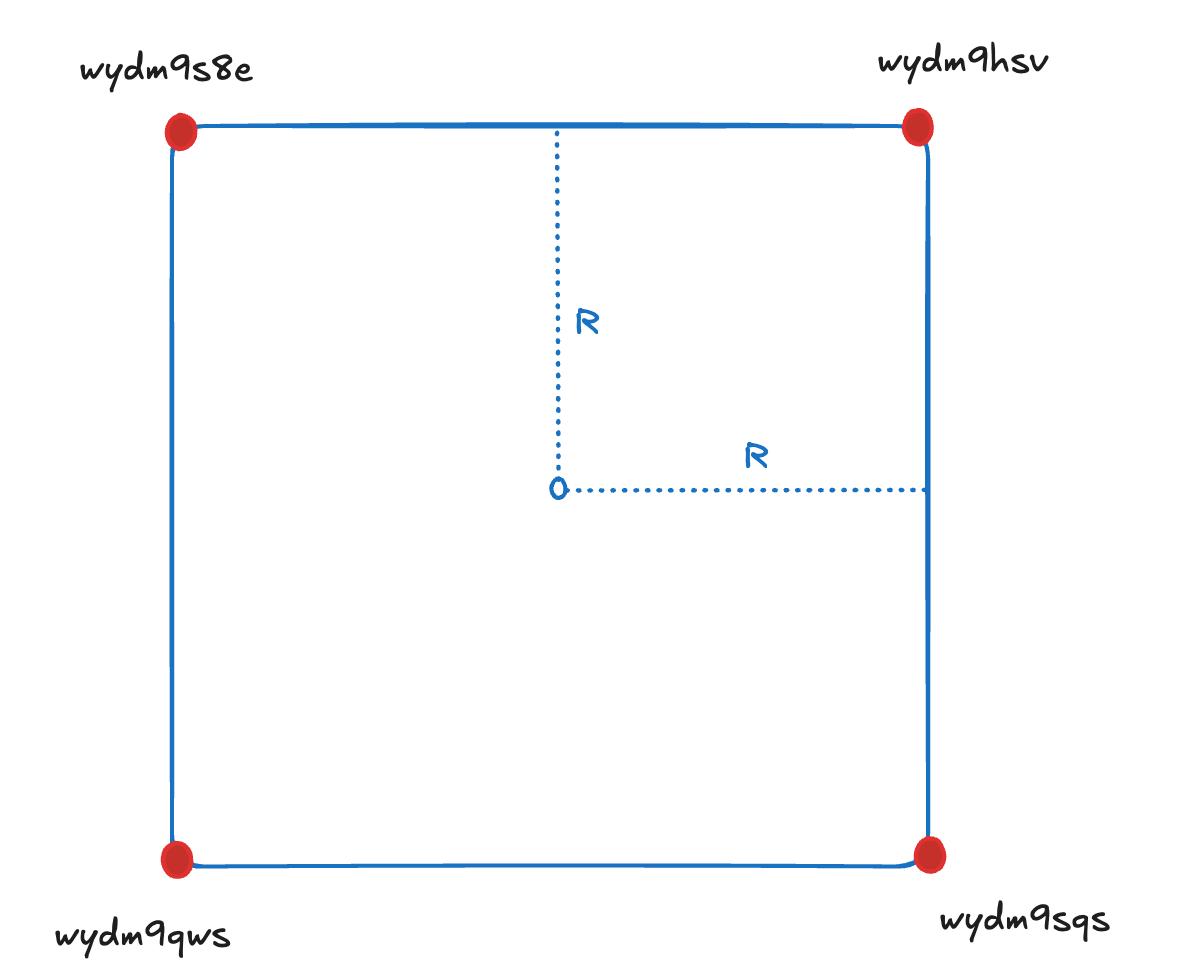 이 특성을 활용해, 반경 원을 완전히 감싸는 사각형을 계산하고, 그 사각형의 각 꼭짓점 Geohash를 구한 뒤 **공통 prefix를 이용해 조회 영역을 결정**했다.
이 특성을 활용해, 반경 원을 완전히 감싸는 사각형을 계산하고, 그 사각형의 각 꼭짓점 Geohash를 구한 뒤 **공통 prefix를 이용해 조회 영역을 결정**했다.
SELECT *
FROM pixel
WHERE geohash LIKE 'wydm9%';이 단 한 줄로, "wydm9"로 시작하는 모든 픽셀(즉, 해당 영역 내 땅들)을 가져올 수 있다.
이는 단순 문자열 검색 같지만, 실제로는 공간 계층구조 기반의 Range Scan이다.
실험
1차 실험 (50VU)
시스템 구성
• MySQL 8.0 (Docker)
• RAM: 1GB
• CPU: 2코어 제한
• 데이터: 전국 단위 80m 간격 픽셀 약 2,900만 row
Spring Boot API 서버
• /search → R-Tree 기반
• /search/geohash → Geohash 기반
부하 도구: k6
• 대한민국 무작위 위치에서 1KM 내의 무작위 반경 조회
• Ramp-up → 2분
• Constant Load → 5분 (50 VU)
• Ramp-down → 1분
• 총 8분간 실행
API 예시는 다음과 같다
public class PixelController {
private final PixelService pixelService;
@GetMapping("/search")
public List<Pixel> getPixelsWithinRadius(
@RequestParam double longitude,
@RequestParam double latitude,
@RequestParam double radius) {
return pixelService.findPixelsWithinRadius(longitude, latitude, radius);
}
@GetMapping("/search/geohash")
public List<Pixel> getPixelsByGeohash(
@RequestParam double latitude,
@RequestParam double longitude,
@RequestParam int radius) {
return pixelService.findPixelsByGeohash(latitude, longitude, radius);
}
}쿼리 레벨에서도 두 방식의 차이는 단순하다:
R-Tree
ST_CONTAINS((ST_Buffer(ST_SRID(ST_PointFromText(:point), 4326), :radius)),
Geohash
geohash LIKE CONCAT(:prefix, '%')
그리고 부하를 위한 k6 script 작성했다.
캐시 워밍업을 위해 API 호출을 초기에 몇 건 진행하고, 결과에서 제외했다.
import http from 'k6/http';
import { sleep, check } from 'k6';
const API_TARGET = __ENV.API_TARGET || 'spatial';
const MIN_LAT = 33.0;
const MAX_LAT = 38.5;
const MIN_LON = 125.0;
const MAX_LON = 132.0;
export const options = {
stages: [
{ duration: '2m', target: 50 },
{ duration: '5m', target: 50 },
{ duration: '1m', target: 0 },
],
thresholds: {
http_req_failed: ['rate<0.01'],
http_req_duration: ['p(95)<1000'],
},
};
export function setup() {
console.log(`Cache warm-up for '${API_TARGET}' API starting...`);
const WARMUP_REQUESTS = 15;
for (let i = 0; i < WARMUP_REQUESTS; i++) {
const lat = Math.random() * (MAX_LAT - MIN_LAT) + MIN_LAT;
const lon = Math.random() * (MAX_LON - MIN_LON) + MIN_LON;
const radius = Math.floor(Math.random() * 1000) + 1;
let url;
if (API_TARGET === 'spatial') {
url = `http://localhost:8080/api/pixels/search?latitude=${lat}&longitude=${lon}&radius=${radius}`;
} else {
url = `http://localhost:8080/api/pixels/search/geohash?latitude=${lat}&longitude=${lon}&radius=${radius}`;
}
http.get(url);
sleep(0.2);
}
console.log('Cache warm-up finished.');
}
export default function () {
const lat = Math.random() * (MAX_LAT - MIN_LAT) + MIN_LAT;
const lon = Math.random() * (MAX_LON - MIN_LON) + MIN_LON;
const radius = Math.floor(Math.random() * 1000) + 1;
const requestParams = {
api: API_TARGET,
latitude: lat,
longitude: lon,
radius: radius,
};
console.log(JSON.stringify(requestParams));
let url;
if (API_TARGET === 'spatial') {
url = `http://localhost:8080/api/pixels/search?latitude=${lat}&longitude=${lon}&radius=${radius}`;
} else {
url = `http://localhost:8080/api/pixels/search/geohash?latitude=${lat}&longitude=${lon}&radius=${radius}`;
}
const res = http.get(url);
check(res, {
'status is 200': (r) => r.status === 200,
});
sleep(1);
}1차 실험 결과
• 평균 응답 시간: 19.44ms
• 95% 응답 시간: 18.67ms
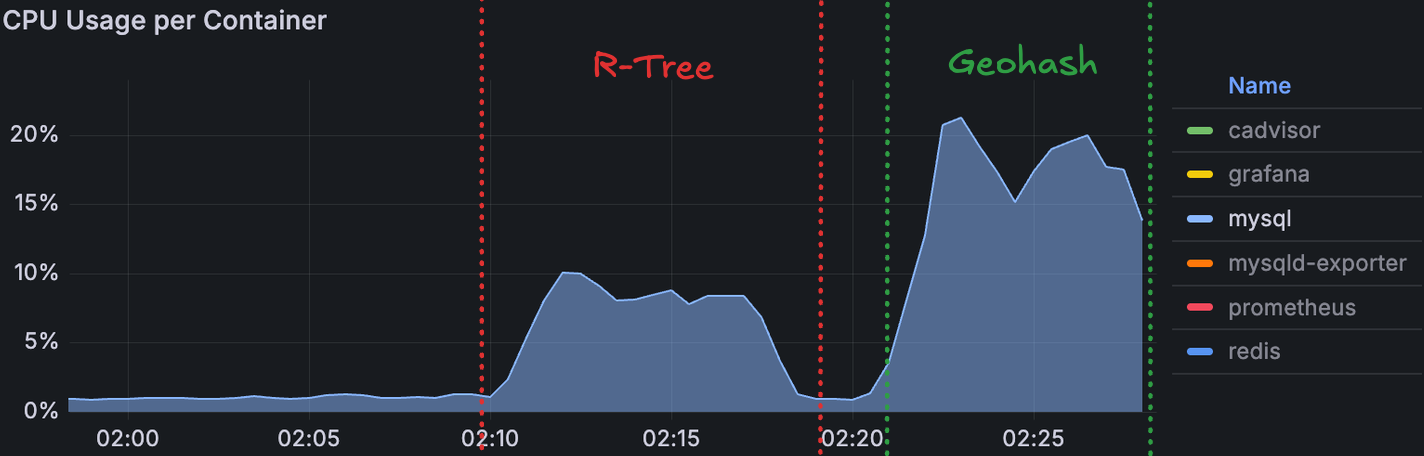
• 최대 응답 시간: 1.71초 (극단치)두 방식 모두 응답 속도 등은 비슷하게 유지했다. 하지만 오히려 CPU 사용량은 Geohash 쪽이 더 높게 유지되었다.
두 방식 모두 응답 속도 자체는 유사했지만, CPU 사용률은 Geohash 쪽이 더 높게 유지되었다.
그래서 한 단계 더 들어가 보기로 했다.
스레드와 커넥션 풀을 조정한 뒤, 고부하(1500 VU) 환경을 가정한 실험이다.
2차 실험 (1500 VU)
🟩 R-Tree 기반 결과
• 평균 응답 시간: 38.63 ms
• 95% 응답 시간: 162.45 ms
• Throughput: ≈ 665 req/s
• 오류율: 0 %
🟥 Geohash 기반 결과
• 평균 응답 시간: 18.64 s
• 95% 응답 시간: 47.17 s
• Throughput: ≈ 55 req/s
• 오류율: 1.9 %
명백하게 R-Tree가 성능이 좋았다. through put 부터 응답 속도까지...
분석
솔직히 납득이 가지 않았다.
B+Tree 기반의 Range Scan은 수많은 엔터프라이즈 시스템에서 쓰이는 검증된 기법인데, 이 정도의 차이라면 단순한 문자열 비교 오버헤드로는 설명이 안 된다.
혹시 문자열 비교 때문일까?
Geohash 컬럼 타입을 VARCHAR(255) → VARCHAR(12)로 줄여보았지만 결과는 동일했다.
문자열 길이나 자료형의 이슈가 아니라는 뜻이었다.
원인 - 레벨마다 32배로 늘어나는 데이터의 수
그때 문득, k6 결과의 data_received가 눈에 들어왔다.
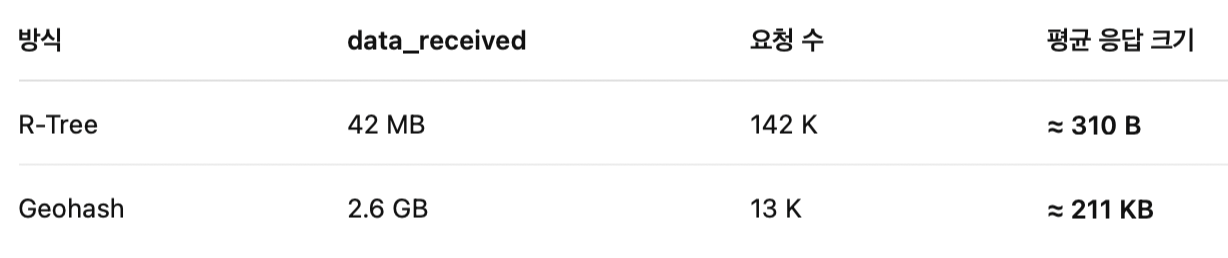
바로 답이 나왔다.
Geohash 쿼리는 훨씬 더 많은 데이터를 조회하고 있었다.
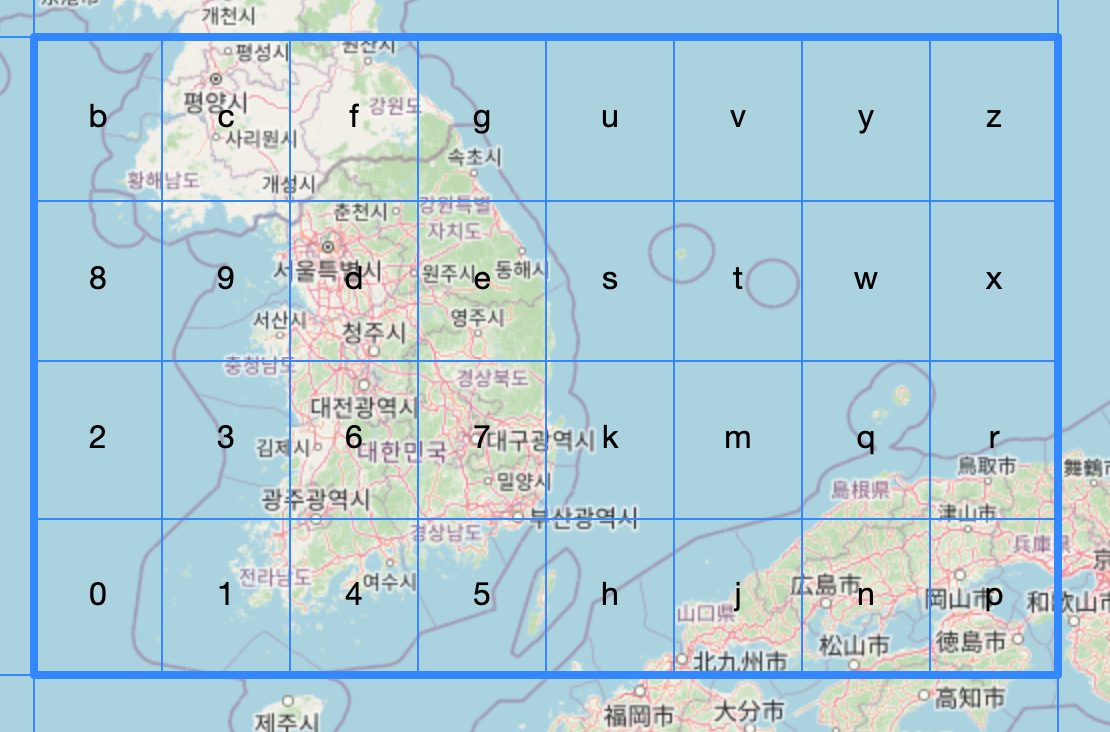
파라미터를 확인해 보니 wy, wyj, wyf 같은 prefix가 보였다. 이걸 지도로 시각화하자 놀라운 결과가 나왔다.
wy의 범위는....놀랍게도 대한민국 전체를 덮고도 남는 영역이었다.
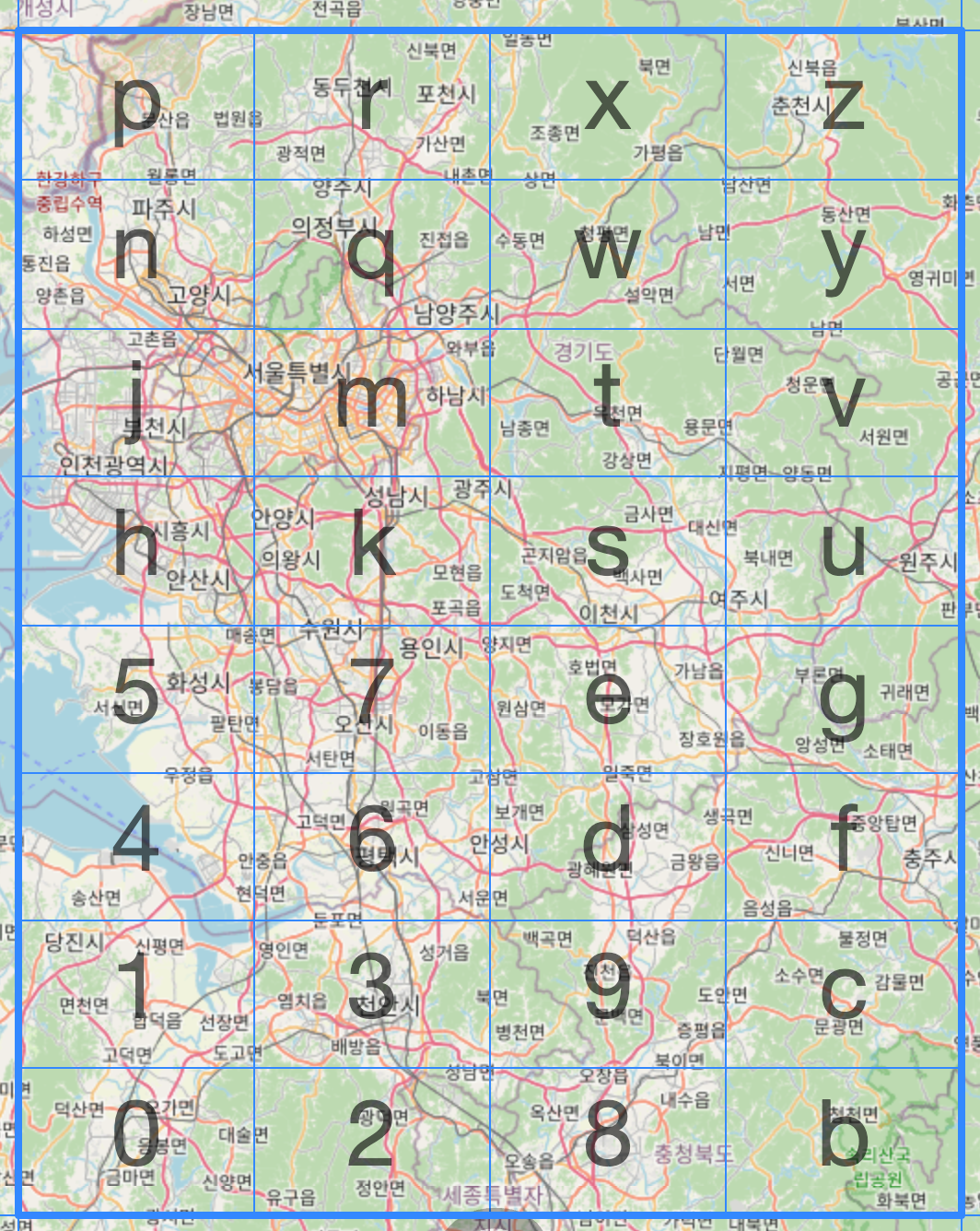
wyj같이 한자리가 더 늘어도, 그 영역은 서울에서 세종을 덮을 정도로 넓었다.
즉, Geohash의 prefix 단위가 너무 넓게 걸려버린 것이다.
LIKE ‘wy%’ 조건 한 줄이 전국 데이터를 긁어가는 셈이었다.
왜 이렇게 넓은 영역이 조회됐지?
Geohash는 prefix를 기준으로 공간을 나눈다.
이때 조회 원의 일부가 상위 레벨의 경계에 걸리면,
그 경계를 포함하는 모든 셀(32배의 영역)을 한꺼번에 조회해야 한다.
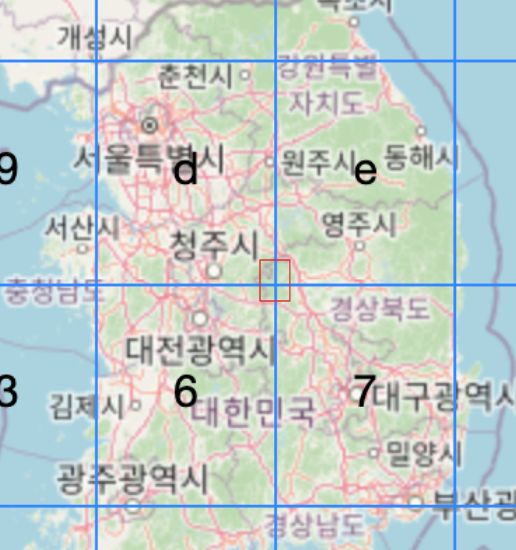
근데 만약에 이렇게 상위 레벨에서 조회 영역이 걸쳐버린다면, 조회 영역은 32배 늘어나게 된다.
실제로 wyj 단계만 가더라도, 조회되는 픽셀 수가 약 300만 건에 달했다.
결국 DB는 불필요한 I/O에 시달렸고, CPU 보다 I/O가 병목이 되어버린 것이다.
느낀 점
이번 실험은 ‘Trade-off’의 본질을 다시 느끼게 했다.
R-Tree의 CPU 비용을 줄이기 위해 B-Tree 기반으로 옮겨왔지만, 대신 I/O 비용이라는 다른 병목이 기다리고 있었다.
즉, “CPU 와 I/O 중 어느 쪽을 더 감당할 것인가” 이 문제는 단순히 인덱스 구조를 바꾸는 것으로 해결되지 않는다.
Geohash는 여전히 가능성이 있다. 다만 지금 형태 그대로는 “반경 검색”에 적합하지 않다.
걸침을 완화하기 위한 보정 로직, 또는 H3 같은 육각 셀 기반의 하이브리드 접근이 필요할 것 같다.
그게 아니면 결국 조회 영역 파티셔닝으로 가야 할지도 모르겠다.
