그라운드 플립 조회 시스템 개선 - 구상 편
서론
그라운드 플립은 ‘땅따먹기’ 게임에서 아이디어를 얻은 지도 기반 만보기 앱이다.
사용자는 걸음을 통해 실제 지도 위의 땅을 점령하고, 다른 사용자들과 경쟁하게 된다.
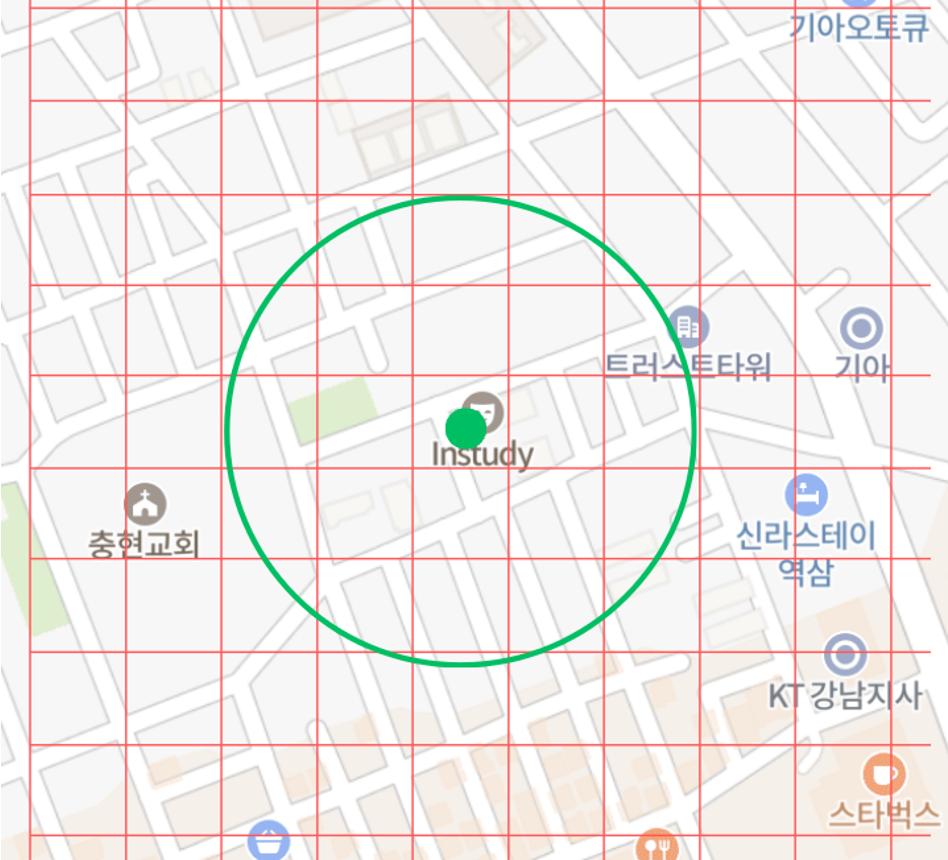 이 과정에서 핵심이 되는 기능은 지도 화면에 특정 반경 내에 현재 소유주가 존재하는 땅을 빠르고 정확하게 조회하는 것이다.
하지만, 서비스가 성장하면서 이 조회 시스템은 성능적·구조적 한계에 부딪혔다.
이 글에서는 그라운드 플립의 픽셀 조회 시스템이 어떤 발전 과정을 거쳤는지, 그리고 지금 시도하려는 새로운 접근(Geohash 기반 구조)에 대해 이야기하고자 한다.
이 과정에서 핵심이 되는 기능은 지도 화면에 특정 반경 내에 현재 소유주가 존재하는 땅을 빠르고 정확하게 조회하는 것이다.
하지만, 서비스가 성장하면서 이 조회 시스템은 성능적·구조적 한계에 부딪혔다.
이 글에서는 그라운드 플립의 픽셀 조회 시스템이 어떤 발전 과정을 거쳤는지, 그리고 지금 시도하려는 새로운 접근(Geohash 기반 구조)에 대해 이야기하고자 한다.
히스토리
그렇다면, 이 땅들을 빠르고, 효율적으로 구현하기 위해 어떤 발전 과정을 거쳐왔을까?
B-Tree 복합 인덱스 사용
초기에는 단순했다.
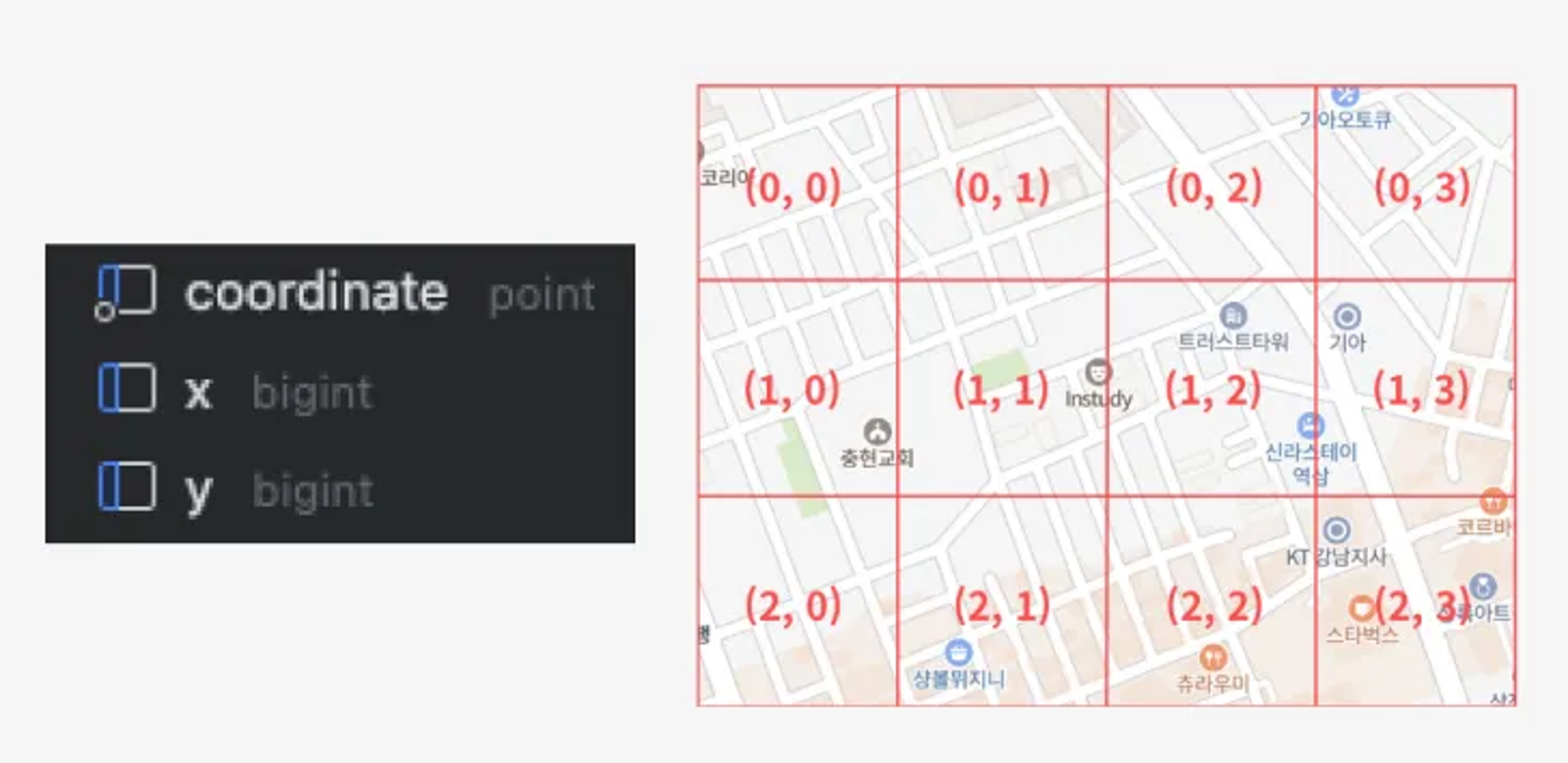
대한민국 전역을 일정한 크기의 그리드(pixel) 로 분할하고,
각 땅의 x, y 좌표를 B-Tree 복합 인덱스로 관리했다.
따라서, 아래와 같은 쿼리로 범위 조회를 수행할 수 있을 것이라 생각했다.
SELECT *
FROM pixel
WHERE x BETWEEN ? AND ?
AND y BETWEEN ? AND ?;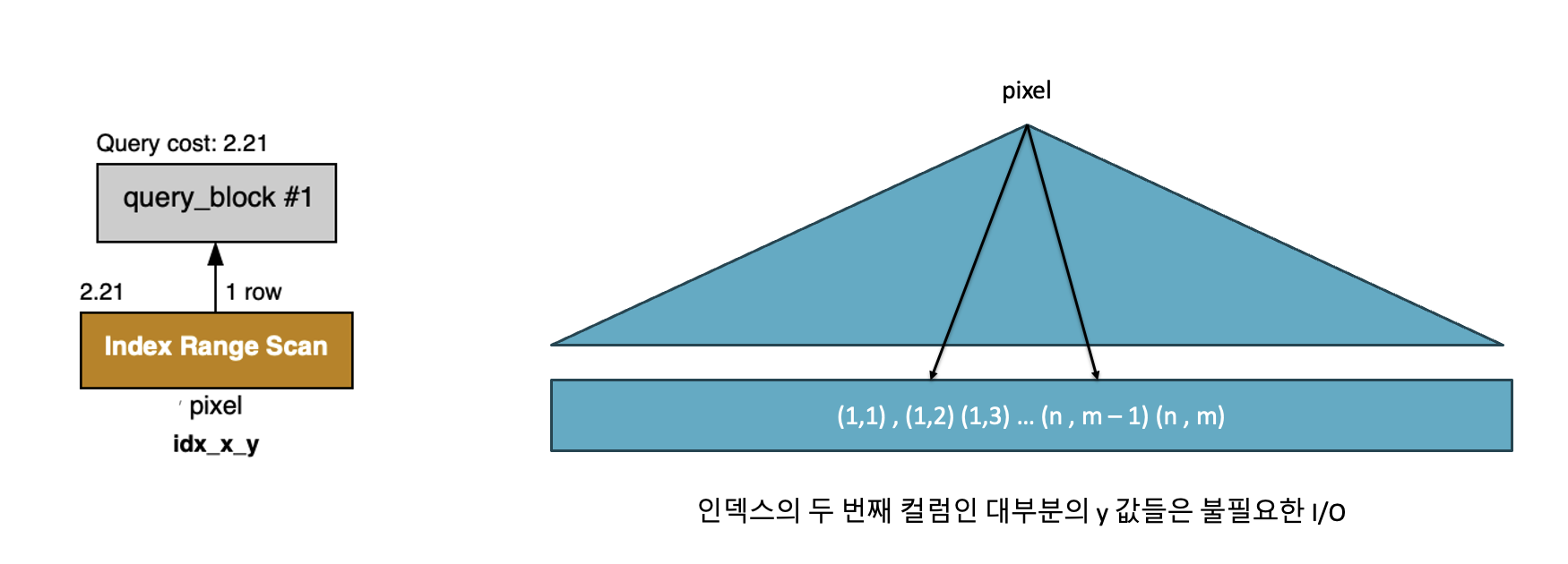
처음엔 나쁘지 않았다.
하지만 곧 두 번째 컬럼이 첫 번째 인덱스에 종속되는 구조적 한계가 드러났다.
특정 구간을 스캔하려면 x 축 기준으로 먼저 B-Tree를 따라 내려간 뒤, 그 안에서 다시 y를 전부 탐색해야 했다.
결국, 불필요한 I/O가 누적되며 성능이 점점 떨어졌고, 전국 단위 데이터를 대상으로는 유지가 불가능했다.
R-Tree 인덱스 사용
이후 우리는 공간 인덱스인 R-Tree로 눈을 돌렸다.
R-Tree란?
공간 데이터를 사각형(MBR)으로 감싸 트리 구조로 관리하는 방식으로,
영역 검색 시 평균적으로 O(log N) 수준의 탐색 성능을 낸다. 최악의 경우 O(N) 성능을 낼 수도 있다.
R-Tree는 MySQL에서 네이티브로 지원되고, 기존 좌표(Point) 컬럼에 단순히 인덱스를 추가하는 것만으로도 적용 가능했다.
CREATE SPATIAL INDEX idx_coordinate ON pixel(coordinate);적용 결과는 꽤 괜찮았다.
• 평균 조회 속도 약 200ms
• 별도 캐싱 없이도 실시간 응답 가능
• 구현 부담 거의 없음
그러나 이마저도 트래픽이 늘어나자 한계에 봉착했다.
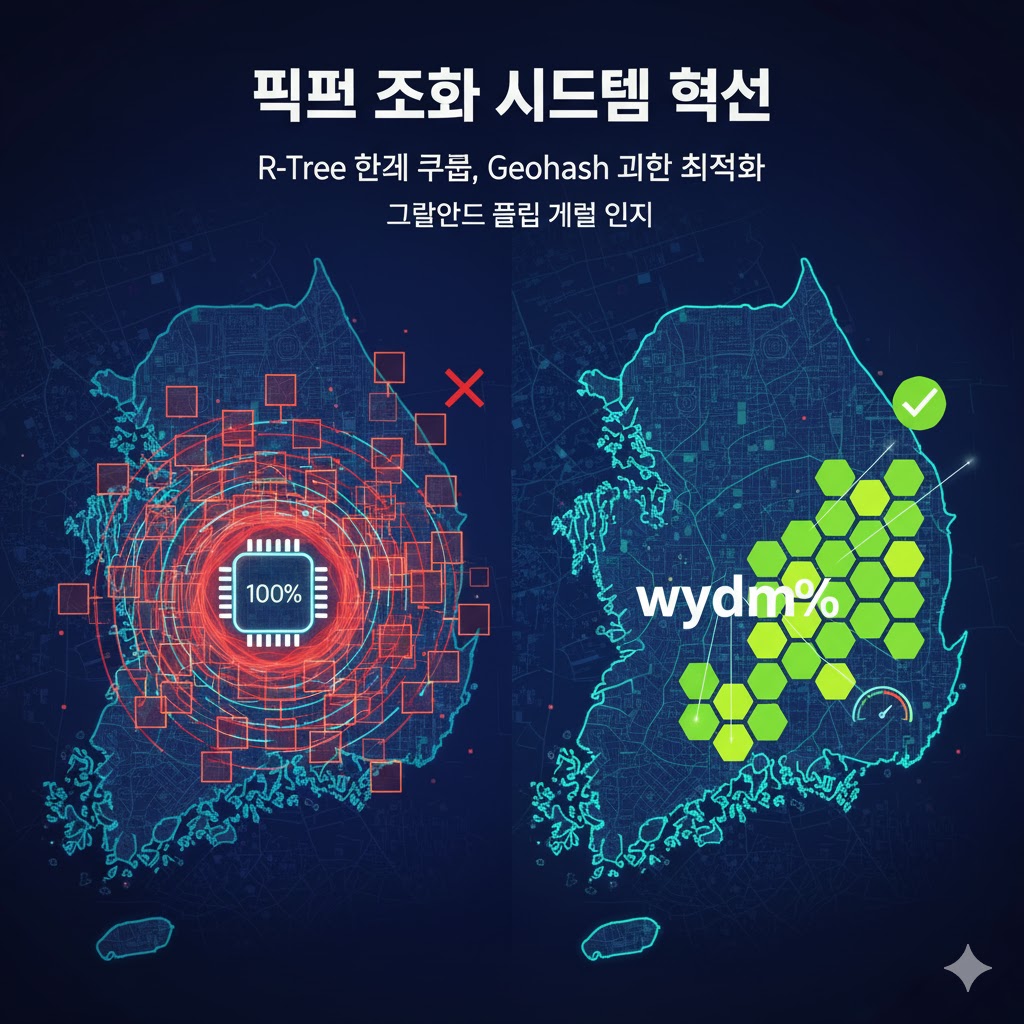
R-Tree 한계
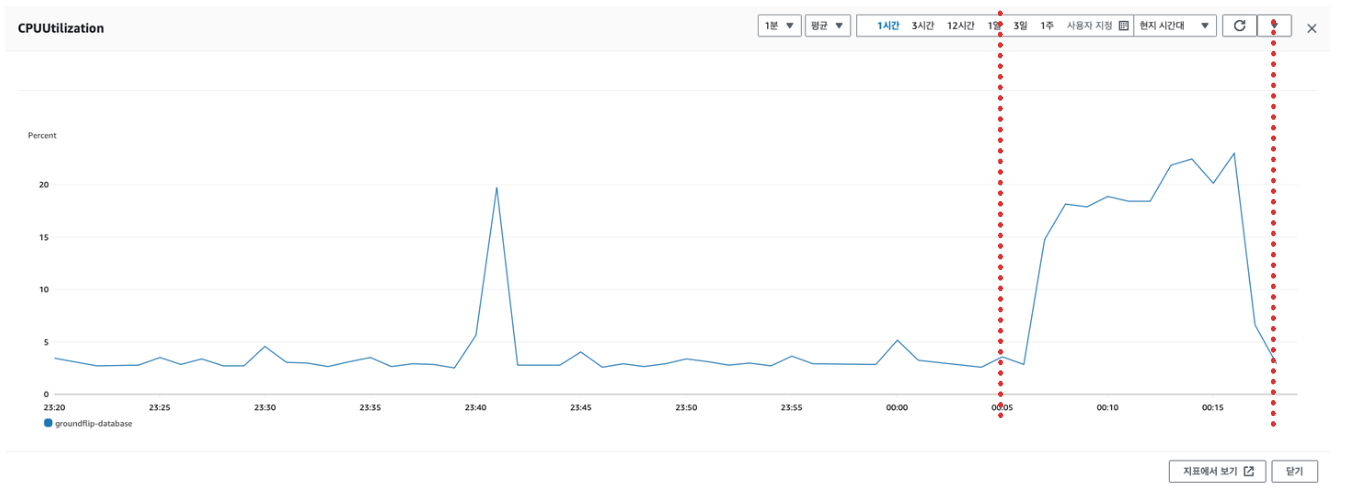
사용자 수가 1,000명을 넘고, 초당 요청 수(RPS)가 150을 돌파하던 시점, DB의 CPU 사용률이 100%까지 치솟았다.
원인을 추적한 결과, 조회 반경이 넓어질수록 MBR(최소 경계 사각형) 들이 과도하게 겹치며, 그만큼 비교 연산이 폭발적으로 늘어나는 구조였다.
즉, 데이터의 ‘양’이 늘수록 선형적으로 느려지는 문제였다.
현재 상황
문제를 단순히 “DB가 느리다”로 보지 않고, “정말 모든 땅 데이터를 저장해야 할까?”라는 관점으로 접근했다.
사실 대한민국 대부분의 땅은 아직 한 번도 밟히지 않았다. 즉, 실제로 필요한 데이터는 ‘누군가 방문한 픽셀들’ 뿐이었다.
그래서 접근 방식을 바꿨다.
“처음 방문한 순간에만 픽셀을 생성하자.”
즉, 전국 모든 땅을 미리 만들어두는 대신, 유저가 처음 해당 위치에 도착할 때 픽셀을 DB에 삽입하는 방식으로 전환했다.
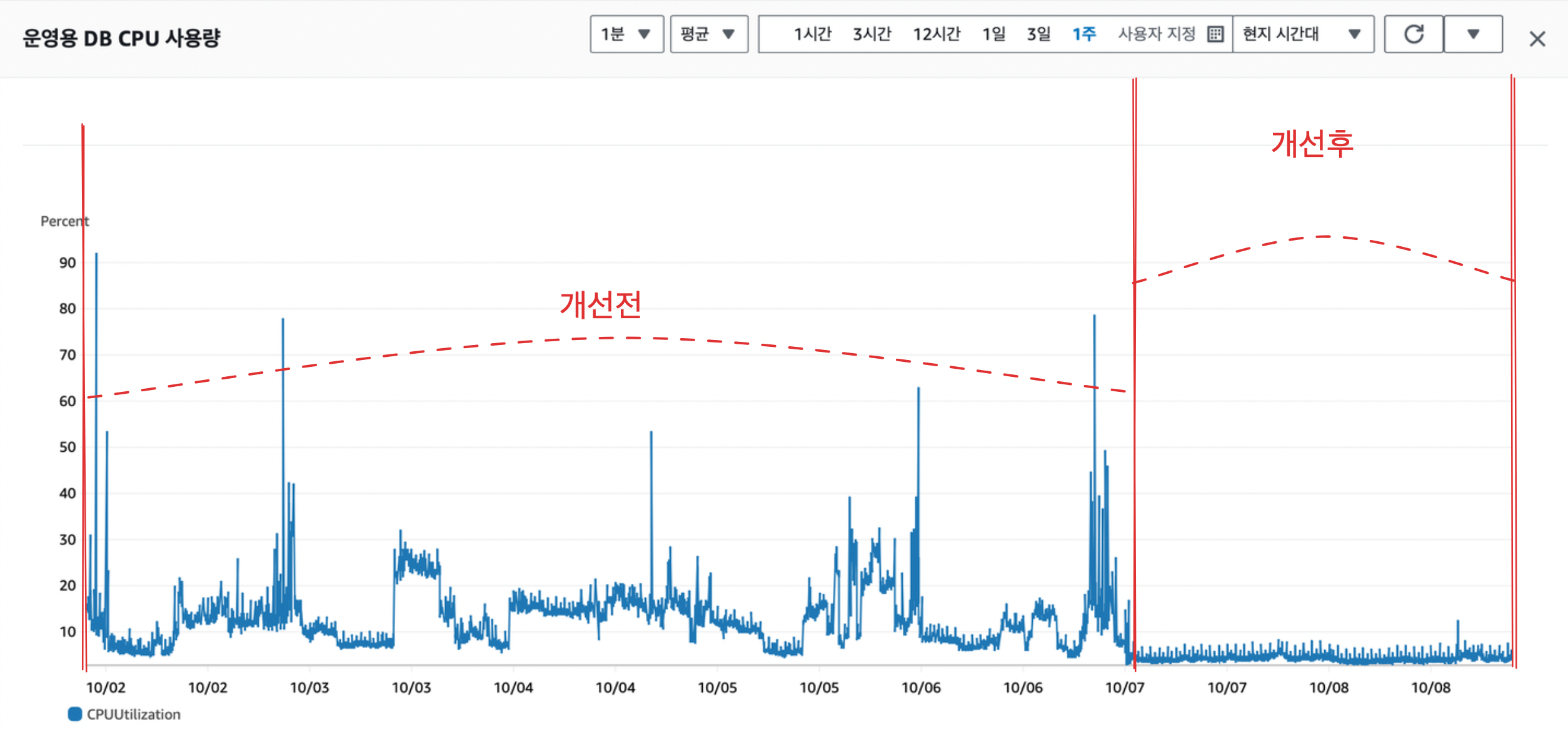
이 단순한 변화만으로도 동일 트래픽 대비 CPU 사용량이 10% 이내로 감소했다.
구상
하지만, 이 방법 또한 근본적으로는 동일한 문제가 발생한다. 실제로 많은 면접에서 아래와 같은 질문을 받았었다.
말씀해주신 방법이 이해는 가는데,,, 만약 모든 땅을 다 방문하거나, 서비스 지역을 전세계로 늘린다면 문제가 생기지 않을까요?
간단한 아이디에이션
그라운드 플립의 “픽셀 조회”는 사실 단순한 문제처럼 보이지만, 근본적으로 공간 검색(spatial query) 의 효율성과 정확도를 모두 만족시켜야 하는 영역이다.
R-Tree는 분명 한동안 좋은 성과를 냈지만, 서비스의 규모가 커지고 데이터가 축적되면서 구조적 한계를 드러냈다.
즉, 단순히 “공간을 빠르게 찾는 방법”을 넘어서,
“우리가 필요한 공간 데이터만 효율적으로 관리할 방법” 이 필요했다.
그래서 새로운 접근을 고민했다.
“R-Tree가 아니라, 좌표를 직접 1차원 데이터 (정수, 문자열 등)으로 바꿀 수는 없을까?”
그렇게 해서 단순 1차원 B-Tree 인덱스 Range Scan만으로 조회를 할 순 없을까?
이 아이디어에서 출발한 것이 바로 공간 해싱(Spatial Hashing) 이다.
좌표를 해시처럼 압축해 문자열로 표현하고, 이를 기반으로 DB 인덱스를 활용하는 기법이다.
대표적인 방식으로는 H3(by Uber)와 Geohash가 있다.
H3 VS Geohash
좌표를 효율적으로 인덱싱하는 대표적인 방식은 두 가지가 있다.
하나는 Geohash, 다른 하나는 H3(Uber Hexagonal Hierarchical Spatial Index) 이다.
두 기술 모두 위도(latitude)와 경도(longitude)를 격자(grid) 로 변환하여
공간 데이터를 일정한 구간 단위로 나누고 관리하는 공간 해싱(spatial hashing) 방법이다.
하지만 내부 구조와 활용 방식은 완전히 다르다.
아래는 두 방식의 핵심 개념과 차이를 요약한 것이다.
Geohash란?
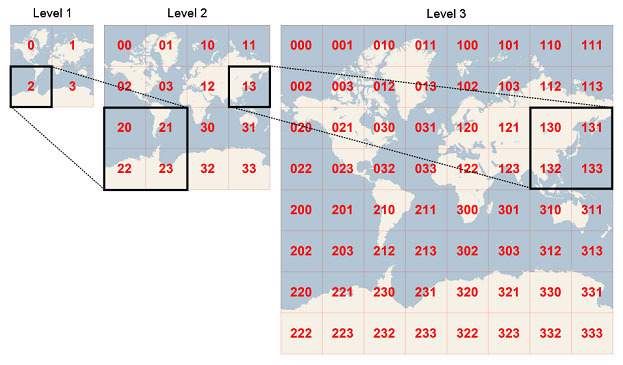
“위도와 경도를 이진수로 번갈아가며 압축한 문자열 해시”
Geohash는 좌표를 Base32 문자열로 표현하는 방식이다.
위도와 경도를 이진수로 변환하고, 이 비트를 번갈아 interleave(교차 결합)하여 하나의 긴 2진수를 만든 뒤, Base32로 인코딩한다.
이 구조의 가장 큰 특징은 다음과 같다:
• 문자열의 앞부분(prefix)이 공간적으로 상위 영역을 의미한다.
• 예를 들어 "wydm" 으로 시작하는 Geohash는 서울 종로 일대를 포함할 수 있다.
• 즉, LIKE ‘wydm%’ 형태의 쿼리만으로도 “서울 종로 일대”를 빠르게 조회할 수 있다.
이 덕분에 문자열 prefix 검색만으로 공간 범위를 표현할 수 있고, MySQL의 B-Tree 인덱스와 완벽히 맞물린다.
SELECT *
FROM pixel
WHERE geohash LIKE 'wydm%';이 한 줄로, wydm으로 시작하는 모든 지역 — 즉, 동일한 공간 내의 픽셀을 바로 찾을 수 있다.
이건 단순히 문자열 검색 같아 보이지만, 실제로는 공간적 계층 구조를 따른 범위 검색(range scan) 이다.
H3란?
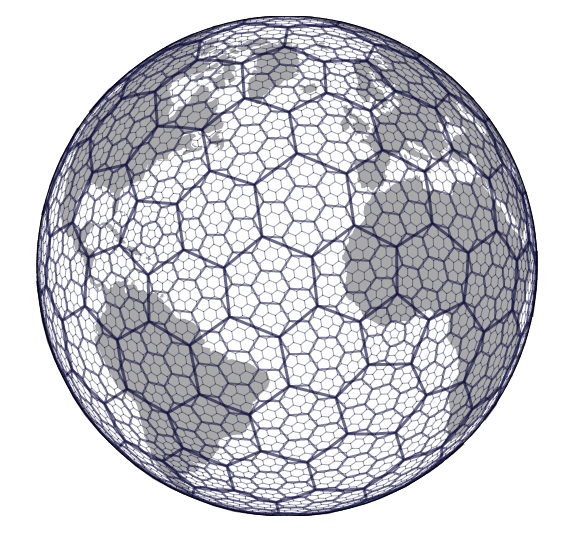
“지구를 정육각형(hexagon) 단위로 계층적으로 분할하는 64비트 인덱스 시스템”
H3는 Uber에서 개발한 공간 인덱싱 시스템으로, 지구를 육각형 격자로 나누어 각 셀마다 고유한 64비트 정수 ID를 부여한다.
이 덕분에 지리적 데이터를 균등한 면적으로 표현할 수 있고, 정확한 반경 기반 탐색이나 클러스터링에 강점을 가진다.
하지만 H3의 ID는 내부 비트 패턴으로 인코딩된 정수 값이기 때문에, 문자열처럼 prefix(접두어)로 계층 관계를 표현하거나 LIKE 'prefix%' 같은 범위 검색을 수행할 수 없다.
즉,
• H3의 “계층 구조”는 내부적으로만 존재하며,
• 문자열 prefix로는 공간적 상하 관계를 식별할 수 없다.
따라서 DB 내에서 H3를 활용하려면, IN (...) 절로 여러 셀을 직접 지정하거나
애플리케이션 단에서 kRing() / gridDisk() 등을 통해 주변 육각형 셀을 계산해 조회해야 한다.
이 방식은 정확도는 높지만, 범위 검색을 단일 인덱스 스캔으로 처리할 수 없다는 점에서 실시간 서비스보다는 분석·집계용에 더 적합하다.
Geohash를 선택한 이유
그라운드 플립의 핵심은 “지도 위 점령지를 빠르고 실시간으로 조회”하는 것이다.
즉, 정확도보다 즉각적인 응답성과 단순한 인덱스 활용이 훨씬 중요하다.
• H3는 정밀하고 수학적으로 아름답지만,
반경 검색마다 주변 셀을 계산해야 하고, DB에서는 IN 절 탐색밖에 쓸 수 없다.
• Geohash는 단 한 줄의 SQL (LIKE 'prefix%') 만으로 수천 개의 공간을 커버하는 빠른 Range Scan을 수행할 수 있다.
즉, H3는 “정확한 공간분석”에 강하고, Geohash는 “빠른 실시간 렌더링”에 강하다.
그리고 그라운드 플립이 필요한 건 실시간 렌더링 쪽이었다.
다음 글 예고
다음 글에서는 이 아이디어를 실제로 프로토타입 형태로 구현해볼 예정이다.
• 픽셀 좌표에 Geohash를 부여하고
• prefix 기반 Range Scan으로 반경 내 데이터를 조회하며
• 기존 R-Tree 방식과의 쿼리 시간, CPU 사용률을 비교한다.
아직 완성된 답은 아니지만,
이 실험을 통해 “공간 데이터를 문자열로 다룬다는 접근이 얼마나 현실적인가”를 검증할 것이다.
