
서론
이 글은 MySQL에서 랜덤한 레코드를 추첨하는 쿼리를 효율적으로 개선하는 과정을 정리한 글입니다.
 |  |
|---|
그라운드 플립은 최근 유저분들의 성원에 보답하기 위해 이벤트를 진행했다.
일주일 간 50px 이상을 점령한 사용자를 대상으로 10명을 추첨해 기프티콘을 진행하는 이벤트였다!
그렇게 많은 사용자분들이 일주일 간 우리 앱을 사용하시며 걸어주셨고 당첨자를 추첨할 시간이 다가왔다.
추첨은 어떻게 하지..?
우리가 원했던 것은 픽셀을 많거나 적게 차지한 사용자들 위주로 10명을 뽑는 것이 아니라 고루 퍼진 당첨자 목록을 원했었다.
이런 점을 고려했을 때 팀원과 장난삼아 랭킹창 중 적당히 우리가 랜덤을 고르는 휴먼 랜덤도 얘기했었다...ㅋㅋㅋㅋ
하지만
- 간편하고
- 모두가 납득 가능하며
- 재사용 가능한
방식이 필요했다.
결국 RDB(MySQL) 상에 쿼리를 날려 당첨자를 추첨하기로 했다.
그라운드 플립엔 매주 아래와 같은 테이블에 Redis 상에 있던 랭킹 데이터를 RDB에 영속화시키기에 이 정보를 사용할 수 있었다.
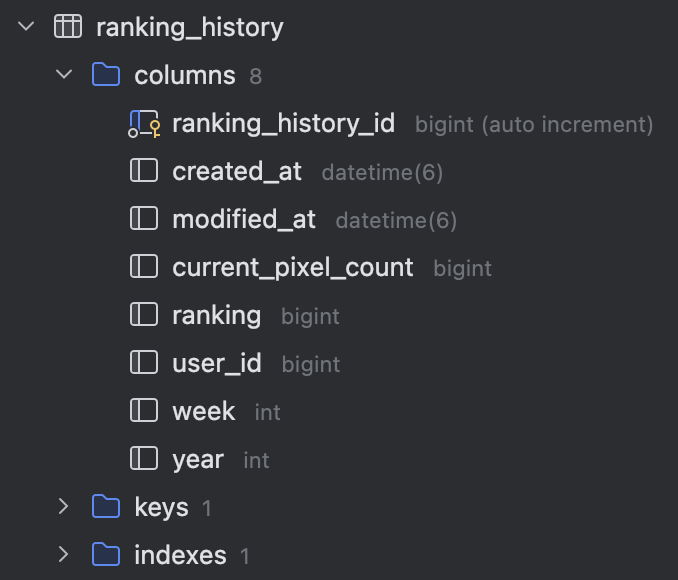
아래와 같은 쿼리를 사용해 랜덤으로 10명을 추출했다.
-- 해당 주차의 픽셀 50개 이상 차지한 사용자를 모두 가져온다.
WITH RankedUsers AS (
SELECT rh.current_pixel_count, rh.user_id, user.nickname
FROM ranking_history rh
LEFT JOIN user ON user.user_id = rh.user_id
WHERE rh.week = 45 and rh.current_pixel_count >= 50
)
-- 랜덤으로 정렬해서 상위 10명을 추첨한다.
SELECT current_pixel_count as '픽셀 수', nickname as '닉네임'
FROM RankedUsers
ORDER BY RAND()
LIMIT 10;근데 문득 이 쿼리가 "진짜 괜찮나..?"라는 생각이 들었다.
만약 50px 이상 차지한 유저가 지금처럼 몇십, 몇백명이 아니라 몇백만이 된다면..?
결국 해당 레코드들을 모두 정렬하는 꼴인 위 쿼리는 매우 느릴 것이며, 운영 상태에 있는 DB에서 급격한 리소스 소비를 할 것이다.
특히 랜덤 쿼리가 성능에 미치는 영향이 꽤나 지대하다고 들어서 관련된 실험으로 한 번 알아보려고 한다.
실험
시나리오
테스트 할 인스턴스
- MySQL (8.x)
- AWS db.t3.micro
- vCPU 2개
- RAM 1GB
테스트 할 테이블
CREATE TABLE IF NOT EXISTS user (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
age INT,
last_login TIMESTAMP
);1. ORDER BY RAND() 방식
우선 이 테이블에 레코드 수를 100만개까지 늘려가며 10개의 데이터를 기존 ORDER BY RAND() 방식으로 추출해보기로 했다.
코드 전문
import mysql.connector
import random
import string
import time
import matplotlib.pyplot as plt
# MySQL 연결 설정
db_config = {
"host": "",
"user": "",
"password": "",
"database": ""
}
# 데이터베이스 초기화 및 설정
def setup_database():
connection = mysql.connector.connect(**db_config)
cursor = connection.cursor()
cursor.execute("CREATE DATABASE IF NOT EXISTS test_db")
cursor.close()
connection.close()
# 테이블 생성
def create_table(connection):
cursor = connection.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS user (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
age INT,
last_login TIMESTAMP
)
""")
connection.commit()
cursor.close()
# 데이터 삽입
def insert_data(connection, num_records):
cursor = connection.cursor()
batch_size = 10000
batches = num_records // batch_size
remaining = num_records % batch_size
def generate_batch(size):
return [
(
''.join(random.choices(string.ascii_letters, k=8)),
f"{random.randint(1000, 9999)}@example.com",
random.randint(18, 99),
"2023-01-01 00:00:00"
)
for _ in range(size)
]
for _ in range(batches):
data = generate_batch(batch_size)
cursor.executemany(
"INSERT INTO user (username, email, age, last_login) VALUES (%s, %s, %s, %s)",
data
)
if remaining > 0:
data = generate_batch(remaining)
cursor.executemany(
"INSERT INTO user (username, email, age, last_login) VALUES (%s, %s, %s, %s)",
data
)
connection.commit()
cursor.close()
# 랜덤 추출 및 시간 측정
def measure_query_time(connection):
cursor = connection.cursor()
start_time = time.time()
cursor.execute("SELECT * FROM user ORDER BY RAND() LIMIT 10")
_ = cursor.fetchall() # 결과를 가져오기만 함
elapsed_time = time.time() - start_time
cursor.close()
return elapsed_time
# 테이블 삭제
def drop_table(connection):
cursor = connection.cursor()
cursor.execute("DROP TABLE IF EXISTS user")
connection.commit()
cursor.close()
# 메인 실행 함수
def main():
setup_database()
connection = mysql.connector.connect(**db_config)
record_sizes = [1000, 10000, 100000, 500000, 1000000] # 데이터 크기 단계
query_times = []
for num_records in record_sizes:
print(f"Testing with {num_records} records...")
create_table(connection)
insert_data(connection, num_records)
elapsed_time = measure_query_time(connection)
query_times.append(elapsed_time)
drop_table(connection)
print(f"Query time for {num_records} records: {elapsed_time:.4f} seconds")
connection.close()
# 결과 시각화
plt.figure(figsize=(10, 6))
plt.plot(record_sizes, query_times, marker='o', linestyle='--', color='b')
plt.title("Query Time vs Number of Records (ORDER BY RAND())")
plt.xlabel("Number of Records")
plt.ylabel("Query Time (seconds)")
plt.grid(True)
plt.show()
if __name__ == "__main__":
main()
결과
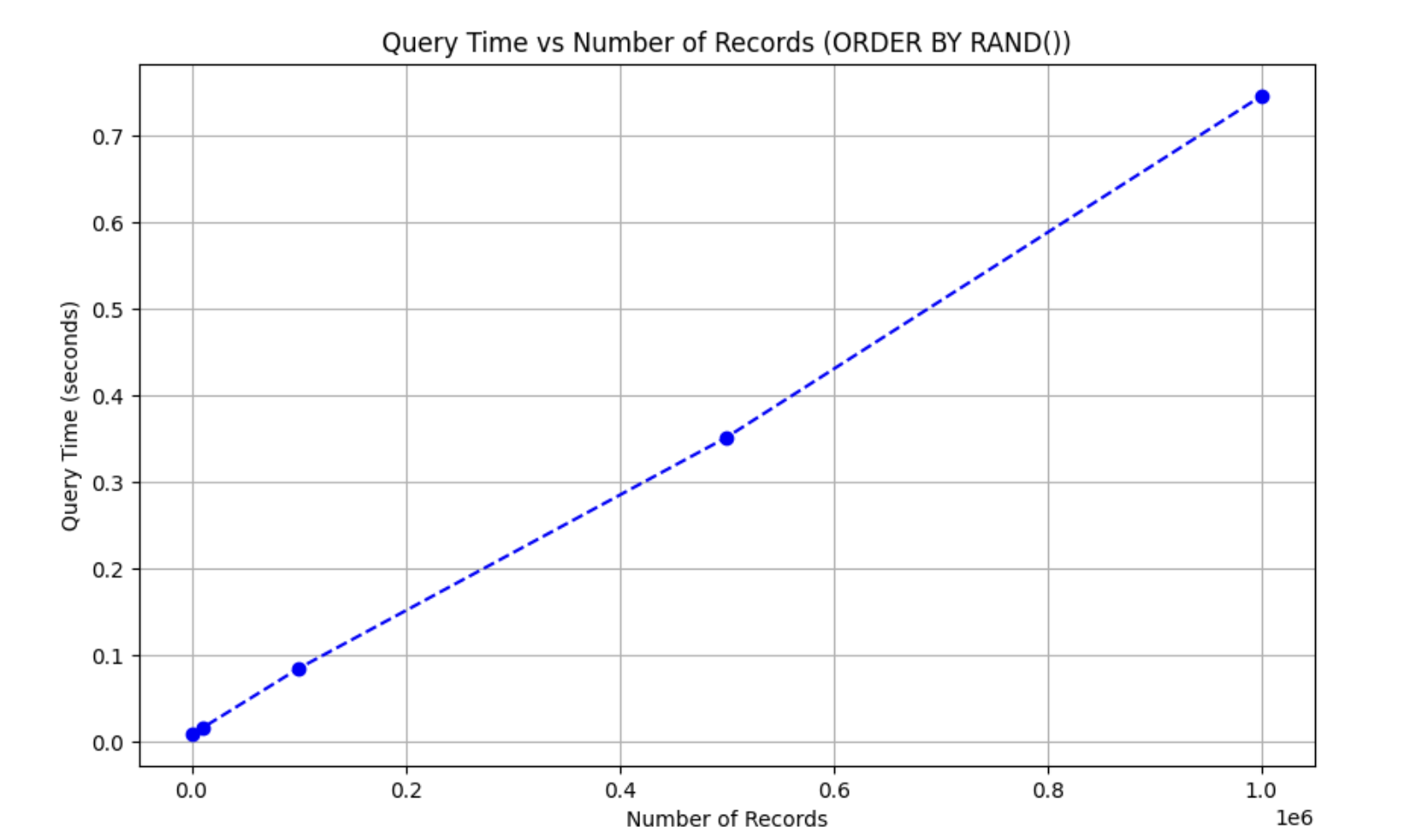
아주 정직하게 사용자 수에 비례하는 것을 볼 수 있다. 특히 100만 개의 레코드에서 10개를 추출하는 것은 약 0.75초가 소모됐다.

실행 계획을 자세히 보자면 Sort를 하는 데에 꽤나 긴 시간이 걸린 것을 볼 수 있다.
2. 샘플링 기법 사용
모든 레코드에 대해 정렬을 하는 것이 오래 걸리는 작업이라면 정렬해야 하는 레코드를 줄여보는 것은 어떨까?
아래와 같이 쿼리를 작성해봤다.
RAND()는 0~1까지의 실수만 가지므로 이걸 활용해 1%를 샘플링하고 이 1%에 대해서만 정렬을 하는 쿼리이다.
-- 전체 행의 1%를 서브쿼리로 샘플링한 뒤, 여기서 10개를 랜덤 추출
SELECT *
FROM (
SELECT *
FROM users
WHERE RAND() < 0.01 -- 1% 확률로 샘플링
) AS sampled_users
ORDER BY RAND()
LIMIT 10;결과
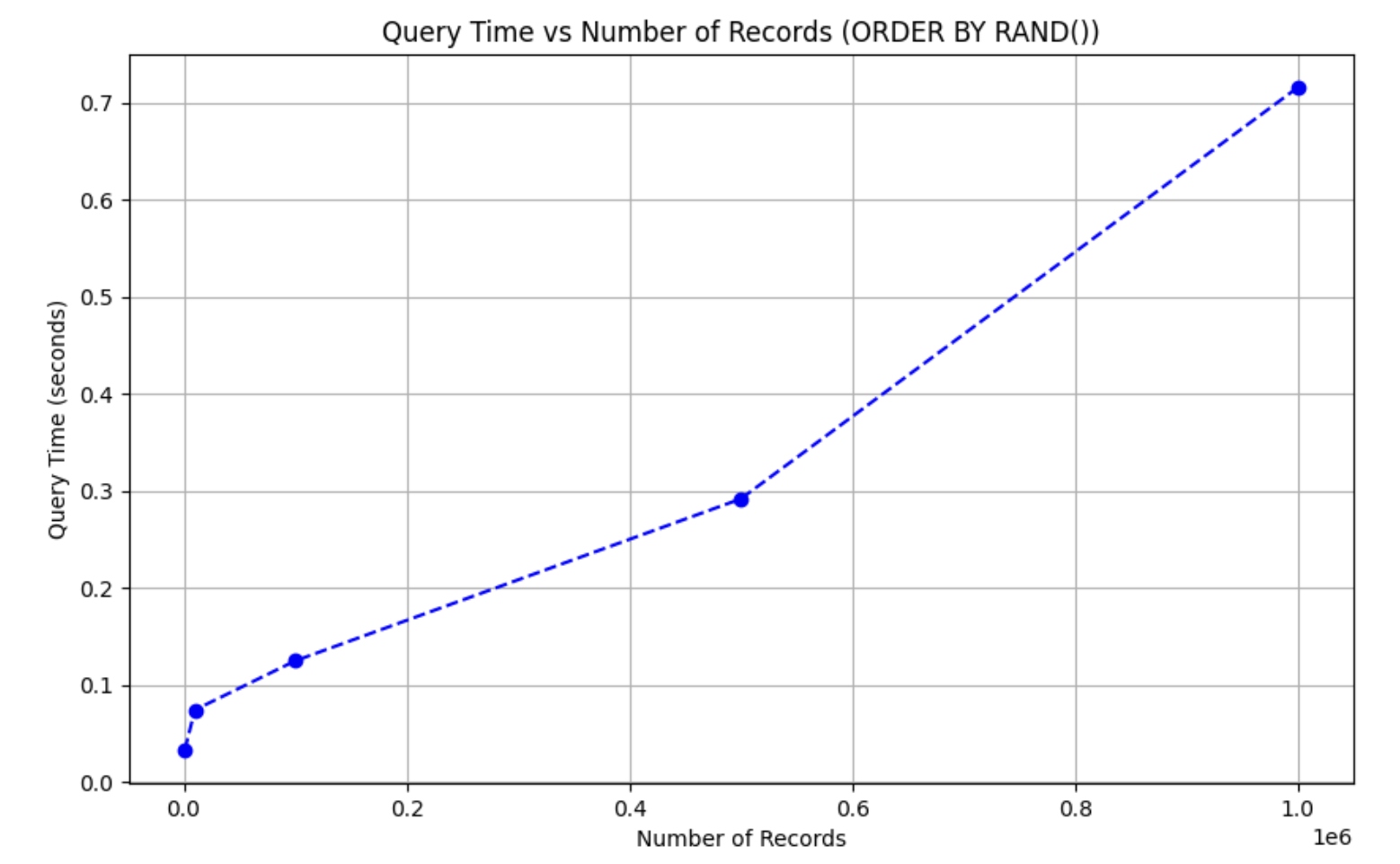
음.. 100만 개에 대해서 0.7초가 걸린 것을 보아 별다른 차이가 없는 것 같다.
고민
아... 머리가 아프다...
도대체 어떻게 해야할까...
난수를 부여하는 게 코스트가 크다면 난수를 미리 만들어 저장하는 컬럼을 만들면 되지만... 절대 내가 원하는 방식은 아니다.
이렇게 고민하던 중 글 하나를 발견했다.
https://jan.kneschke.de/projects/mysql/order-by-rand/
내가 하던 고민과 정확히 똑같은 글이었고 해답을 찾을 수 있었다.
3. 순수 쿼리 튜닝과 프로시저
자 이 방법은 우선 PK의 최댓값 * RAND()한 값을 난수로서 활용한다.
예를 들면 이런 식이다.
SELECT CEIL(RAND() * (SELECT MAX(id) FROM users))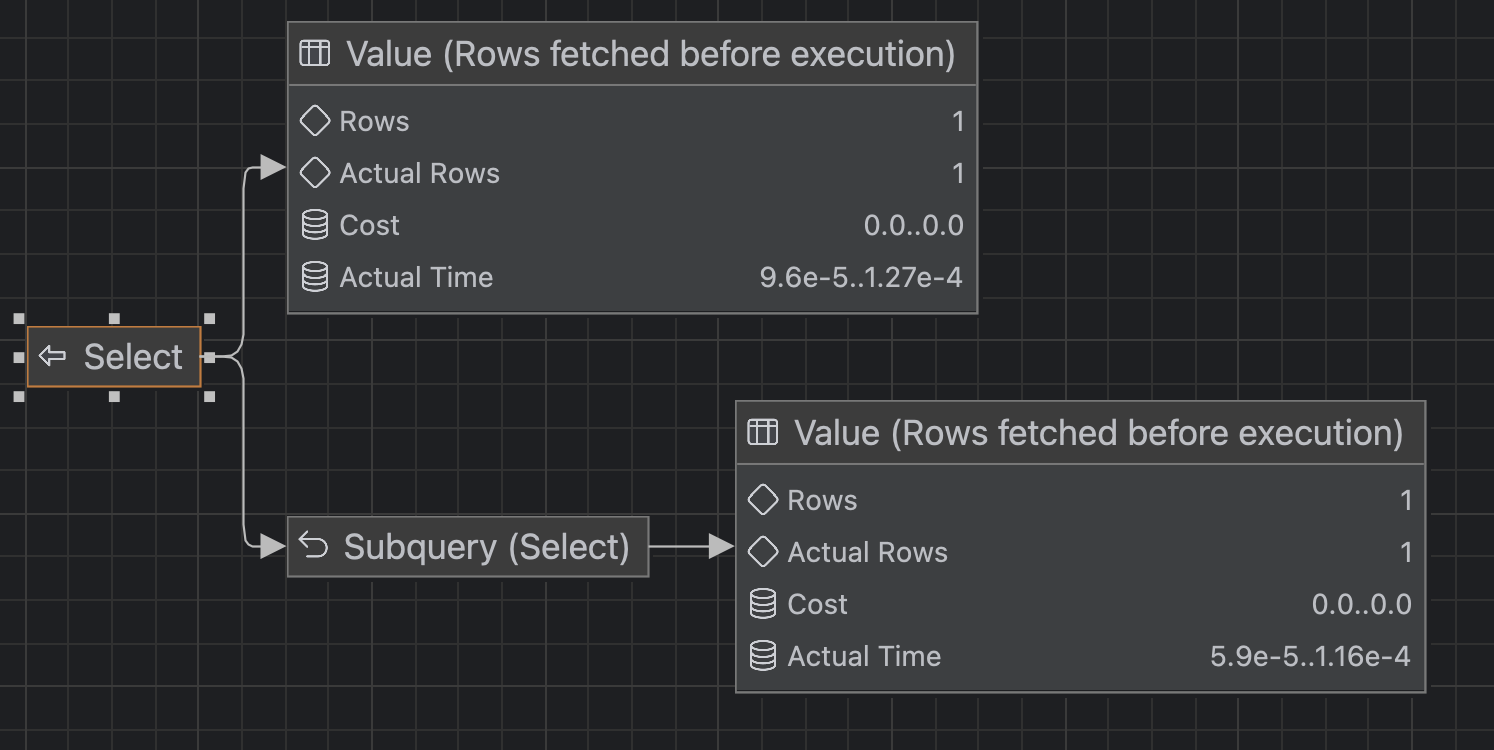
보다시피 SELECT MAX(id) FROM users는 PK이기 때문에 인덱스를 역순 탐색해 매우 빠른 속도로 실행되고 결국 cost가 0에 가깝게 난수를 뽑을 수 있다.
이것을 활용해서 난수와 같은 PK를 JOIN을 사용해 선택한다.
SELECT users.id
FROM users JOIN
(SELECT CEIL(RAND() * (SELECT MAX(id) FROM users)) AS id) AS r2
USING (id);이렇게 하면..?

진짜 엄청나게 낮은 코스트로 랜덤한 레코드를 "하나" 선택할 수 있다.
우리의 목표는 10개를 뽑는 것이니 간단하게 procedure를 만들었다.
DELIMITER $$
DROP PROCEDURE IF EXISTS get_rands$$
CREATE PROCEDURE get_rands(IN cnt INT)
BEGIN
DROP TEMPORARY TABLE IF EXISTS rands;
CREATE TEMPORARY TABLE rands ( rand_id INT );
loop_me: LOOP
IF cnt < 1 THEN
LEAVE loop_me;
END IF;
INSERT INTO rands
SELECT users.id
FROM users JOIN
(SELECT CEIL(RAND() *
(SELECT MAX(id)
FROM users)) AS id
) AS r2
USING (id);
SET cnt = cnt - 1;
END LOOP loop_me;
END$$
DELIMITER ;그렇다면 이제 한 번 결과를 확인해보자.
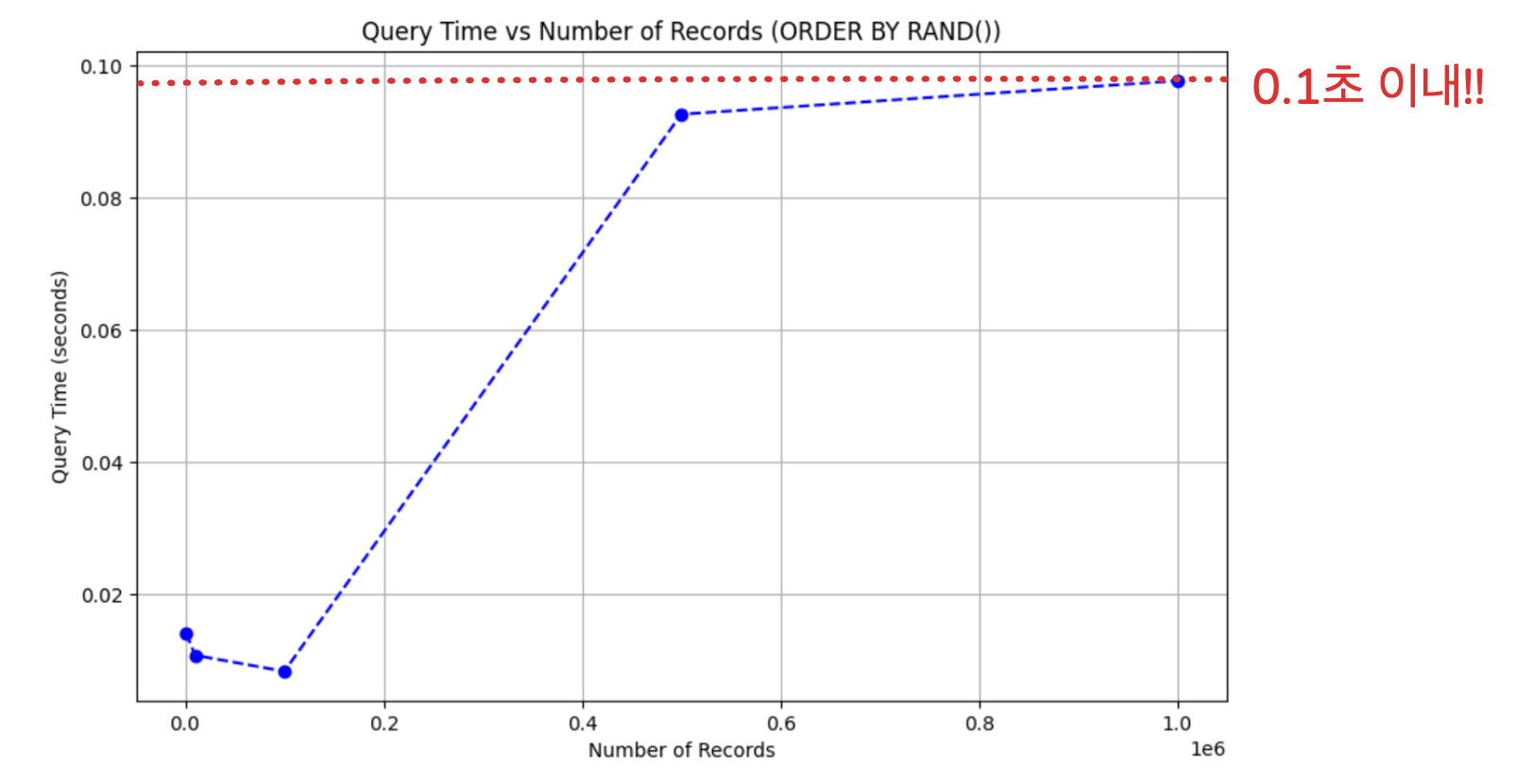
레코드 수가 100만개가 되어도 0.1초 이내로 실행되는 것을 볼 수 있다.
하지만 이 방식에도 한계가 존재한다.
- 해당 프로시저엔 unique한 레코드를 뽑는 부분이 아직 미구현돼있다.
- 실제로 서비스에 사용한다면 탈퇴했거나 조건에 맞지 않는 유저도 필터링 해야한다.
- 난수와 같은 PK가 없다면 재추첨같은 로직이 필요하다.
최종 결과
| 레코드 수 | ORDER BY RAND() | 쿼리 튜닝 |
|---|---|---|
| 1천 | 0.0172 | 0.0141 |
| 1만 | 0.0169 | 0.0108 |
| 10만 | 0.1396 | 0.083 |
| 50만 | 0.5646 | 0.0926 |
| 100만 | 0.7631 | 0.0977 |
결론
사실 데이터베이스를 잘 안다고 생각했지만 위에 링크해둔 글을 이해하는 데 꽤 오랜 시간이 걸렸다.
그리고 컬럼을 추가하거나 더 복잡한 방법으로 개선하려 했지만 정말 쿼리를 잘 쓰는 것만으로도 이렇게 효율을 높일 수 있다니.. DB 공부를 정말 열심히 해야겠다는 생각이 들었다.

당신의 글 내용이 매우 흥미롭습니다. 정말 감명받았습니다. 더 많은 훌륭한 글을 기대합니다. 감사합니다! Wellstar MyChart