
글을 시작하기 전...
이 글은 리버스 지오코딩 기능을 자체적으로 구현한 Flask 서버에서 발생했던 shp 파일의 과도한 메모리 용량 문제를 해결하는 과정을 담은 글입니다.
또한, 본인은 Python과 Flask에 대해 깊은 지식이 없으며 GPT의 도움과 여러 접근 방식으로 문제를 해결했습니다.
따라서 글 내용 중 일부 틀린 점이 있더라도 너그러이 읽어주시면 감사하겠습니다.
서론
현재 진행중인 프로젝트에선 '리버스 지오코딩'이 필요하다.
정확히 말하자면, "위경도 좌표를 입력받아 시/도, 시/군/구를 알 수 있는 기능"이 필요했다.
리버스 지오코딩이란?
위,경도 같은 위치를 입력받아 사람이 읽을 수 있는 주소로 변환하는 기술을 의미한다.
기존에는 해당 기능을 네이버 클라우드의 API에 의존하고 있었지만
- 무료 사용량 제한
- 높은 레이턴시
- 외부 의존성
등의 문제로 팀원이 대한민국 시군구의 shp 파일과 간단한 Flask 서버를 사용해 이를 직접 구현해놓은 상태이다.
코드 전문
app = Flask(__name__)
transformer = Transformer.from_crs("EPSG:4326", "EPSG:5186", always_xy=True)
def load_all_shp():
shapefile_directory = "gis"
gdf_list = []
for folder_name in os.listdir(shapefile_directory):
folder_path = os.path.join(shapefile_directory, folder_name)
if os.path.isdir(folder_path):
for file in os.listdir(folder_path):
if file.endswith(".shp"):
filepath = os.path.join(folder_path, file)
gdf = gpd.read_file(filepath)
gdf_list.append(gdf)
merged_gdf = gpd.GeoDataFrame(pd.concat(gdf_list, ignore_index=True))
merged_gdf = merged_gdf.rename(columns={'SGG_NM': 'region_name'})
return merged_gdf
def load_region_info():
df = pd.read_csv('region.csv')
name_id_dict = pd.Series(df.region_id.values, index=df.name).to_dict()
print('[성공] 지역 정보 불러오기 성공')
return name_id_dict
merged_gdf = load_all_shp()
region_dict = load_region_info()
def find_district(lon, lat):
transformed_x, transformed_y = transformer.transform(lon, lat)
point = Point(transformed_x, transformed_y)
matched_area = merged_gdf[merged_gdf.contains(point)]
if not matched_area.empty:
district_name = matched_area.iloc[0]['region_name']
return district_name
else:
return None
@app.route('/find_district', methods=['GET'])
def find_district_api():
lon = float(request.args.get('lon'))
lat = float(request.args.get('lat'))
region_name = find_district(lon, lat)
if region_name:
region_id = region_dict[region_name]
else:
region_id = None
response_data = {'region': region_name, "region_id": region_id}
response_json = json.dumps(response_data, ensure_ascii=False)
return Response(response=response_json, status=200, mimetype='application/json')
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=3030)보다시피 shp 파일을 읽어 메모리에 적재하고 이를 기반으로 해당 좌표가 포함되어 있는 시, 군, 구를 반환하는 간단한 코드이다.
문제
하지만 치명적인 단점이 있었으니... 바로 메모리 사용량이었다.
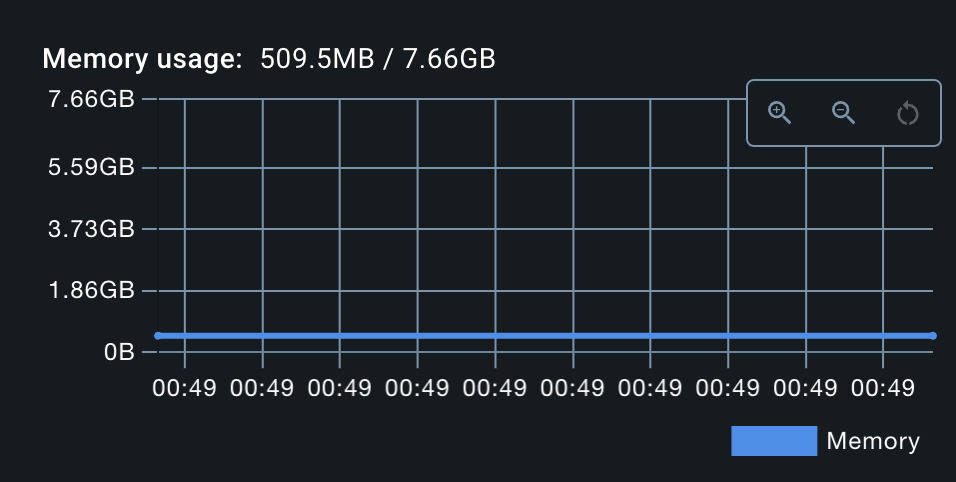
해당 코드를 도커 컨테이너로 실행시켜 보니 약 500MB를 차지했다.
현재 우리 팀이 사용하는 EC2 인스턴스는 팀 비용 등의 문제로 메모리를 1GB 이상 구축하기엔 무리가 있었다.
따라서 어떻게든 메모리 사용량 절감을 해야했다.
분석
1. 정말 메모리를 많이 차지하는 것이 맞을까?
현재 나는 Java, Spring Boot를 기반으로 개발을 약 1년 반동안 해왔다.
Hello World 예제 코드만 작성하고 Spring Boot를 실행시켰을 때, 메모리를 300~400MB 차지하는 것은 익숙한 그림이었다.
따라서 나는
Flask도 기본적으로 차지하는 메모리 용량이 큰 게 아닐까?
라고 생각했다.
바로 Flask의 Hello World 예제를 작성하고 메모리 사용량을 측정했다.
app = Flask(__name__)
# 메모리 사용량을 3초마다 출력하는 함수
def log_memory_usage():
process = psutil.Process(os.getpid())
while True:
memory_usage = process.memory_info().rss / 1024 ** 2 # MB 단위
print(f"Memory usage: {memory_usage:.2f} MB")
time.sleep(3)
# 메모리 로그 쓰레드 시작
memory_thread = threading.Thread(target=log_memory_usage, daemon=True)
memory_thread.start()
@app.route("/")
def hello_world():
return "Hello, World!"
if __name__ == "__main__":
app.run()결과
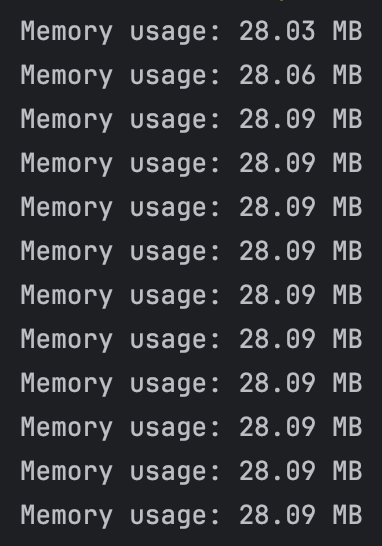
내 생각과는 다르게, Flask의 예제 코드는 매우 적은 메모리를 차지했다.
그렇다면 결국 메모리를 크게 잡아먹는 무언가가 존재한다는 것을 의미했다.
2. shape 파일이 원인이다!
위에 적힌 코드를 보면, Flask에서 메모리에 적재되는 것은 shp 파일을 읽은 GeoDataFrame 밖에 없었다.
하지만 shp 파일의 용량을 확인해봤지만 모두 합해도, 100MB를 넘지 않았다.
물론 파일의 실제 용량이 메모리에 적재될 때의 크기를 정확히 반영하진 않겠지만 어쨋든 의구심이 들었다.
하지만 더 이상 의심가는 요소는 없었기에 shape 파일을 개선하여 해결해보기로 했다.
해결
shapefile은 GIS 애플리케이션에서 사용할 벡터 데이터 형태(점/선/폴리곤)의 공간지리정보를 담기 위해 사용된다.
또한 벡터 정보 뿐만 아니라 추가적인 정보를 함께 저장할 수 있다.
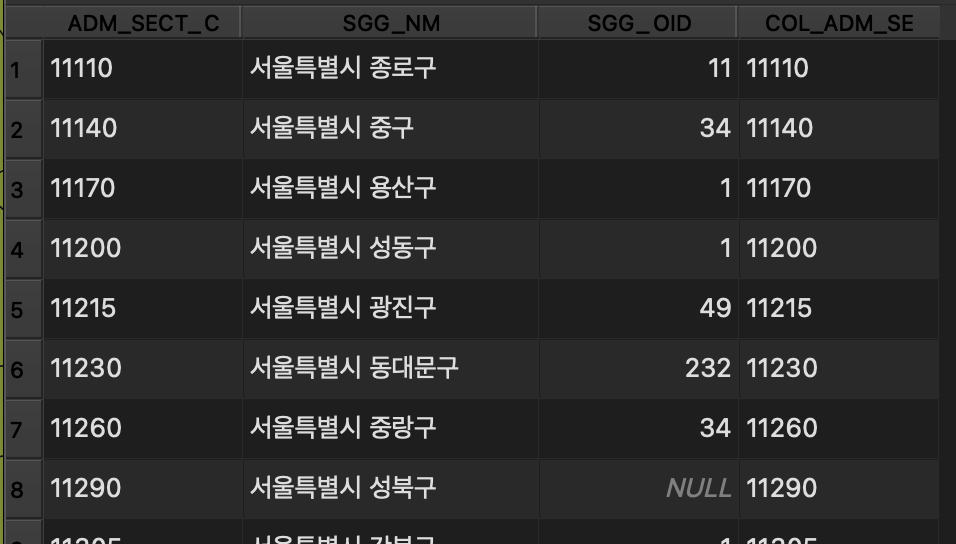
우리가 사용 중인 .shp 파일은 위와 같이 시/군/구의 이름을 포함하고 있다.
그렇다면, 어떻게 생겼는지 확인해보자.
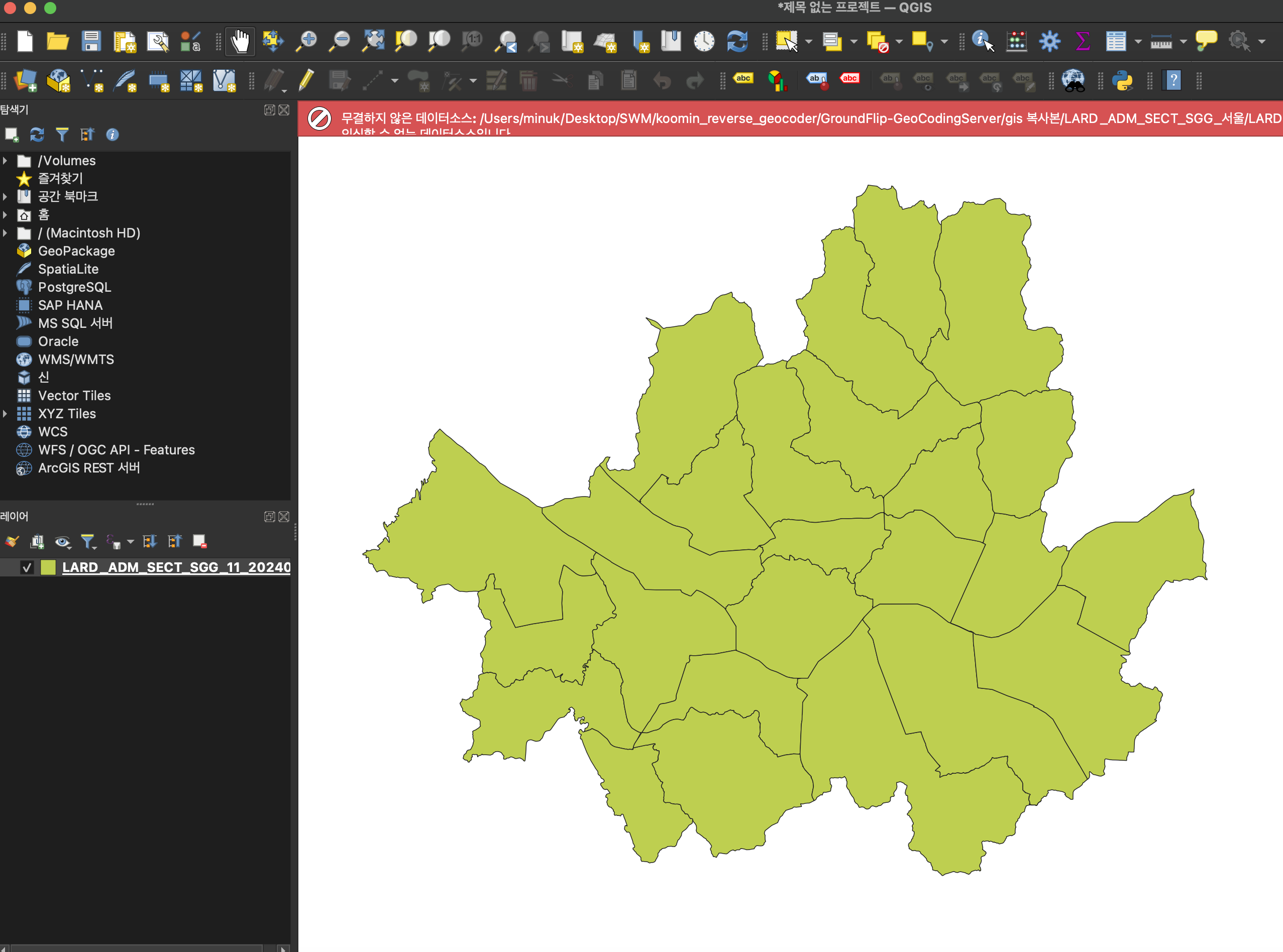
우선 QGIS라는 툴을 활용하여 서울특별시의 .shp 파일을 열어보았다. 우리가 아는 서울특별시의 궤적이 아주 자세히 나타나있다.
그렇다면 .shp 파일은 어떤 방식으로 자세하게 지역의 경계선을 표현할 수 있을까?
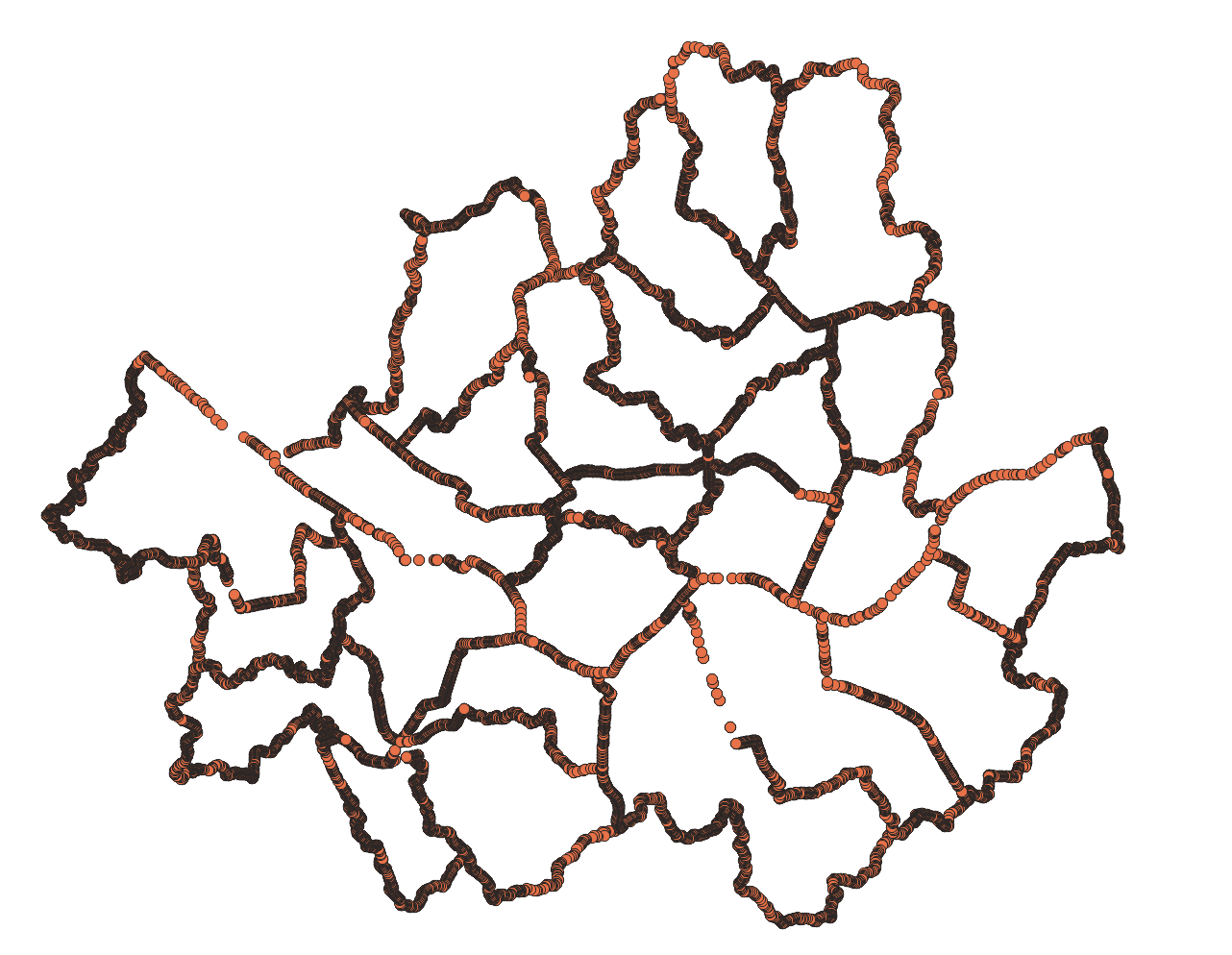
QGIS에서 벡터-지오메트리 도구-꼭짓점 추출로 확인해보면, .shp 파일은 사진과 같이 35040개의 점들로 이뤄져있는 것을 볼 수 있다.
하지만... 이렇게까지 높은 정밀도가 필요할까?
우리 앱은 약 80m 간격의 좌표를 기준으로 한다. 따라서 대략 50m의 오차까지는 허용이 가능하다.
그렇다면 이 정도의 오차를 허용하도록 .shp 파일을 압축, 혹은 비슷한 무언가를 할 순 없을까?
단순화
단순화는 복잡한 다각형, 선형 데이터 등의 불필요한 좌표를 제거하거나 압축하여 데이터 포인트 수를 줄이는 방식이다.
이를 위해 두 가지 방법을 시도해보았다.
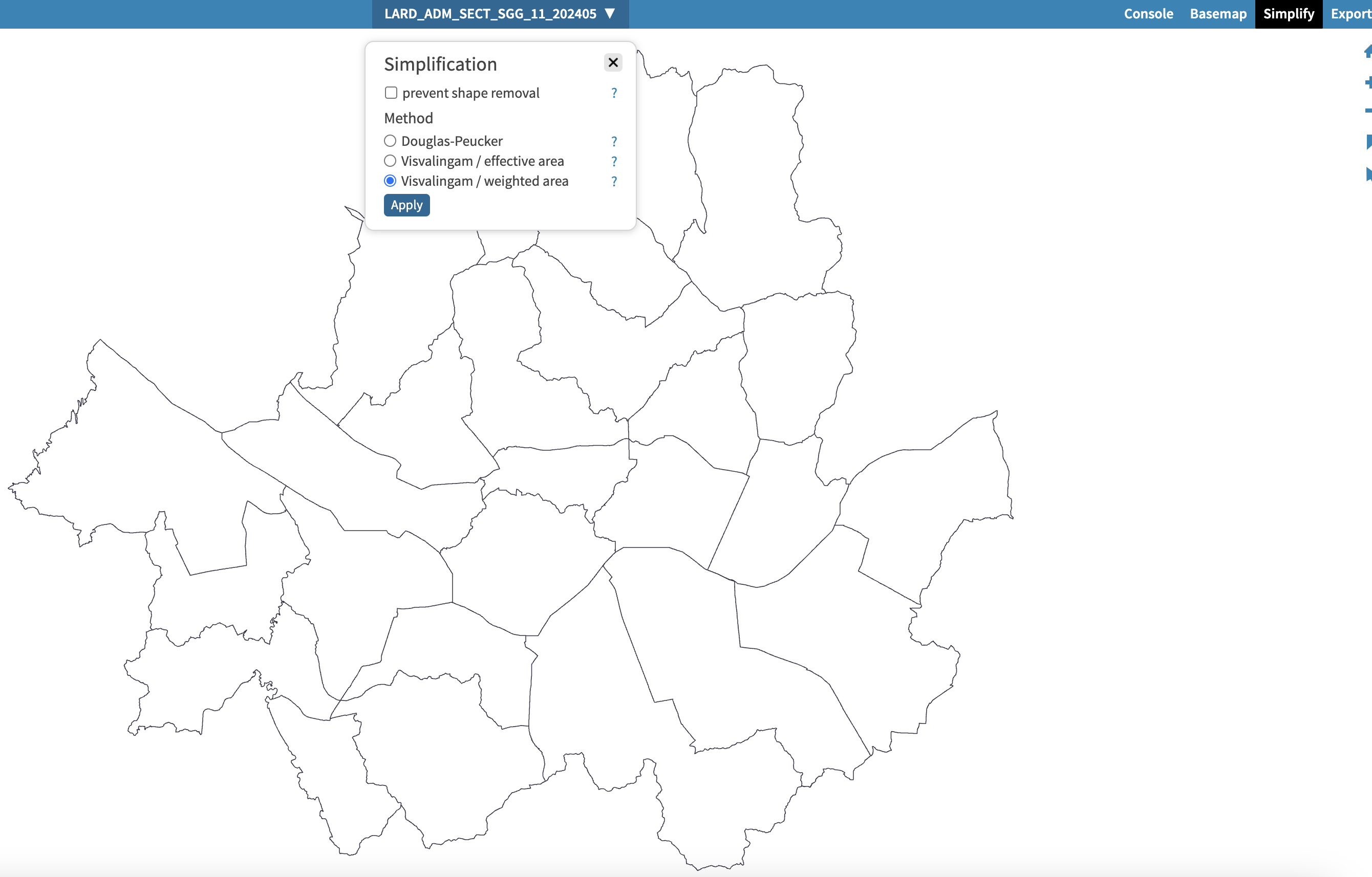
간편하게 파일을 drag & drop 방식으로 업로드하여 단순화 정도를 정할 수 있다.
하지만
- 여러 개의 파일을 한 번에 작업하기 어려움
- 단순화 후에 .shp 파일 내에 일부 attribute들이 손실됨
등의 이유로 활용하지 못했다.
2. geopandas
최종적으로 선택했던 방법이다.
디렉토리를 순회하며 한 번에 여러 파일들을 압축할 수 있었으며, 인코딩 옵션만 잘 지정해주면 한글이 깨지거나 attribute들이 손실되는 일도 발생하지 않았다.
import os
import geopandas as gpd
shapefile_directory = "gis"
for folder_name in os.listdir(shapefile_directory):
folder_path = os.path.join(shapefile_directory, folder_name)
if os.path.isdir(folder_path):
for file in os.listdir(folder_path):
if file.endswith(".shp"):
filepath = os.path.join(folder_path, file)
gdf = gpd.read_file(filepath, encoding="cp949")
tolerance = 50
gdf["geometry"] = gdf["geometry"].simplify(tolerance, preserve_topology=True)
gdf.to_file(filepath, encoding="cp949")주의사항
해당 코드에서 tolerance는 변수 이름이 나타내듯 오차의 허용 정도를 의미한다.
하지만 이 오차 허용 단위가 .shp 파일의 좌표계의 따라 상이했다.
-
WGS84(우리가 아는 일반적인 위경도 좌표계)의 경우
단위는 1당 1도를 의미한다. -
투영좌표계의 경우
단위는 1당 1m를 의미한다.
그렇다면, 우리의 사용하는 .shp 파일은 어떤 좌표계를 쓰고 있을까?
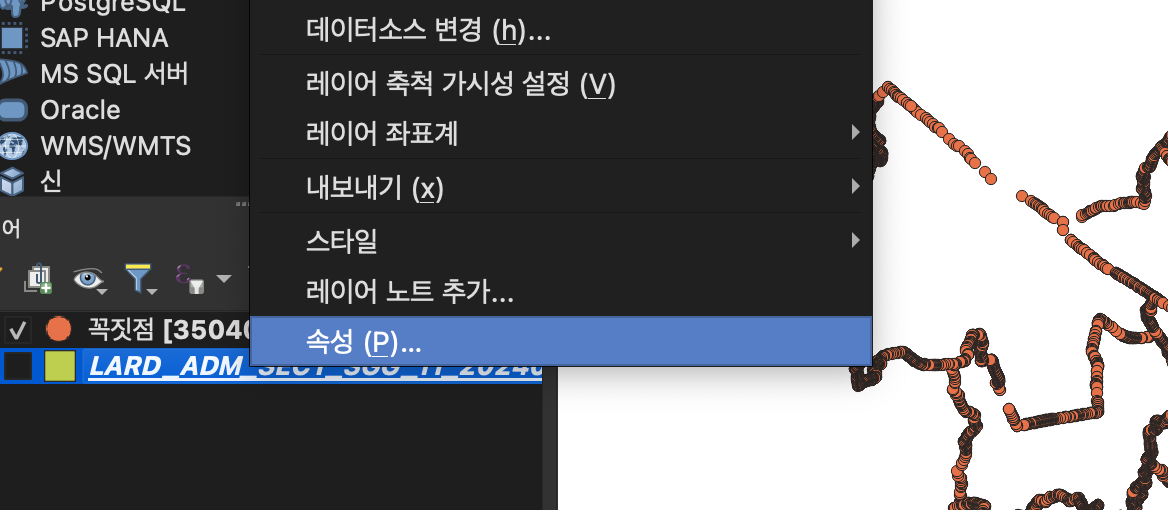

QGIS에서 속성을 통해 확인해보면, 투영좌표계인 것을 확인할 수 있다.
그렇다면 실행 후 결과는?
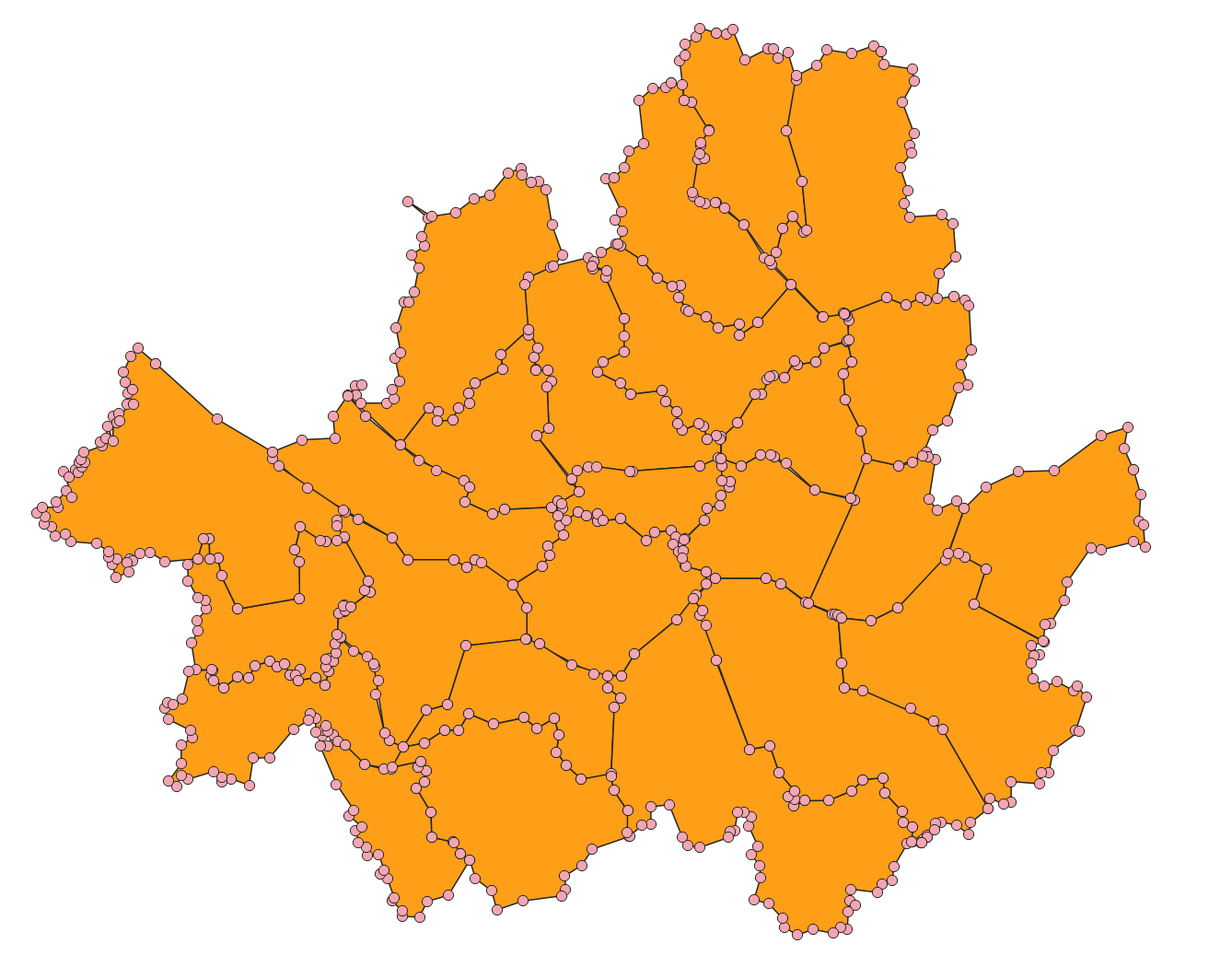
꼭짓점을 966개로 크게 감소시켰지만 기본적인 서울특별시의 경계 모양은 유지하는 것을 볼 수 있다.
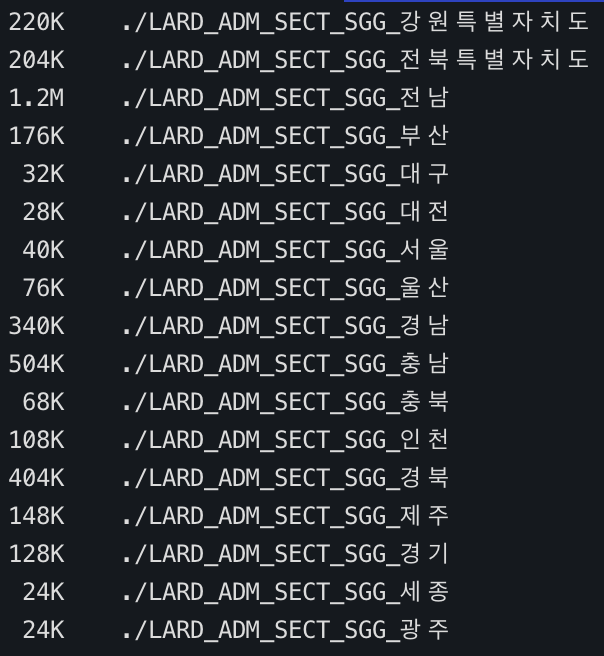
또한 .shp 파일들의 크기를 전부 합쳐도 10MB를 넘지 않는다.

메모리 사용량 또한 130MB로 기존에 비해 약 74% 감소시켰다.
결론
기존의 shapefile의 정밀도를 어느정도 포기했지만 메모리 측면에서 큰 이득을 볼 수 있었다.
.shp나 QGIS 파일같은 순수 GIS 데이터와 툴은 다뤄본 적이 없었지만, 여러 레퍼런스들을 통해 문제를 해결할 수 있었다.
부록
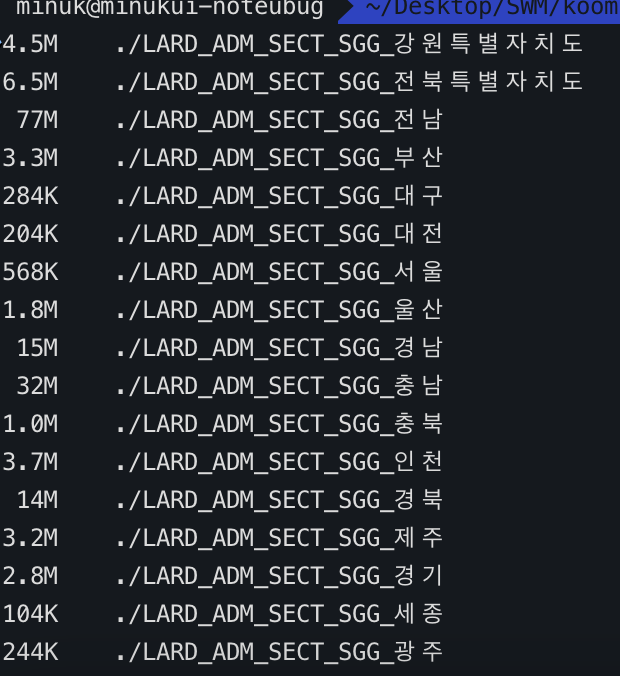
파일 용량이 무려 77MB나 됐던 전남의 사진이다.
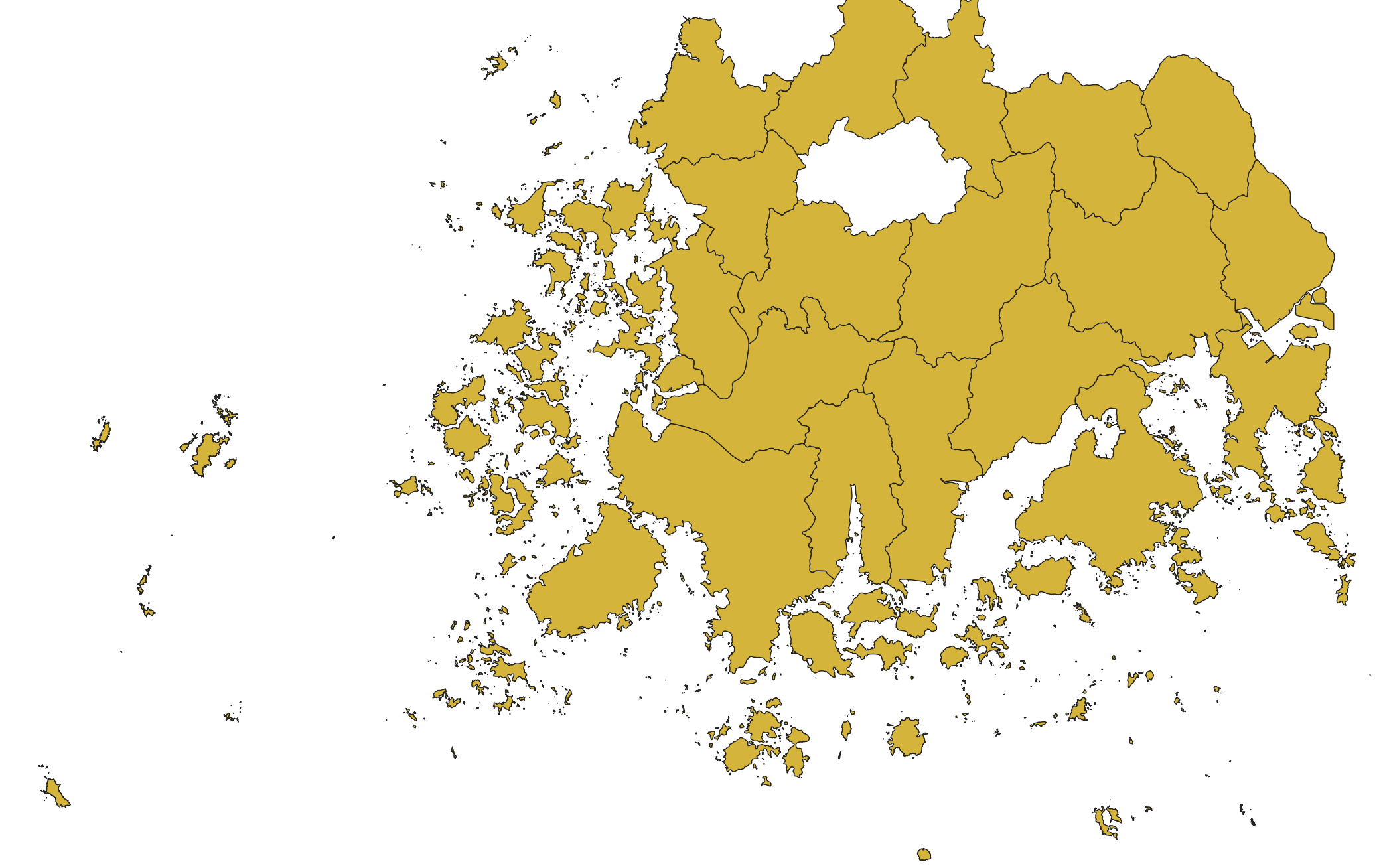
복잡한 해안선과 수많은 섬들로 인해 특히 용량이 더 컸던 것 같다!
레퍼런스
https://velog.io/@ys__us/.shp-%ED%99%95%EC%9E%A5%EC%9E%90-%EB%9C%AF%EC%96%B4%EB%B3%B4%EA%B8%B0
https://iron-jin.tistory.com/entry/QGIS-%EB%8B%A8%ED%8E%B8%ED%99%94-%EC%9E%91%EC%97%85

고양이 사진에 끌려서 들어왔다가 좋은 글 보고 갑니다! ㅋㅋㅋㅋ
요구사항에 비해 과도한 리소스가 사용되는 경우가 생각보다 많은 것 같더라구요
최적화까지 신경쓰시는 모습 멋있습니다!