1. What is Image Captioning
Image Captioning is the process of generating textual description of an image. It uses both Natural Language Processing and Computer Vision to generate the captions.

이번 프로젝트를 하면서 궁금한 것:
- Image Captioning 으로 얻어진 결과에서 단어들 끼리의 우선순위가 있나
ㅇㅇ 있다.
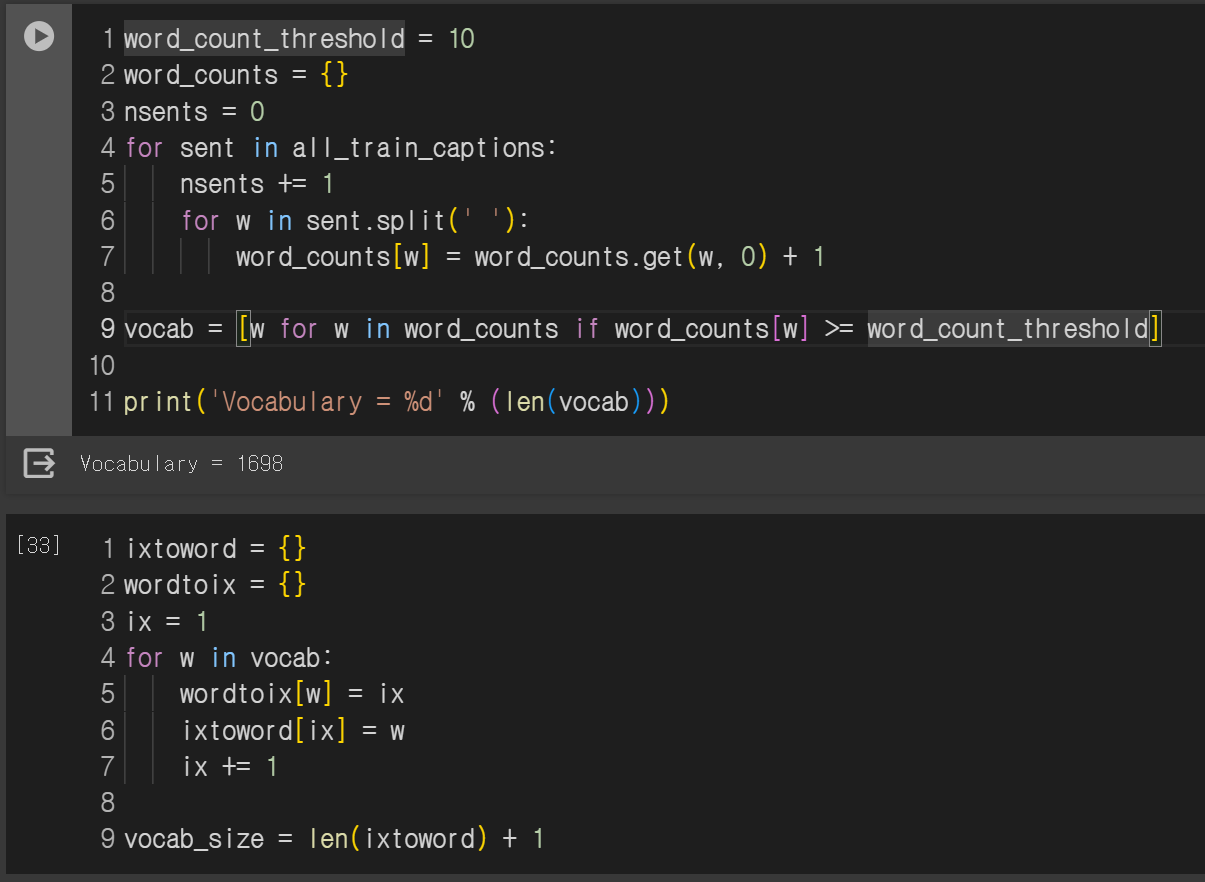
중요 단어 빈도 체크 한다!
2. Data Settings
glove6b : Embedding files from Kaggle
flicker8k : Images and text data from kaggle
우선 glove 임베딩 파일들을 이용하여 Flickr8k의 임베딩을 만들어야 한다.

이런 식으로 이미지와 이미지에 대한 설명이 같이 있는것을 볼 수 있음.
한 이미지는 여러 word(description) 을 가짐. -> 여기서는 5가지 Text 종류
따라서 두가지의 모델을 학습 시킨 후 이 두 모델이 이미지에서 같이 작동 할 수 있도록 결합 해야함.
1. 이미지를 읽는 모델 학습
2. 텍스트를 읽는 모델 학습
3. Libraries
import numpy as np
from numpy import array
import matplotlib.pyplot as plt
%matplotlib inline
import string
import os
import glob
from PIL import Image
from time import time
from keras import Input, layers
from keras import optimizers
from keras.optimizers import Adam
from keras.preprocessing import sequence
from keras.preprocessing import image
from keras.preprocessing.text import Tokenizer
#from keras_preprocessing.sequence import pad_sequences
from tensorflow.keras.preprocessing.sequence import pad_sequences
from keras.layers import LSTM, Embedding, Dense, Activation, Flatten, Reshape, Dropout
from keras.layers import Bidirectional
from keras.layers import add
from keras.applications.inception_v3 import InceptionV3
from keras.applications.inception_v3 import preprocess_input
from keras.models import Model
from keras.utils import to_categorical
- from keras.applications.inception_v3 import InceptionV3
: To read images and for embedding. InceptionV3에서는 주로 3차원의 배열로 표현돈 이미지를 받고, 숫자로 표현되며 각 픽셀은 색상 값으로 나타짐. 이미지를 고차원 특징 벡터로 변환하는 역할.- from keras.applications.inception_v3 import preprocess_input
: InnceptionV3 모델에 이미지를 입력하기 전에 전처리 수행. preprocess_input 사용하면 아래의 전처리과정 (ImageNet 전처리 방식: 이미지 크기 조정 -> 채널 정규화 -> 축 변) 자동 수행.- from keras.utils import to_categorical
: 다중 클래스 레이블을 원-핫 인코딩으로 변환하기 위한 함수
3-1. Why "to_categorical"?
inceptionV3 모델을 사용할 때 모델의 출력 레이어에서 클래스 인덱스를 얻게 되고, 이를 to_categorical 함수를 사용하여 원-핫 인코딩된 형태로 변환함으로써 모델을 훈련하고 평가하는 과정을 원활하게 할수 있다.
(무슨말이지 ???_??? 왜 "원-핫 인코딩된 형태로 변환"이 꼭 필요할까 )
예를 들어
- 클래스 개수3개 (고양이, 개, 새)
- 모델 출력 형태: 3개의 뉴런으로 이루어진 출력 레이어, 각 뉴런은 각 클래스에 대한 확률 출력
먼저 모델이 이미지를 처리하고 예측을 내놓았다고 가정하자, 이때 출력레이어는 [0.2,0.7,0.1] 이라고 하면, 이 뜻은 이 모델이 해당 이미지가 고양이 일 확률 0.2 개 일 확률 0.7 새 일확률 0.1 이라고 예측한 것 일 것이다.
이제 이 예측 값들을 가지고 클래스 인덱스를 얻어야 하는데, 가장 높은 확률을 가진 클래스의 인덱스를 선택한다. 이 이경우 개(0.7)로 클래스 인덱스는 1이다.
predicted_index = 1 이제 to_categorical 함수를 사용해서 클래스 인덱스를 원-핫 인코딩된 형태로 변환 해야한다.
from keras.utils import to_categorical
# 클래스 개수
num_classes = 3
# 모델의 예측된 클래스 인덱스
predicted_index = 1
# 클래스 인덱스를 원-핫 인코딩으로 변환
one_hot_encoded = to_categorical(predicted_index, num_classes=num_classes)
결과적으로 [0,1,0] 의 해당 클래스의 개수만큼의 길이를 가진 one_hot_encoded 벡터를 생성할 수 있었다. 여기서 중요한 점은 to_categorical 함수는 클래스의 인덱스를 알고 있어야 올바른 변환을 수행할 수 있다는 것이다.
3-2. One_Hot_Encoding 장점
기본적으로, 다중 클래스 분류 문제에서 모델의 출력을 쉽게 해석하고 효과적으로 훈련시키기 위해 원-핫 인코딩이 사용된다.
-
모델의 출력 해석이 용이: 원-핫 인코딩은 각 클래스에 해당하는 요소가 0 또는 1인 벡터로 표현됨. 이는 모델이 어떤 클래스를 예측했는지 더욱 명확하게 해준다. 만약 세 개의 클래스가 있다면, [0, 1, 0]은 두 번째 클래스를 의미한다.
-
손실 함수의 요구사항을 충족: 다중 클래스 분류의 경우, 주로 크로스 엔트로피와 같은 손실 함수를 사용하는데 이 손실 함수는 정답 레이블이 원-핫 인코딩된 형태여야한다.
-
클래스 간의 상대적인 중요도 표현 가능: 각 클래스가 독립적으로 존재하며 모든 클래스는 서로 독립적으로 다른 클래스와 비교된다. 이는 모델이 각 클래스 간의 상대적인 중요도를 학습할 수 있도록 해준다.
-
클래스 불균형 해결 용이: 원-핫 인코딩은 클래스가 불균형하게 분포되어 있을 때도 유용한다.모델이 한 클래스에 치우치지 않도록 도와준다.
이 장점들은 NLP에서 원-핫 인코딩이 부적절하다고 언급되는 이유이기도 하다.
그래서 NLP 에서는 Word Embedding같은 방법을 써야함.
- Word Embedding은 단어를 고차원 벡터로 표현하는 방법 중 하나로, 단어 간의 의미적 유사성을 보존하면서 효과적으로 차원을 줄이는 기술 (Word2Vec,Glove..)
