
MNIST Data Load
from keras.dataset import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
import matplotlib.pyplot as plt
x_train.shape
# (60000, 28, 28)
One Hot Encoding : Label 카테고리화
###### One Hot Encoding 적용 전
y_train
# 결과 : array([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
y_test
# 결과 : array([7, 2, 1, ..., 4, 5, 6], dtype=uint8)
y_train.shape
# 결과 : (60000,)
###### One Hot Encoding 적용 (category 화)
from keras.utils.np_utils import to_categorical
y_cat_test = to_categorical(y_test,10)
y_cat_train = to_categorical(y_train,10)
###### One Hot Encoding 적용 후
y_cat_test
# 결과
array([[0., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 1., 0.]], dtype=float32)
y_cat_test.shape
# 결과 (60000, 10)
y_cat_test[0]
# 결과 : array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)One Hot Encoding 사용하는 이유
단어 집합내의 각 단어들을 고유한 벡터로 표현하는 것
해당 단어의 인덱스에만 1이 있고, 나머지 위치에는 0 이 존재
y_cat_test = to_categorical(y_test,10)y_test를 카테고리화 시키는데 10개의 카테고리로 분류하겠다는 의미
단어 집합
중복을 제거한 텍스트의 총 단어의 집합
자연어를 처리할 때, 컴퓨터가 이해할수 있도록 단어를 벡터화 시켜서 처리를 진행한다.
원본 문장
["나는 학생입니다", "학생은 공부를 합니다"]
문장을 토큰화(단어화)
['나는', '학생입니다', '학생은', '공부를', '합니다']
단어를 벡터로 표현
{'나는': 1, '학생입니다': 2, '학생은': 3, '공부를': 4, '합니다': 5}단어화 시킨 결과
- "나는" -> [1, 0, 0, 0, 0]
- "학생입니다" -> [0, 1, 0, 0, 0]
- "학생은" -> [0, 0, 1, 0, 0]
- "공부를" -> [0, 0, 0, 1, 0]
- "합니다" -> [0, 0, 0, 0, 1]
단어를 벡터로 표기하는 이유
모델에 입력 가능: 머신 러닝 모델은 숫자 데이터 입력을 기대합니다. 텍스트 데이터를 벡터로 변환하면 모델이 이를 처리할 수 있습니다.수치 연산 가능: 벡터화된 텍스트 데이터는 수학적 연산이 가능해집니다. 이를 통해 유사도 측정, 군집화, 분류 등의 다양한 분석을 수행할 수 있습니다.단어 간 관계 표현: 복잡한 의미와 문맥을 벡터 공간에서 표현할 수 있습니다. 단어 벡터가 의미적으로 가까운 단어끼리 가까운 벡터를 가지도록 학습할 수 있습니다.효율적인 저장: 잘 설계된 벡터 표현은 텍스트 데이터를 메모리 효율적으로 저장하고 사용할 수 있게 합니다.
데이터셋 Shape 변경
##### 기존 Shape
x_train.shape
x_test.shape
# 결과(train 데이터) : (60000, 28, 28)
x_test = x_test.reshape(10000,28,28,1)
x_test = x_test.reshape(10000,28,28,1)
##### 변경후 Shape
x_train.shape
x_test.shape
# 결과(train 데이터) : (60000, 28, 28, 1)모델에 학습하기 위한 Shape
(갯수, Height, Width, Color)
- GrayScale 이미지는 마지막 Color가 1을 가지도록 변경
- 컬러 이미지는 마지막 Color가 3을 가지도록 변경
모델 학습
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPool2D, Flatten
###### 모델 생성
model = Sequential()
##### Convolution 레이어 생성
model.add(Conv2D(filters=32, kernel_size=(4,4),input_shape=(28, 28, 1), activation='relu',))
##### Pooling 레이어 생성
model.add(MaxPool2D(pool_size=(2, 2)))
##### Flatten 레이어 생성
model.add(Flatten())
##### Dense 레이어
model.add(Dense(128, activation='relu'))
##### Dense 출력 레이어
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',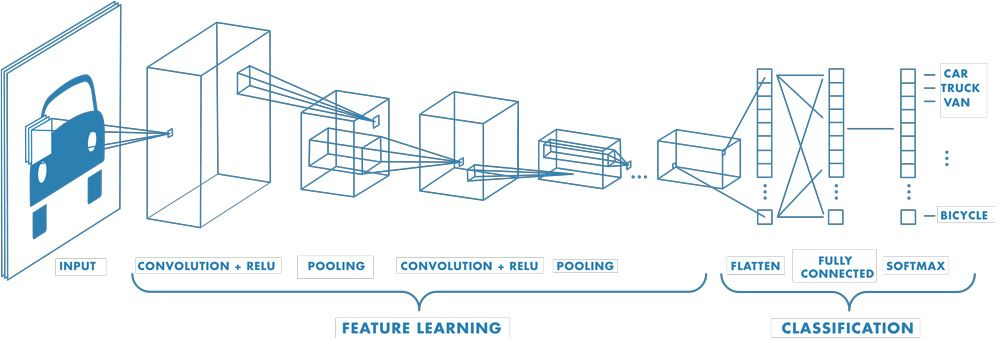
Convolution 레이어
CNN에 사용되는 Convolution연산을 진행하는 레이어
Convolution 레이어는 Convolution연산 + 활성화 함수 연산 수행
Conv2D(filters=32, kernel_size=(4,4),input_shape=(28, 28, 1), activation='relu', stride=1, padding='same')- filter : 필터의 갯수, 필터의 수만큼 Feature Map 생성됨, (Height, Width, 필터수) 형태
- 출력 : (Height, Width, 필터수)
- Height와 Width는 커널 사이즈와, padding, Stride에 의해 설정됨
- 출력 : (Height, Width, 필터수)
- kernel_size : 합성곱 연산을 진행할 커널의 크기
- input_shape : Input Shape, 입력과 출력의 사이즈는 Convolution 레이어와, Pooling 레이어에 의해서 변경됨을 주의
- activation : 활성화 함수 지정
- stride : 커널을 이동시킬 픽셀 크기
- padding : 이미지 외부에 0을 채울 padding의 크기
'valid': 패딩을 추가하지 않습니다. 출력 크기는 입력 크기보다 작아질 수 있습니다.'same': 출력 크기가 입력 크기와 동일해지도록 패딩을 추가합니다.
Pooling 레이어
의도적으로 Feature Map의 크기를 줄이는 레이어
계산 비용을 줄이고, 과적합을 방지해 모델의 성능을 높일 수 있다.
최대 풀링, 평균 풀링과 같은 기법이 존재한다.
keras.layers.MaxPool2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)- pool_size : 픽셀을 합칠 사이즈를 결정, (2,2) 라면 2*2 4개의 픽셀을 하나의 픽셀로
- stride, padding : Convolution레이어와 동일
Flatten 레이어
3차원 데이터를 하나의 1차원 배열(벡터)로 바꾸는 과정 (Vectorization)
Convolution과 Pooling을 진행하며 이미 이미지의 특성만 추출하였기 때문에, 1차원 배열(벡터)로 바꿔서 학습을 진행해도 무관
Flatten()Dense 레이어
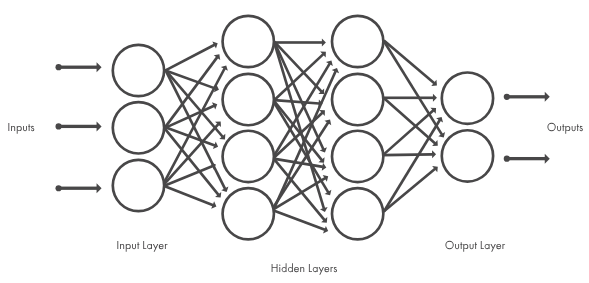
딥러닝 하면 가장 먼저 떠오르는 이미지, 위 작업을 진행하는 레이어
- 이미지를 Conv, Pooling 과정을 여러번 거치면서 특징을 추출하고, 추출된 특징을 Flatten레이어를 통해 벡터화 시켜 Dense레이어에 Input으로 전달
- 이때까지 배웠던 Activation Function, Gradient Descent, Backpropagation등의 기술을 활용, 모델을 학습
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))출력층의 Activation Function을 SoftMax로 사용하는 이유
- 분류해야할 대상이 여러개인 경우, SoftMax가 적합
softmax는 각 클래스에 대한 예측 확률을 제공, 출력들의 총합이 1이 되는 확률 분포를 만듬

qkdk