
반복을 사용한 요소 처리의 번거로움
개발을 하다보면 다수의 요소가 포함된 자료구조를 다루게 될 경우가 상당히 많다.
그런 경우에 이전 개발방식으로는 반복문(for or while문)이나 향상된 반복문(for-each)를 사용해 배열형 자료구조에 대한 처리를 하게 된다.
그런데 이 방식은 요소 수가 늘어나고 로직이 복잡해질수록 코드가 제어 흐름(인덱스 증가, if, add 등)에 묻혀 읽기 어려워지고, 병렬화도 번거롭다.
list = generateTestData(200_000);
// Act
List<String> result1 = new ArrayList<>();
for (String s : list) {
if (s.length() > 3) { //연산당 indent 증가
String upper = s.toUpperCase();
result1.add(upper);// 결과 수집을 위해 별도의 자료구조 사용, 결과 수집이 로직에 침투
}
}위 예시를 보면
- 분기나 반복을 할때마다 code의 indent가 증가한다
- 결과 수집을 위해 별도 자료구조를 선언후 적재
에 대한 문제가 보인다.
뿐만 아니라 병렬처리를 하려 할때가 상당히 번거롭다.
try (ExecutorService pool = Executors.newFixedThreadPool(parallelism)) {
List<Callable<Optional<String>>> tasks = new ArrayList<>(list.size());
for (String n : list) {
tasks.add(() -> {
if (n.length() > 3) {
return Optional.of(n.toUpperCase());
}
return Optional.empty();
});
}
List<Future<Optional<String>>> futures = pool.invokeAll(tasks);
List<String> out = new ArrayList<>();
for (Future<Optional<String>> f : futures) {
f.get().ifPresent(out::add);
}
return out;
}분명 이전 코드와 로직상 동일하게 동작할테지만 병렬처리에 사용할 자원 할당부터 작업 정의, 실행 시점 직접 명시까지 신경써야할 부분이 많다.
그리고 개인적인 의견으론 가장 큰 문제가 있는데, 바로 함수형 코드로 문제를 해결할 수가 없다. 요즘 사용하는 대다수의 프레임워크들은 함수형 개발에 다양한 방면으로 지원하는 경우가 많거나, 지원하지 않더라도 함수형으로 개발하다보면 나름의 코드 간결성(?)이 보이는 경우가 많아 선언적으로 처리하는 반복문이 불편한 경우가 많다.
Stream API
함수형 프로그래밍이라는 패러다임이 대두대면서 여러 프로그래밍 언어들에 도입된 개념이다. 기존의 스크립트 방식으로 반복된 작업을 해결하는 방식이 아닌 하나의 흐름을 함수로 제어하여 원하는 결과를 도출한다. 이과정에서 자바는 함수를 객체로 전달받기에 기존의 패러다임과 다르게 반복적 작업을 재사용 할 수 있도록 설계가 가능해진다.
자바 진영에서는 8버전부터 Stream API가 공식 스펙으로 추가되었다.
그리고 여느 Stream API와 마찬가지로 크게 세가지 스텝으로 나누어 스트림을 작업한다.
1. Source 생성
컬랙션을 하나의 흐름으로 만들기 위해 Stream 객체로 변환하는 과정이 필요하다.
배열, 컬랙션, 심지어 문자열까지 stream으로 변환하도록 지원해주고 있다.
List<String> list = List.of("a", "bb", "cccc");
Stream<String> s1 = list.stream();// 컬렉션
IntStream s2 = Arrays.stream(new int[]{1,2,3});// 배열
Stream<String> s3 = Stream.of("x","y","z");// 상수
String s = "1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ".chars();// 문자열
 Collection에서는 기본적으로 지원한다.
Collection에서는 기본적으로 지원한다.
이 과정에서 생성된 스트림은 즉각적인 연산이 아닌 데이터를 가져올 준비를 하게 된다. 다만, 컬렉션 원본의 훼손 없이 컬렉션의 흐름을 생성한다.
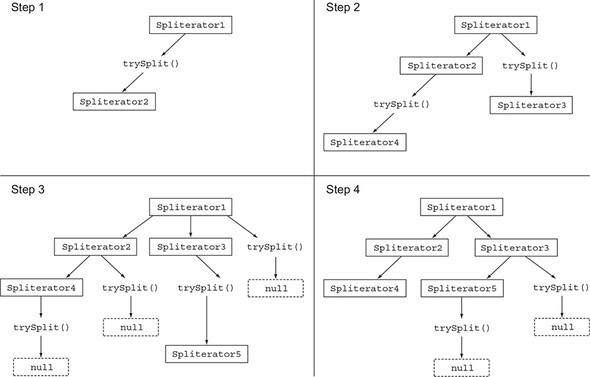
Stream의 내부 구현을 보면 Spliterator를 사용해 요소들을 나눠준다. Spliterator는 병렬 연산을 하기 위해 후에 최종 연산때 재귀적으로 작업을 분기해 처리한다.(세포분열과 같은 형상을 띈다.)
단순 반복 연산일때는 사실 for-each 처리보다 비효율적으로 보이지만 병렬 처리를 했을때 이러한 작업방식이 다수 요소 처리를 할때 유리하게 작용한다.
하지만 여기서 생각해야 할 것은 Stream의 요소들을 등록하기만 했기 때문에 분기 과정의 복잡한 작업이 지금 단계에서는 이루어지지 않는다. 그렇기에 이 단계에서는 연산의 비용이 크지 않다.
2. Intermediate 연산
중개 연산 단계이다. 처리할 작업을 수행할 수 있도록 명시하는 단계다. 여러가지 작업을 순차적으로 실행할 수 있도록 chaining method와 함수형 매개변수로 작업을 전달받는다. 하지만 이전 source 단계와 마찬가지로 직접적인 연산이 이루어지지는 않는다. 지연 연산을 위해 실행 계획을 정의해두는 단계다.
Stream<String> s = list.stream()
.filter(n -> n.length() > 3)
.map(String::toUpperCase);여기서 주의해야할 점은 각각의 요소들이 위와 같은 코드의 흐름에 따라 처리가 될것이라는 점이다.
이말인 즉슨, 위와 아래의 처리가 다르단 것이다.
Stream<String> s = list.stream()
.map(String::toUpperCase)
.filter(n -> n.length() > 3);예를들어 list의 요소가 100만개가 있다고 해보자. 길이가 3보다 긴 문자열이 딱 하나밖에 없다면? 아래 코드의 경우에는 100만개의 문자열을 대문자로 변경하고 나서 3보다 긴 문자열을 처리하도록 최종 연산자가 처리해줄 것이다. 그렇기에 불필요하게 대문자로 변경하는 처리를 많이 하게 될것이다. 하지만 위의 코드의 경우에는 이미 각 요소들의 길이를 검증하는 과정에서 하나의 문자열을 제외하고는 배제되기 때문에 상대적으로 메모리 소모가 많은 toUpperCase를 최소한으로 호출하게 된다.
| Method | 설명 | 예시 |
|---|---|---|
| filter | 결과가 true인 대상을 다음 stream에 넘김 | stream.filter(s -> s.size() > 2) |
| map | 각 요소를 변환 | stream.map(s -> s.toUpperCase()) |
| flatMap | 각 요소를 여러 요소로 변환 | stream.flatMap(c-> IntStream.of(c, c + 1)) |
| distinct | 중복 요소 제거 | stream.distinct() |
| sorted | 요소 정렬 | stream.sorted() |
| peek | 요소를 소비하지 않고 다른 작업 수행 | stream.peek(x -> System.out.println(x)) |
| limit | 스트림 크기 제한 | stream.limit(50) |
| skip | 처음 n개 요소 생략 | stream.skip(3) |
3. Terminal 연산
최종 연산이다. 만들어둔 흐름을 한번에 처리한다. 그렇기에 최종 연산이 진행되지 않은 Stream의 처리는 느리지 않다.
여기서 중요한건 최종 연산인 만큼 더이상 해당 Stream 객체를 사용할수가 없다는거다.
수집, 집계, 탐색, 소비등을 주로 지원하고 있다.
Spliterator가 한 청크씩 각자의 작업을 위에서 명시해준대로 처리한다. 이렇게되면 병렬 처리를 할때 각자가 작업을 처리하고 돌아오는데에 있어 간단한 부분이 있다.
| Method | 설명 | 예시 |
|---|---|---|
| forEach | 각 요소를 처리 | stream.forEach(System.out::println); |
| forEachOrdered | 각 요소를 순차적으로 처리 | stream.forEachOrdered(System.out::println); |
| findAny | 임의 요소 반환 | stream.findAny(); |
| findFirst | 처음으로 찾은 요소 반환 | stream.findFirst(); |
| anyMatch | 하나라도 해당하면 true | stream.anyMatch(n -> n > 3); |
| allMatch | 모두 해당하면 true | stream.allMatch(n -> n > 3); |
| nonMatch | 모두 해당하지 않으면 true | stream.noneMatch(n -> n > 3); |
| count | 해당하는 요소의 갯수 반환 | stream.count(); |
Stream API 성능 분석
그렇다면 반복적 연산을 처리해야 하는 상황에서 기존의 반복문과 Stream API의 속도는 어떤 차이를 보이며, Stream API를 어떻게 사용해야지 더 효율적으로 사용 가능할지 알아보자.
for vs stream
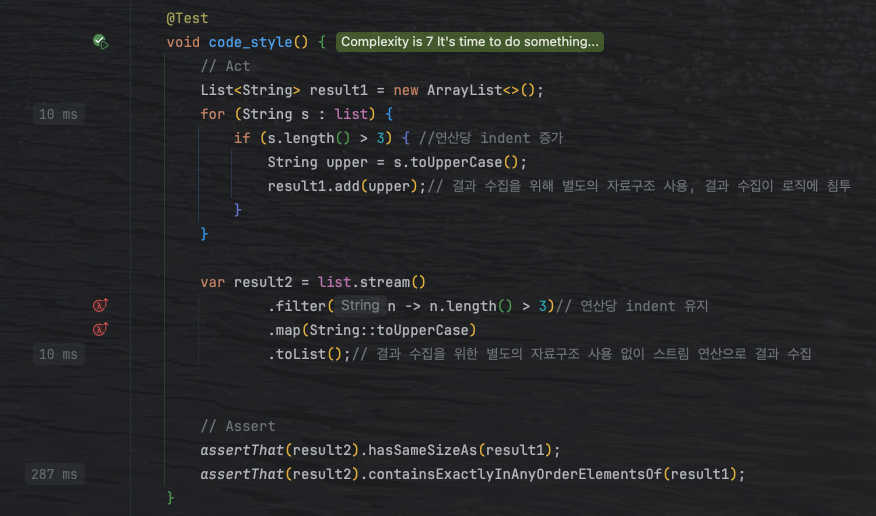
동일한 로직에 대해 성능을 비교해봤다. 문자열 컬랙션인 list를 기준으로 테스트를 진행했고, 문자열은 2~6사이 길이의 랜덤한 문자열이다. 총 20만개의 문자열로 동일한 로직에 대해 처리해본 결과 그리 큰 차이를 보이지 않는다.
stream 연산 순서
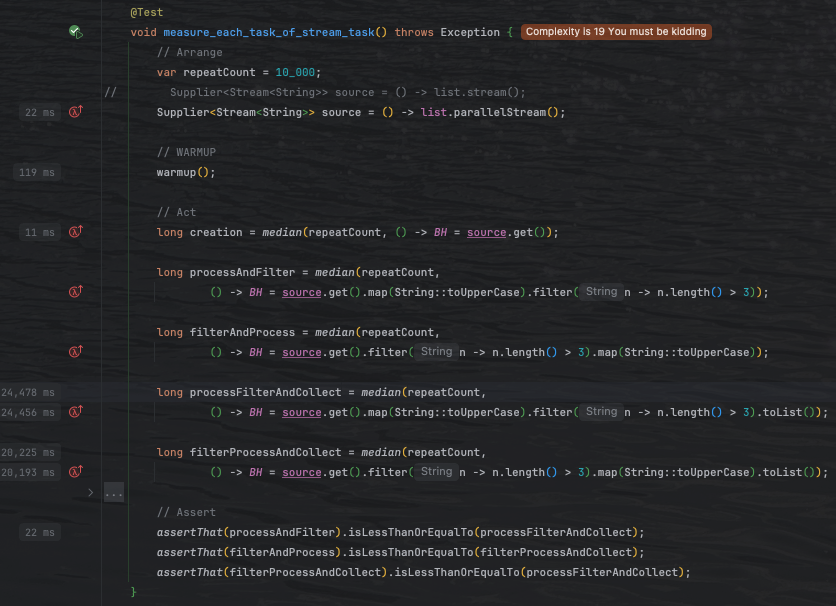
다음은 stream의 연산 단계와 순서에 따른 비용 측정 결과이다. median 메서드는 각 반복 연산의 총 비용 소요 시간을 계산해준다. 단순히 stream을 생성하는데에 소모되는 시간이 매우 짧게 이루어 지는 모습을 볼 수 있다. 최종연산을 진행하지 않았기 때문에 보여지는 모습이라고 생각된다. 하지만 이후의 processFilterAndCollect와 filterProcessAndCollect의 경우 연산도 한번에 진행하기 때문에 매우 많은 연산시간이 보인다. 다만, filter 이후 map을 처리하는 부분이 더 빠른것을 볼 수 있는데, 이는 먼저 가벼운 선별로 데이터량을 줄여 버려질 요소에 대한 불필요한 변환과 수집 버퍼 확장을 피하기 때문으로, 결국 호출 횟수, 할당량, GC 압력이 감소해 파이프라인 전체 비용이 줄어든다. 특히 필터 통과 비율이 낮을수록 이 차이는 더 크게 나타난다.
뿐만아니라,
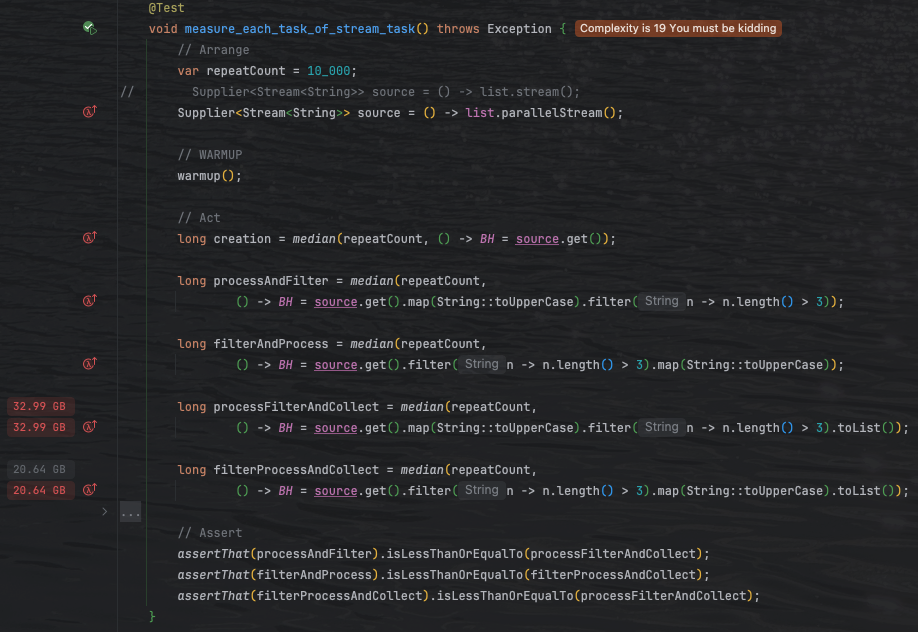
필터링 된 만큼 메모리 할당을 적게 하기 때문에 상당한 메모리 비용을 아낄 수 있다.
