오늘 배운 것🤓
RedShift에 사용하기 위한 sql을 배운 것이기 때문에 PostgreSQL 8.X 버전의 문법으로 정리한다.
JOIN
2개 이상의 테이블을 합치는 것을 Join 혹은 Merge 한다고 한다. 아래의 그램에서는 MySQL이라고 되어있지만 모든 SQL에는 아래와 같은 Join이 있다.
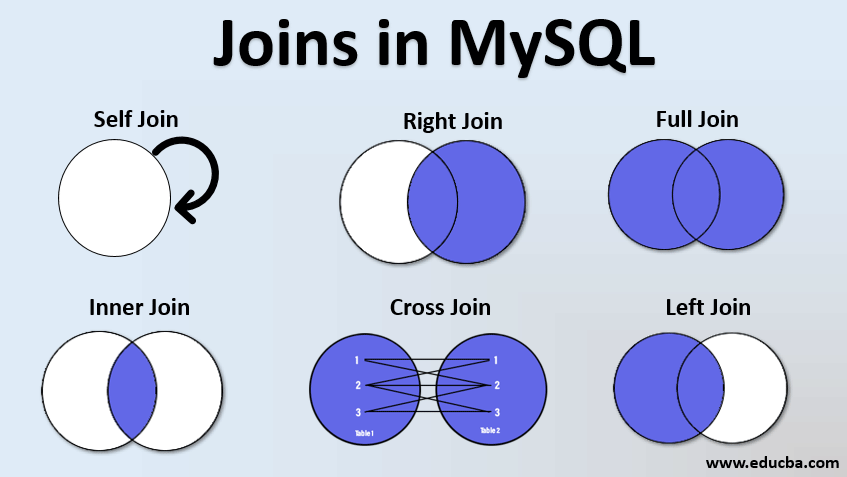
- 90% 이상은 INNER JOIN과 LEFT JOIN으로 해결이 가능하다.
- JOIN 연산 시 체크해야할 점
- 중복 레코드 X
- PK Uniqueness가 보장되는지 확인
- 조인하는 테이블 간의 관계 명확하게 정리
- One to One - 1:1 관계일 때
- One to Many
- Many to One - One to Many와 같다
- Many to Many - 거의 없는 케이스
NULL과 관련된 SQL 연산
- Null은 무조건 IS, IS NOT으로 비교해야 한다.
=, !=, <>으로 수행하면 잘못된 결과를 반환한다.
-- 올바른 경우
SELECT col1, col2 FROM table
WHERE col1 IS NULL
-- 잘못된 경우
SELECT col1, col2 FROM table
WHERE col1 = NULLBoolean은 IS, IS NOT 연산에서 주의해야 한다.
-- 1번 SELECT col1, col2 FROM table WHERE flag IS TRUE; -- 2번 SELECT col1, col2 FROM table WHERE flag = TRUE; -- 3번 SELECT col1, col2 FROM table WHERE flag IS NOT FALSE;1번과 2번 쿼리는 같은 결과를 반환하지만, 1번과 3번은 다른 결과를 반환한다.
Boolean을 타입으로 지정했지만 NULL값이 있을 수 있기 때문이다. NULL은 true도 false도 아니다.
-
NULLIF(field, value)
: field의 값이 value일 때 NULL로 변환한다. -
COALSCE(exp1, exp2, exp3, ...)
: NULL값을 다른 값으로 바꿔주는 함수(NULL 대신 다른 백업값을 리턴한다.)
exp1부터 차례대로 하나씩 살펴서 NULL이 아니면 그 값을 리턴한다.
끝까지 NULL이라면 NULL을 리턴
공백/예약 키워드를 field name으로 사용
" " 을 사용한다. (' ' 은 불가!)
공백/예약 키워드를 사용하여 table을 생성했다면 select를 할 때마다 똑같이 " "를 사용해야 한다.
SELECT
col1 AS "field name",
col2 AS "select"
FROM tableROW_NUMBER()
한 field로 group을 만들어서 또 다른 field를 기준으로 일련번호를 붙혀준다.
ROW_NUMBER() OVER (PARTITION BY field1 ORDER BY field2) seq
위와 동일한 방법으로 FIRST_VALUE, LAST_VALUE를 사용할 수 있다.
느낀 점😊
오늘은 갑작스러운 특강과 예정된 저녁 일정으로 많은 시간을 사용하지 못했다. 수업을 다 듣고 숙제를 풀어보려고 했으나 다양한 풀이가 나올 수 있을 것 같아서 이것저것 시도해보고 있다. 내일 수업에 들어가기 전에 머리속에 떠오른 다양한 풀이들을 모두 시도해봐야겠다.
