데브코스 TIL
1.[데이터 엔지니어링 데브코스] TIL 2일차 - 자료 구조 & 알고리즘 풀기(2)

연결 리스트(Linked List)선형 배열은 번호가 붙은 칸에 원소를 차례로 채워넣는 방식이라면, 연결 리스트는 각 원소들을 줄줄이 엮어서 관리하는 방식이다.선형 배열과 연결 리스트의 장단점 및 활용 방법연결 리스트는 단방향 연결과 양방향 연결이 있다.두 가지 연결
2.[데이터 엔지니어링 데브코스] TIL 3일차 - 자료 구조 & 알고리즘 풀기(3)

큐(Queue)큐는 자료를 보관할 수 있는 선형 구조이다.FIFO 선입선출 구조이다.환형 큐(Circular Queue)큐의 길이가 길어지면 복잡도가 증가하는 문제를 해결하기 위해 등장끝이 없이 원처럼 계속 돌고 있는 구조우선순위 큐(Primary Queue)큐가 FI
3.[데이터 엔지니어링 데브코스] TIL 4일차 - 자료 구조 & 알고리즘 풀기(3)
단일 연결 리스트 정리연결 리스트 정리 글 클릭!이진 탐색 트리 (Binary Search Tree) \- 모든 노드에 대해, 왼쪽 서트브리는 현재의 노드의 값보다 작고 오른쪽 서브트리는 현재의 노드의 값보다 크다는 성질을 만족하는 이진 트리 \- 배열에 대한 이
4.[데이터 엔지니어링 데브코스] TIL 5일차 - 자료 구조 & 알고리즘 풀기(3)
이진 탐색 트리 삭제Heap \- 이진 트리의 한 종류로써 binary heap 이라고도 부른다. \- 루트 노드가 항상 최댓값이거나 최솟값이어야하며 완전 이진 트리여야한다. \- 원소의 삽입과 삭제가 용이하며 마지막 노드에서만 가능하다.오늘은 개인적인
5.[데이터 엔지니어링 데브코스] TIL 6일차 - 파이썬으로 웹다루기(1)
HTML 구조느낀 점😊
6.[데이터 엔지니어링 데브코스] TIL 7일차 - 파이썬으로 웹다루기(2)
WEB네트워크(Network) : 두 컴퓨터를 연결하여 정보를 교환하는 것근거리 지역 네트워크(Local Area Network, LAN): 두 개의 컴퓨터가 아닌 가까운 여러 컴퓨터를 연결하는 것을 라고 한다.인터넷(Internet, Inter Network) : 범
7.[데이터 엔지니어링 데브코스] TIL 8일차 - 파이썬으로 웹다루기(3)
BeatifulSoup4requests 모듈을 사용해서 페이지의 내용을 긁어왔지만 원하는 태그의 내용까지 긁어오기엔 힘들었다. 이를 해결하기 위해 BeatifulSoup4 모듈을 사용한다.페이지네이션 되어있는 페이지의 경우 page의 정보가 url로 변경된다면 page
8.[데이터 엔지니어링 데브코스] TIL 9일차 - 파이썬으로 웹다루기(4)
Selenium을 이용한 웹 브라우저 조작필요한 라이브러리 : Selenium, webdriver-managerSelenium을 통해 웹 브라우저를 이동할 수 있고 마우스를 이용한 클릭, 스크롤, 키보드를 통한 입력 등을 python으로 자동화할 수 있다.이때, 빠르게
9.[데이터 엔지니어링 데브코스] TIL 10일차 - 파이썬으로 웹다루기(5)
시각화 라이브러리 Seaborn다양한 그래프를 고수준(high-level)으로 쉽게 그릴 수 있도록 도와주는 라이브러리matplotlib 라이브러리에 기반을 두고 있어 기존 함수에 다양한 속성과 요소에 변화를 주기 위해선 matplotlib.pyplot을 사용한다.자료
10.[데이터 엔지니어링 데브코스] TIL 11일차 - 장고 활용한 API서버 만들기(1)
Django 세팅django의 프로젝트는 웹 사이트 하나를 말하고, 앱은 웹 페이지 하나를 말한다.각 프로젝트와 앱에 대해 폴더가 하나씩 만들어지고 서로 관리하기 위해 import와 export를 자유롭게 이용한다.django Model 생성django에서 Model은
11.[데이터 엔지니어링 데브코스] TIL 12일차 - 장고 활용한 API서버 만들기(2)
뷰(View)와 템플릿(Template)뷰는 models에서 정의한 테이블을 실제 화면에 적용하는 것이고, 템플릿은 django에서 html을 쓰게 해주는 도구이다. 뷰는 views.py 파일에서 작성한다.템플릿은 각 앱에 templates/app-name 폴더를 만든
12.[데이터 엔지니어링 데브코스] TIL 13일차 - 장고 활용한 API서버 만들기(3)
SerializerSerialize : 모델 인스턴스나 QuerySet과 같은 데이터를 API로 주고 받기 위해서 JSON 형식의 파일로 변환하는 작업Deserialize : JSON 형식의 데이터를 정의된 포맷에 맞추어 다시 모델 인스턴스로 변환하는 작업Seriali
13.[데이터 엔지니어링 데브코스] TIL 14일차 - 장고 활용한 API서버 만들기(4)
User & AuthenticationUser는 django.contrib.auth에서 자동으로 생성해주는 테이블shell 에서 불러올 때 from django.contrib.auth.models import User 을 사용한다.유저의 로그인 상태에 대한 자세한 pe
14.[데이터 엔지니어링 데브코스] TIL 15일차 - 장고 활용한 API서버 만들기(5)
pop(), popitem()pop(key, default)딕셔너리에서 지정된 key에 해당하는 value를 반환하고, 해당 key-value 쌍을 딕셔너리에서 제거하는 메서드만약 딕셔너리에 해당 key가 존재하지 않는다면, pop()메서드는 default 값을 반환d
15.[데이터 엔지니어링 데브코스] TIL 16일차 - 크롤한 데이터로 만들어보는 웹사이트(1)

오늘부터 이번주 금요일까지 크롤링한 데이터로 간단한 웹사이트를 만드는 프로젝트를 진행한다.첫 시작으로 프로젝트의 주제와 데이터를 정하는 회의를 진행했다.주제 : 서울 실시간 핫플레이스는 어디?설명 : 서울 실시간 도시 데이터를 활용하여 현재 붐비는 곳과 한적한 곳을 표
16.[데이터 엔지니어링 데브코스] TIL 17일차 - 크롤한 데이터로 만들어보는 웹사이트(2)

핫 플레이스가 3개 미만일 때가 있다.=> 3개 미만인 경우 해당하는 핫플레이스만 표출지금 화면의 API가 Get method 하나만 있다.=> 댓글창을 추가하자. 댓글은 200자 제한하고 최근 댓글 3~4개만 표출이미지를 db에 저장할 것인가? 서버에 저장할 것인가?
17.[데이터 엔지니어링 데브코스] TIL 18일차 - 크롤한 데이터로 만들어보는 웹사이트(3)
오늘 배운 것🤓 python 가상환경 원하는 버전으로 세팅 원하는 버전을 우선 컴퓨터에 설치하기 이때, path를 생성하는 버튼을 꼭 누르자. cmd에서 py -0으로 설치된 버전 확인한다. python 버전 확인 원하는 경로로 이동
18.[데이터 엔지니어링 데브코스] TIL 19일차 - 자료 구조 & 알고리즘 풀기(4)
완주하지 못한 선수마라톤에 뛰는 선수와 완주한 선수가 담겨있는 리스트를 받으면 완주하지 못한 선수를 찾는 문제단, 완주하지 못한 선수는 1명이다.이름이 겹칠 수도 있기 때문에 마라톤을 뛰는 모든 선수들에게 점수를 1점씩 부여하고 완주할때 1점을 감점함으로써, 1점이 남
19.[데이터 엔지니어링 데브코스] TIL 20일차 - 자료 구조 & 알고리즘 풀기(5)
오늘 배운 것🤓 Heap을 이용한 알고리즘 문제 풀이 Heap은 완전이진트리를 만족하는 자료 구조로써, Max Heap, Min Heap으로 사용한다. 최대/최소 원소를 빠르게 찾을 수 있다는 장점을 가지고 있고, 완전이진트리 성질을 이용해 배열로써 구현이 가능하기
20.[데이터 엔지니어링 데브코스] TIL 21일차 - 데이터 웨어하우스와 SQL과 데이터분석(1)
SQL은 구조화된 데이터(RDBMS)를 다루기 위해 개발된 언어데이터 직군에서는 SQL은 필수이다. 데이터 직군에서는 데이터 요약과 데이터 분석에 초점을 맞춘다.종류DDL(Data Definition Language) : 테이블을 정의한다.ex) CREATE, ALTE
21.[데이터 엔지니어링 데브코스] TIL 22일차 - 데이터 웨어하우스와 SQL과 데이터분석(2), (3)
여러 줄의 SQL문을 실행한다면 세미콜론(;)로 분리하는 것이 필수주석이 한 줄일 땐 --, 여러 줄 일 땐 /\* \*/테이블, 필드 이름의 명명규칙, SQL 키워드 대소문자 등 규칙을 정해서 통일성을 맞추도록 하자.1) CREATE테이블을 만들 수 있으며, RDB와
22.[데이터 엔지니어링 데브코스] TIL 23일차 - 데이터 웨어하우스와 SQL과 데이터분석(4)
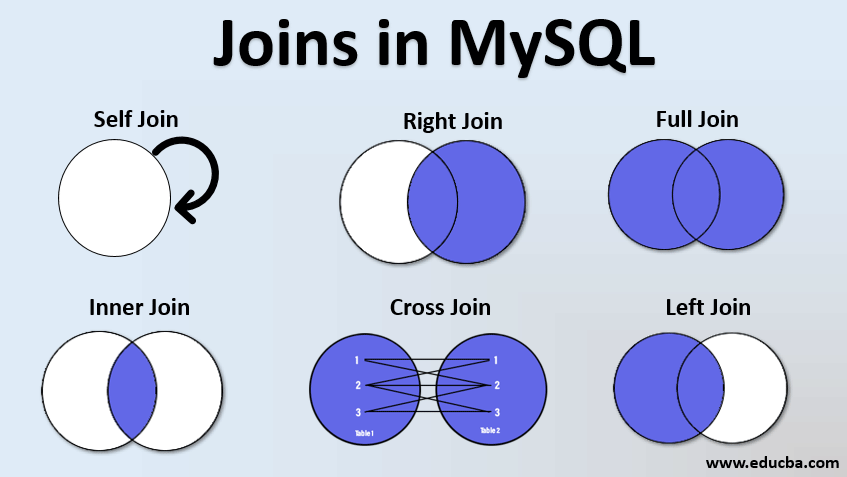
RedShift에 사용하기 위한 sql을 배운 것이기 때문에 PostgreSQL 8.X 버전의 문법으로 정리한다.2개 이상의 테이블을 합치는 것을 Join 혹은 Merge 한다고 한다. 아래의 그램에서는 MySQL이라고 되어있지만 모든 SQL에는 아래와 같은 Join이
23.[데이터 엔지니어링 데브코스] TIL 24일차 - 데이터 웨어하우스와 SQL과 데이터분석(5)
Atomic하게 실행되어야 하는 SQL들을 하나의 작업처럼 처리하는 방법atomic : 여러 SQL이 동시에 성공/실패해야 데이터의 정합성을 유지할 수 있는 경우(예. 은행 계좌 이체)이는 DDL이나 DML 중 레코드를 수정/삭제/추가 했을 때만 적용(즉, SELECT
24.[데이터 엔지니어링 데브코스] TIL 24일차 - 데이터 웨어하우스와 SQL과 데이터분석(5)
Atomic하게 실행되어야 하는 SQL들을 하나의 작업처럼 처리하는 방법atomic : 여러 SQL이 동시에 성공/실패해야 데이터의 정합성을 유지할 수 있는 경우(예. 은행 계좌 이체)이는 DDL이나 DML 중 레코드를 수정/삭제/추가 했을 때만 적용(즉, SELECT
25.[데이터 엔지니어링 데브코스] TIL 25일차 - AWS 클라우드(1)
Amazon Web Service인터넷을 통해 논리적 서버와 서비스를 On-demend로 제공하고 사용하고 사용한 만큼만 지불하도록 하는 클라우드 컴퓨팅을 제공하는 회사클라우드 컴퓨팅은 민첩성, 탄력성, 비용절감, On-demend, 관리 용이성에 대한 장점을 가지고
26.[데이터 엔지니어링 데브코스] TIL 26일차 - AWS 클라우드(2)
클라우드 서비스가상화를 기반으로 물리적이 아닌 논리적으로 서버를 구성하여 제공하는 서비스Snapshot(스냅샷)사진 찍듯이 시스템을 포착해 보관하는 기술그 순간의 리소스나 프로세스를 저장하여 해당 시점으로 서버를 구동할 수 있도록 한다.장애, 에러와 같은 상황에 스냅샷
27.[데이터 엔지니어링 데브코스] TIL 27일차 - AWS 클라우드(3), (4)
리소스에 대한 액세스를 안전하게 제어할 수 있는 AWS 웹 서비스인증(로그인)과 권한 관리를 한다.IAM 자격 증명은 AWS계정 루트 사용자가 하며, 일상적인 작업에서는 루트 사용자가 아닌 별도의 사용자 계정을 이용해야 한다.어떤 리소스에 대해서 접근할 수 있고 허가를
28.[데이터 엔지니어링 데브코스] TIL 28일차 - AWS 클라우드(4), (5)

이벤트에 대응하여 코드를 실행하는 serverlss 서비스별도의 물리적인 서버도, EC의 인스턴스도, 환경도 필요없이 코드를 실행시킨다.특정 이벤트에 대한 반응으로 사용하는 것이 일반적생성할 때 "블루프린트 사용"을 누른다면 AWS에서 제공하는 이미 존재하는 코드를 실
29.[데이터 엔지니어링 데브코스] TIL 29일차 - 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(1), (2)
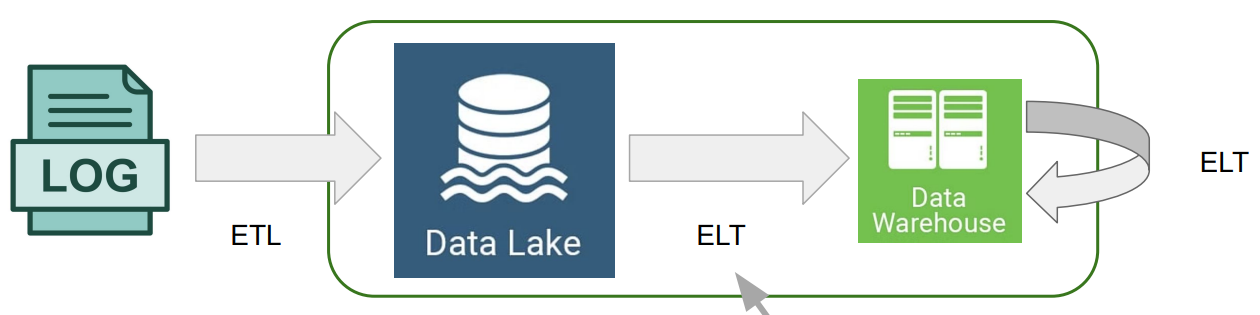
프로그래밍 언어 : Python은 필수, JAVA, Scalar는 선택Data Warehouse : RedShift, BigQuery, Snowflake 등빅데이터 파이프라인 : AirflowETL 스케줄러이며, 특정 ETL의 실행이 실패했을 때 원인을 분석하고 재실행
30.[데이터 엔지니어링 데브코스] TIL 30일차 - 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(2), (3)
일반적으로 사용자 별로 테이블의 권한을 설정하지 않는다. (너무 복잡하여 실수할 가능성이 높기 때문)사용자 집합(Group/Role)과 테이블 집합(Schema)를 만들어서 그 사이에 access 권한을 연결한다.개인 정보와 관련된 테이블이라면 따로 schema와 g
31.[데이터 엔지니어링 데브코스] TIL 31일차 - 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(3), (4)
Redshift의 확장 기능 (별도의 설치 X)S3에 있는 데이터와 파일들을 SQL을 이용하여 Redshift에서 외부 테이블(External Table)로 처리하면서 redshift의 테이블과 조인 가능하다.S3와 redshift는 같은 region에 있어야 한다.S
32.[데이터 엔지니어링 데브코스] TIL 32일차 - 데이터 웨어하우스를 이용한 대시보드 구성 2일차
\-> 서울시 구별 유출 인구 원인 분석유동인구 데이터를 통해 2023년 월 별 구 단위의 이동 인구의 유출을 비교한다.지도 그래프를 사용(나이대, 성별과 같은세부 선택 사항은 select 가능 하도록 제작)유동인구 데이터와 생활 데이터를 접목하여 지하철 사용, 유투브
33.[데이터 엔지니어링 데브코스] TIL 33일차 - 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드(5) & 데이터 웨어하우스를 이용한 대시보드 구성 3일차
대시보드 혹은 BI(Businuess Intelligence) 툴이라고도 부른다.데이터 기반 의사결정을 가능하게 한다.현업 종사자들이 데이터 분석을 가능하도록 한다\-> Citizen Data AnalystExcel / 구글 스프레드 시트 어쩌면 전세계적으로 가장 많
34.[데이터 엔지니어링 데브코스] TIL 34일차 - 데이터 웨어하우스를 이용한 대시보드 구성 4일차
필터로 특정 구 선택 시, 다방면으로 그래프가 변화하도록 구성구성할 차트 목록각 구의 유출 인구 수를 지도를 통해 scatter로 보여주기점의 크기는 인구 수에 영향을 받음지도로 표현한 값을 바 그래프로 자세하게 수치 비교성별, 연령대, 시간, 요일에 따른 선택한 구의
35.[데이터 엔지니어링 데브코스] TIL 35일차 - 데이터 웨어하우스를 이용한 대시보드 구성 5일차
필터 일괄 적용보고서 작성Diagrams 사용하여 flow chart 생성Graphbiz 라이브러리에 의존성을 가지고 있다.Graphbiz 라이브러리를 사용하려면 graphbiz에 대한 path를 설정해야 한다.Graphbiz는 정말 예상치 못했다. Path 설정하는게
36.[데이터 엔지니어링 데브코스] TIL 36일차 - 데이터 파이프라인과 Airflow(1)
데이터를 소스로부터 목적지로 복사하는 작업Data Worflow 혹은 DAG(Airflow에서) 혹은 ETL이라고 한다.보통 코딩(Python)과 SQL로 이루어진다.ETLExtract, Transform, Load데이터를 외부에서 내부로 가져오는 프로세스보통 타부서에
37.[데이터 엔지니어링 데브코스] TIL 37일차 - 데이터 파이프라인과 Airflow(2)
Atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법중간에 실패하면 불완전한 상황에 놓이는 일련의 작업들이 있을 때 사용한다.BEGIN; 부터 END; 또는 COMMIT; 사이에 놓은 작업들을 하나의 작업처럼 사용한다.ROLLBACK;은 BE
38.[데이터 엔지니어링 데브코스] TIL 38일차 - 데이터 파이프라인과 Airflow(3)
다양한 Operator들 중 적합한 Operator를 찾지못해 직접 작성하는 경우 사용한다.자유도가 높고, 설정해줘야하는 내용이 많다.위의 코드를 좀더 단순하게 Operator를 직접 지정하지 않고 task Decorator를 사용하여 파이썬 함수 자체를 operato
39.[데이터 엔지니어링 데브코스] TIL 39일차 - 데이터 파이프라인과 Airflow(3)
오늘 배운 것🤓 Connection 웹 UI를 통해 Connections를 추가할 때 써야하는 항목 Conn Id : 원하는 이름 Conn Type : DB 종류 (Postgresql, MySQL, Redshift, ...) Host : DB 접속 주
40.[데이터 엔지니어링 데브코스] TIL 40일차 - 데이터 파이프라인과 Airflow(4)
테이블에서 하나의 레코드를 유일하기 지칭할 수 있는 필드(들)하나의 필드가 일반적이지만 다수의 필드 사용 가능다수의 필드를 PK로 사용할 경우 일부 필드는 FK일 수도 있다.하지만 Data Warehouse는 PK를 지켜주지 않는다.(Why? 보정하는데 메모리와 시간이
41.[데이터 엔지니어링 데브코스] TIL 41일차 - 데이터 파이프라인과 Airflow(5)
Production DB가 MySQL이고 Data Warehouse는 Redshift라는 전제 하에 정리MySQL의 데이터를 바로 Redshift로 Insert하기이 방법은 데이터 수가 적을 때 사용한다.MySQL의 데이터를 file형태로 S3에 적재한 후, S3에서
42.[데이터 엔지니어링 데브코스] TIL 42일차 - Docker & K8S (1)
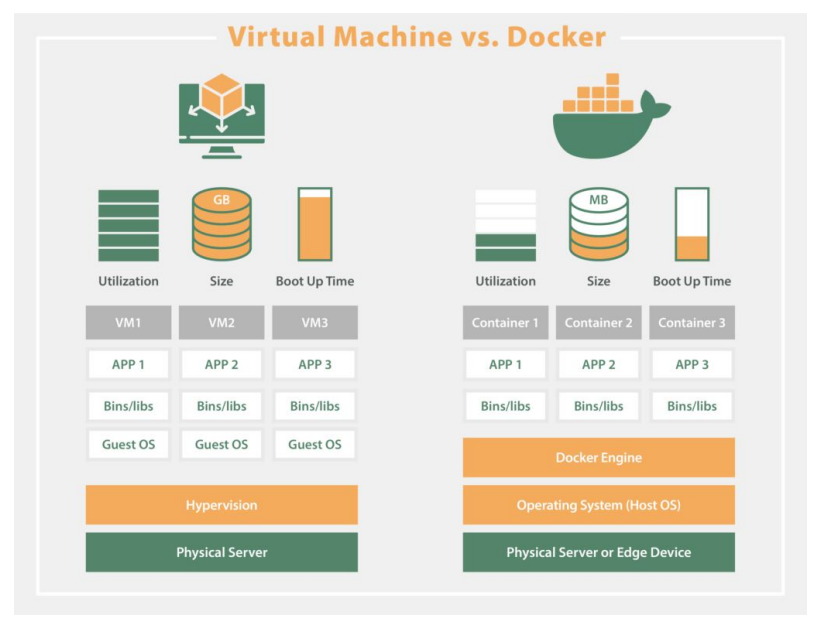
DAG 수가 많아진다면 데이터 품질이나 데이터 리니지 이슈 이외에도 다양한 이슈가 발생한다.라이브러리 충돌라이브러리/모듈이 충돌할 수도 있다.DAG에 따라 실행에 필요한 라이브러리/모델이 달라지기 시작한다.DAG 혹은 Task코드에 적용되는 Docker Image를 만
43.[데이터 엔지니어링 데브코스] TIL 43일차 - Docker & K8S (2)
Github main의 코드가 머지될 때마다 다음의 순서를 수행한다.테스트 수행Docker Image 빌드dockerfile을 repo에 생성Docker Image를 Docker Hub로 푸시이 과정을 자동으로 수행하기 위해 Github Actions를 사용할 수 있다
44.[데이터 엔지니어링 데브코스] TIL 44일차 - Docker & K8S (3)
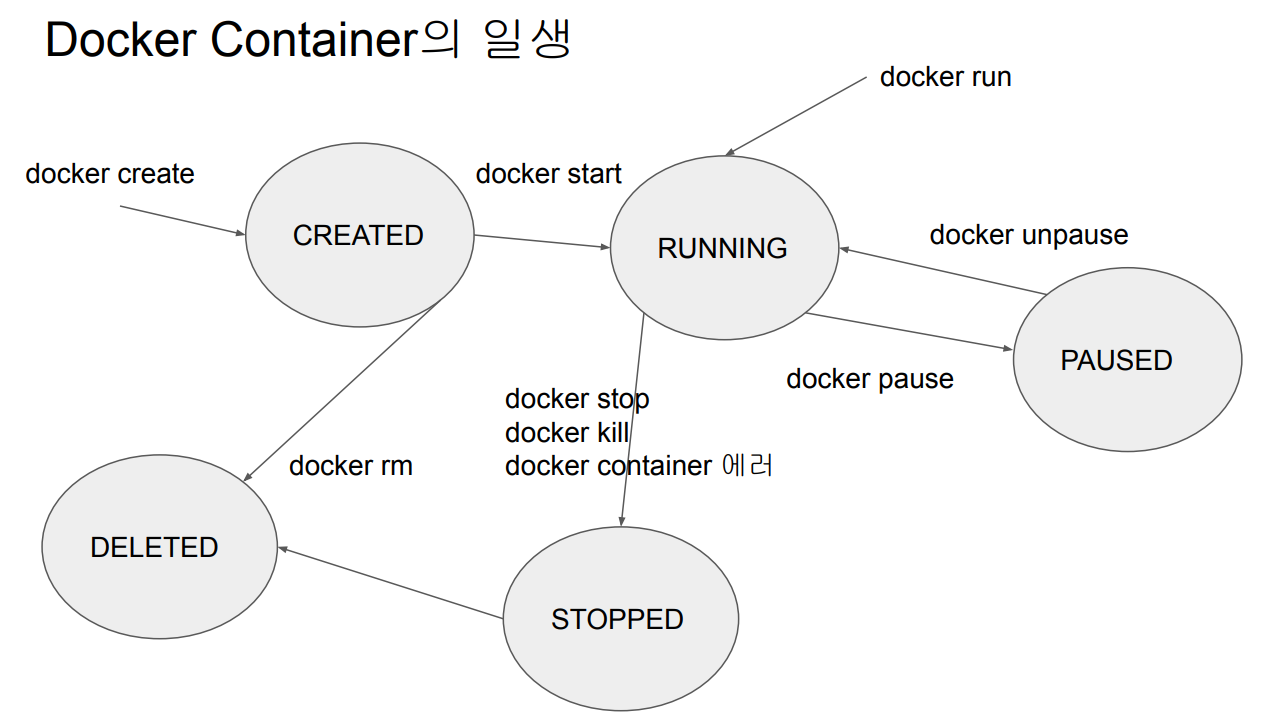
CI/CD를 Github 위에서 구현하기 위한 서비스코드 테스트, 빌드, 배포 자동화 기능 제공Github Actions로 만든 프로세스들을 workflow라고 부른다.trigger event가 발생하면 시작되는 일련의 동작들의 집합triggeg event 예시코드 c
45.[데이터 엔지니어링 데브코스] TIL 45일차 - Docker & K8S (3)
Docker Container가 실행 중에 중단된다면 데이터는 저장되지 않고 모두 날라간다.Docker Container로 실행하는 애플리케이션이 일회성으로 동작하는 것이 아니라 계속 동작해야 한다면(예. DB) 데이터가 영구적으로 보관되어야 한다.Data Persis
46.[데이터 엔지니어링 데브코스] TIL 46일차 - Docker & K8S (4)&(5)
다수의 container로 소프트웨어가 구성되는 경우 사용하는 툴이자 환경설정파일이다.docker-compose.yml 혹은 docker-compose.yaml으로 설정한다. 둘 중 하나만 있으면 되고 둘 다 있으면 에러가 발생한다.다양한 테스트들이 수행 가능하며, 다
47.[데이터 엔지니어링 데브코스] TIL 47일차 - Docker & K8S (5) & Airflow 고급 기능 배우기(1)
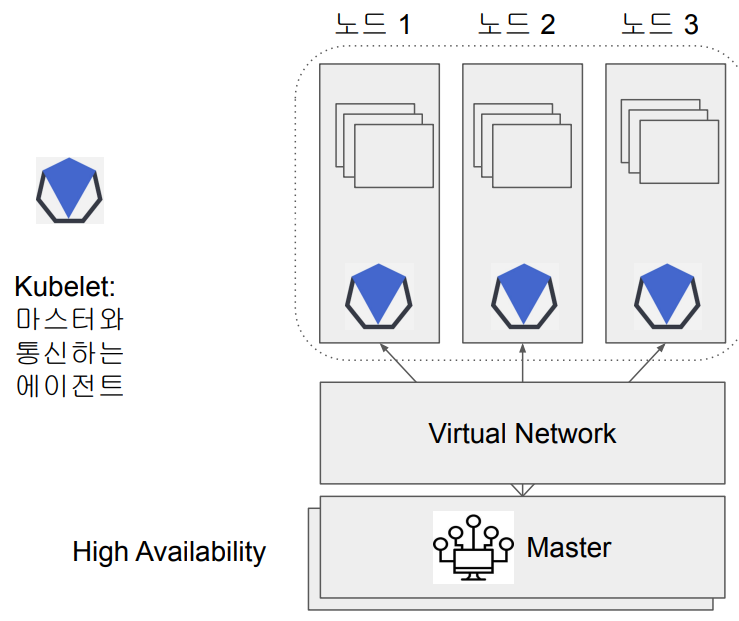
다수의 호스트에서 구동되는 다수의 container을 효율적으로 관리하기 위한 도구한 클러스터 안에 다양한 서비스들(DB, Web, Backend,...)이 공존한다. 각 서비스들에서 자원을 요청하고 마스터에서 그 요청을 모아 자원을 할당한다.배포, 스케일링, 네트워크
48.[데이터 엔지니어링 데브코스] TIL 48일차 - Airflow 고급 기능 배우기(1) & (2)
자동으로 원하는 시간에 돌아가도록 만든 DAG는 에러가 발생해도 직접 Airflow에 접속해서 일일이 확인하지 않는다면 에러가 발생했는지 알 수가 없다. 에러가 발생했을 때 실시간으로 알 수 있는 방법으로 Slack과 연동하는 방법이 있다.전반적인 순서는 아래와 같다.
49.[데이터 엔지니어링 데브코스] TIL 49일차 - Airflow 고급 기능 배우기(3)
Python에서 널리 사용되는 템플릿 엔진Django 템플릿 엔진에서 영감을 받아 개발Jinja를 사용하면 프레젠테이션 로직과 애플리케이션 로직을 분리하여 동적 HTML 생성Flask에서 사용변수는 이중 중괄호 {{ }} <h1> 제 이름은 {{name}} 입니다
50.[데이터 엔지니어링 데브코스] TIL 50일차 - Airflow 고급 기능 배우기(3)&(4)
오늘 공부한 내용🤓 Dynamics DAG 비슷한 기능을 하는 DAG들 각각을 manual하게 개발하지 말고 템플릿을 만들어서 인자를 넘겨주는 형태로 개발하는 DAG DAG를 계속해서 만드는 것과 한 DAG 안에서 task를 늘리는 것 사이의 밸런스가 필요하다.
51.[데이터 엔지니어링 데브코스] TIL 51일차 - 3차 미니 프로젝트 (End-to-end 데이터 파이프라인 구성하기)
인천 출발 항공편 데이터를 활용한 세계 날씨, 환율 비교데이터항공편 데이터환율 데이터(https://www.koreaexim.go.kr/ir/HPHKIR020M01?apino=2&viewtype=C&searchselect=&searchword= - 날씨 데
52.[데이터 엔지니어링 데브코스] TIL 52~55일차 - 3차 미니 프로젝트 (End-to-end 데이터 파이프라인 구성하기)
추후 작성 예정
53.[데이터 엔지니어링 데브코스] TIL 56일차 - 하둡과 spark(1)
서버한 대로 처리할 수 없는 규모의 데이터기존의 SW로는 처리할 수 없는 규모의 데이터4V를 만족하는 데이터Volume : 데이터 크기Variety : 구조화/비구조화Velocity : 데이터 처리 속도Veracity : 데이터의 품질큰 데이터를 손실없이 보관할 방법이
54.[데이터 엔지니어링 데브코스] TIL 57일차 - 하둡과 spark(2)
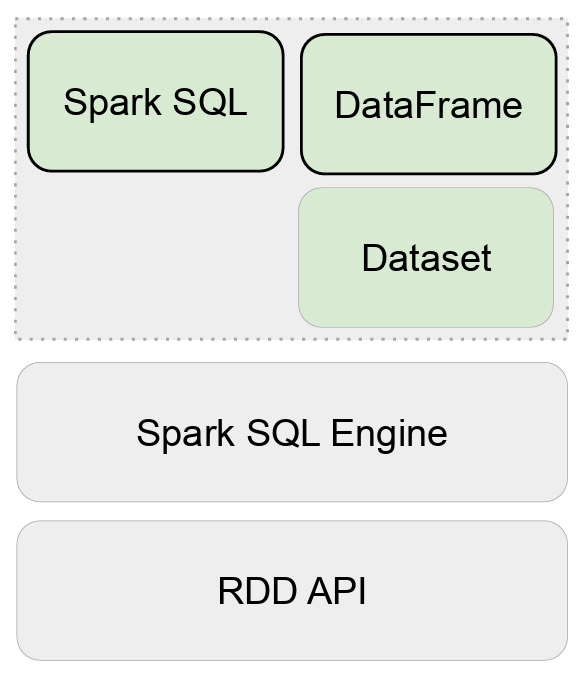
오늘 공부한 내용🤓 데이터 병렬 처리 데이터 병렬 처리가 가능하려면 우선 데이터를 분산시키고, 그렇게 나눠진 데이터를 각각 따로 처리해야 한다. 데이터 분산 -> 파티셔닝(Partitioning) 하둡 map의 데이터 처리 단위는 디스크에 있는 데이터 블록
55.[데이터 엔지니어링 데브코스] TIL 58일차 - 하둡과 spark(3)
SQL은 빅데이터 세상에서 필수!구조화된 데이터는 규모와 상관없이 SQL을 사용모든 대용량 data warehouse는 SQL 기반Redshift, Snowflake, BigQueryHive / PrestoSpark도 Spark SQL을 지원함으로써 SQL을 사용구조화
56.[데이터 엔지니어링 데브코스] TIL 59일차 - 하둡과 spark(3)~(5)
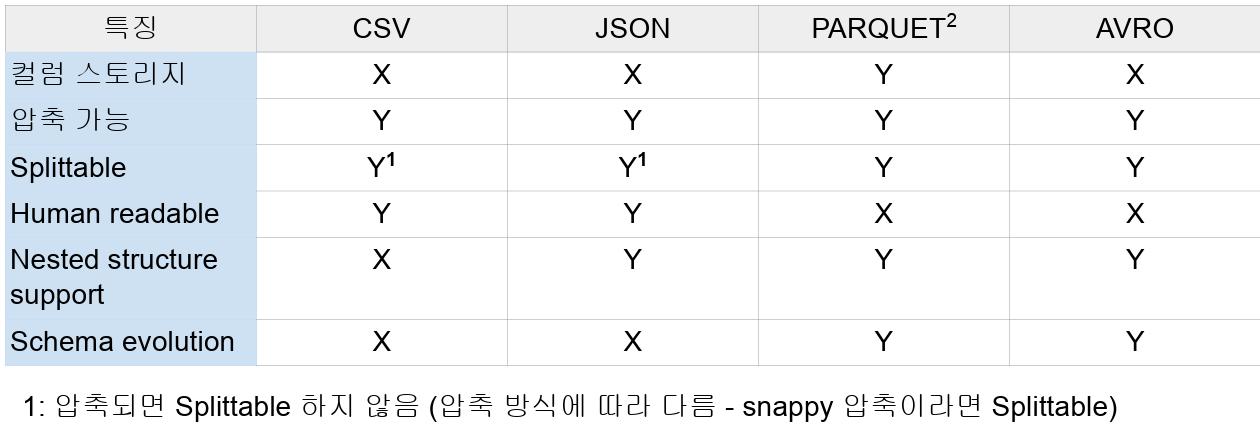
카탈로그 : 테이블과 뷰에 관한 메타 데이터 관리기본으로 메모리 기반 카탈로그 제공 : 임시 메모리 기반으로 세션이 끝나면 사라짐Hive와 호환되는 카탈로그 제공 : 영구적 스토리지 기반으로 지속적으로 사용할 수 있다. (Persistent)테이블 관리 방식 : 테이블