오늘 배운 것🤓
데이터 엔지니어 기본 스킬
- 프로그래밍 언어 : Python은 필수, JAVA, Scalar는 선택
- Data Warehouse : RedShift, BigQuery, Snowflake 등
- 빅데이터 파이프라인 : Airflow
ETL 스케줄러이며, 특정 ETL의 실행이 실패했을 때 원인을 분석하고 재실행해야 한다.(backfill) - 클라우드 : AWS, Azure, GCP
위의 5가지는 주니어 엔지니어로써 꼭 알아야 하는 것들이라면 아래는 시니어 엔지니어가 되기 위해 알아야 하는 스킬이다.
- 컨테이너 기술 : docker, K8s
- 빅데이터 처리 프레임 워크 : Spark/YARN
분산 환경 시스템으로, fault tolerance(소수의 서버가 고장나도 동작해야 한다.)를 만족해야 한다. - Machine Learning의 일반적인 지식
- A/B 테스트, 통계 지식
ETL vs ELT
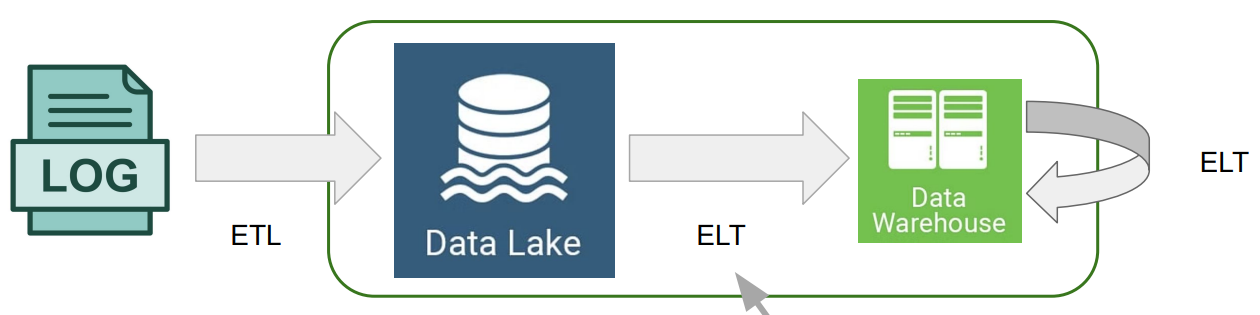
우선, 데이터 레이크는 storage 그 자체로써 data warehouse보다는 가격이 더 싸고, 비구조적 데이터를 적재할 수 있다는 장점을 가지고 있다.
모든 데이터를 데이터 레이크에 적재하는 과정을 ETL이라고 하고, 적재된 데이터를 정제하고 다시 데이터 레이크에 적재하거나 데이터 웨어하우스에 적재하는 과정을 ELT라고 한다.
ETL와 ELT는 같은 단어의 순서만 뒤바꾼 형태이다.
E는 Extract로써 데이터를 추출한다는 의미이다.
T는 Transform으로써 데이터에 변형을 가하는 것이다.
L은 Load로써 데이터를 적재하는 과정을 말한다.
이렇게 최초로 데이터를 적재하는 과정을 ETL이라고 하고, 적재된 데이터를 다시한번더 원하는 형태로 가공하여 다시 적재할 때 ELT라고 한다.
데이터 웨어하우스 옵션
1. AWS RedShift
- AWS기반의 데이터 웨어하우스
- PostgreSQL 8.xx 버전과 호환됨
- Python으로 UDF(User Defined Function)을 작성하여 기능 확장이 가능하다.
- 다양한 데이터 포맷을 지원(CSV, JSON, Avro, Parquet 등)
- AWS 내의 다른 서비스와 연동이 쉬움
- 배치 데이터 중심이고 실시간 데이터 처리를 지원한다.
2. Snowflake
- 클라우드 기반 데이터 웨어하우스로 시작했고, 현재는 데이터 클라우드로 부를 수 있을 만큼 성장했다.
- 데이터 판매를 통한 매출을 가능하게 했다 -> Data Sharing/ Market place
- ETL과 다양한 데이터 통합 기능을 제공
- SQL 기반이며 UDF를 사용하여 기능을 확장할 수 있다.
- 다양한 데이터 포맷 지원(CSV, JSON, Avro, Parquet 등)
- 배치 데이터 중심이고 실시간 데이터 처리를 지원한다.
- 클라우드에 관계없이 동작한다.
3. GCP BigQuery
- 가장 scalable한 데이터 웨어하우스 솔루션
- BigQuery SQL로 데이터 처리가 가능하다.
Nested fields, Repeated field를 지원하는 등 다른 SQL보다 강력한 기능을 가지고 있다. - 다양한 데이터 포맷 지원(CSV, JSON, Avro, Parquet 등)
- 배치 데이터 중심이고 실시간 데이터 처리를 지원한다.
4. Apache Hive/Presto
- 하둡 기반 SQL을 지원하는 데이터 웨어하우스
- 1세대는 MapReduce, 2세대는 Apache Tez 위에서 동작한다.
- JAVA와 Python으로 UDF 작성 가능
- 배치 프로세싱 시스템을 지원한다.
- 데이터 파티셔닝 & 버킷팅과 같은 최적화 작업 지원
- Hive는 빠른 처리 속도보다 데이터 양의 크기에 최적화
- Presto는 데이터 양보다 처리 속도에 최적화
- 테스트할 때는 Presto, 운영할 때는 Hive를 사용하는 것이 일반적
5. Apache IceBerg
- 엄밀히 말하자면 데이터 웨어하우스 기술이 아니지만 Spark와 함께 사용하면서 DW로써 사용되는 중
- 모든 클라우드 서비스에서 사용되는 데이터 파일 포맷
- ACID 트랜잭션을 지원
- 과거 버전으로 Rollback이 가능하며 변경 기록을 유지한다.
- 스키마 진화(Schema Evolution) 지원을 통한 컬럼 제거와 추가 가능
- 자바와 파이썬 API를 지원
6. Apache Spark
- 빅데이터 처리 관련 종합선물세트라고 볼 수 있다.
(배치처리(API/SQL), 실시간처리, 그래프처리, 머신러닝 기능 제공) - 분산 처리 시스템을 지원한다.
자체적인 시스템은 아니고 기존에 있는 시스템을 사용한다.(Hadoop, Mesos, k8s 등) - JAVA, Python, Scalar, R을 지원한다.
스케일링 방식
스케일링 방식에는 크게 2가지가 있다. 이 2가지 중 하나만 사용하는 것이 아니라 상황에 맞게 2가지를 적절하게 섞어 사용한다. Redshift에서는 이 방식을 고려하는 것이 중요하지만(고정 비용이기 때문) BigQuery나 SnowFlake는 고려할 필요가 없다.(가변 비용이기 때문)
- Scale out
서버의 개수를 늘리는 방식
Redshift에서 resizing 옵션을 통해 auto scaling하도록 할 수 있다. - Scale up
기존에 있는 서버의 용량/사양을 늘리는 방식
레코드 분배와 저장 방식
- Redshift에서는 2대 이상의 노드로 구성되면 테이블 최적화가 중요하다.
- 강의에서는 Redshift에 대해서 배우므로 이것을 고려하는 것은 아주 중요!
- 레코드를 분배할 때는 3가지 키워드가 중요하다.
- Diststyle
한 테이블의 속성으로 지정한다.
all : 모든 데이터를 모든 노드에 복제
even : 노드별로 돌아가면서 저장 (default)
key : 특정한 column의 값을 기준으로 분배 - Distkey
diststyle을 key로 지정했을 때만 필요
노드에 저장하는 기준 column을 정한다.
key를 잘못 선택하면 data skew(특정 노드에 데이터가 몰리는 현상)문제가 발생한다. - Sortkey
어떤 column을 기준으로 정렬할지 표현
timestamp가 일반적이다.
- Diststyle
CREATE TABLE table_name (
column_info ~~~
) DISTSTYLE ALL SORTKEY (column1);
CREATE TABLE table_name (
column_info ~~~
) DISTSTYLE EVEN SORTKEY (column1);
CREATE TABLE table_name (
column_info ~~~
) DISTSTYLE KEY DISTKEY(column1) SORTKEY (column2);느낀 점😊
추워지면서 몸살기가 있어서 수업에 전혀 참여를 하지 못했다. 이불을 꼭꼭 덮고 자야지...
드디어 AWS 기능을 직접 써볼 수 있다니! 너무 신난다!!! 내일은 빠르게 2일치 수업을 다 들어버릴것이다!

데이터 엔지니어를 꿈꾸는 주니어 입니다!