오늘 공부한 내용🤓
데이터 병렬 처리
데이터 병렬 처리가 가능하려면 우선 데이터를 분산시키고, 그렇게 나눠진 데이터를 각각 따로 처리해야 한다.
- 데이터 분산 -> 파티셔닝(Partitioning)
- 하둡 map의 데이터 처리 단위는 디스크에 있는 데이터 블록
- Spark에서는 이를 파티션(Partition) 이라고 부름
- 파티셔닝 방법은 데이터 소스에 따라 달라진다.
예를 들어 JDBS 소스는 기본적으로 하나의 파티션만 만든다. - 가능하다면 외부 데이터를 HDFS에 넣는 ETL 과정을 별도로 구축하여 spark에 적용하는 것을 추천
- 적절한 파티션 수 :
(Excutor의 수)*(Excutor당 CPU의 수)
- 나눠진 데이터 각각 처리 -> 병렬 처리
- MapReduce에서 N개의 데이터 블록으로 구성된 파일 처리 시 N개의 Map task가 실행된다.
- Spark에서는 파티션 단위로 메모리에 로드되어 Executor가 배정된다.
Spark 데이터 처리 흐름
- 데이터 프레임(이하 df)은 작은 파티션들로 구성된다.
- df는 한번 만들어지면 수정 불가(immutable)
- 입력 df를 원하는 결과 도출까지 다른 df로 계속 변환
sort,group by,filter,map,join, ...
sort,group by과 같은 연산은 파티션 간에 데이터 이동이 불가피하게 일어남! => 셔플링
셔플링(Shuffling)
- 파티션 간에 데이터 이동이 필요한 경우 발생
- 발생 하는 경우
- 명시적으로 파티션을 새롭게 하는 경우 (예. 파티션 수 줄이기)
- 시스템에 의해 이뤄지는 셔플링 (예.
group by와 같은 aggregation이나sort)
- 셔플링이 발생할 때 네트워크를 타고 데이터가 이동
- 데이터 변환 방식에 따라 파티션의 수와 방식이 결정
sort: range partition 사용aggregation: hashing partition 사용- 그 외, random partition, ...
- 셔플링 과정 중 Data Skew 발생 가능성이 다분
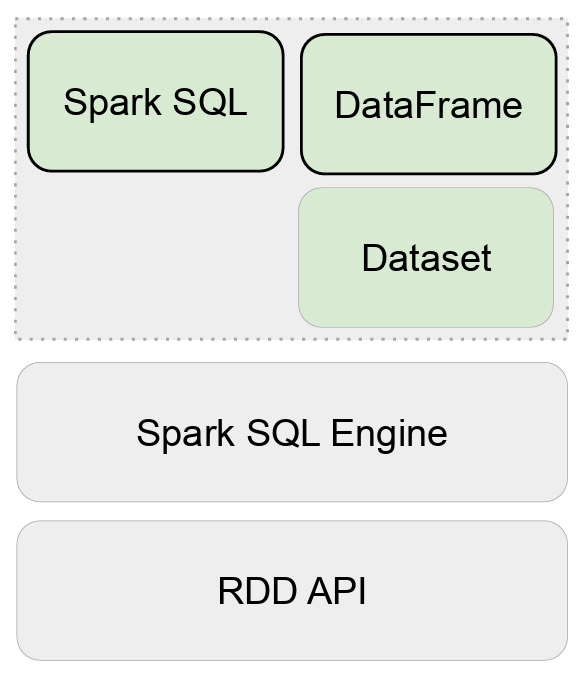
Spark 데이터 구조
- 종류 : RDD, DataFrame, Dataset
- Immutable Distributed Data 구조를 띄운다.
- 모두 파티션으로 나뉘어 Spark에서 처리한다.
- 2016년에 dataframe과 dataset은 하나의 API로 통합
spark script 작동 원리
- Code Analysis
: spark 상에서 코드를 분석한다. - Logical Optimization (Catalyst Optimizer)
: 코드를 실행할 수 있는 여러 개의 방안과 비용들에 대해 계산한다. - Pysical Planning
: 2번에서 나온 방안들 중 비용 최적의 방안을 선택한다. - Code Generation (Project Tungsten)
: 실제로 실행할 수 있도록 최적화를 진행하며 java byte code로 변경한다.
RDD
- low level 데이터로 클러스터 내의 서버에 분산된 데이터를 지칭
- 레코드 별로 존재하지만 스키마가 존재하지 않음
- 구조화/비구조화 데이터 모두 지원
- 다수의 파티션으로 구성
- low level의 함수형 변환 지정(map, filter, flatMap 등)
- 일반적인 파이썬 데이터는
parallelize함수로 RDD 변환 - 반대로
collect로 파이썬 데이터로 변환 가능
단, 작은 데이터로만 불러올 것
DataFrame & Dataset
- RDD와는 다르게 필드 정보를 가지고 있다. (테이블 형태)
- RDB table 처럼 컬럼으로 나눠서 저장
- 다양한 데이터 소스 지원 : HDFS, Hive, 외부 DB, RDD 등
- DataFrame은 Java, Scalar, Python과 같은 언어에서 지원
- Dataset은 타입 정보가 존재하며 컴파일 언어(Java/Scalar)에서 사용 가능
Spark Session
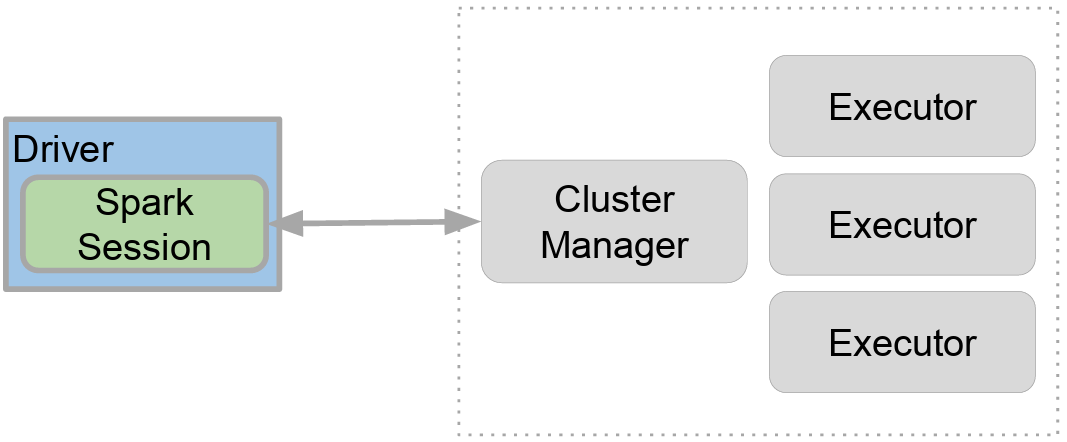
- Spark 프로그램 시작은 Spark Session을 만드는 것!
- 프로그램마다 하나를 만들어(Singleton 객체) Spark Cluster와 통신 => entrypoint와 같은 역할을 한다.
- Spak 2.0에서 처음 소개
- Spark Session을 통해 Spark에서 제공해주는 다양한 기능을 사용
- DataFrame, SQL, Streaming, ML API 모두 이 객체로 통신
- config 메소드를 이용해 다양한 환경 설정 가능
- 단, RDD와 관련된 작업을 할 때는 Spark Session 밑의 Spark Context 객체를 사용
환경 변수
- 사용하는 Resource Manager에 따라 환경 변수가 많이 달라지므로 공식 문서 필수
- 환경 변수 예시
- executor 별 메모리 :
spark.executor.memory(기본값 : 1g) - executor 별 CPU 수 :
spark.executor.cores(YARN에서는 기본값 : 1) - driver 메모리 :
spark.driver.memory(기본값 : 1g) - 셔플링 후 파티션 수 :
spark.sql.shuffle.partitions(기본값 : 200; 최대값을 설정하는 것)
- executor 별 메모리 :
- 환경 변수 설정 방법 4가지 (충돌 시 우선순위는 아래일 수록 높다.)
- 환경 변수
$SPARK_HOME/conf/spark_defaults.conf- spark.submit 명령의 CLI 파라미터
- Spark Session 만들 때 지정
지원하는 데이터 소스 (YARN 기준)
- Resource Manager에 따라 많이 다르다!
spark.read(Dataframe)를 사용하여 df로 로드Dataframe.write(DataframeWriter)를 사용하여 df를 저장- 많이 사용되는 데이터 소스들
- HDFS 파일
- CSV, json, Text, Parquet, ORC, Auro
- Hive 테이블
- JDBC, RDB
- 클라우드 기반 데이터 시스템
- 스트리밍 시스템
- HDFS 파일
Spark 개발 환경 옵션
- Local Standalone Spark + Spark Shell
- Spark Cluster Manager로
local[n]지정 - 주로 개발이나 간단한 테스트 용도
- 하나의 JVM에서 모든 프로세스를 진행
- 하나의 Driver와 하나의 Executor가 실행
- 1개 이상의 thread가 Executor 안에서 실행
- Spark Cluster Manager로
- Python IDE (Pycharm, Visual Studio)
- Databricks Cloud - 커뮤니티 에디션 무료
- Notebook (Jupyter Notebook, 구글 Colab, 아나콘다, ...)
PySpark
Spark Session
# 1. builder를 사용하여 만들기
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.config("spark.some.config.option1", "some-value") \
.config("spark.some.config.option2", "some-value") \
.getOrCreate()# SparkConf를 사용하여 만들기
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "PySpark Tutorial")
conf.set("spark.master", "local[*]")
spark = SparkSession.builder\
.config(conf=conf) \
.getOrCreate()Spark DataFrame 만들기
- python <-> RDD <-> Spark DF
# session은 이미 만들었다고 가정한다.
name_list = ['{"name":"danee"}', ...]
# Python -> RDD
# lazy executor이므로 연산이 실행되어야 표출
rdd = spark.sparkContext.parallelize(name_list)
# 저장된 RDD를 불러와서 json 형태로 변환
parsed_rdd = rdd.map(lambda x : json.loads(x))
# spark에서 불러오기
parsed_rdd.collect()# Python -> Spark df
from pyspark.sql.types import StringType
# spark.createDataFrame(list, 원소 타입)
df = spark.createDataFrame(name_list, StringType())# RDD -> Spark df
df_parsed_rdd = parsed_rdd.toDF()# spark df schema 확인
df.prictSchema()
# df 확인
df.show(n, truncate=True)
df.head(n)- csv <-> Spark DF
# CSV -> Spark df
## 헤더 없을 때
## 컬럼 이름이 없으므로 spark에서 임의로 설정
df = spark.read.csv("~~.csv")
df = spark.read.format("csv").load("~~.csv")
## spark df 컬럼 이름 사용자가 지정
## 단, csv의 컬럼 수와 동일한 수의 컬럼명을 넣어야 한다.
df = spark.read.csv("~~.csv")\
.toDF('col1', 'col2', ... , 'colN')
## 헤더 있을 때
df = spark.read.option("header", True).csv("~~.csv")# 타입 지정
## Spark에서 자동 지정
df = spark.read\
.option('inferSchema', 'true')
.csv('~~.csv')\
.toDF('col1', 'col2', ... , 'colN')
## 사용자가 직접 지정
## StructType('col_name', type, null 여부)
from pyspark.sql.types import StringType, IntegerType, ...
from pyspark.sql.types import StructType, StructField
schema = StrucType([
StructField('col1', StringType(), True),
StructField('col2', IntegerType(), False),
...
])
df = spark.read.schema(schema).csv('~~.csv') # Spark df -> CSV
# 분산 처리할 만큼 큰 데이터를 처리한다고 가정(블록 단위로 데이터 저장)
# 주어진 이름과 동일한 폴더를 만들고, 그 폴더 안에 블록 단위로 part_로 시작하는 파일로써 저장한다.
## 아래의 2개는 같은 것
## 기존에 같은 이름의 폴더가 있다면 에러
df.write.csv('~~~')
df.write.format('csv').save('~~~')
## 기존에 같은 이름의 폴더가 있다면 덮어쓰기
df.write.mode('overwrite').csv('~~~')Spark Dataframe 조작하기
# 컬럼 선택하기 (아래 2가지는 모두 같은 결과)
stationTemp = df[['station', 'temp']]
stationTemp = df.selct('station', 'temp')# 컬럼 삭제하기
df_new = df.drop('col')# 필터링 방법 (아래 3가지는 모두 같은 결과)
minTemps = df.filter(df.measure == 'min')
minTemps = df.where(df.measure == 'min')
minTemps = df.where("df.measure = 'min'")# groupby
minTempsByStation = minTemps.groupBy('station').min('temp')
# 연산 진행한 컬럼명 변경하기
## 1. withColumnRenamed('기존의 이름', '변경 이름') 사용
## 한번에 하나의 컬럼만 바꿀 수 있다.
df_group = df.groupBy('col1').sum('col2')\
.withColumnRenamed('기존의 이름', '변경 이름')
## 2. .agg() 사용하기
## 여러개의 컬럼을 한번에 바꿀 수 있다.
import pyspark.sql.functions as f
df_group = df.groupBy('col1')\
.agg(f.sum('col2').alias('new_sum'),
f.max('col3').alias('new_max'),
...)# 기존의 데이터를 사용해 새로운 컬럼 만들기
# withColumn(('수정/추가할 컬럼', UDF(채우고 싶은 데이터 처리 함수)))
df_new = df\
.withColumn('col1', sum('col2'))# 정규표현식 사용하기
# regexp_extract(컬럼명, '정규표현식', 표현식 위치)
# 표현식 위치의 인덱스는 1에서 시작
from pyspark.sql.function import *
regex_str = r'~~(\S+) ~~~ (\d+) ~~~'
df_new = df\
.withColumn('col1', regexp_extract('origin', regex_str, 1))
.withColumn('col2', regexp_extract('origin', regex_str, 2))# 하나의 row가 array일 때, 원소 하나를 1개의 row로 펼치기
# f.explode(df.컬럼명)
import pyspark.sql.functions as f
df_new = df.select(f.explode(df.col1).alias('explode col1'))# sorting
import pyspark.sql.functions as f
## 내림차순
df.sort(f.desc('col'))
df.orderby('col', ascending=False)
## 오름차순
df.sort(f.asc('col'))
df.orderby('col', ascending=True)# join
# 종류 : inner, left, right, outer, semi, anti
join_exp = left_df.id == right_df.id
join_df = left_df.join(right_df, join_exp, "inner")Spark SQL
앞서 보였던 예시 중 Spark Dataframe으로 처리하는 것 보다 SQL로 처리하는 것이 더 효율적인 경우가 대부분이다.
SQL로 처리할 수 있다면 SQL로 처리하고 그 외의 것들을 Dataframe으로 처리하도록 하자.
(예. 정규표현식을 dataframe으로!)
# dataframe을 sql로 처리하기 위해 임시 테이블명을 만든다.
df.createOrReplaceTempView('table_nm')
# sql 실행
df_new = df.sql('''SELECT *
FROM table_nm
WHERE ~~~
GROUP BY ~~~
''')# Spark에서 사용하는 table 리스트 확인
# Hive가 연동되어 있다면 Hive의 테이블도 보여준다.
spark.catalog.listTables()느낀 점😊
분량 진짜 너무 많다... 다 듣다가 기절하는 줄 알았다...
이 글을 쓰는데만 1시간이 넘게 걸렸다.... 이게 무슨 일이지?! 하지만 정말로 데이터 전처리하는 기분이라서 재미있었다.
생각보다 python의 dataframe과는 함수가 다르기 때문에 pyspark를 사용하여 만들기에는 시간이 걸릴 것 같다. 좀더 다양한 데이터로 이것저것 테스트하고 싶다.

데이터 엔지니어를 꿈꾸는 주니어 입니다!