[데이터 엔지니어링 데브코스] TIL 59일차 - 하둡과 spark(3)~(5)
Hive MetaStoreTILbucketingfile system partitioningparquetsparkspark execution plan데이터 엔지니어링 데브코스프로그래머스
0
데브코스 TIL
목록 보기
56/56
오늘 공부한 내용🤓
Hive Metastore
- 카탈로그 : 테이블과 뷰에 관한 메타 데이터 관리
- 기본으로 메모리 기반 카탈로그 제공
: 임시 메모리 기반으로 세션이 끝나면 사라짐 - Hive와 호환되는 카탈로그 제공
: 영구적 스토리지 기반으로 지속적으로 사용할 수 있다. (Persistent)
- 기본으로 메모리 기반 카탈로그 제공
- 테이블 관리 방식 : 테이블들은 '데이터베이스'라고 부르는 폴더(RDB에서 Schema)와 같은 구조로 관리
- 스토리지 기반 테이블
- 기본적으로 HDFS와 Parquet 포맷을 사용
- Hive와 호환되는 Metastore 사용
- 두 종류의 테이블 존재 (Hive와 동일한 개념)
- Managed Table : Spark가 실제 데이터와 메타 데이터 모두 관리
- UnManaged(External) Table : Spark가 메타 데이터만 관리
- 메타데이터는 테이블 이름, 스키마, 위치 등을 담고 있으며, 카탈로그(메타스토어)에 저장된다.
사용 방법
- 스토리지 기반 카탈로그 사용 시작
- Spark Session 생성 시
enableHiveSupport()호출 default라는 이름의 db 생성
- Spark Session 생성 시
from pyspark.sql import SparkSession
# Hive metasort 사용
spark = SparkSession.builer\
.appName('session 이름')\
.enableHiveSupport()\
.getOrCreate()
# default 말고 다른 database 사용하기
spark.sql("CREATE DATABASE IF NOT EXISTS db_name")
spark.sql("USE DATABASE")- Managed Table
- 사용 방법 2가지
dataframe.saveAsTable("테이블 이름")- CTAS /
CREATE TABLE
spark.sql.warehouse.dir이 가리키는 위치에 데이터 저장- 기본 데이터 포맷 : PARQUET
- 보통 선호하는 방식 (외부 db의 데이터를 배치를 돌려서 Managed Table로 변경하여 사용하는 것이 일반적)
- Spark 테이블로 처리하는 것이 장점
- JDBC/ODBC 등으로 Spark를 연결해서 접근 가능
spark.catalog.listTables()실행 시isTemparary=False확인
- 사용 방법 2가지
- External Table
- 이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용 =>
LOCATION이라는 인자 사용 - 메타 데이터만 카탈로그에 기록됨
: External Table을 삭제하면 메타 데이터만 삭제하고 실제 데이터는 그대로 있다.
- 이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용 =>
CREATE TABLE table_nm (
col ~~~
) USING PARQUET
LOCATION 'hdfs_path'Spark 파일 포맷
- 데이터는 디스크에 파일로 저장됨
- Unstruced : Text
- Semi-Structed : JSON, XML, CSV
- Structed : PARQUET, AVRO, ORC, SequeceFile
- Spark 주요 파일 타입
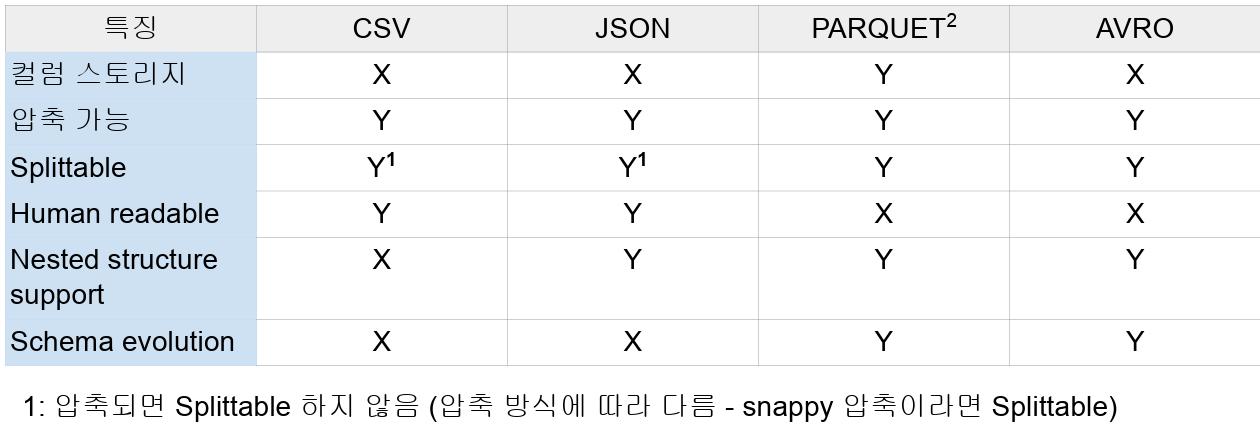
PARQUET
- Spark에서 채택한 기본 파일 형식
- PARQUET은 Hybrid Storage 방식을 따른다.
- 데이터 블로 별로 데이터를 적재하면서, 데이터 블록 안에서는 Column-wise 방식으로 적재
- PARQUET은 Schema Evolution이 가능한 파일 형식이므로 각기 다른 column을 가지고 있는 여러개의 파일을 한번에 merge가능
df = spark.read.option('mergeSchema', True).parquet('*.parquet')Avro 파일을 사용하려면 spark session을 만들 때 config를 추가해야 한다.
spark = SparkSession.builder\ .appName('session 이름'). ~~~ \ .config('spark.jars.packages', 'org.apache.spark:spark-avro_2.12:3.3.1')\ .getOrCreate()
Spark Execution Plan
- Spark가 코드를 어떻게 변환하여 실행하는가? => Execution Plan
- Transformations : 데이터 처리 과정
- Narrow Dependencies : 독립적인 Partition Level 작업
stage에서 한번에 처리할 수 있음
select,filter,map등 - Wide Dependencies : Shufflig이 필요한 작업
stage에서 처리 X
group by,reduce by,partition by,reparition등등 - Narrow 연산 여러 개를 하나의 stage가 작업하고, Wide 연산이 등장하면 새로운 stage가 생성된다.
- Narrow Dependencies : 독립적인 Partition Level 작업
- Actions : Job을 실행시키는 과정 (실제 코드 실행)
Read,Write,Show,Collect, ...- Lazy Execution : 더 많은 operation을 볼 수 있기에 최적화를 더 잘 할 수 있다. 그래서 SQL을 선호
- Execution 순서
- Action -> Job -> 1+Stage -> 1+Task
- Action : Job을 하나 만들어내고 코드가 실제로 실행됨
- Job : 하나 혹은 그 이상의 stage로 구성됨
- Stage : DAG의 형태로 구성된 Task들이 존재, 여기 task들은 병렬 실행이 가능
- Task : 가장 작은 실행 유닛으로 Executor에 의해 실행
Bucketing & File System Partitioning
- 둘 다 Hive 메타스토어의 사용이 필요 :
saveAsTable - 데이터 저장을 데이터 반복 처리에 최적화된 방법으로 하는 것
Bucketing
- shuffling을 줄이는 것이 가장 큰 목적
- shuffling을 발생시키는 연산 (Aggregation, Join, Window 함수)에서 자주 사용되는 column이 있다면 그 컬럼들을 기준으로 테이블로 저장 (caching 느낌)
- DataFrame을 특정 ID를 기준으로 나눠서 테이블로 저장
- 이를 로딩하여 사용함으로써 반복 처리 시 시간 단축
DataFrameWriter의bucketBy함수 사용
-> Bucket의 수와 기준 ID 저장
- 데이터의 특성을 알고 있는 경우 사용 가능
File System Partitioning
- 데이터를 Partion Key 기반 폴더('Partition') 구조로 물리적으로 나눠 저장
- Hive에서 주로 사용
- 사용 예시
- 굉장히 큰 로그 파일을 데이터 생성 기반으로 데이터 읽기를 많이 한다면?
-> 데이터 자체를 연도-월-일의 폴더 구조로 저장
-> 이를 통해 데이터 읽기 과정을 최적화(스캐닝 과정이 줄어들거나 없어짐) & 데이터 관리도 쉬워짐(Retention Policy 적용 시)
- 굉장히 큰 로그 파일을 데이터 생성 기반으로 데이터 읽기를 많이 한다면?
DataFrameWriter의partitionBy사용- partition key를 잘못 선택하면 엄청나게 많은 파일 생성
느낀 점😊
이번 수업에서는 지금 초보자가 생각하기에는 조금 딥한 내용을 다뤘다. execution plan은 한번에 생각해내기에는 조금 시간이 걸릴 것 같다...ㅠㅠㅠ
bucketing과 file system partitioning은 정말 중요할 것 같은데 이번에 최종 프로젝트에서 꼭 사용해보고 싶다!

데이터 엔지니어를 꿈꾸는 주니어 입니다!