
휴! 드디어 CPU Virtualization 파트를 끝마치고 Memory virtualization 파트로 넘어왔다.
과제로 나온 TLB 분석 문제에서 막혀버려서 ㅠ 얼른 복습해서 다시 따라잡아야겠다.
13.1. Early Systems

메모리의 관점에서 초기의 컴퓨터는 사용자에게 지금처럼 다양한 추상화 기법을 제공해주질 않았다. 왜냐? 물리적인 메모리 구조 자체가 위에서 보다시피 꽤 단순했기 때문이다. 컴퓨터라는게 나온지 얼마 되지도 않았고.
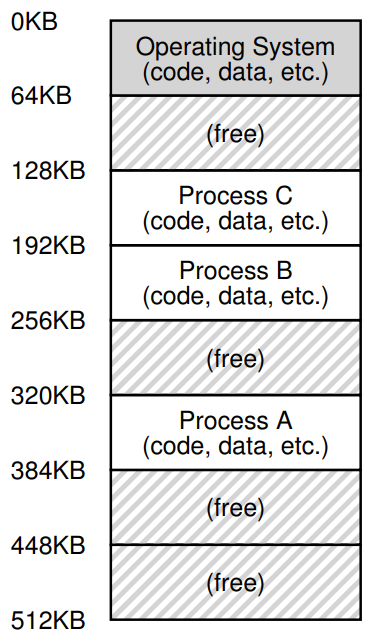
좀 자세히 살펴 볼래도, 그냥 OS(사실 이때는 이것저것 기능을 가져다 쓰기 위한 library 수준이긴 하지만)가 물리 주소 0번부터 일정 부분을 점유하고 있고, 현재 실행중인 프로그램이 그 뒤를 이어서(여기서는 64K) 메모리에 상주하고 있을 뿐이다. 이때만 했어도 사용자가 OS에게 그다지 많은 것들을 바라질 않았기 때문에 이정도로도 충분했다.
13.2. Multiprogramming and Time Sharing
이때 다수의 프로세스들이 실행되기를 기다리고 있으면 OS가 번갈아가며 이 프로세스들을 실행해주는 원시적인 Multiprogramming 기법이 탄생했는데, 예를 들어 어떤 프로세스가 I/O에 들어가면 다른 프로세스가 CPU를 사용할 수 있도록 전환해주는 식으로, CPU의 이용률(Utilization)이 크게 증가되었다.
좀 더 시간이 흐른 뒤에는 이걸로는 부족했다. 그래서 Time-Sharing 기법이 나왔다.
이때는 프로세스가 실행되다가 다른 프로세스에게 실행권을 넘겨줄 때, 그냥 중단 시점의 모든 상태(레지스터, 메모리, ..)를 디스크에 통째로 저장하고 디스크로부터 다음으로 실행할 프로세스의 상태를 또 통째로 복원하는 식으로 작동했는데, 레지스터야 원래 빠르게 만들어지기도 했고 갯수도 정해져 있었으니 딱히 문제가 없었지만 메모리를 이런 식으로 우루루 저장하고 우루루 복원하다보니 메모리가 커질수록 Context switching이 엄청 느려졌다.
느린건 둘째치더라도, 이전에는 프로그램 하나만 컴퓨터에 올려 놓고 쓰는 방식이다보니 굳이 신경쓸 필요 없었던 메모리의 Protection 역시 새로운 문제점으로 부상했다. 카카오톡이 막 내 슬랙 메시지를 허락 없이 읽을 수 있으면 안되잖아?
13.3. Address Space
그래서 이전처럼 메모리 공간을 그냥 엄청 긴 array로만 보는게 아니라, 추상화하여 더 쉽게, 직관적으로 다룰 수 있게 하여 위와 같은 불상사가 없도록 하기 위해 고안된 것이 바로 Address Space이다.
Address space는 말 그대로 프로그램을 실행시키기 위한 모든 메모리 상태를 가지고 있는데, 프로그램의 명령어가 저장된 code 영역, 함수 Call chain, 지역 변수, 매개 변수, 반환값 등을 저장하기 위한 stack 영역, malloc()이나 new 키워드 등을 통해 메모리를 동적으로 할당하기 위한 heap 영역 등으로 구성되어 있다. 정적 변수를 저장하기 위한 data 영역도 강의 중에 살짝씩 언급되기는 하는데,, 일단은 이 세 영역만 생각해도 충분하다. 충분히 머리아프다.
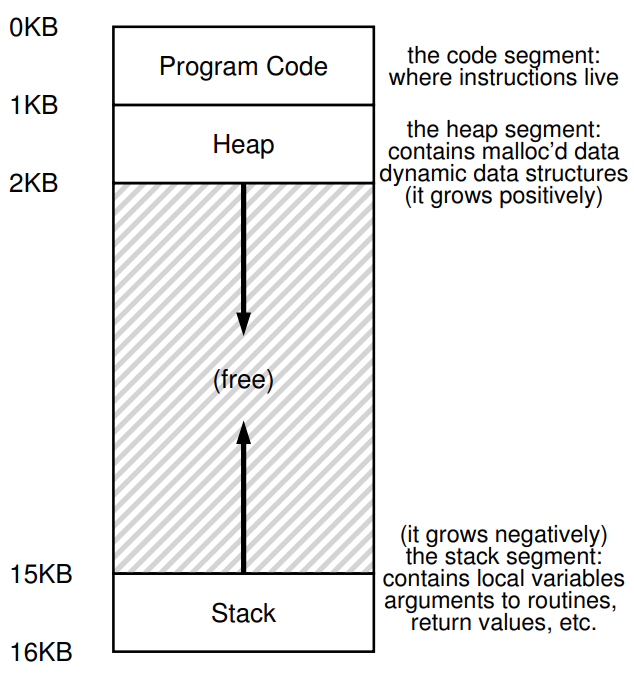
위에 16KB짜리 address space에 code, heap, stack이 배치된 모습이 그려져 있다.
여기서 code 영역이야 프로그램을 실행하는 도중에 막 늘어나거나 줄어들지 않으니 0~1KB 영역에 박아 놓은 것이고, heap을 그 아래에, stack을 address space의 끝 경계(16KB)에 배치했다.
heap은 아래로, stack은 위로 늘어나는 이 배치는 그냥 관례상 그런 것이고, 맘대로 배치해도 작동만 잘 하면 문제 없다고 한다. (강의 중에는 이런 비슷한 형태로 보통 배치한다.)
엇 그런데! 13.2의 프로세스 A, B, C가 메모리에 올라와있는 그림을 보면 위의 그림과 달리 메모리의 시작점, 끝점이 0KB, 16KB가 아니다.
기억하나 모르겠는데, 맨 첫 게시글에서 서로 다른 프로세스가 같은 메모리 주소에 접근하는 것처럼 표준 출력되면서도, 각각의 메모리에 접근하고 있는 예제를 직접 코드를 뜯어보며 확인했었다.
이처럼 실제 프로세스가 점유하고 있는 물리적인 메모리 내에서의 위치는 다르지만, 마치 프로세스가 시스템의 메모리 전체를 독점하고 있는 것처럼, 다른 프로세스가 없는 것처럼 착각하도록 하되 다른 프로세스의 메모리에 침범하지 않고 자기에게 주어진 물리적 메모리 공간에만 접근할 수 있도록 하는 이 기술을 Memory virtualization이라 부른다.
13.4. Goals
이 Memory virtualization이 달성해야 할 세부적인 목표는 무엇일까?
1. Transparency
나는 투명성이라 하면 유리창을 사이로 안팎이 훤히 보이는 그런 이미지부터 떠오르는데, 여기서의 투명성은 다른 의미이다.
"The OS should implement virtual memory in a way that is invisible to the running program."
그러니까 여기서의 투명성은 프로세스가 Virtual memory 밑에 깔려 있는 Physical memory layer를 훤히 볼 수 있다는 의미가 아니라, virtualization이라는 것 자체가 투명화되어 프로세스가 전혀 알아챌 수 없도록 해야 한다는 의미이다.
프로세스는 이 가상화 작업이 일어나고 있다는 것을 모르기 때문에, 자기 자신이 시스템 전체의 메모리를 몽땅 소유하고 있는 것처럼 행동할 수 있음을 보장해야 한다. 이때 생기는 메모리 공유라던지, 주소 변환 같은 이슈는 OS와 HW가 물 밑에서 열심히 작업하는 거고.
2. Efficiency
아까 초창기 Time-sharing 방식이 적용된 시스템에서 Context switching시 메모리 상태까지 몽땅 저장/복구하는 탓에 프로그램이 커질수록 switching 비용이 가파르게 높아지는 극단적인 예시를 살펴보았다. OS는 Memory virtualization 과정을 위해 시공간 양쪽 측면에서 효율적인 방법을 채택해야 한다.
뒤에서 이 시공간상의 효율성에 대한 논의를 아주아주 자세히 해볼 것이다. 요즘 배우고 있는 TLB랑, Paging, Segmentation, 등등... 질리도록,, 배우게 될 것이다,, 아주,,,
3. Protection
개념은 참 쉽다. 각각의 프로세스 사이에 메모리 접근이 불가능하도록 고립시켜야 한다는 건데, 이게 지켜지지 않으면 막 카카오톡이 슬랙 메시지 몰래 훔쳐보는 그런게 된다는 것이다.
마무리
어휴! 오늘 Advanced paging까지 공부했는데 진짜 퀴즈 역대급으로 어려웠다.
그래서 그런가,, 기운이 안나,, 컴퓨터 네트워크 공부하고 과제하고 얼른 자야겠다. 나머진 내일~~
