
이번 장에서는 Lock에 대해 좀 더 자세히 공부해볼 것이다. 어우 말만 들어도 손이 다 떨린다.
Lock은 무엇인가. 말 그대로 '잠그는 무언가'라고 할 수 있겠다. 그럼 뭘 잠그느냐?
Lock은 코드의 특정 영역을 감싸서 한 순간에 오로지 한 스레드만 이 영역에 접근할 수 있도록 해주는 것, 즉 Mutual Exclusion을 위해 존재한다.
이 Lock이 없으면 우리가 작성한 Multi thread program이 제대로 예상한대로 작동하지 않을 가능성이 높다. 첫째로 우리는 그냥 C언어 명령어 한 줄을 쓰는 것 같은데 그걸 번역(컴파일)하면 여러 줄의 기계어 명령어로 번역되기 때문이며, 둘째로는 그걸 알면서도 여러 줄의 C언어 코드들을 한 순간에 한 스레드만 접근할 수 있도록 보장해야 할 때가 있기 때문이다.
28.1 Locks: The Basic Idea
Atomic하다고 생각했으나 그렇지 않은 예시로 계속 balance = balance + 1;을 들고 있는데, LOAD, ADD, STORE의 세 기계어 명령어로 구성된 이 연산을 수행할 때 다른 스레드가 중간에 끼어들지 못하도록 막으려면 (개념적으론) 아래와 같이 작성하면 된다.
lock_t mutex; // some globally-allocated lock ’mutex’
...
lock(&mutex);
balance = balance + 1;
unlock(&mutex);별거 없다! lock으로 사용할 mutex를 초기화하고, 그냥 atomic하게 실행할 영역을 lock과 unlock으로 감싸주었다.
이전 장에서 다 설명했던 내용인데 한 번 더 들춰보자면, lock이 걸려 있지 않은 상태(available = unlocked = free = idle)라면 해당 lock에 접근한 스레드가 lock의 owner가 되어 걸어 잠가(= locked = acquired = busy) 다른 스레드가 접근할 경우 이 뒤의 영역으로 접근할 수 없도록 막고, lock owner가 볼일을 다 보고 나면 그때 기다리고 있던 스레드가 lock을 얻어 critial section에 진입하는 구조이다.
이건 뭐,, 이전 장에서 구구절절 설명했던 내용이라 더 자세히 쓰지는 않겠다.
28.2 Pthread Locks
28.1의 예제 코드는 좀 추상화된 것이고, POSIX에서는 아래와 같이 사용해야 한다.
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
Pthread_mutex_lock(&lock); // wrapper; exits on failure
balance = balance + 1;
Pthread_mutex_unlock(&lock);POSIX에서는 여러개의 lock이 필요한 경우 위와 같이 PTHREAD_MUTEX_INITIALIZER를 사용해 mutex를 여러 번 선언할 수 있게 구현해 두었는데, 이런 방법을 fine-grained approach라 한다.
말고도 시스템에 따라 하나의 Global lock을 두고 모든 critical section에서 돌려 쓰는 방식인 coarse-grained locking strategy라는 것도 있다고 한다. 지금이야 락 하나만 있어도 충분할 것 같은데, 뒤에서 배울 여러 복잡한 문제들을 세밀하게(fine-grained) 해결하기 위해서는 여러 개의 락이 꼭 필요할 것이다.
28.3 Building A Lock
여기서 끝내면 좋겠지만? 실제로 Lock을 구현하기 위해서 어떤 것들이 필요한지 생각해보아야 한다. 어려운 내용이지만 되게 흥미로우니까 천천히 읽어보면 좋겠다.
이전에 Virtualization을 구현할 때 그랬던 것처럼 Lock을 구현하기 위해 하드웨어/소프트웨어적으로 어떤 요소들이 필요한지 나누어서 생각해볼 것이고, 이렇게 구현된 Lock의 효율성을 여러 관점에서 평가해보기도 할 것이다.
28.4. Evaluating Locks
![]()
뭐든 대충 만드는건 쉽지만, 잘 만드는건 항상 어렵다. 그리고 잘 만들어진 작품에는 항상 이유가 있다!
잘 만들어진 Lock은 아래 세 조건을 만족해야 한다.
1. Mutual Exclusion
Lock의 뼈대가 되는 요소이다. 같은 자원에 여러 스레드가 접근하려고 시도할 때 딱 하나의 스레드만 안전하게 접근할 수 있도록 막아주지 못한다면,, 효율성이고 나발이고 애초에 Lock으로써 실격이다.
2. Fairness
Virtualization과 같은 맥락으로 Lock에서도 starvation, 그러니까 기아 상태가 발생할 수 있다.
드럽지만 이만한게 없는 것 같아서 또 화장실을 예로 들어보면, 잠긴 문 앞에서 기다리고 있는데 문이 열릴 때마다 누가 자꾸 뛰어들어가서 문을 잠가버리는 상황 정도 될 것 같다. 한 번도 힘든데 이게 한 여섯시간 반복된다,,? 어우
3. Performance
기본적인 역할도 잘 수행하고, 일도 공정하게 처리해주지만 어쨌든 느려터진 시스템은 빨리빨리가 디폴트인 조선땅에서는 살아남을 수 없다.
즉, Lock은 세가지 측면에서 효율적이어야 한다.
- 첫째로 Lock/Unlock 연산 자체도 공짜로 뚝딱 되는 것이 아니기 때문에 여기에 들어가는 비용을 최소화해야 하며,
- 둘째로 하나의 CPU만 있는 상황에서 race condition이 발생했을 때 이를 처리하는데 들어가는 비용을 최소화해야 하고,
- 나아가 여러 개의 CPU가 있는 상황에서 race condition을 처리하는데 들어가는 비용까지 최소화되어야 좋은 Lock이라고 할 수 있겠다. 벌써 막 지끈지끈하지?
28.5 Controlling Interrupts
좋다! 이제 여러 형태의 Lock 구현 방법을 하나씩 살펴보자.
컴퓨터가 나온지 얼마 안됐을 때의 단일 프로세스 시스템(한 번에 하나의 프로세스만 실행할 수 있는 원시적인 시스템)에서는 아예 아래와 같이 Interrupt를 켜고 끄는 방법으로 Lock을 구현했다.
void lock() {
DisableInterrupts();
}
void unlock() {
EnableInterrupts();
}캬 롸끈하다! lock은 그냥 누구도 간섭할 수 없도록 interrupt 기능을 통째로 꺼버리고, unlock은 다시 interrupt 기능을 켜서 구현해 놓았다.
너무 화끈해서 꺼림칙하긴 한데, Race condition이 발생하는 근본적인 이유에 대해서 다시 한 번 생각해볼 수 있다는 측면에서 유의미하다. 애초에 interrupt가 발생했기 때문에 다른 스레드로 자원에 대한 접근 권한이 넘어간 것이니 interrupt 자체를 막아버리자는 접근. 단순하고 강력하지 않은가?
그런데 뭔가 뭉툭한 느낌이 든다. 단점을 하나씩 까보자.
1. 뭘 믿고?!
초반부에서 그냥 일반적인 프로세스한테 넘겨주면 안되는 기능들은 privileged mode로, 그렇지 않은 기능들은 user mode로 접근할 수 있도록 해야 한다고 했었다.
Interrupt를 켜고 끄는 기능도 privileged mode로 취급되어야 하는데, 만약 아무나 이 기능에 접근이 가능하다면 스케줄링 되자마자 바로 lock을 걸어서 아무도 interrupt할 수 없게 만들면 OS 자체가 무용지물이 되어버릴 수 있다. 그렇기에 이런 방법은 무조건 프로세스를 신뢰할 수 있는 OS 내부에서나 가능한 방법이다.
2. 엥? 여기는 열려있는디?
또한 CPU가 여러개이면 이런 방법이 소용이 없다. Interrupt가 CPU 단위로 걸리기 때문인데, CPU 1에서 특정 자원에 접근하기 위해 프로세스 1이 interrupt를 꺼버린다고 해도 CPU 2에서 같은 자원에 접근하려는 프로세스 2가 실행된다면 옆문으로 빠져 나가듯이 실행될 수 있으므로 이러한 기법이 유효하지 않다.
3. 구려!
이건 논리적으로 유추할 수 없었던 부분인데, 일반적인 명령어에 비해 interrupt를 켜고 끄는 명령어 자체가 요즘 나오는 CPU에서는 굉장히 느리다고 한다. 구려!
28.6 A Failed Attempt: Just Using Loads/Stores
ㅇㅋ Interrupt를 단순히 막는 것만으로는 해결이 안된다는 것을 알았으니까, 이번엔 좀 다른 시도를 해보자.
- boolean type의 flag 변수를 하나 두고, 기본값을 0으로 한다.
- lock을 얻으려 하는 시점에 flag 값이 0이면 lock이 idle(free)하므로 값을 1로 바꾸어 해당 스레드 혼자만 critical section에 진입할 수 있도록 한다.
- flag 값이 1이면 누군가 lock을 사용하고 있는 상태이므로 해당 lock을 걸어 놓은 스레드가 unlock해줄 때까지 기다리도록 한다.
- lock을 얻은 사용자가 critical section에 해당되는 작업을 모두 마치면, flag 값을 0으로 바꾸어 다른 스레드가 lock을 얻을 수 있도록 한다.
지금까지는 뭉뚱그려서 기다린다고만 표현했는데, 지금부터 이 기다리는 상태를 spin-wait으로 가정해보자.
이름 그대로 돌면서 기다린다는 의미인데, 일종의 공회전이라고 생각하면 될 것 같다. 즉, 아무런 작업도 하지 않고 lock이 풀릴 때까지(= flag가 0이 될 때까지) 그냥 아래와 같이 기다리는 것이다.
def lock() {
...
while (flag == 1)
; // Busy waiting
...
flag = 1; // Lock Acquired!
...
}교수님께서는 이걸 Busy-wait 한다고도 표현하셨는데, 앞으로는 두 용어를 혼용해서 쓸 것이다.
'공회전'의 어감도 그렇고, flag의 값을 바꾸는 시점부터 뭔가 쎄하지 않은가? 이 방법도 두가지 문제가 있다.

그냥 단순하게 flag 변수에 대한 Load/Store만 수행해서는 위와 같은 문제 상황이 발생할 수 있다.
- Thread 1(T1)이 lock을 얻기 위해 system call
lock을 호출했다.- 현재 lock이 걸려 있는지 확인하기 위해 while문의 조건식을 평가했는데, flag의 초기값이 0이므로 while loop로 빨려들어가지 않는 것이 확정되었다.
- 그런데 이때! OS에 의해 interrupt가 발생해 Thread 2(T2)로 context switching 되었다.
- T2도 동일하게 lock을 얻으려 system call 'lock'을 호출하고,
- T1이 아직 flag를 1로 전환하지 못했기 때문에 조건식이 거짓이 되어 Busy-wait 하지 않으므로,
- 그 다음으로 넘어가 flag를 1로 바꾸어 다른 스레드가 critical section에 진입하지 못하도록 했는데?
- 또 다시 T1으로의 context switching이 발생해
- T1도 아까 하려던 작업을 마저 이어서 동일하게 수행하므로 flag를 1로 바꾼다.
이렇게 되면 결국 T1과 T2가 같은 자원에 동시에 접근하게 되므로, mutual exclusion이 지켜지지 않은 것이다.
똑똑한 친구라면 원래 lock이 없던 상황과 근본적으로 같은 이유로 문제가 발생했음을 알 수 있을텐데, 여기서는 (1) flag 값을 검사하고, (2) flag 값이 0인 경우 1로 바꾸는 작업을 atomic하게 수행하지 못했기 때문에 mutual exclusive하게 작동하지 않은 것이다.
음, 이해가 잘 안된다면,, while문 대신 if문을 넣어서 생각해본 다음 얼른 다시 while문으로 돌아와서 이어 생각해보면 좋을 것 같다.
while문도 매번 해당 라인에 도달할 때마다 조건식을 평가(=비교?) 해서 참인 경우에만 while문의 code block 안쪽의 명령어들을 실행하는건데, lock을 얻으려 기다리는 스레드가 이걸 한 번만 시도하고 바로 flag 값을 1로 바꿔주면 안되겠지? 그러니까 if문이 아니라 while문을 쓴 것이다~~ 하고 이해하면 좀 와닿을 것 같다. 뒤에서 비슷한 식의 논리 전개가 나오기도 하고.
둘째로, lock에 가로막힌 스레드가 말그대로 의미없는 공회전을 하는 것이 문제이다. 만약 싱글 코어 프로세서에서 가로막힌 스레드에게 주어진 time slice가 끝날 때까지 아~~무것도 안하고 그냥 CPU를 놀게 둔다면 그만한 낭비도 없을 것이다. 다른 방법이 필요하다!
28.7 Building Working Spin Locks with Test-And-Set
위에서 나온 lock이 idle한 경우 값을 1로 바꿔주는 작업이 atomic하게 수행되지 않았기 때문에 문제가 발생했다,, 는 말을 좀 곱씹어보면, 저 작업을 atomic하게 만들어주면 되는거 아닌가?! 하고 자연스럽게 떠올랐을 것이다.
근데 소프트웨어 입장에서는 별도의 장치 없이는 오직 기계어만이 atomic하게 실행될 수 있는 level이므로(실행되거나, 안되거나) 저 여러 줄의 명령들을 atomic하게 만들어줄 수 있는 방법이 없다. 이때부터는 하드웨어의 지원이 필요하다. 왜냐? 실행 가능한 기계어의 목록(ISA, Instruction Set Architecture)은 하드웨어가 정하는거니까!
int TestAndSet(int *old_ptr, int new) {
int old = *old_ptr; // fetch old value at old_ptr
*old_ptr = new; // store ’new’ into old_ptr
return old; // return the old value
}C언어처럼 생겼는데, 저 TestAndSet은 여러 줄의 기계어로 구성된 명령어가 아니라 그냥 사람이 보기 편하라고 pseudo code로 표현한 것이다. 그러니까 TestAndSet은 실행되거나, 실행되지 않거나의 두 가지 경우 밖에 없는 atomic한 명령어라는거지.
위의 test-and-set은 다음과 같이 작동한다.
- 비교 및 갱신할 값의 주소를 포인터로 받는다.
- 비교 및 갱신할 값만 따로 받아놓는다.
- 포인터가 가리키는 위치의 값을 new로 바꿔준다.
- 2에서 받아 놓은 값을 외부로 반환한다.
어우 뭔소린지 잘 모르겠지? 일단 하드웨어가 이 작업을 지원해준다고 생각하고 Lock을 대강 구현해보자.
typedef struct __lock_t {
int flag;
} lock_t;
void init(lock_t *lock) {
// 0: lock is available, 1: lock is held
lock->flag = 0;
}
void lock(lock_t *lock) {
while (TestAndSet(&lock->flag, 1) == 1)
; // spin-wait (do nothing)
}
void unlock(lock_t *lock) {
lock->flag = 0;
}이전의 코드와 딱히 달라진게 없다! 다만 이젠 TestAndSet에서 원자적으로 아래의 작업을 수행하고 있다.
- flag 값을 확인해서 만약 0인 경우 한방에 flag가 1로 갱신되고(acquired) TestAndSet도 맨 처음에 가져다 놓은 값인 0을 반환하므로 바로 while문을 빠져나온다. (0 != 1)
- flag 값을 확인해서 만약 1인 경우 flag를 1로 (무의미하게) 갱신하고, TestAndSet이 갱신 전의 flag 값에 해당되는 1을 반환하므로 loop를 다시 한 번 돈다. (1 == 1)
즉, 검사하고(test) 갱신해주는(set) 작업을 atomic하게 실행해주기에 이러한 구현이 유효함을 알 수 있다.
단 우리가 지금까지 interrupt의 존재를 너무 당연하게 생각해서 쉽게 넘어갈 수 있는 부분인데, 우리가 상정하고 있는 OS가 Preemtive scheduling 정책을 따르고 있기 떄문에 위와 같이 구현해도 문제가 없는 것이다.
이는 만약 OS가 실행되고 있는 스레드의 실행을 임의로 멈추어 다른 스레드에게 내어줄 수 없다면 먼저 lock을 얻은 스레드가 unlock하기 전에 같은 lock을 얻으려는 다른 스레드로 context switching 했을 때 말 그대로 무한 루프에 빠져버리기 때문이다.
28.8 Evaluating Spin Locks
위에서 Test-And-Set과 Busy-waiting을 통해 Spin lock을 구현했는데, 예고했다시피 세가지 측면에서 이 lock을 평가해보겠다.
1. Mutual Exclusion
TestAndSet의 도입으로 flag 값의 비교 및 갱신이 atomic하게 수행되므로, mutual exclusion이 보장된다. 통과!
2. Fairness
그을쎄,,,, 만약 T1이 Lock을 얻고 T2가 이걸 기다리는 상황인데, 운나쁘게 T1이 unlock할 때쯤에 같은 lock을 얻으려는 스레드가 계속 새치기를 해버리면 T2는 lock을 오랜 시간 동안 얻지 못하는 starvation 상태에 빠질 수도 있다. 탈락!
3. Performance
CPU가 하나인 경우 아까 얘기했다시피 lock을 얻지 못한 스레드가 계속해서 무의미한 busy waiting을 하기 때문에 그 time slice의 합만큼 CPU가 놀게 된다. 탈락!
반면 CPU가 여러 개인 경우 나쁘지 않게 작동할 가능성이 높다.
CPU 1에서 T1이 먼저 lock을 얻어 놓은 상태에서 CPU 2에 T2가 실행되어 lock을 얻으려 busy waiting을 하는 상황을 가정해보자. 이때 T1의 critical section이 짧기만 하다면 T2가 대기하는 시간은 그만큼 줄어들게 된다. 그림으로 볼까?
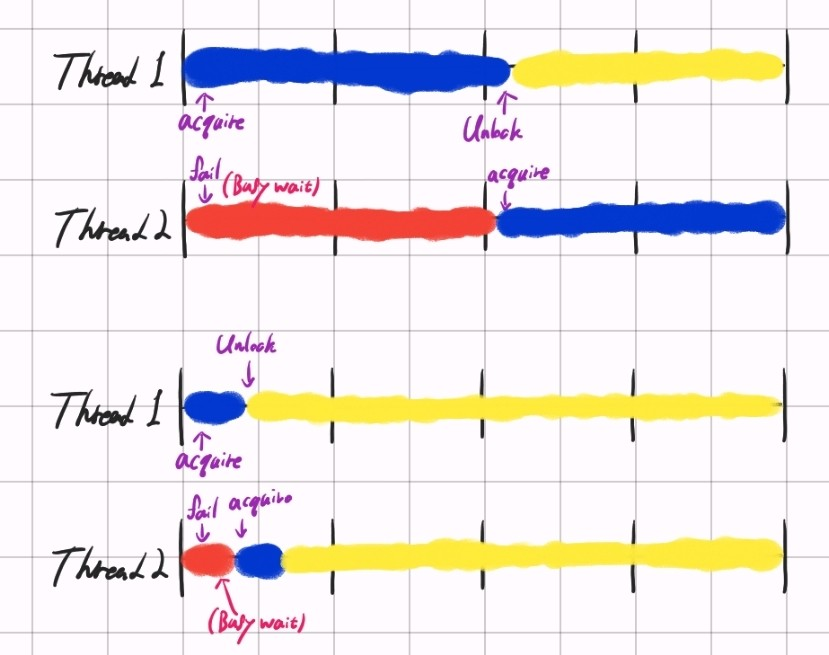
어우 그림 참 못그렸는데,, 파란색은 critical section, 빨간색은 busy waiting, 노란색은 병렬 실행이 가능한 부분이다.
위의 경우 critical section이 길어서 무지막지하게 많이 기다려야 하는 반면, 아래의 경우 critical section이 짧아 이것만 지나면 오래오래 병렬 실행이 가능하기 때문에 CPU가 상대적으로 적게 놀고 있음을 알 수 있다.
28.9 Compare-And-Swap
TestAndSet 말고 다른 하드웨어 명령어로 lock을 구현할 수도 있다.
int CompareAndSwap(int *ptr, int expected, int new) {
int original = *ptr;
if (original == expected)
*ptr = new;
return original;
}위의 CompareAndSwap도 TestAndSet과 마찬가지로 pseudo code로 표현했을 뿐 atomic하게 실행되는 기계어 명령임을 잊지 말자! 이 명령어는 다음과 같이 작동한다.
- TestAndSet과 마찬가지로 검사할 값을 가리키는 주소를 포인터로 넘겨받는다.
- 이 포인터가 가리키는 곳의 값을 읽어 놓는다.
- 만약 이 값과 expected의 값이 같다면, 그 위치에 new를 쓴다.
- 2에서 읽어 놓은 값을 반환한다.
이것도 이렇게만 보면 어떻게 돌아가는건지 전혀 모르겠지? lock에선 어떻게 사용될 수 있는지 살펴보자.
void lock(lock_t *lock) {
while (CompareAndSwap(&lock->flag, 0, 1) == 1)
; // spin
}뭐,, lock의 attribute로 flag를 넣어주는 부분, init, unlock 부분은 모두 같아서 lock만 따로 써주었나보다.
위의 코드는 아래와 같이 작동한다.
- flag의 값이 0인 경우, expected에 해당하는 값 0과 같으므로 flag 값을 1로 갱신해준 뒤(acquired) 이전에 flag에서 읽어 놓은 0을 반환하여 while문에 빠지지 않는다. (0 != 1)
- flag의 값이 1인 경우, expected에 해당하는 값 1과 다르므로 flag 값을 (무의미하게) 1로 갱신해준 뒤 이전에 flag에서 읽어 놓은 1을 반환하여 다시 조건식을 검사한다. (1 == 1)
TestAndSet과 비교했을 때 인자 expected와 조건문이 하나 더 들어가 있음을 알 수 있다. 변수가 하나 더 늘었으니 TestAndSet보다는 조금 더 복잡한 일을 수행할 수 있겠지? 물론 TestAndSet 대신에 저 구현을 가져다 사용하는 입장에서 볼 때는 이전과 완전히 동일하게 작동한다.
28.10 Load-Linked and Store-Conditional
이번엔 두 개의 명령어로 lock을 구현해보자.
엥? 여태까지 lock을 얻는 과정이 atomic하지 않아서 고생고생 생고생을 했는데 두개로 늘린다고?
int LoadLinked(int *ptr) {
return *ptr;
}
int StoreConditional(int *ptr, int value) {
if (no update to *ptr since LoadLinked to this address) {
*ptr = value;
return 1; // success!
} else {
return 0; // failed to update
}
}위 명령어는 앞서 소개한 명령어들과 마찬가지로 기계어 instruction이므로 atomic하다. 이하 생략!
LoadLinked가 별도의 설명도 없고 pseudo code로 쓰여 있어서 단번에 이해가 잘 안되었는데, 그냥 메모리 위에 있는 값을 레지스터에다가 읽어 오는 역할만 한다고 한다.
StoreConditional은 아래와 같이 작동한다.
- 검사할 값의 포인터를 전달받는다.
- 이 포인터를 통해 LoadLinked가 메모리에서 레지스터로 값을 읽어들인 이후로 아무도 값을 갱신하지 않았을 경우에만 ptr이 가리키는 위치에 value를 써주고 1을 반환한다.
- 만약 레지스터로 값을 읽어들인 이후로 값이 갱신되었다면, ptr이 가리키는 위치의 값은 그대로 두고 0을 반환한다.
어우 이걸 어떻게 쓴다는거약! 코드로 보자.
void lock(lock_t *lock) {
while (1) {
while (LoadLinked(&lock->flag) == 1)
; // spin until it’s zero
if (StoreConditional(&lock->flag, 1) == 1)
return; // if set-it-to-1 was a success: all done
// otherwise: try it all over again
}
}
void unlock(lock_t *lock) {
lock->flag = 0;
}정리하자면,,
- LoadLinked를 통해 값을 메모리에서 레지스터로 읽어들이는데, 이때 읽은 값이 1이면 다른 스레드가 lock을 걸어 놓은 것이므로 여기서 busy waiting을 하고 0이면 idle한 상태이므로 단계 3으로 넘어간다.
- 이때 단계 1에 해당하는 while문과 if문 사이에서 context switching이 발생해 다른 스레드가 flag를 갱신해버릴 수도 있다. 기억해두자.
- 여기로 넘어왔다는 것은 flag가 0으로 읽혔다는 의미인데, 그 사이(2)에 다른 스레드에 의해 값이 1로 바뀌어 lock이 걸려버리면 0을 반환하므로 다시
while (1)로 돌아가 처음부터 lock을 얻으려 시도한다.- 만약 단계 2가 없어 아직도 flag가 0으로 남아 있다면? flag를 1로 바꿔 lock을 얻은 뒤 1을 반환하는 작업을 StoreConditional이 atomic하게 수행하여 lock을 얻고 return하게 된다.
캬. 오묘하지 않은가? 이해하느라 머리털 다 빠지는 줄 알았다.
28.11 Fetch-And-Add
하드웨어의 지원을 통해 lock을 구현하는 마지막 방법이다.
int FetchAndAdd(int *ptr) {
int old = *ptr;
*ptr = old + 1;
return old;
}위의 코드는 아래와 같이 작동한다.
- ptr이 가리키는 값을 읽어와서,
- 여기에 1을 더해 갱신해주고
- 이전에 읽어온 값을 반환한다.
으잉? 뭔가 되게 씨잘데기 없는 명령어같은데 이걸 사용해서 Ticket lock이라는 것을 구현할 수 있다.
typedef struct __lock_t {
int ticket;
int turn;
} lock_t;
void lock_init(lock_t *lock) {
lock->ticket = 0;
lock->turn = 0;
}
void lock(lock_t *lock) {
int myturn = FetchAndAdd(&lock->ticket);
while (lock->turn != myturn)
; // spin
}
void unlock(lock_t *lock) {
lock->turn = lock->turn + 1;
}오,, 이전보다 뭔가 더 복잡해졌다. 여기선 라인 단위로 보지 말고 왔다갔다 하면서 보는 편이 좋겠다.
일단 여기서 ticket과 turn의 의미를 먼저 알아야 하는데, 각각 내가 받은 표와 차례가 된 표 정도로 생각해도 충분하다.
음, 은행에 일이 있어서 방문했다고 생각해보자. 가장 먼저 뭘 해야 할까?
교양있는 현대인이라면 응당 번호표부터 뽑아야할 것이다. 번호표를 주는 쪽은 당연히 은행(에 딸린 기계)일 것이고, 은행측은 고객 한 명을 처리할 때마다 번호를 1씩 올려가며 다음으로 처리할 고객을 불러줄 것이다.
위의 알고리즘도 비슷하게 작동한다!
여기서는 ticket과 turn을 0으로 초기화 해주었으므로 번호표가 0부터 시작하는데, lock을 요청할 경우 int myturn = FetchAndAdd(&lock->ticket); 명령어를 통해 myturn에 현재 기계 맨 끝에 걸쳐져 뽑히기를 기다리고 있는 0번 표를 쥐어주고, 다음으로 발급해줄 번호를 하나 올려 ticket에 갱신해준다. 비유하자면 이번엔 1번 표가 기계 끝에서 뽑히기를 기다리고 있는 상황이라 할 수 있겠다.
그 다음 while문에서는 현재 처리할 차례가 온 번호(lock->turn)와 내가 뽑은 번호가 같은지 확인하여, 같을 경우 while문을 빠져 나와 일을 보고(lock) 다를 경우 내 차례가 올 때까지 계속 기다린다. 운이 좋아서 앞에 대기하고 있던 사람이 없으면 바로 일을 볼 수 있고, 그렇지 않으면 계속(while) 기다려야 할 것이다.
일을 다 본 후에는 어떻게 해주어야 할까? 다음 사람이 일을 보아야겠지?
은행에서 번호표 숫자를 1씩 올려가며 다음 고객을 부르는 것과 같은 원리로, 현재 처리할 차례를 의미하는 lock->turn에 값을 1만큼 더해 대기하고 있던 다음 스레드가 critical section에 접근할 수 있도록 해준다. 신기하지 않은가?!
음 아님 말구,,
이제 이 ticket lock을 평가해보자.
mutual exclusion은 hw의 도움을 통해 다른 방법들도 만족했고, 성능은,, busy waiting으로 인해 아직 (특히 Unicore에서) 나쁘지만 fairness만큼은 개선되었다 볼 수 있겠다.
이는 곧 starvation이 해결되었다는 의미인데, 번호표를 발급받은 순서대로 critical section에 접근하기 때문에 중간에 다른 스레드가 lock을 얻으려 해도 무조건 줄을 서야 하기 때문이다. 공정하다!
28.12 Too Much Spinning: What Now?
Mutual exclusion은 지금까지 배운 모든 방법들이 만족하고 있고, fairness는 방금 배운 ticket lock이 해결했다. 그럼 이제 남은건 performance뿐인데, 배운 방법들 모두 busy waiting으로 인한 낭비가 발생하고 있어 해결이 필요하다.
어우 그나저나 이번 챕터가 유난히 긴 것 같지 않은가?
잠깐 허리도 좀 펴고, 기지개도 켜자. 안아파야 오래 공부하지!
More reson to avoid spinning: Priority Inversion
Spinning으로 인한 낭비를 해결하기 이전에, spinning으로 인해 발생하는 또 다른 문제를 하나 짚어보고 넘어가려고 한다.
Scheduling되는 서열을 정하는데 사용되는 우선 순위(priority)가 각각의 스레드에 부여되었다고 가정해보자. 즉, T1의 우선 순위가 T2의 우선 순위보다 낮은 경우 T1이 실행되고 있는 도중에 T2가 시스템에 도착하면 preemtion으로 인해 T2가 실행된다는 의미이다.
이때 우선 순위가 높은 T2가 I/O 요청을 하면 우선 순위와 무관하게 T2가 sleep 상태에 들어가므로 T1이 실행될 수 있게 되는데, T1이 여기서 lock을 걸어버리면 T2가 I/O를 마치고 ready 상태로 돌아오는 순간 T2의 우선 순위가 더 높으므로 T2가 스케줄링될 것이다.
이때 문제가 발생하는데, T1은 우선 순위가 낮아 T2가 시스템에 남아 있는 동안은 unlock할 수 없는 상황이 되었고, T2는 T1이 unlock을 해주질 않으니 끝없이 busy waiting만 하는, Deadlock이 발생하게 된다.
그럼 T2가 한 번에 lock을 얻지 못하고 busy waiting을 하는 것을 감지할 경우 time slice가 끝났을 때 ready가 아니라 block 상태로 잠들어 T1이 얼른 critical section을 끝내고 unlock해줄 수 있도록 해결하면 되지 않을까?
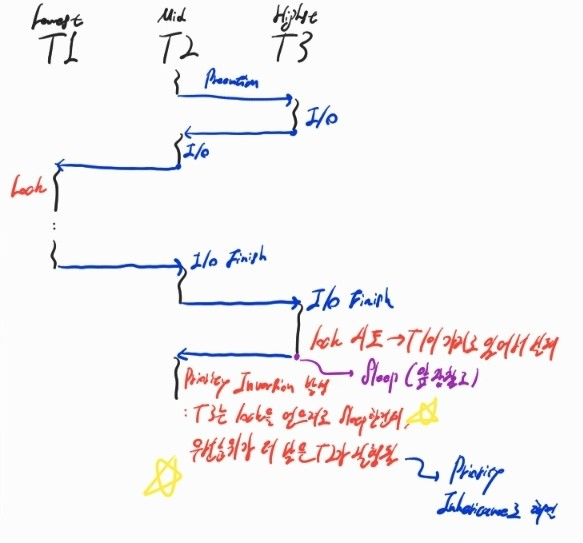
이 방식이 스레드가 2개일 때는 유효한데, 그 이상으로 넘어가면 그렇게는 해결할 수가 없다.
위와 같이 T1, T2, T3의 순서대로 스레드의 우선 순위가 높은 상황을 가정해보자.
아까와 마찬가지로 우선순위가 낮은 T2가 실행되고 있는 도중에 T3가 들어와 preemtion으로 인해 T3가 잠깐 실행되던 중 I/O가 발생하는 것까지는 동일하다.
그런데 시스템에 T2보다 우선 순위가 낮은 T1이 T2에 밀려서 실행되지 못하고 있었고, T2마저 I/O 요청으로 인해 block되어 T1이 실행되는 도중에 T1이 lock을 걸어버리면?
T3 -> T2 순서대로 깨어나는 경우 아까 제시한대로 한 번에 lock을 못얻었음을 감지하면 다시 sleep 상태로 들어가는 방법으로 해결할 수 있겠지만 T2 -> T3 순서대로 깨어나는 경우 위와 같은 문제가 발생하게 된다.
보다시피 T2가 깨어나면 T2가 T1보다 우선 순위가 높기 때문에 preemtion이 발생하여 T2가 실행되고, 이어서 T3가 깨어나서 만약 T1이 걸어 놓은 lock에 접근하려고 하면 lock을 얻는데 실패하기 때문에 바로 T3가 잠이 들어버린다.
그럼? 시스템에서 우선 순위가 가장 높은 T2가 이어서 스케줄링되므로 아까와 마찬가지로 T3보다 T2가 먼저 실행되는 Priority inversion이 발생한 것이 된다!
이 머리 복잡해지는 난제는 Priority inheritance를 통해 해결해줄 수 있다.
말 그대로 우선 순위를 상속해준다는 의미인데, 상속보다는 잠시 빌려준다고 이해하는게 더 좋은 표현 같다.
위의 상황에서 T3가 T1이 걸어놓은 lock을 요청했다가 실패하면 sleep하는건 똑같은데, unlock해주어야 하는 대상 스레드인 T1에다가 잠시 T3의 우선 순위를 빌려주어 T3가 잠들어도 일시적으로 T2보다 T1이 먼저 실행되도록 하는 것이 바로 priority inheritance이다!
그럼 T1이 T2보다 항상 먼저 실행되므로 unlock까지 안전하게 도달하고, unlock과 함께 T3로부터 받은 priority를 내려놓고 T3를 깨워주면? 이젠 의도한대로 T2가 T3에 밀려 T3가 먼저 실행된다.
정리해보자, Spinning과 Non-spinning의 성능 측면에서 가장 결정적인 차이를 만드는 요소는 무엇일까?
CPU를 점유하고 있느냐, 그렇지 않느냐 정도가 될 것 같다. 할 수 있는 것도 없으면서 스케줄러의 선택을 받아 무의미한 busy waiting을 하고 있어 그 자체로 낭비일 뿐더러 애써 정해놓은 priority가 역전되는 상황이 발생할 수 있다는 것이다.
28.13 A Simple Approach: Just Yield, Baby
첫째로, 내가 CPU를 알뜰하게 사용할 것도 아닌데 계속 쥐고 있는 것이 문제라면 그냥 공회전을 하지 말고 아예 다른 스레드가 사용할 수 있도록 양보하는 방법이 있다.
void init() {
flag = 0;
}
void lock() {
while (TestAndSet(&flag, 1) == 1)
yield(); // give up the CPU
}
void unlock() {
flag = 0;
}가장 간단한 TestAndSet을 활용했다. 달라진 부분이라면 lock()에서 lock을 얻지 못하는 경우 얻을 때까지 공회전을 하는게 아니라, yield()를 통해 바로 다른 스레드에게 양보해버리고 있다.
여기서 양보란 프로세스의 status와 마찬가지로 스레드에도 running-ready-blocked의 세 status가 있는데, running 중인 이 스레드가 lock을 얻지 못하자 다른 스레드가 스케줄링 될 수 있도록 ready 상태로 전환되는 것을 의미한다.
스레드가 2개정도면 뭐, lock을 얻지 못하는 스레드가 스케줄링 되자마자 바로 critical section을 처리하는 스레드에게 사용권을 양보해서 빨리 lock을 받을 수 있도록 참는 꼴이므로 납득할 수 있다.
근데 스레드가 100개쯤 되면 얘기가 달라진다. 누누히 얘기했지만 context switching 자체도 비용이 들어가는 작업이기 때문에 단 1개의 lock을 얻은 스레드를 제외한 나머지 99개의 스레드들이 차례대로 스케줄링 되자마자 yield로 양보하는 작업을 수행한다면 어떨까?
한두개는 괜찮은데 스레드가 많아지면 많아질수록 이 과도한 context switching 비용이 꾸준히 쌓여 결과적으론 큰 낭비가 된다. 심지어 Round robin 방식과 같이 fairness가 보장되지 않는 scheduling policy를 사용한다면 최악의 경우 먼저 lock을 기다리고 있던 스레드가 다른 스레드에 계속 밀리는 starvation이 발생할 수도 있다. 탈락!
28.14 Using Queues: Sleeping Instead Of Spinning
스레드 입장에서 볼 때 시스템의 스케줄링 정책은 Black box이므로 무조건적인 yield가 그다지 좋은 방법은 아닌 것이니까, ticket lock과 비슷하게 뭔가 순서를 명시적으로 보장해주면 되지 않을까?
이러한 작업에 딱인 자료구조가 바로 Queue이다. 살펴보자.
typedef struct __lock_t {
int flag;
int guard;
queue_t *q;
} lock_t;
void lock_init(lock_t *m) {
m->flag = 0;
m->guard = 0;
queue_init(m->q);
}
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; //acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
m->guard = 0;
park();
}
}
void unlock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; //acquire guard lock by spinning
if (queue_empty(m->q))
m->flag = 0; // let go of lock; no one wants it
else
unpark(queue_remove(m->q)); // hold lock
// (for next thread!)
m->guard = 0;
}뭔가 무시무시하게 생겼는데,,
아 일단, park()는 해당 system call을 호출한 스레드를 재우는 함수이고, unpark(queue_remove(m->q))는 인자로 전달된(deque된) 스레드를 깨우는 함수이다. 이때 큐에서 빠져 나오는 값은 threadID이므로, 이는 곧 해당 ID가 가리키는 스레드를 깨우는 것이다.
lock부터 뜯어보자!
처음 보는 변수인 guard가 바로 눈에 들어오는데, 이것도 일종의 flag이다.
다만 lock을 얻으려는 스레드 사이의 race condition을 정리해주기 위한 flag가 아니라, lock과 unlock 작업 자체를 atomic하게 수행하도록 만들어주기 위한 flag라고 생각하면 된다.
즉, 여태껏 봐왔던 flag와 마찬가지로 guard 값이 0이면 idle한 상태이므로 atomic하게 lock을 걸어 critical section에 진입하고, 그렇지 않은 경우 이전과 마찬가지로 busy waiting을 하게 된다.
으잉? 지금 busy waiting을 없애보겠다고 queue니 뭐니 이것저것 새로 붙이는거 아닌가?
맞다! 대신 이건 경우가 좀 다르다. 우린 지금 OS 내부에서 사용될 lock을 구현하고 있으므로 이건 client가 아니라 커널 내부에서 사용될 코드를 짜고 있는 것이다.
따라서 critical section의 길이를 일정하게, 가능하다면 최대한 짧게 유지하는 것(커널 코드는 우리가 미리 짜놓는 것이니까)이 가능하기 때문에 이정도의 낭비는 필수적인 것으로 보고 그냥 너그러이 넘어갈 수 있는 것이다. 맘에 안들면 새로 짜보던가?!
다시 돌아와서, guard가 풀려 있어서(0) 내가 열고 들어간 다음 잠가버린(1) 상황을 가정해보자.
여기서부터는 이전까지 봐왔던 flag의 조작과 거의 유사하다. 만약 flag가 0인 idle한 상황이다? 그럼 flag를 1로 만들어 해당 lock() 호출을 보낸 스레드가 mutual exclusive하게 실행될 수 있도록 보장해준 다음 다시 guard를 0으로 바꿔 다른 스레드가 lock 함수 안쪽 깊숙한 곳까지 진입할 수 있도록 만들어준다.
flag가 1인, lock이 이미 걸려 있는 상황이 좀 다른데, 냅다 lock을 얻을 때까지 공회전하거나 무작정 다른 스레드가 스케줄링 되도록 양보해버리는 것이 아니라, lock이 돌아올 때까지 기다리는 줄(Queue)에 선 다음 가드를 풀고 park()를 통해 잠들어버린다.
저 '가드를 풀고' 부분, 잘 봐두자. 미리 스포일러를 좀 해보자면 저걸 그냥 쥐고 잠들어버리는 순간 lock 함수 안쪽 깊숙한 곳까지 어떤 스레드도 도달할 수 없어 이 lock을 얻으려는 모든 스레드들이 끝나지 않는 busy waiting을 할 것이다. 이걸 Deadlock이라고 한다!
lock에서 냅다 공회전하거나 무작정 양보하는게 아니라 줄을 서고 잠을 자버린다고 했으니, unlock에선 그럼 다음으로 실행될 스레드를 찾아서 깨워주면 되는 것 아니겠는가?
이 lock/unlock을 수행하는 내부 작업들은 모두 mutual exclusive하게 작동해야 하므로 lock과 마찬가지로 guard가 다른 스레드에 의해 잠겨있다면 대기하고, 그렇지 않은 경우 본격적으로 unlock을 수행하게 된다.
이때 만약 큐가 비어있다면 이는 lock을 얻으려 줄을 서서 잠들어 있는 스레드가 하나도 없다는 의미이므로, 다른 스레드를 깨워주고 자시고 할 필요도 없이 그냥 쥐고 있던 lock을 놓아 주면 된다.
근데 큐가 비어 있지 않다면? 내가 쥐고 있던 lock을 어떤 다른 스레드가 원한다는 뜻이므로 큐의 맨 앞에서 자고 있던 스레드를 깨워줘야 한다. 그래야 언제든 스케줄링 되어서 다시 lock을 얻으려 시도할거 아니야!
큐가 비어있었든, 차있었든, 어쨌든 이제 다른 스레드가 lock이나 unlock을 수행할 수 있어야 하므로 busy waiting을 끝내주기 위해 마지막으로 guard를 0으로 만들어 풀어주면 unlock 작업까지 모두 끝나게 된다. 와!
,,와! 하기엔 아직 문제가 하나 남았다.
- lock을 얻으려는 어떤 스레드 T2가 guard가 풀리자마자 와다다 달려왔는데 이미 어떤 스레드 T1이 lock을 쥐고 있어 어쩔 수 없이 대기열에 스스로를 등록해 두는 것(enque)까지는 정상적으로 수행했다.
- 근데 이때 lock을 쥐고 있던 T1이 스케줄링 되어 unlock을 해버리면,,? 큐가 비어 있지 않기 때문에 else문으로 빠져 뭔가 일단 깨워보려고 하는데 재수없게도 큐가 원래 비어 있었어서 T2가 맨 앞에 있어 deque 및
unpark(=wake up) 되었다고 생각해보자. 이미 깨어 있는데도! - 다시 T2로 스케줄링 되어
park를 통해 잠들어버린다? 그럼 다른 스레드가 나타나든가 말든가 이미 대기열에선 빠져 버린 상태이기 때문에 이 T2를 깨울 수 있는 방법이 없어진다.
이런 문제를 wakeup/waiting race라고 하는데, Solaris에서는 이걸 setpark()를 통해 해결했다.
void lock(lock_t *m) {
while (TestAndSet(&m->guard, 1) == 1)
; //acquire guard lock by spinning
if (m->flag == 0) {
m->flag = 1; // lock is acquired
m->guard = 0;
} else {
queue_add(m->q, gettid());
setpark(); // NEW!!!!!!
m->guard = 0;
park();
}
}다른 부분은 모두 같고, queue_add와 guard 해제 사이에 setpark만 끼어들었다.
이 setpark는 park가 실제로 호출되기 전에 다른 스레드가 먼저 unpark를 호출했을 경우 이어지는 park에서 sleep하지 않고, unpark가 호출되지 않았을 경우 예정대로 sleep하는 역할을 한다.
아까와 같이 lock을 얻는데 실패해서 큐에 스스로를 등록하자마자 context switching이 발생해 lock을 쥐고 있던 스레드가 unlock 및 awake를 하는 바람에 다시 스케줄링 되어 대기열에서 빠진 상태로 잠들어버리는 상황에 setpark를 끼워 넣어 문제를 어떻게 해결할 수 있는지,, 요건 직접 그림을 그려서 꼭 추적해보기를 바란다. 그려보면 쉽다!
이외에도 guard 자체를 커널로 가져와서 관리하도록 함으로써 해결할 수도 있다는데, 이 경우 unlock과 deque 과정을 atomic하게 한 번에 처리할 수 있도록 반드시 보장해야 할 것이다.
28.15 Different OS, Different Support
리눅스에서는 Lock을 futex를 통해 지원한다.
강의 중에는 아예 하루를 몽땅 써서 설명해주실 만큼 양이 많은데,,,, thread trace까진 몰라도 코드 내용이라도 리뷰해보겠다.
void mutex_lock (int *mutex) {
int v;
/* Bit 31 was clear, we got the mutex (the fastpath) */
if (atomic_bit_test_set (mutex, 31) == 0)
return;
atomic_increment (mutex);
while (1) {
if (atomic_bit_test_set (mutex, 31) == 0) {
atomic_decrement (mutex);
return;
}
/* We have to waitFirst make sure the futex value
we are monitoring is truly negative (locked). */
v = *mutex;
if (v >= 0)
continue;
futex_wait (mutex, v);
}
}
void mutex_unlock (int *mutex) {
/* Adding 0x80000000 to counter results in 0 if and
only if there are not other interested threads */
if (atomic_add_zero (mutex, 0x80000000))
return;
/* There are other threads waiting for this mutex,
wake one of them up. */
futex_wake (mutex);
}기본적으로 각각의 futex는 독립적인 물리 메모리 공간, 그리고 커널 내부에 잠들어 있는 스레드들을 관리하기 위한 큐를 가지고 있다.
이 futex는 보다시피 주요 연산으로 futex_wait(address, expected)와 futex_awake(address)을 제공한다. 까보자!
- futex_wait(address, expected)
만약 전달된 futex의 주소(address)와 expected가 같으면 sleep하고, 그렇지 않으면 바로 반환한다.
만약 sleep했다면, 깨어나는 시점에 해당 함수가 반환된다.
- futex_awake(address)
해당 address가 가리키는 futex의 큐에 대기하는 스레드가 있다면 깨워준다.
이 futex를 사용해서 lock을 구현할 수 있다.
mutex_lock(int *mutex)
기본적으로 futex는 각각의 독립적인 물리 메모리 공간을 가지고 있다고 했는데, 이 공간에는 길이 32짜리 bit sequence가 들어있다.
이때 최상위 비트가 1이면 현재 lock이 걸려 있음을 표시하는 것이고, 0이면 lock이 걸려 있지 않음을 의미한다. 또한, 나머지 하위 31비트는 현재 lock을 얻으려는 스레드의 갯수를 2진수로 표현한 것(앞으로 count라 하겠다!)이라고 약속했다 생각하고 코드를 살펴보자.
if (atomic_bit_test_set (mutex, 31) == 0)
return;atomic_bit_test_set은 앞에서 배운 TestAndSet과 비슷하게 생각하면 될 것 같은데, 풀어서 말하자면 최상위 비트(31번째 비트)가 0이면(idle) mutex의 최상위 비트를 1로 갱신해준 다음(lock acquire) 바로 critical section으로 진입(return)하라는 의미이다.
만약 최상위 비트가 1이라면? lock을 얻으려고 계속 시도해야겠지?
atomic_increment (mutex);일단 lock을 못얻었으니 현재 lock을 얻으려 기다리고 있음을 mutex에 atomic하게 갱신하고,
while (1) {
if (atomic_bit_test_set (mutex, 31) == 0) {
atomic_decrement (mutex);
return;
}
/* We have to waitFirst make sure the futex value
we are monitoring is truly negative (locked). */
v = *mutex;
if (v >= 0)
continue;
futex_wait (mutex, v);
}
}Lock을 얻을 때까지 위 코드를 반복하면 된다.
while code block 안쪽의 코드 블럭이 좀 익숙한데, 이건 혹시라도 while문 안에 진입했을 때 unlock된걸 감지하면 바로 주워서 lock을 얻기 위함이다. 물론 lock을 얻었으니 대기하고 있는 스레드의 갯수도 하나 줄어야 하고! (atomic_decrement)
만약 그 짧은 틈새 동안 lock이 풀리지 않았다? 그럼 이제 실제 mutex 값을 읽어다가(v = *mutex) sleep할지 말지 결정하면 된다.
여기서 v >= 0은 MSB가 0, 그러니까 현재 lock을 걸어 놓은 스레드가 없음을 의미하므로 다시 루프의 맨 앞으로 돌아가 최상위 비트를 검사받고 lock을 얻으려 시도하면 된다. MSB가 1이면? v가 음수이므로 이젠 짤없이 잠들면 되는거지(futex_wait(mutex, v)).
즉, 여기서 while문은 spin wait을 위한 것이 아니라 sleep 상태로 들어가기 전에 마지막으로 한 번 더 기회를 주는,, 느낌에 가깝다고 보면 될 것 같다. 아름답지 않은가?!
(저 짧은 틈새에 v와 mutex 값이 서로 달라질만한 상황에서는 어떻게 작동해야 할지 꼭 생각해봤으면 좋겠다.)
mutex_unlock(int *mutex)
다행히도 unlock은 좀 더 단순하다.
if (atomic_add_zero (mutex, 0x80000000))
return;0x80000000은 2진수로 1000 0000 ... 0000이므로, 이 값을 atomic하게 mutex에 더했을 때 결과가 0이 되었다면 mutex의 최상위 비트가 1이었으므로 자리 올림이 발생해 최상위 비트는 0이 되고, 하위 31비트에 해당하는 count가 0인 경우에만 이 함수의 반환값이 참이 되어 바로 반환할 수 있다.
좀 더 사람에 가깝게 풀어서 해석하자면, unlock해줌과 동시에 현재 큐에서 대기중인 스레드가 있는지 확인하여 만약 없는 경우 별도의 조치 없이 그냥 unlock 작업을 마치는 것이라고 할 수 있겠다.
반면 만약 count가 0이 아니라면? 대기하고 있는 스레드가 있다는 의미이므로 unlock해주는건 물론이고 잠들어 있는 스레드 중 하나(여기서는 맨 앞)를 깨워 ready Queue로 보내주어야 한다.
28.16 Two-Phase Locks
별 내용도 없고 지금 좀 졸린지 잘 안와닿아서(...) 일단 패스.
굳이 짚고 넘어가자면 Context switching 등의 외부 요소들을 몽땅 고려했을 때 오히려 spinning하는 쪽이 거시적으로 보면 더 이득일 수도 있다는 내용인 것 같다.
마무리
아오! 왜 이렇게 길어! 하고 구시렁대면서 강의 자료를 쭉 보다보니까 3차시 분량을 한 번에 다 해서 그런거였다.
여하튼 이번 장에서는 Lock의 정의, Lock의 성능을 평가하는 방법, 하드웨어의 도움을 받아 Lock을 구현하는 방법, Spinning을 제거해 lock의 성능을 향상시키는 방법, 그리고 Linux에서 lock을 구현하기 위해 지원하는 Futex에 대해 공부했다.
이어지는 다음 장에서는 lock을 사용해 다양한 자료 구조에 병렬적으로 접근할 수 있도록 하는 방법들에 대해 공부할 것이다. 내용도 정리하고 퀴즈도 리뷰하려면 시험 끝날 때까지 죽었다 생각하고 열심히 달려야겠다. 오늘은 여기서 GG,,,,
