
시작하기 전에 잠깐! Mechanism과 Policy의 차이점을 기억하는가?
- Mechanism
Low-level의, 즉 기계에서 수행되는 방법이나 프로토콜을 의미한다. context switching 등이 여기에 속한다.
- Policy
여러 메커니즘 맨 꼭대기에서 OS가 어떤 결정을 내리기 위해 미리 정해둔 알고리즘을 의미하며, 조만간 공부할 여러 Scheduling policy들이 여기에 속한다.
쉽게 풀자면 Mechanism은 그냥 어떤 목표를 실행하기 위한 기술 따위를 의미하고, Policy는 그걸 활용해서 무엇을 할 것인지 결정하기 위한 알고리즘 정도로 생각해도 될 것 같다.
지금까지 2~6강에 걸쳐 Context switching과 같은 프로세스 실행 메커니즘을 공부했는데, 이번 장에서는 OS의 Scheduler가 수행하는 High-Level의 Policy(=discipiline)에 대해 공부해볼 것이다!
7.1. Workload Assumptions
여러 Policy에 대해 배우기 전에, 시스템에서 프로세스가 실행되는 상황인 Workload를 좀 더 쉽게 이리저리 굴려보기 위한 몇 가지 가정을 하고 시작하겠다. 이 Workload를 정의하는 것은 policy를 정하는데 있어서 매우 중요한 작업이기도 하고, workload의 특성에 대해 제대로 이해하고 있어야 더욱 성능 좋은 policy를 만들 수 있다고 한다.
아래 가정은 좀 비현실적이지만, 일단 편하게 개념을 익힐 수 있도록 하기 위함이므로 지금 당장은 문제가 없을 것이다. 챕터가 진행됨에 따라 이 비현실적인 가정들을 조금씩 고쳐 나갈 것이며, 최종적으로는 fully-operational scheduling discipline(policy), 그러니까 완전히 잘 작동하는 Policy로 완성시킬 것이다.
시스템에서 실행되는 프로세스(=job, 작업)을 아래와 같이 가정한다.
- 모든 작업들은 같은 시간 동안 실행된다.
- 모든 작업들은 동시에 도착한다.
- 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
- 모든 작업들은 I/O 요청 같은 별도의 작업 없이 CPU만 사용한다.
- 작업의 실행 시간을 모두 알고 있다.
특히 5번 항목이 제일 비현실적이다. 뭐든 해봐야 아는 법이다(?).
7.2. Scheduling Metrics
Job에 관한 가정 이외에도, 각각의 스케줄링 정책을 비교하기 위한 Scheduling metric(평가 지표?)이 필요하다. 기준이 있어야 어떤게 더 좋은 정책인지 고를 수 있지!
제일 간단한 Turnaround time(반환 시간)부터 생각해보자. 작업의 반환 시간은 작업이 완료된 시각에서 작업이 시스템에 도착한 시각을 뺀 값으로 정의한다.
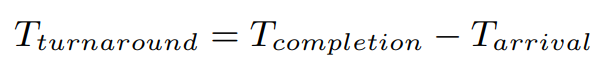
지금은 위에서 모든 작업들이 동시에 도착한다고 가정했기 때문에, T_arrival은 항상 0이므로 T_turnaround = T_completion이 된다.
이 반환 시간은 성능의 지표가 될 수 있는데, 말고도 Jain's Fairness Index 같은 다른 metric을 사용하면 fairness(공정함) 역시 스케줄러의 평가 대상이 될 수 있다.
이 두 평가 지표는 알고리즘에서 시간 복잡도와 공간 복잡도의 trade-off처럼 서로 어느정도 상충하는 요소인데, 스케줄러가 성능을 극대화하기 위해 어떤 작업을 잠깐 멈춰놓는다거나(성능>공정함), 또 차등 없이, 생각 없이 모든 프로세스를 공정하게만 다루면 성능 측면에서 손해를 볼 수도 있다(성능<공정함).
7.3. First In, First Out (FIFO)
제일 먼저 배울 아주 기초적인 알고리즘은 First In, First Out(FIFO), 또는 First Come, First Served(FCFS)라 불리우는 것이다. 일종의 Queue 같은건데..
제일 먼저 배우는 알고리즘답게 정말 간단하다. 간단한게 장점이다.
예를 들어 아래와 같이 작업 A, B, C가 거의 같은 시간에 도착한다고 해도(T_arrival=0), 일단 작업을 대기하는 Queue에 작업을 하나씩 넣어주어야 하기 때문에 어쩔 수 없이 하나씩 실행될 것이다. 여기서는 A, B, C 순서대로 삽입되었다.

여기서 A, B, C 세 작업의 평균 반환 시간(average turnaround time)은 몇 초일까?
T_arrival은 모두 같고, A, B, C 각각의 T_finished가 각각 10, 20, 30이므로 세 작업의 평균 반환 시간은 (10+20+30) / 3 = 20이다. 여기서는 A, C, B든, C, B, A든 어떤 작업이 들어와도 모두 동일한 평균 반환 시간으로 계산될 것이다.
왜냐? 아래와 같은 가정이 있었기 때문이다.
- 모든 작업들은 같은 시간 동안 실행된다.
위 가정을 지워버리면, A, B, C가 작업을 마치는데 소요되는 시간이 달라져 작업이 수행되는 순서가 평균 반환 시간에 영향을 줄 수 있게 된다. 아래처럼!

어우 이번엔 A가 가장 먼저 실행된건 같은데, B와 C가 작업 완료에 10초 밖에 소요되지 않는 반면 A는 100초가 소요된다. B와 C가 A가 실행될 때까지 최소 100초를 기다려야 하므로, 평균 반환 시간은 (100+110+120) / 3 = 110초로 이전보다 5배 이상 늘어났다. 끼악!
이 문제점을 convoy effect라 부르는데, 계산대가 하나 밖에 없는 곳에서 껌 한 통 사려는데 내 앞에 어디 피난 가는 것처럼 산더미만큼 물건 사려는 사람, 배달 처음 시켜보는 사람이 서있는 상황과 느낌이 비슷하다. 나는 껌 한 통만 사면 되는데, 앞 사람이 일을 처리하는데 걸리는 시간이 이렇게 길어져 버리니 이걸 두고 성능 측면에서 좋지 못하다고 하는 것이다.
7.4. Shortest Job First (SJF)
1. 모든 작업들은 같은 시간 동안 실행된다.
2. 모든 작업들은 동시에 도착한다.
3. 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
4. 모든 작업들은 I/O 요청 같은 별도의 작업 없이 CPU만 사용한다.
5. 작업의 실행 시간을 모두 알고 있다.
좋다. 아까 (많이 비현실적이지만) 각각의 작업을 수행하는데 소요될 시간을 완벽히 알고 있다고 가정했으니, 그럼 작업을 수행하는데 가장 시간이 적게 걸리는 작업을 먼저 수행해주면 어떨까?
예컨데 껌 한통만 사는 사람을 먼저 계산하게 해주도록 해주고, 그 다음에는 그 뒤에 서있던 사람이 아니라 줄 서있는 사람들 중에 가장 들고 있는 짐이 적은 사람이 다음으로 계산할 수 있게 해주면 누가, 언제 오든 간에 손에 짐을 적게 들고 있는 사람은 항상 빨리 계산하고 나갈 수 있게 된다.
이를 Shortest Job First(SJF) 정책이라 부르는데, SJF를 적용하면 아래와 같이 작업을 실행할 수 있게 된다.

이번엔 A, B, C가 거의 동시에 도착한 것은 맞는데, 마구잡이로 아무거나 막 실행시키는게 아니라 실행 시간이 가장 짧은 B, C를 먼저 실행시켰다. 평균 반환 시간을 계산해보면, (10 + 20 + 120) / 3 = 50으로, 아까의 110보다 절반 이상 줄어들었다. 만세!
모든 작업이 동시에 도착한다는 가정만 있다면, 이 SJF가 스케줄링 알고리즘 중에 가장 빠르다. 즉 Optimal(최적)이다!
그도 그럴것이 미래를 미리 알고 가장 빨리 응답할 수 있도록 배치해주는 것이기 때문에 다른 알고리즘보다 더 빠를 수가 없다. 이 'Optimal'함 때문에 다른 알고리즘과의 비교 대상으로 많이 쓰인다고 하니, 꼭 기억해 두는 편이 좋겠다.
씁 근데, 지금이야 운이 좋아서 껌을 들고 왔을 때 계산대에 물건이 안 올려져 있어서 이런 시나리오가 가능한데, 만약 주류 코너 싹 쓸어서 술만 가짓수대로 한 병씩 여섯 박스를 산 사람이 이미 계산중이라면?
이 상황은 아래 가정이 사라진 상황과 비슷하다.
- 모든 작업들은 동시에 도착한다.
부러운건 둘째치고, '나 껌 한 통만 계산하면 되니까 지금 하던거 다 멈추고 내 것부터 계산해주세요!' 할 수가 없다. 아래 가정 때문이다.
- 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
사실 이것도 꽤나 비현실적인 가정인게, 컴퓨터를 켜서 이것 저것 작업을 하기야 할텐데 그걸 한 번에 쫙! 다 실행하나? 실로 이상한 가정이 아닐 수 없다.
이렇게 시스템이 각 작업이 종료될 때까지 계속 실행시켜놓는 것을 Non-preemptive(비선점) 스케줄링 방식이라고 부르는데, 살짝 스포일러를 해보자면 이론적으로 우리가 사용하고 있는 현대 스케줄러는 다른 프로세스를 실행시키기 위해 현재 실행중인 프로세스를 중단시킬 수 있는 Preemptive(선점) 스케줄러이다. 즉 Context switching이 가능하다는 거지!
여하튼 가정 2를 지우면, 아래와 같은 상황이 일어날 수 있다.

끔찍하게 오래 걸리는 A가 실행되고 있는 도중에, B와 C가 한 발 늦게 도착한 상황이다.
이제 B와 C의 T_arrived가 0이 아닌 10이 되었으므로, 위 상황에서 평균 반환 시간은 {100 + (110-10) + (120-10)} / 3 = 103.33이다. 끼악!
7.5. Shorted Time-to-Completion First (STCF)
STCF는 Preemtive Shorted Job First, PSJF라 불리우기도 한다.
1. 모든 작업들은 같은 시간 동안 실행된다.
2. 모든 작업들은 동시에 도착한다.
3. 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
4. 모든 작업들은 I/O 요청 같은 별도의 작업 없이 CPU만 사용한다.
5. 작업의 실행 시간을 모두 알고 있다.
이전까지는 문제 상황을 만들기 위해 가정을 지웠다면, 이번에는 문제를 해결하기 위해 아래의 가정을 지워보겠다. (즉, 비선점 스케줄러에서 선점 스케줄러로 바꿔준 것이다.)
- 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
그럼 이제 언제든 새로운 작업이 들어오면 남아 있는 작업 중 남은 실행 시간이 가장 적은 작업을 골라 실행해줄 수 있게 된다.

선점 방식으로 스케줄러를 바꿔주었을 때의 실행 타임라인이다. 아까와 마찬가지로 A가 실행되고 있는 도중에 B와 C가 시스템에 도착한 것은 같은데, 이번에는 실행 시간이 90만큼 남은 A가 아니라, 실행 시간이 10 밖에 남지 않은 B, C가 먼저 실행된 다음 A가 실행되는 것이다. 좀 디테일하게 살펴보면 B가 끝난 다음 실행 시간이 90 남은 A와 실행 시간이 10 남은 C 중 실행 시간이 더 적게 남은 C가 실행된 것이라 할 수도 있겠다.
결과적으로 평균 반환 시간이 {(120-0)+(20-10)+(30-10)} / 3 = 50으로, 아까의 절반 정도로 확 줄었다. 작업들이 동시에 도착할 보장이 없는 상황에서는 STCF이 Optimal하다.
7.6. A New Metric: Response Time
1. 모든 작업들은 같은 시간 동안 실행된다.
2. 모든 작업들은 동시에 도착한다.
3. 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
4. 모든 작업들은 I/O 요청 같은 별도의 작업 없이 CPU만 사용한다.
5. 작업의 실행 시간을 모두 알고 있다.
좋다! 이젠 작업이 동시에 오지 않아도, 같은 시간 동안 실행되지 않아도 Optimal한 결과를 낼 수 있는 STCF Policy를 선택했다. 끝인가?
아니! 아까 위에서 Policy를 두 가지 기준에 의해 평가한다고 했는데, 위에서 FIFO, SJF, STCF를 거쳐 성능에 관한 이슈를 다루었다면, 이젠 Fairness, 즉 공정함에 대한 이슈를 다룰 차례이다.
이 공정함의 지표로써 Response time(응답 시간)이라는 새 기준을 정의할 것인데, 이는 작업이 도착할 때부터 처음 스케줄 될 때까지의 시간을 의미한다.
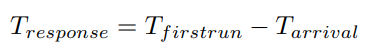
예를 들어 아래와 같이 A, B, C가 시점 0에 동시에 도착한 상황에서 SJF를 적용해 평균 응답 시간을 계산해보면, 스케줄링 된 시각이 각각 0, 5, 10이므로 평균 응답 시간은 {(0-0)+(5-0)+(10-0)} / 3 = 5로, 길다. 너무 길다!

예를 들어 웹 브라우저를 통해 네트워크로부터 무언가 받아 화면을 표시할 때, OS의 반응 속도가 느리다면 다른 프로세스가 실행되고 있을 경우 화면에 뭔가 보일 때까지 시간이 너무 오래 걸리게 된다. 최소한 '로딩중...' 이라고 뜨기라도 하면 '아 그냥 느린갑다' 하고 기다릴텐데, 아무런 피드백도 없이 하얀 창만 계속 떠있으면, 좀 답답할 것 같지 않은가? 조선땅에서는 그런거 있을 수가 없다. 고쳐보자.
7.7. Round Robin
1. 모든 작업들은 같은 시간 동안 실행된다.
2. 모든 작업들은 동시에 도착한다.
3. 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
4. 모든 작업들은 I/O 요청 같은 별도의 작업 없이 CPU만 사용한다.
5. 작업의 실행 시간을 모두 알고 있다.
이 문제를 해결하기 위해, Round-Robin(RR)이라는 스케줄링 알고리즘을 고려해볼 것이다.
아까 STCF를 도입하며 삭제한 3번째 조건 때문에 가능한 것인데, 작업이 끝날 때까지 프로세스를 실행시키는 것이 아니라 작업을 일정한 time slice(=scheduling quantum) 동안만 실행시킨 다음 시간이 다 되었으면 다음 작업에게 프로세서의 사용권을 넘겨주는 것이다. (이때 당연히 time slice 길이는 timer interrupt 주기의 배수가 되어야 한다.)

RR이 적용된 위 예시에서 time slice 길이는 1이고, A, B, C가 동시에 도착한 상황이다.
그럼 이 때 평균 반환 시간은? (0+1+2) / 3 = 1로, 방금 문제를 발견한 SJF의 5초보다 훨씬 짧다. 와!
좋아. 그럼 저 time slice의 길이를 m이라 하면, 위와 같은 상황에서 평균 반환 시간이 (0+m+2m) / 3 = m이니까, time slice의 길이가 짧아지면 선형적으로 평균 반환 시간이 짧아지는 것 아닌가? 줄여봐?!
세상에 공짜는 없다. 앞선 다른 챕터에서 배웠듯 Context switch 자체에도 비용이 들기 때문에, 이 time slice 길이를 너무 짧게 하면 Context switch 비용이 너무 많이 들어가게 되기 때문에 적절한 값을 찾아 타협을 봐야 한다. 물론 너무 길어도 평균 응답 시간이 길어지니 적당한 선에서.
또, 지금까지 쭉 평균 반환 시간 관점에서만 정책을 봐서 RR이 좋아 보이는데, 다른 평가 기준인 성능 측면에서는 RR이 좋은 정책은 아니다. 도착은 모두 동시에 했는데, A, B, C의 작업 완료 시점이 각각 13, 14, 15이므로 평균 반환 시간이 14로 증가해버린 것이다! (SJF였다면 10이었을 것이고, 심지어 같은 상황이었다면 FIFO보다 나쁘다.)
이것이 바로 맨 앞에서 언급한 성능과 공정함 사이의 trade-off이다. SJF/STCF는 성능 측면에서 양호하지만 공정함 측면에서 좋지 않고, RR은 공정하지만 이렇듯 성능이 좋지 못하다.
7.8. Incorporating I/O
1. 모든 작업들은 같은 시간 동안 실행된다.
2. 모든 작업들은 동시에 도착한다.
3. 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
4. 모든 작업들은 I/O 요청 같은 별도의 작업 없이 CPU만 사용한다.
5. 작업의 실행 시간을 모두 알고 있다.
위 문제를 해결하기 위해 이번에는 가정 4를 지워보자. 쓰던 것들 중에 I/O 없는 프로그램 본 적 있는가?!
앞에서 CPU의 status(ready, running, blocked)에 대해 배웠을 때, Disk I/O와 같은 작업은 CPU가 아닌 각각의 장치와 어떤 작업을 수행하기 때문에 다른 CPU를 사용해야 하는 프로세스들에게 방해가 되지 않도록 실행을 기다리는 ready가 아닌 blocked 상태로 전환되어 I/O 작업이 완료될 때까지 기다린다는 것을 알게 되었다.
"음 그런거 잘 모르겠고, 그냥 기다리지 뭐!" 하는 마음으로 아래 예제를 살펴보자.

위와 같이 CPU를 50ms 동안 사용해야 하는 프로세스 A, B가 있는 상황에서, B는 이때까지 예로 들었던 작업들처럼 CPU만 사용하고, A는 19 10ms 동안 CPU를 사용한 다음, 10ms 동안 I/O 요청을 하는 것을 반복하고 있다.
딱 봐도 비효율적이지 않은가? 둘 다 CPU를 총 50ms만큼 써야 하는 건 알겠는데, 그렇다고 해서 중간 중간 Disk I/O를 요청하는 A와 B가 작업을 마치는데 소요되는 시간이 같은 건 아니잖아!
문제를 해결하기 위해 A를 10ms씩 나누어 STCF로 스케줄링 한다고 생각해보자.

그럼 0ms 시점엔 A의 10ms짜리 하위 작업과 B를 비교해서 가장 남은 시간이 적은 A가 실행되고(0~10), A이 I/O 요청을 하는 동안은 B 밖에 없으니 B를 다음으로 실행하면 된다(10~20).
A의 Disk I/O 요청이 끝나면 다음 A의 하위 작업(10ms)과 B(40ms)가 스케줄러에 의해 비교되어 남은 소요 시간이 더 적은 A가 실행되고(20~30), A가 I/O를 요청하면 B가 혼자 남았기 때문에 B를 다시 실행해주고(30~40), ...
이걸 반복하면 A가 I/O를 수행하는 사이 사이에 B를 넣어서 훨씬 빨리 작업을 마칠 수 있다. 여기서 포인트는 A를 각각의 10ms짜리 독립적인 하위 작업으로 다루는 것이다.
7.9 No More Oracle
1. 모든 작업들은 같은 시간 동안 실행된다.
2. 모든 작업들은 동시에 도착한다.
3. 일단 작업이 시작되면, 각각의 작업들은 완료될 때까지 실행된다.
4. 모든 작업들은 I/O 요청 같은 별도의 작업 없이 CPU만 사용한다.
5. 작업의 실행 시간을 모두 알고 있다.
가정 1~4를 차례로 지우고 나니, 가장 비현실적인 가정 5가 남았다.
앞서 말했듯 프로세스를 실행하기도 전에 얼만큼 시간이 소요될지 알 수 있는 방법은 대부분 있을 수 없다. [1, 100] 범위의 정수를 반환하는 랜덤 함수를 돌려서 100이 나와야 프로세스를 종료하는 간단한 프로그램만 해도 언제 작업이 끝날지 확신할 수 없다.
그럼 우리한테는 더 이상 희망이 남질 않은걸까? 실행 시간을 몰라도 SJF/STCF처럼 효율적이고, RR처럼 공정한 스케줄러는 만들 수 없는 걸까? ㅠ
마무리
이전까지 CPU의 가상화를 위한 메커니즘을 공부했다면, 이번 챕터부터는 고수준의 Policy, 그러니까 어떻게 작동할지 결정하기 위한 알고리즘을 배웠다.
성능과 공정함 사이의 trade-off라.. 이전까지는 딱히 생각해보지 않은 주제여서 그런지 제법 신선하다.
읽다 보니 책 참 잘 쓴 것 같다. 나도 이렇게 설명할 수 있을만큼 열심히 배워야겠당.
