
지난 새벽에 이분 탐색의 개념, 구현, 표준 라이브러리를 활용한 구현까지 다뤄봤다.
이젠 미루고 미뤄왔던 upper, lower bound를 활용한 개념과, 이를 활용한 문제를 하나 풀어보겠다!
예고한대로 백준 문제집 '이분 탐색 단계'를 따라서 풀어볼 것이고, 이번엔 두 번째 문제인 S4 난이도 숫자 카드 2를 풀겠다.
접근
[-10,000,000, 10,000,000] 범위의 정수가 적힌 카드가 500,000개 주어질 때, 이어서 특정 카드가 덱에 몇 개 들어있는지 확인하면 된다.
구현 1-1 : Map을 활용한 구현
보자마자 떠오른 접근은 역시 어제와 같다. 다만 개수를 저장해야 하기 때문에 Set이 아닌 Map을 써야 할 것이다.
// 카드의 개수
final int NUM_OF_CARDS = Integer.parseInt(in.readLine());
// key : 카드
// value : 해당 카드가 덱에 포함된 횟수
Map<Integer, Integer> cardCounter = new HashMap<>();
st = new StringTokenizer(in.readLine());
for (int cnt = 0; cnt < NUM_OF_CARDS; cnt++) {
// 해당 카드가
int card = Integer.parseInt(st.nextToken());
// 덱에 있었다면 지금까지의 누적 개수를, 없었다면 0을 반환하고
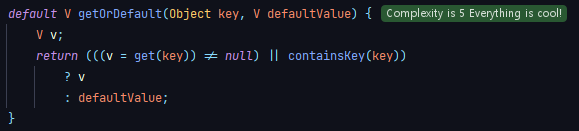
int numOfCard = cardCounter.getOrDefault(card, 0);
// 반환된 개수에 1을 더해 누적 개수를 갱신한다.
cardCounter.put(card, numOfCard + 1);
}
// 특정 카드가 몇 개 들어 있는지 확인할 횟수
final int NUM_OF_OPERATIONS = Integer.parseInt(in.readLine());
st = new StringTokenizer(in.readLine());
for (int cnt = 0; cnt < NUM_OF_OPERATIONS; cnt++) {
int card = Integer.parseInt(st.nextToken());
int numOfCard = cardCounter.getOrDefault(card, 0);
out.append(numOfCard).append(' ');
}
// 결과 출력
System.out.println(out);
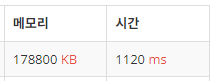
참고로 실행 시간 자체는 이분 탐색 풀이보다 200ms 정도 빠른데, 메모리는 27,000KB=27MB 정도 더 쓴다.
int numOfCard = cardCounter.getOrDefault(card, 0);원래는 if (cardCounter.containsKey(card))로 카드의 등장 여부를 확인해서 없으면 1을 put하고, 있으면 get해서 지금까지 누적한 카드 개수에 1을 더한 값으로 put 해주는 식으로 분기하려고 했는데, 같은 작업을 더 깔끔하게 수행해주는 메서드가 있길래 써봤다.
구현 1-2 : 카운터 배열과 Offset
위와 같이 자료구조를 쓸 수도 있고, 이전 포스트에서 얘기했듯이 정수 범위가 작으니까(10,000,000 * 2 < 2^32) 배열을 써서 counter[num]이 이때까지 누적한 카드의 등장 횟수를 의미하는 것으로 놓고 풀 수는 없을까?
// 카드의 개수
final int NUM_OF_CARDS = Integer.parseInt(in.readLine());
// 인덱스는 양수여야 하므로, 구간이 음수 방향으로 뻗은 크기만큼 더해서 저장/사용함
final int OFFSET = 10_000_000;
int[] cardCounter = new int[OFFSET * 2 + 1];
st = new StringTokenizer(in.readLine());
for (int cnt = 0; cnt < NUM_OF_CARDS; cnt++) {
// 여기 주목!!!!!!!!!!!!!
int card = Integer.parseInt(st.nextToken());
cardCounter[card + OFFSET]++;
}
// 특정 카드가 몇 개 들어 있는지 확인할 횟수
final int NUM_OF_OPERATIONS = Integer.parseInt(in.readLine());
st = new StringTokenizer(in.readLine());
for (int cnt = 0; cnt < NUM_OF_OPERATIONS; cnt++) {
int card = Integer.parseInt(st.nextToken());
// 여기 주목!!!!!!!!!!!!!
int numOfCard = cardCounter[card + OFFSET];
out.append(numOfCard).append(' ');
}
// 결과 출력
System.out.println(out);다른건 대부분 다 같고, 자료 구조를 Map이 아니라 배열을 쓴 부분만 다르다.
일종의 카운팅 소트 비슷한 접근 방식인데, 문제의 경우 카드에 적힌 숫자의 범위의 길이가 정수로 표현할 수 있는 범위보다 작고, 이 말인 즉 카드의 개수를 저장할 공간의 크기를 정의할 때 배열을 사용할 수 있다는 의미이다.
다만 배열에서 원소의 위치를 특정할 때 쓰는 인덱스 값은 항상 0이거나 2^31-1 보다 작거나 같은 값이어야 하기 때문에, final int OFFSET = 10_000_000으로 선언된 상수값을 카드의 개수를 갱신할 때, 받아올 때 매번 더해서 표현한 것이다. 물론 이 역시 OFFSET * 2 < 2^31-1이므로 가능한 것이다.

Map 특유의 Primitive wrapping, 충돌 등등의 요소는 배제되고 캐시의 이점을 취한 것인지 속도는 Map 방식보다 132ms 빠르다. 하지만 문제에서 메모리 제한은 256MB인데 거의 간당간당하게 안 넘었으니,, 표현하는 범위가 좁은 특수한 상황에서 유용할 것 같다.
여기서 좀 더 응용하면 bit mask 기법을 사용해서 2^32개의 상태를 표현할 수도 있다. offset까지 써가면서 비트 마스킹을 한 적은 따로 없는 것 같긴 하지만 여하튼,, 상태를 누적 갱신하는 방법만 다를 뿐(++ vs <<) 결은 비슷한 것 같아 남겨 놓는다.
이분 탐색으로 해결하기
이제 본론으로 넘어가서, 이분 탐색으로 문제를 해결해보자.
해결에 앞서 어제 얘기하다 만 insertion point에 대해 먼저 알고 있어야 한다.
그 전에!
포스트에 '삽입'이란 단어가 나오는데, 예를 들어 인덱스 2에 삽입한다는 것은 기존의 인덱스 2에 있던 요소부터 끝 요소까지 한 칸씩 뒤로 밀고, 인덱스 2에 새 값을 넣는다는 의미이다. 막바지에 혹시 헷갈리는 분이 계실까봐 남긴다!
Insertion Point in binarySearch

이분 탐색 메서드의 주석이다. 어렴풋이 해석해보자면,,
이분 탐색 알고리즘을 사용하여 int형 배열 내부의 특정 int형 값을 탐색합니다. 이 메서드를 호출하기에 앞서 배열은 반드시
sort(int[])메서드 등을 사용하여 정렬되어 있어야 합니다. 만약 정렬되어 있지 않다면 원하는 결과가 나오지 않습니다. 만약 배열이 주어진 값을 여러 개 포함하고 있다면, 그 중 어떤 것의 위치가 반환될지 알 수 없습니다.인자 :
a- 탐색 대상 배열
key- 탐색할 값반환 : 배열 안에 탐색할 값이 있는 경우 해당 값이 위치한 인덱스를 반환합니다.
그렇지 않은 경우(-(insertion point) - 1)을 반환합니다.
Insertion point는 배열에 키가 삽입될 수 있는 위치를 의미합니다. 즉, 주어진 키보다 큰 첫 번째 요소의 인덱스이거나, 배열의 모든 요소가 지정된 키보다 작다면 배열의 길이(a.length)입니다. 이 반환 값이 0 이상일 경우에만 키가 배열에 포함되어 있음을 보장합니다.
정도 될 것 같다. 조금만 더 풀어서 설명해보자면 이 메서드의 반환 값이 0 이상이라면 배열 내부에서 해당 값이 등장한 위치를 의미하지만 같은 값을 여러 번 포함할 수 없다는 제약 조건이 없으므로 이들 중 어떤 요소의 인덱스가 반환될지 보장할 수는 없다.
반면 반환 값이 0 미만이라면 배열에 해당 값이 포함되어 있지 않음을 의미하며, 더불어 탐색을 요청한 값이 배열의 정렬 상태를 깨지 않으면서 삽입될 수 있는 위치를 반환한다고 할 수 있다. 배열 안에 값이 있음과 없음을 보장하기 위함이라면 그냥 -(insertion point)를 반환하면 될 수도 있지 않나,,? 싶을 수 있지만 반환 값이 0이라면 실제 등장한 위치가 0인지, 아니면 insertion point가 0인지 구분할 수 없기 때문에 저렇게 반환하는 것 같다.
말은 쉽다, 코드로 배워보자.
// 정렬 필수!
int[] numbers = {50, 40, 30, 20, 10};
Arrays.sort(numbers); // {10, 20, 30, 40, 50}
// case 1 : 배열 안에 key가 존재하는 경우
System.out.println("10 => " + Arrays.binarySearch(numbers, 10)); // 10 => 0
System.out.println("30 => " + Arrays.binarySearch(numbers, 30)); // 30 => 2
// case 2 : 배열 안에 key가 존재하지 않는 경우
// -(insertion point) - 1 = -1이므로 insertion point = 0
// 즉, 0번 위치에 5를 삽입해야 정렬 상태가 유지된다. {5, 20, 30, 40, 50}
System.out.println("5 => " + Arrays.binarySearch(numbers, 5)); // 5 => -1
// 거꾸로 값을 유추할 수도 있다. 정렬 상태를 유지하며 배열에 없던 25를 배열에 삽입하려면
// 30이 위치해 있는 numbers[2]에 값을 삽입해야 하므로 insertion point는 2이다.
// 따라서 반환되는 값은 -2-1 = -3일 것이다.
System.out.println("25 => " + Arrays.binarySearch(numbers, 25)); // 25 => -3
// 배열에 key가 존재하지 않을 때 얻을 수 있는 가장 큰 값은 -numbers.length-1이다.
// 배열에 삽입할 때 뒤의 모든 요소들을 한 칸씩 뒤로 밀어야 하기 때문에, 맨 뒤에 추가해야 하기 때문이다.
System.out.println("100 => " + Arrays.binarySearch(numbers, 100)); // 100 => -6주석으로 설명해놨으니 이해가 잘 안된다면 직접 이런 저런 값을 넣어 보면 좋을 것 같다.
구현 2-1 : binarySearch를 활용한 구현
사실 binarySearch만 배운 어제 상황에서도 충분히 응용해서 풀 수 있었겠지만, 구현 2-2에서 지금 작성할 코드를 upper & lower bound로 개선할 수 있기 때문에 일부러 여기까지 끌고 왔다. 문제 해결 전략은 대충 다음과 같을 것이다.
- 배열에 카드에 적힌 숫자를 입력 받는다.
- 이분 탐색을 위해 배열을 정렬한다.
- 덱에 포함된 개수를 확인할 각 카드마다..
3-1.Arrays.binarySearch메서드로 카드의 위치를 확인한다.
3-2. 만약 반환된 값이 음수라면 덱에 포함되어 있지 않은 것이므로 0을 출력한다.
3-3. 양수라면, 덱에 특정 숫자가 적힌 카드가 한 장씩만 있다는 제약 조건이 없므으로 좌우로 그 값과 같은 숫자가 적힌 카드가 더 없을 때까지 탐색하여 개수를 누적한다.
마지막 줄이 핵심이다. 코드로 표현하자면,,
// 1. 카드 입력 받기
final int NUM_OF_CARDS = Integer.parseInt(in.readLine());
int[] cards = new int[NUM_OF_CARDS];
st = new StringTokenizer(in.readLine());
for (int idx = 0; idx < NUM_OF_CARDS; idx++) {
int card = Integer.parseInt(st.nextToken());
cards[idx] = card;
}
// 2. 이분 탐색을 위한 정렬
Arrays.sort(cards);
// 특정 카드가 몇 개 들어 있는지 확인할 횟수
final int NUM_OF_OPERATIONS = Integer.parseInt(in.readLine());
st = new StringTokenizer(in.readLine());
// 3. 확인할 각 카드마다,,
for (int cnt = 0; cnt < NUM_OF_OPERATIONS; cnt++) {
int targetCard = Integer.parseInt(st.nextToken());
// 3-1. 이분 탐색으로 카드의 위치를 확인한다.
int targetIdx = Arrays.binarySearch(cards, targetCard);
// 3-2. 만약 반환된 값이 음수라면 덱에 포함되어 있지 않은 것이므로 0을 출력한다.
if (targetIdx < 0) {
out.append(0).append(' ');
}
// 3-3. 양수라면, 덱에 특정 숫자가 적힌 카드가 한 장씩만 있다는 제약 조건이 없므으로
// 좌우로 그 값과 같은 숫자가 적힌 카드가 더 없을 때까지 탐색하여 개수를 누적한다.
else {
// cards[targetIdx]와 그 좌우 위치의 카드를 확인하며 targetCard와 같은 숫자의 개수를 누적
int numOfTargets = 1;
// 왼쪽으로 경계를 벗어나지 않으며 targetCard가 더 안나올 때까지 탐색
int leftIdx = targetIdx - 1;
while (leftIdx >= 0 && cards[leftIdx] == targetCard) {
leftIdx--;
numOfTargets++;
}
// 오른쪽으로 경계를 벗어나지 않으며 targetCard가 더 안나올 때까지 탐색
int rightIdx = targetIdx + 1;
while (rightIdx < NUM_OF_CARDS && cards[rightIdx] == targetCard) {
rightIdx++;
numOfTargets++;
}
// 누적된 개수를 출력
out.append(numOfTargets).append(' ');
}
}
// 결과 출력
System.out.println(out);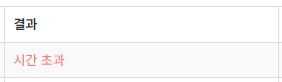

Ta-da- 장렬히 시간 초과가 났다.
분석 : 이럴거면 왜 이분 탐색 했어
이분 탐색의 강점은 매 탐색 iteration마다 탐색 범위를 반으로 줄이는 데 있다. 그 장점을 써보겠다고 덤빈 것 자체는 좋았지만 치명적인 맹점이 하나 있는데,,
// 3-3. 양수라면, 덱에 특정 숫자가 적힌 카드가 한 장씩만 있다는 제약 조건이 없므으로
// 좌우로 그 값과 같은 숫자가 적힌 카드가 더 없을 때까지 탐색하여 개수를 누적한다.
else {
// cards[targetIdx]와 그 좌우 위치의 카드를 확인하며 targetCard와 같은 숫자의 개수를 누적
int numOfTargets = 1;
// 왼쪽으로 경계를 벗어나지 않으며 targetCard가 더 안나올 때까지 탐색
int leftIdx = targetIdx - 1;
while (leftIdx >= 0 && cards[leftIdx] == targetCard) {
leftIdx--;
numOfTargets++;
}
// 오른쪽으로 경계를 벗어나지 않으며 targetCard가 더 안나올 때까지 탐색
int rightIdx = targetIdx + 1;
while (rightIdx < NUM_OF_CARDS && cards[rightIdx] == targetCard) {
rightIdx++;
numOfTargets++;
}
// 누적된 개수를 출력
out.append(numOfTargets).append(' ');
}바로 이 부분이다. 만약 덱이 모두 같은 카드로 구성되어 있고, 탐색마저 이 같은 값으로 계속 수행한다면 사실상 선형 탐색을 매번 수행하는 것과 다를 바가 없기 때문에 시간 초과가 난 것이다.
뭔가를 찾는다는 것도 같고, targetIdx가 가리키는 위치의 좌우도 정렬되어 있음이 보장되니까 여기서도 이분 탐색을 쓰면 더 빨리 targetIdx 좌-우의 마지막 targetCard가 등장하는 위치를 찾을 수 있지 않을까?
Upper & Lower bound
볼드체 떡칠해가면서 강조한 부분들을 모아서 정리해보자면, 지금 우리가 해야 할 일은 이분 탐색을 사용해서 특정 요소가 배열 안에서 등장하는 가장 왼쪽의 위치와 가장 오른쪽의 위치를 찾는 일이다.
왜냐! 배열은 정렬이 수행된 이후로 계속 읽기 연산의 대상으로만 사용되기 때문에, 가장 왼쪽의 위치와 가장 오른쪽의 위치를 빠르게 찾을 수 있다면 그 차이가 곧 타겟이 등장한 횟수와 같기 때문이다.
예를 들어 배열이 {2, 3, 4, 4, 4, 4, 5, 6}으로 길이가 8이라면, 4의 개수를 구할 때 가장 왼쪽의 4가 등장하는 위치가 2, 가장 오른쪽의 등장하는 4의 위치가 5이므로 4의 개수를 5-2+1=4와 같이 구할 수 있다는 말이다. 마찬가지로 단 한 번 등장하는 2의 개수를 구하고 싶다면 0-0+1=1과 같이 구할 수 있다.
이 아래가 포스트의 핵심이다. 이만큼은 이해해야 한다!
사실 배열 안에서 특정 원소가 등장하는 가장 끝 위치를 구해주는 것보단 정렬 상태를 유지하며 삽입할 수 있는 가장 끝 위치를 구해주는 편이 범용성 측면에서 더 낫다. 따라서,,
- lower bound는 일정 구간 안에서 찾으려는 값 이상인 가장 첫 위치
- upper bound는 일정 구간 안에서 찾으려는 값을 초과하는 가장 첫 위치
를 반환한다고 확장해서 생각하자. 이렇게 생각해야 만약 lower bound 함수가 반환한 인덱스가 배열의 범위를 벗어나거나(arr.length) 반환된 인덱스에 위치한 값이 targetNum과 다를 때(arr[lowerBoundIdx] != targetNum) targetNum이 배열 안에 존재하지 않는다는 식의 활용이 가능하기 때문이다.
마찬가지로 upper bound가 '찾으려는 값을 초과하는 가장 첫 위치'이기 때문에 가장 뒤에 삽입해야 하는 경우인 arr.length가 최댓값이 될 것이며, 이는 곧 lower bound의 값이 0이며 키 값과 다를 때 맨 앞에 삽입해야 함과 대조적으로 맨 뒤에 삽입해야 함을 의미한다. (뒤에서 보겠지만 그래서 경계를 표시할 때 [0, arr.length)가 아니라 [0, arr.length]를 사용한다. 맨 뒤에 삽입해야 할 수도 있으니까!)
물론 이렇게 확장하면 구간 안에 키 값이 없을 경우 lower bound와 upper bound가 0이나 arr.length로 같아질 것이며, 키 값이 구간 안에 포함된 횟수를 구할 때에는 upper_bound - lower_bound와 같이 구할 수 있을 것이다. (이전 계산 식에서 +1이 빠졌다!)
그럼 왼쪽 경계, 즉 인덱스가 낮은 방향의 끝 경계인 Lower bound를 찾아보자. 그림은 바킹독님 자료 찾아서 봐라 ㅎ
public static int lowerBound(int[] numbers, int targetNum) {
// targetNum이 위치할 수 있는 인덱스를 찾기 위한 구간을 [low, high]부터 좁혀나간다.
int low = 0;
// 맨 뒤에 추가해야 할 수도 있으므로, high는 N-1이 아닌 N으로 초기화한다.
int high = numbers.length;
// low와 high가 같아짐은 한 인덱스가 특정되었음을 의미함
while (low != high) {
// low와 high 중앙에 있는 값이
int mid = (low + high) >> 1;
// target보다 크거나 같다면, 조건을 만족하는 첫 위치를 찾는 것이므로
// 구간의 왼쪽으로 좁혀나가며 mid 위치는 이미 targetNum 이상이므로 더 확인하지 않는다.
// [low, high] => [low, mid]
if (numbers[mid] >= targetNum) {
high = mid;
}
// target보다 작다면, 적어도 mid 위치보다 오른쪽에 목적지가 있으므로
// 구간의 오른쪽으로 좁혀나가며 mid 위치는 이미 targetNum 미만이므로 더 확인하지 않는다.
// [low, high] => [mid+1, high]
else {
low = mid + 1;
}
}
// high를 반환해도 상관 없음
return low;
}요점은 주석으로 남겨 두었으니, 한 10개 정도 요소를 가지는 배열을 놓고
- 중간쯤에 다수 있는 요소의 lower bound 찾기
- 중간쯤에 단 하나 있는 요소의 lower bound 찾기
- 중간에 끼울 수 있는, 배열에 없는 값의 lower bound 찾기
- 맨 앞 요소의 lower bound 찾기
- 맨 앞 요소보다 작은 요소의 lower bound 찾기
- 맨 뒤 요소의 lower bound 찾기
- 맨 뒤 요소보다 큰 요소의 lower bound 찾기
정도 손으로 직접 해보면 분명 이해가 될 것이다. 꼭 해봐야 한다 꼭!

글씨는 안예쁘지만 예쁘게 흐름과 결과를 잘 적어놓고, 이제 설명할 upper bound에 대해서도 동일한 테스트 케이스를 손으로 따라 그려보자.
public static int upperBound(int[] numbers, int targetNum) {
// targetNum이 위치할 수 있는 인덱스를 찾기 위한 구간을 [low, high]부터 좁혀나간다.
int low = 0;
// 맨 뒤에 추가해야 할 수도 있으므로, high는 N-1이 아닌 N으로 초기화한다.
int high = numbers.length;
// low와 high가 같아짐은 한 인덱스가 특정되었음을 의미함
while (low != high) {
// low와 high 중앙에 있는 값이
int mid = (low + high) >> 1;
// targetNum보다 크다면, 해당 위치를 포함한 그 뒷쪽은 반드시 targetNum보다 클 것이므로
// 그 뒷쪽은 볼 필요가 없음, 따라서 왼쪽 절반으로 구간을 축소
if (numbers[mid] > targetNum) {
high = mid;
}
// targetNum보다 작거나 같다면, 가장 오른쪽에 있는 삽입 위치를 찾는 것이므로
// mid의 오른쪽 구간을 선택하여 축소
else {
low = mid + 1;
}
}
// high를 반환해도 상관 없음
return low;
}이게,, 직접 안그려보면 quick sort랑 비슷한 느낌으로 구간을 어딜 잡아야 할지 되게 헷갈린다.
꼭 upper bound도 직접 그려보고 값을 비교해보자!
구현 2-2 : Upper & Lower bound를 활용한 구현
두 함수를 구현했다면 나머지는 쉽다! 아까 얘기했듯 upper_bound - lower_bound가 targetNum의 개수이기 때문이다. 중복되는 주석을 빼고 코드 전문을 써보자면,,
/**
* N개의 정수로 구성된 배열이 주어질 때, 이 안에 특정 정수가 존재하는지 M번 구한다.
*/
public class Main {
// ...
public static void main(String[] args) throws Exception {
final int NUM_OF_CARDS = Integer.parseInt(in.readLine());
int[] cards = new int[NUM_OF_CARDS];
st = new StringTokenizer(in.readLine());
for (int idx = 0; idx < NUM_OF_CARDS; idx++) {
cards[idx] = Integer.parseInt(st.nextToken());
}
Arrays.sort(cards);
final int NUM_OF_OPERATIONS = Integer.parseInt(in.readLine());
st = new StringTokenizer(in.readLine());
for (int cnt = 0; cnt < NUM_OF_OPERATIONS; cnt++) {
int targetCard = Integer.parseInt(st.nextToken());
// LB와 UB를 각각 구해 인덱스 차이로 card의 개수를 구한다.
int lowerBoundIdx = lowerBound(cards, targetCard);
// 두 조건에 해당될 경우 해당 카드가 덱에 존재하지 않음을 의미한다.
if ((lowerBoundIdx == cards.length) || (targetCard != cards[lowerBoundIdx])) {
out.append(0).append(' ');
continue;
}
int upperBoundIdx = upperBound(cards, targetCard);
out.append(upperBoundIdx - lowerBoundIdx).append(' ');
}
System.out.println(out);
}
public static int lowerBound(int[] numbers, int targetNum) {
// ...
}
public static int upperBound(int[] numbers, int targetNum) {
// ...
}
}
메인 함수 안쪽이 중요하다! Upper bound index를 구하지 않은 상태라도 아까 이야기 했듯 lowerBoundIdx가 배열의 표현 범위를 벗어났거나(삽입할 경우 가장 큰 값), 해당 위치에 삽입할 수 있으나 원래 배열에 없던 값인 경우 해당 카드가 배열 안에 포함되어 있지 않음을 미리 알 수 있기 때문이다.
마무리
어휴 힘들었다. 이제 감이 좀 잡히는 것 같아 기쁘다!
다음 포스트에서는 이분 탐색에서 나아가 매개 변수 탐색(Parametric Search)를 공부해보겠다. 빠세!
참고한 자료
- 바킹독 [실전 알고리즘] 0x13강 - 이분탐색 : 그림과 함께 bound의 개념을 알기 쉽게 설명해주셨다. 다시 정독!
- [Algorithm/Java] 이진탐색 Binary Search / UpperBound / LowerBound : Bound의 경계를 잡는 과정을 제대로 이해 못하고 있었는데, 그 부분에서 정말 시원하게 설명해주셨다. 꼭 읽어보셨으면 좋겠당 ㅎ
