“Single Shot MultiBox Detector” -2016
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, Alexander C. Berg
UNC Chapel Hill, Zoox Inc, Google Inc, University of Michigan
Link to Paper: https://arxiv.org/pdf/1512.02325
Table of Contents
- Introduction
- SSD
- Training
- Code
1. Introduction
기존 객체 탐지 시스템(Faster R-CNN)은 bounding box 생성 후 픽셀 또는 특징들을 리샘플링하여 객체를 탐지합니다.
Faster R-CNN
RoI Pooling(Region of Interest Pooling)
잠재적으로 객체가 있을 수 있는 관심 영역ROI (Region of Interest)을 RPN (Region Proposal Network)로 bounding box을 예측 → 관심 영역을 동일한 지정 크기로 변환하기 위해 해당 영역을 샘플링하는 과정 ROI Pooling 수행 → ROI Pooling으로 ROI bounding box에서 픽셀 및 특징을 다시 샘플링한 후, 분류기와 네트워크에 전달하여 최종 결과를 얻음
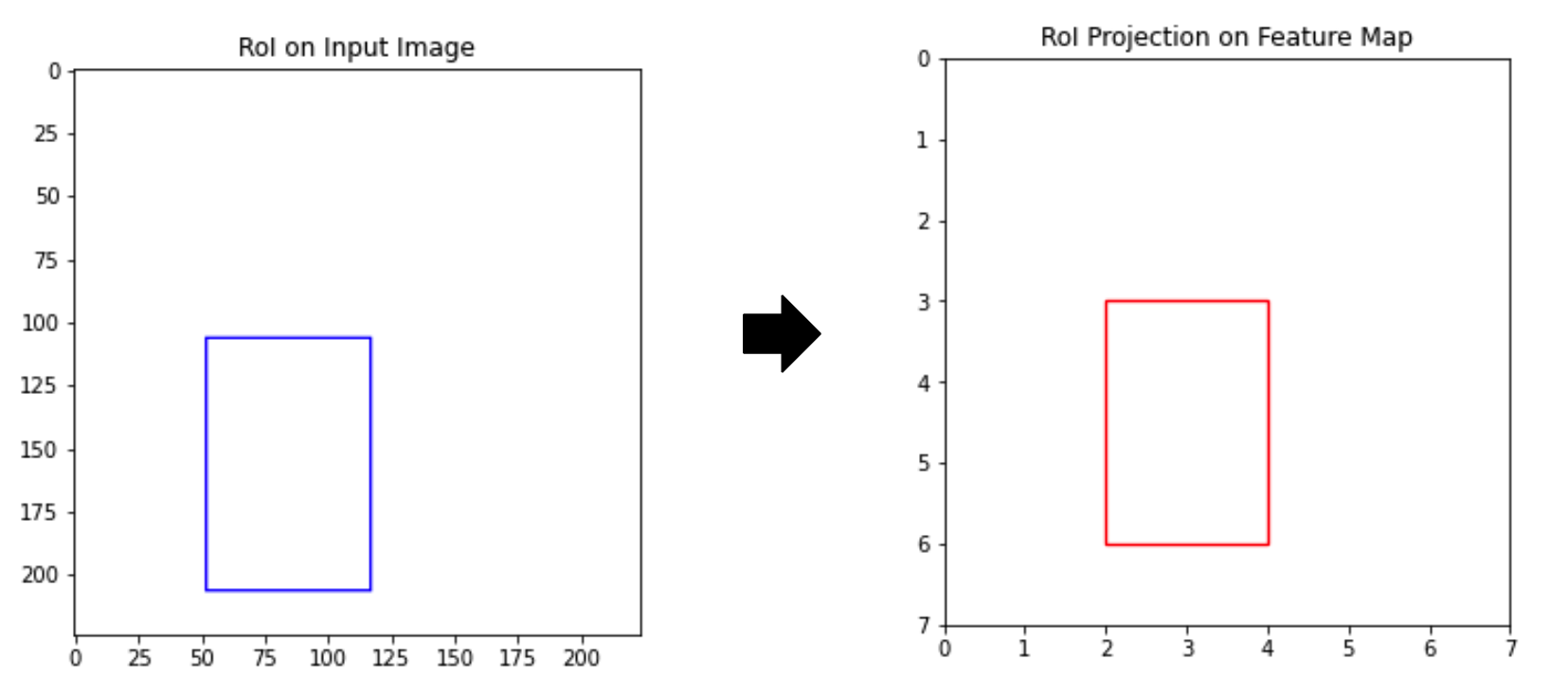
입력이미지 224X224에서 관심 영역 ROI(Region of Interest)이 100X65(좌표:52, 106, 117, 206)이라 할때, 100X65 영역이 그대로 네트워크에 들어가기엔 너무 큰 정보량을 가지고 있어서 ROI Pooling을 통해서 7X7 특징맵으로 변환하고 해당 ROI는 반올림해서 [2, 3, 4, 6] 으로 변환되어 효율적으로 학습
그러나 픽셀 및 특징을 리샘플링하는 과정은 연산 비용이 크고 실시간 적용에 한계가 있습니다.
SSD는 이러한 과정을 제거하여 더 빠른 속도로 실시간 탐지가 가능하게 했습니다. 논문에서는 Faster R-CNN 속도는 느리지만 높은 정확도, YOLO 빠르지만 정확도가 다소 떨어지는 한계를 거론하면서 SSD로 객체 탐지 수행이 두 방식의 장점을 결합한 모델이라 소개합니다.
2. SSD
SSD는 일정한 fixed-size collection의 Bounding Box를 NMS(Nom-maxumum Suppression)를 적용해 객체를 탐지하는 모델입니다.
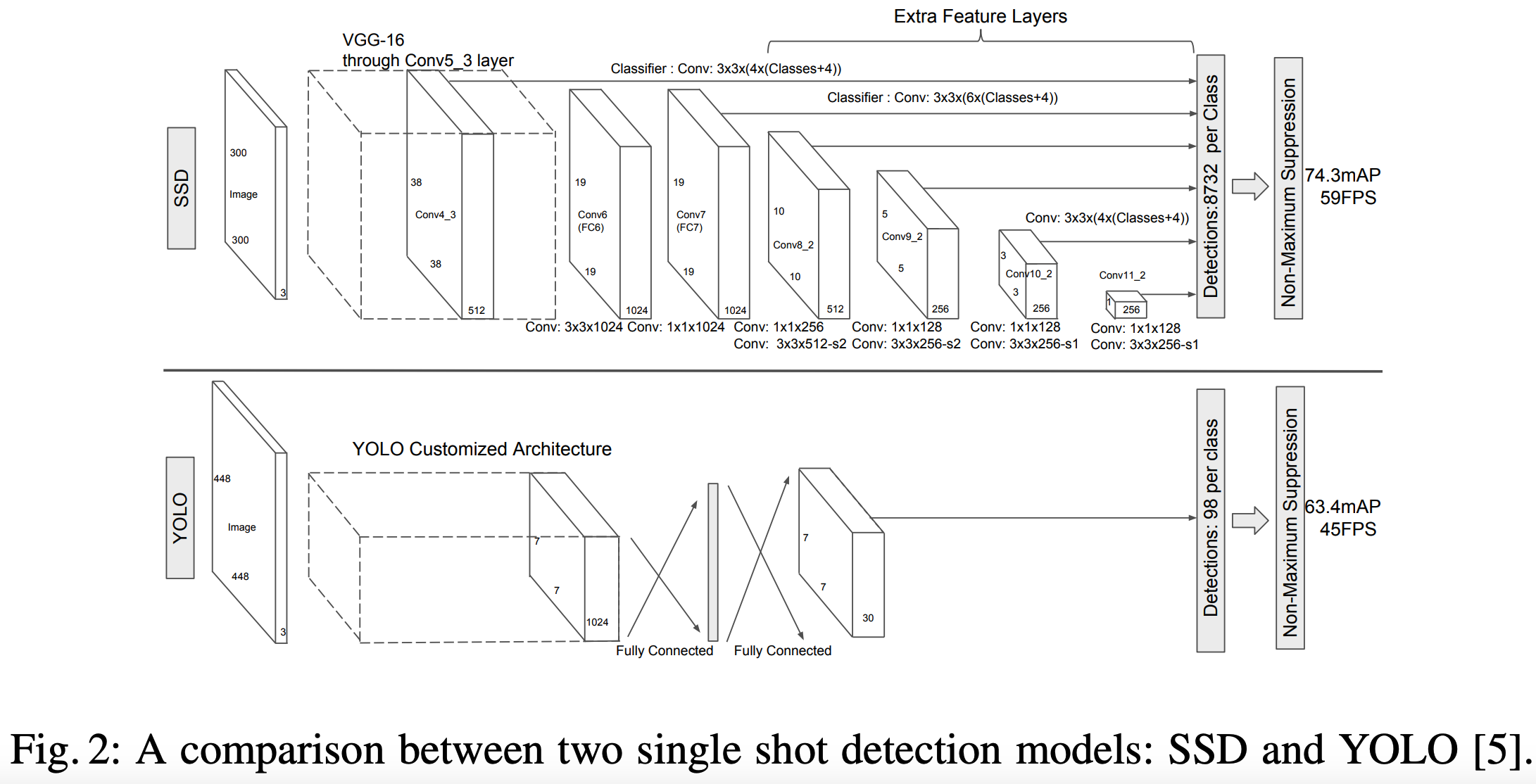
SSD의 구조는 Early Network와 Auxiliary Layers으로 구성됩니다.
Early Network
Base Network로 부르며, VGG16 백본에서 중간 부분을 사용하여 (con4_3) 다양한 특징 맵을 생성하여 추후에 제일 작은 객체를 탐지 및 클래스 점수(카테고리 점수) 예측하는데 사용됩니다.
Auxiliary Network
Auxiliary Network에서는 Base Network에서 나온 후 (con7_3) 여러 단계로 3X3 컨볼루션을 진행하여 점차 크기가 작아진 feature map을 생성하여, 각 층 별로 더 큰 객체를 탐지 및 클래스 점수(카테고리 점수) 예측하는 데 사용됩니다.
1) Multiscale feature maps
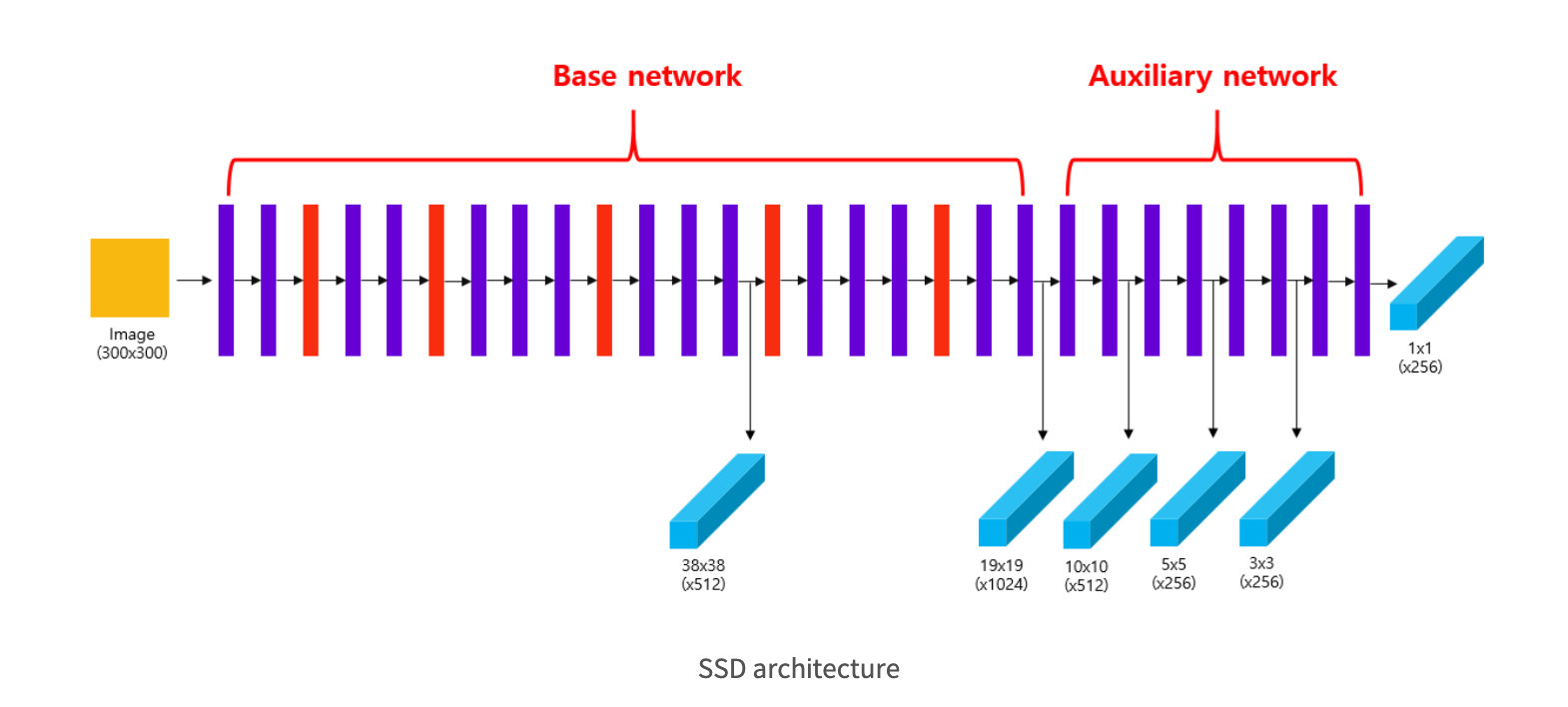
SSD 모델은 YOLO v1 모델과 같게 1-stage detector로 하나의 통합된 네트워크로 detection을 수행합니다. YOLO v1 같은 경우 7X7X30 크기의 feature map만 사용했습니다. 단일한 scale의 feature map을 사용할 경우, 다양한 크기의 객체를 포착하기 여렵다는 단점이 있습니다. 그래서 SSD는 다양한 scale의 feature map을 사용하여 detection을 수행한다는 점이 YOLO v1 과 차이점을 가지고 있습니다.
SSD에서는 Auxiliary Network 부분으로 4개의 conv를 통해서 다양한 크기의 feature map을 생성합니다.
아래 그림을 보면, base network 부분은 con4_3 layer에서 38X38X512, conv7 layer에서 19X19X1024 크기의 feature map을 추출합니다.
auxiliary network 부분은 conv8_2, conv9_2, conv10_2, conv11_2 layer에서 10X10X512, 5X5X256, 3X3X256, 1X1X256 크기의 feature map을 추출합니다.
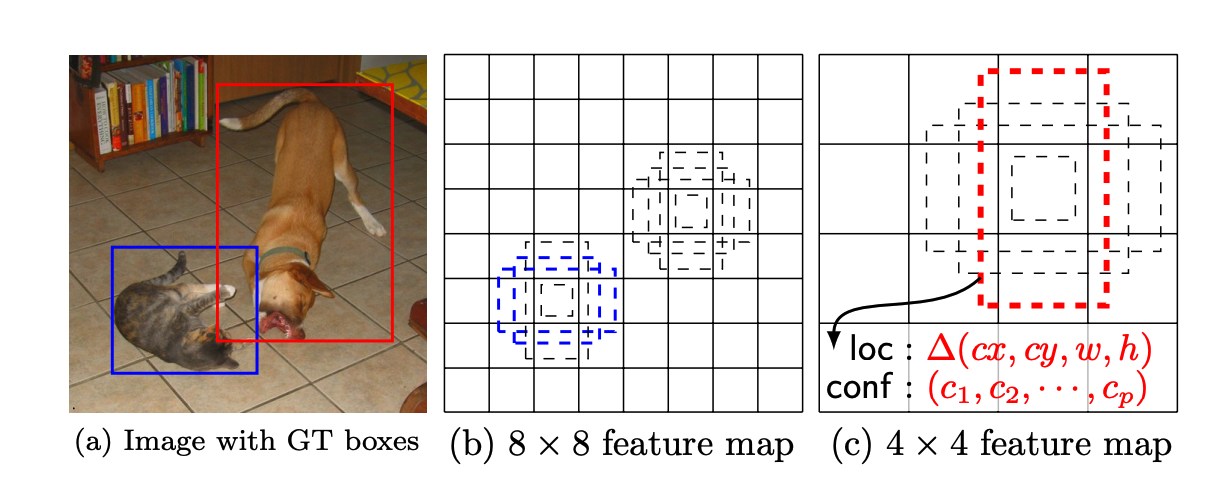
2) Convolutional predictors for detection / Default boxes and aspect ratios
SSD는 각 각 6개층(Base+Auxiliart Network)의 feature map에서 3X3 사이즈의 커널로 p개의 값을 추출합니다.
p = c + 4 (Class + (중심 좌표와의 x, y offset, 영역의 w, h offset))
각 feature map들은 다양한 aspect ratios(직사각형의 가로세로 비율: 1, 2, 0.5, 0.333)로 k개의 default bounding box를 생성하고, c 개의 클래스 점수와 default bounding box의 좌표 4개의 값을 계산합니다.
그렇게 해서 SSD는 총 8732(Bounding boxes, class scores)를 얻습니다.
3. Training
1) Matching Strategy
학습 과정에서 각 Default box가 어떤 Ground truth 와 매칭하는지 결정해야 합니다. 각 Default box는 위치, aspect ratios(비율), 크기가 다르게 나오게되며, 정답지인 Ground truth와 매칭하여 Jaccard Overlab이 가장 높은 박스를 선택하게 됩니다. 그런 다음, 겹쳐진 비율이 0.5 이상인 Default box들을 Ground truth와 최종 매칭합니다.
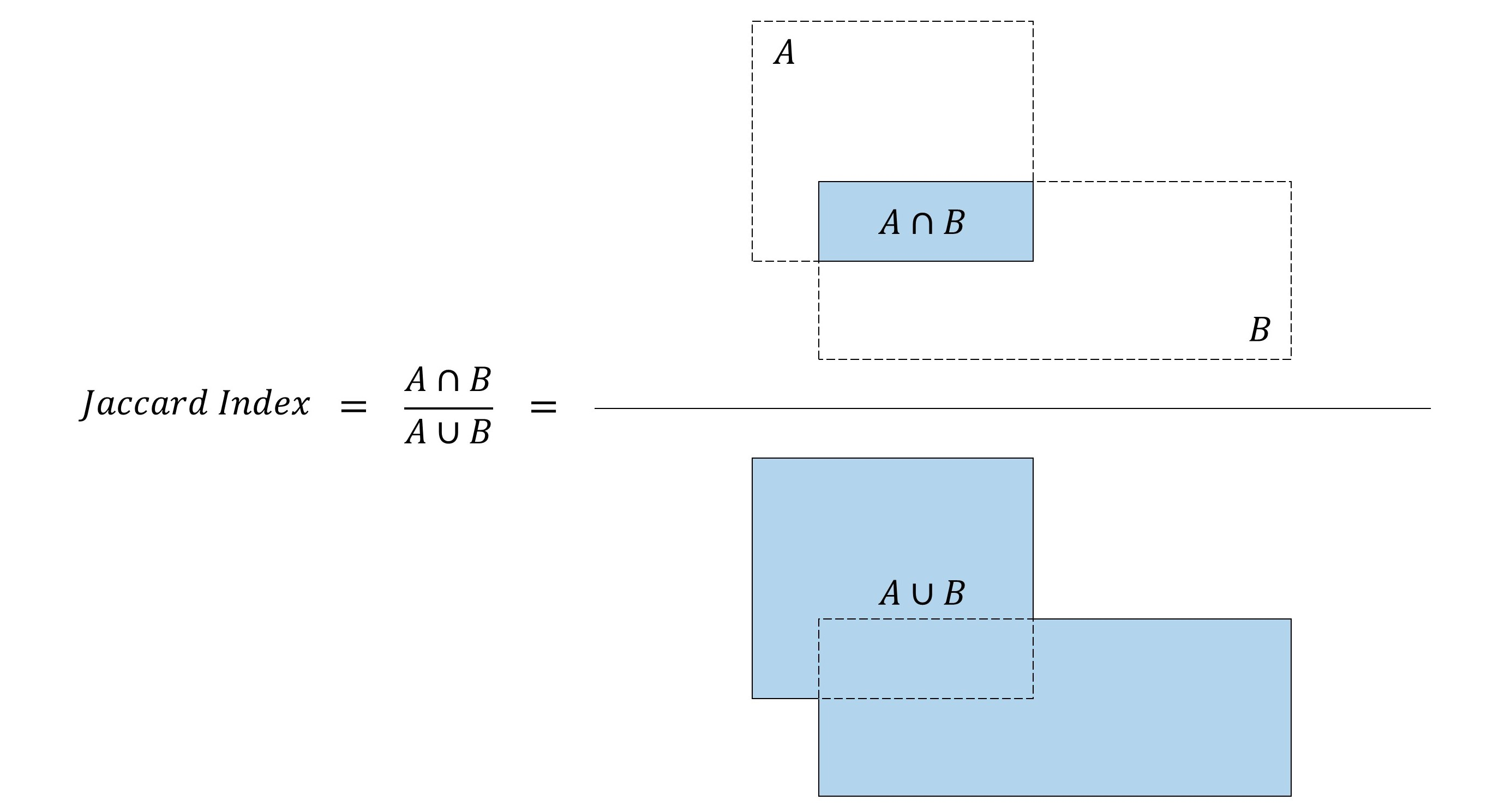
Jaccard Index 또는 Jaccard Overlap 또는 IOU(Intersection-over-Union)이라 불리며, 두 박스가 얼마나 겹치는지를 측정하는 지표로, IoU 값이 1이면 두 박스가 동일, 0 이면 두 박스가 겹쳐지지 않는 것을 의미합니다.
2) Traning Objective
SSD의 학습 목표는, 위에서 설명한 다양한 Box들인 MultiBox에서 유래한 손실함수로, Localization Loss(loc)와 Confidence Loss(conf)의 가중치 합으로 이루어집니다.
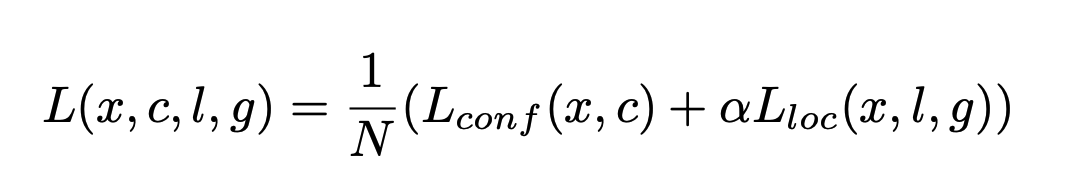
L(x, c, l, g): 전체 손실
x: 각 Default box가 어떤 클래스와 매칭되는지 나타내는 값
c: 클래스 예측 값
l: Localization(예측된 박스 위치 정보)
g: Ground truth(정답 박스)
α: Localization 가중치 (L_conf 와 L_loc 비율을 조정하는 역할을 합니다)
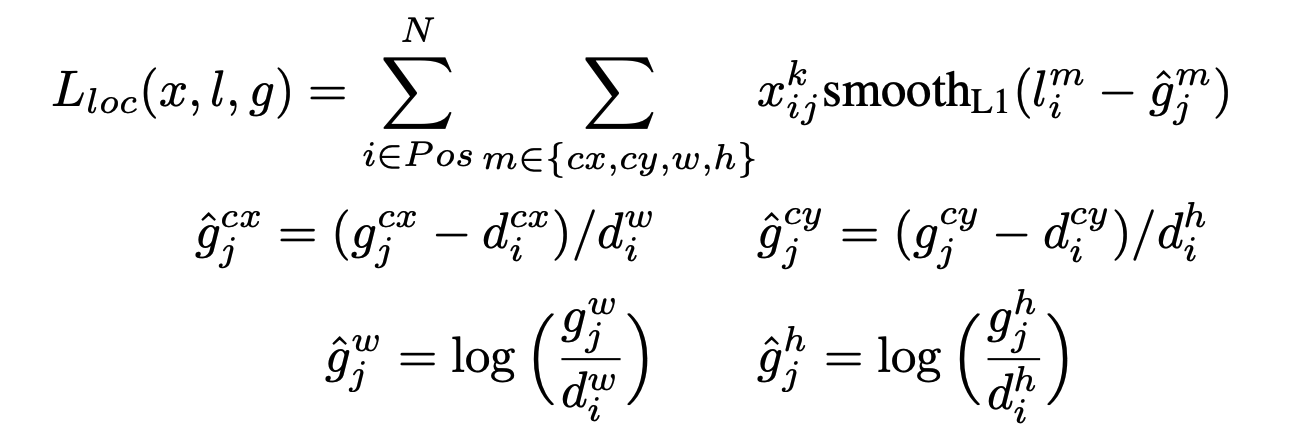
예측된 바운딩 박스와 실제 바운딩 박스의 좌표 간의 차이를 계산합니다. 이때 중심 좌표 (cx, cy)와 크기 (w, h)의 차이를 각각 정규화하고, 이 차이에 대해 Smooth L1 손실을 적용하여 계산합니다.
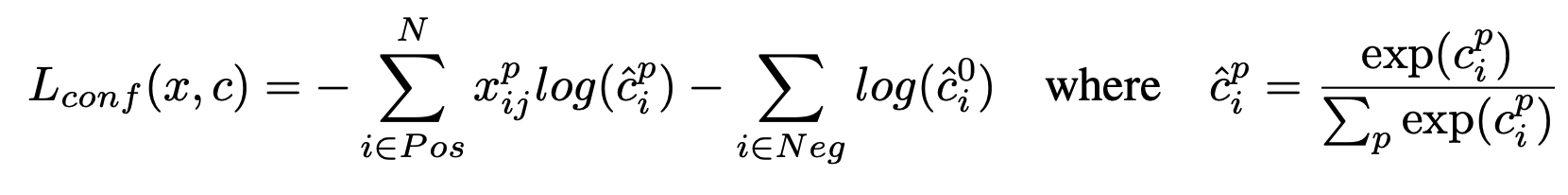
예측한 클래스 확률과 실제 레이블 간의 차이를 측정합니다. 양성 샘플은 객체의 정확한 클래스를 예측하도록 학습되고, 음성 샘플은 객체가 아닌 배경을 예측하도록 학습됩니다.
i ∈ Pos는 양성(positive) 샘플, 즉 객체와 매칭된 디폴트 박스에 대해 계산 (예측 박스 i가 실제 객체 j의 클래스 p와 매칭 되었을 때 1인 지표)
i ∈ Neg는 음성(negative) 샘플, 즉 객체와 매칭되지 않은 디폴트 박스에 대해 계산(예측 박스 i가 객체가 없는 상태(즉, 배경)일 확률을 계산, 음석객체는 객체가 아닌 배경을 예측하도록 학습
3) Choosing scales and aspect ratios for default boxes
SSD 모델에서 Default Boxes 의 Aspect ratio 로 각 feature map에서 다양한 크기와 비율로 설정된 default box를 통해, 모델은 여러 크기의 객체를 적응하여 탐지할 수 있습니다.
SSD는 각 feature map의 크기에 맞춰 작은 객체부터 큰 객체까지 모두 탐지합니다. 첫 번째 feature map에 대해 가장 작은 스케일을, 마지막 feature map에 대해 가장 큰 스케일을 적용하빈다.
예를 들어, 첫 번째 feature map(conv4_3)의 default box는 상대적으로 작은 스케일을 가지며, 마지막 feature map(conv11_2)의 default box는 큰 스케일을 가집니다.
.
여기서,
s_min과 s_max는 최소 및 최대 스케일 값,
m은 feature map의 개수,
k는 현재 feature map의 index를 나타냅니다.
Aspect Ratios
SSD는 aspect ratio로 1:1, 2:1, 3:1, 1:2, 1:3. 이를 통해 정사각형과 직사각형 등의 다양한 형태의 객체를 탐지할 수 있습니다.
1:1 aspect ratio는 정사각형 모양의 박스를 생성하고, 2:1 또는 1:2와 같은 비율은 직사각형 모양의 박스를 생성합니다.
4) Hard Negative Mining
Hard Negative Mining은 양성(positive) 예시와 음성(negative) 예시 간의 불균형을 해결하는 방법입니다.
위의 Confidence Loss(conf)에서 구한 양성(객체와 일치하는 박스) 음성(객체와 매칭되지 않는 박스(배경))으로 양성대 음성 비율을 1:3 으로 조정해서 불균형을 해결 하였습니다.
5) Data Augmentation
SSD 데이터 증강으로는
- 학습 이미지 전체를 그대로 사용
- Jaccard Overlap 기준 샘플링
기준을 0.1, 0.3, 0.5, 0.7, 0.9 중 하나로 설정됩니다. 예를 들어, IoU가 0.5인 패치를 샘플링할 경우, 추출한 패치가 객체와 50% 정도 겹치도록 만듭니다. 이 방식은 모델이 객체를 부분적으로 인식할 수 있도록 도와줍니다. - 랜덤 샘플링
특정 기준없이 랜덤하게 샘플링
4. Code
VGG-16 backbone
class VGGBase(nn.Module):
"""
VGG-16 backbone
"""
def __init__(self):
super(VGGBase, self).__init__()
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, padding=1)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
self.conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
self.load_pretrained_layers()
def forward(self, image):
out = F.relu(self.conv1_1(image)) # (N, 64, 300, 300)
out = F.relu(self.conv1_2(out)) # (N, 64, 300, 300)
out = self.pool1(out) # (N, 64, 150, 150)
out = F.relu(self.conv2_1(out)) # (N, 128, 150, 150)
out = F.relu(self.conv2_2(out)) # (N, 128, 150, 150)
out = self.pool2(out) # (N, 128, 75, 75)
out = F.relu(self.conv3_1(out)) # (N, 256, 75, 75)
out = F.relu(self.conv3_2(out)) # (N, 256, 75, 75)
out = F.relu(self.conv3_3(out)) # (N, 256, 75, 75)
out = self.pool3(out) # (N, 256, 38, 38)
out = F.relu(self.conv4_1(out)) # (N, 512, 38, 38)
out = F.relu(self.conv4_2(out)) # (N, 512, 38, 38)
out = F.relu(self.conv4_3(out)) # (N, 512, 38, 38)
conv4_3_feats = out # (N, 512, 38, 38)
out = self.pool4(out) # (N, 512, 19, 19)
out = F.relu(self.conv5_1(out)) # (N, 512, 19, 19)
out = F.relu(self.conv5_2(out)) # (N, 512, 19, 19)
out = F.relu(self.conv5_3(out)) # (N, 512, 19, 19)
out = self.pool5(out) # (N, 512, 19, 19)
out = F.relu(self.conv6(out)) # (N, 1024, 19, 19)
conv7_feats = F.relu(self.conv7(out)) # (N, 1024, 19, 19)
# Lower-level feature maps
return conv4_3_feats, conv7_feats
사전 학습된 VGG-16 모델 가중치 불러오기
def load_pretrained_layers(self):
# SSD 모델 가중치, 파라미터 가져오기
state_dict = self.state_dict()
param_names = list(state_dict.keys())
# 사전 학습된 VGG-16 모델 가중치 불러오기
pretrained_state_dict = torchvision.models.vgg16(pretrained=True).state_dict()
pretrained_param_names = list(pretrained_state_dict.keys())
# Conv1 ~ Conv5 까지 가중치 복사
for i, param in enumerate(param_names[:-4]):
state_dict[param] = pretrained_state_dict[pretrained_param_names[i]]
# fc6
# VGG-16의 fc6 레이어를 컨볼루션 레이어(conv6)로 변환, fc6의 가중치를 컨볼루션 레이어 형식에 맞게 변환, decimate 함수를 사용하여 크기를 줄임
conv_fc6_weight = pretrained_state_dict['classifier.0.weight'].view(4096, 512, 7, 7) # (4096, 512, 7, 7)
conv_fc6_bias = pretrained_state_dict['classifier.0.bias'] # (4096)
state_dict['conv6.weight'] = decimate(conv_fc6_weight, m=[4, None, 3, 3]) # (1024, 512, 3, 3)
state_dict['conv6.bias'] = decimate(conv_fc6_bias, m=[4]) # (1024)
# fc7
#VGG-16의 fc7 레이어를 컨볼루션 레이어(conv7)로 변환, fc6의 가중치를 컨볼루션 레이어 형식에 맞게 변환, decimate 함수를 사용하여 크기를 줄임
conv_fc7_weight = pretrained_state_dict['classifier.3.weight'].view(4096, 4096, 1, 1) # (4096, 4096, 1, 1)
conv_fc7_bias = pretrained_state_dict['classifier.3.bias'] # (4096)
state_dict['conv7.weight'] = decimate(conv_fc7_weight, m=[4, 4, None, None]) # (1024, 1024, 1, 1)
state_dict['conv7.bias'] = decimate(conv_fc7_bias, m=[4]) # (1024
self.load_state_dict(state_dict)
print("\nLoaded base model.\n")AuxiliaryConvolutions 보조 컨볼루션
채널을 256과 128로 줄이고 다시 늘리는 과정은 모델의 효율성 및 연산량 감소, 다양한 크기의 객체 탐지를 위해서 사용
1x1 컨볼루션을 통해 피처 맵의 채널 수를 줄여 연산을 간소화하고, 3x3 컨볼루션을 통해 다시 채널을 늘려 세밀한 정보를 추출합니다.
class AuxiliaryConvolutions(nn.Module):
def __init__(self):
super(AuxiliaryConvolutions, self).__init__()
self.conv8_1 = nn.Conv2d(1024, 256, kernel_size=1, padding=0) # 1x1 컨볼루션 채널 수 (1024 -> 256)
self.conv8_2 = nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1) # 3x3 컨볼루션, stride=2 해상도 절반, 차원 증가 (256 -> 512)
self.conv9_1 = nn.Conv2d(512, 128, kernel_size=1, padding=0) # 1x1 컨볼루션 채널 수 (512 -> 128)
self.conv9_2 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1) # 3x3 컨볼루션, stride=2 해상도 절반, 차원 증가 (128 -> 256)
self.conv10_1 = nn.Conv2d(256, 128, kernel_size=1, padding=0) # 1x1 컨볼루션 채널 수 (256 -> 128)
self.conv10_2 = nn.Conv2d(128, 256, kernel_size=3, padding=0) # 3x3 컨볼루션, stride=2 해상도 절반, 차원 증가 (128 -> 256)
self.conv11_1 = nn.Conv2d(256, 128, kernel_size=1, padding=0) # 1x1 컨볼루션 채널 수 (256 -> 128)
self.conv11_2 = nn.Conv2d(128, 256, kernel_size=3, padding=0) # 3x3 컨볼루션, 최종 해상도 줄이고 차원은 동일 (128 -> 256)
self.init_conv2d()
# 가중치 초기화
def init_conv2d(self):
for c in self.children():
if isinstance(c, nn.Conv2d):
nn.init.xavier_uniform_(c.weight)
nn.init.constant_(c.bias, 0.)
def forward(self, conv7_feats):
out = F.relu(self.conv8_1(conv7_feats)) # (N, 256, 19, 19)
out = F.relu(self.conv8_2(out)) # (N, 512, 10, 10)
conv8_2_feats = out # (N, 512, 10, 10)
out = F.relu(self.conv9_1(out)) # (N, 128, 10, 10)
out = F.relu(self.conv9_2(out)) # (N, 256, 5, 5)
conv9_2_feats = out # (N, 256, 5, 5)
out = F.relu(self.conv10_1(out)) # (N, 128, 5, 5)
out = F.relu(self.conv10_2(out)) # (N, 256, 3, 3)
conv10_2_feats = out # (N, 256, 3, 3)
out = F.relu(self.conv11_1(out)) # (N, 128, 3, 3)
conv11_2_feats = F.relu(self.conv11_2(out)) # (N, 256, 1, 1)
return conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_featsPrediction Convolutions
class PredictionConvolutions(nn.Module):
def __init__(self, n_classes):
super(PredictionConvolutions, self).__init__()
self.n_classes = n_classes
# 각 피처 맵에서 사용할 prior-boxes의 개수 지정
n_boxes = {'conv4_3': 4,
'conv7': 6,
'conv8_2': 6,
'conv9_2': 6,
'conv10_2': 4,
'conv11_2': 4}
# Localization Prediction Convolutions : 각 피처 맵에서 박스 좌표 예측
self.loc_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * 4, kernel_size=3, padding=1)
self.loc_conv7 = nn.Conv2d(1024, n_boxes['conv7'] * 4, kernel_size=3, padding=1)
self.loc_conv8_2 = nn.Conv2d(512, n_boxes['conv8_2'] * 4, kernel_size=3, padding=1)
self.loc_conv9_2 = nn.Conv2d(256, n_boxes['conv9_2'] * 4, kernel_size=3, padding=1)
self.loc_conv10_2 = nn.Conv2d(256, n_boxes['conv10_2'] * 4, kernel_size=3, padding=1)
self.loc_conv11_2 = nn.Conv2d(256, n_boxes['conv11_2'] * 4, kernel_size=3, padding=1)
# Class Prediction Convolutions : 각 피처 맵에서 클래스 확률 예측
self.cl_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * n_classes, kernel_size=3, padding=1)
self.cl_conv7 = nn.Conv2d(1024, n_boxes['conv7'] * n_classes, kernel_size=3, padding=1)
self.cl_conv8_2 = nn.Conv2d(512, n_boxes['conv8_2'] * n_classes, kernel_size=3, padding=1)
self.cl_conv9_2 = nn.Conv2d(256, n_boxes['conv9_2'] * n_classes, kernel_size=3, padding=1)
self.cl_conv10_2 = nn.Conv2d(256, n_boxes['conv10_2'] * n_classes, kernel_size=3, padding=1)
self.cl_conv11_2 = nn.Conv2d(256, n_boxes['conv11_2'] * n_classes, kernel_size=3, padding=1)
# 가중치 초기화
self.init_conv2d()
def init_conv2d(self):
for c in self.children():
if isinstance(c, nn.Conv2d):
nn.init.xavier_uniform_(c.weight)
nn.init.constant_(c.bias, 0.)
def forward(self, conv4_3_feats, conv7_feats, conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats):
"""
conv4_3 : (N, 512, 38, 38)
conv7 : (N, 1024, 19, 19)
conv8_2 : (N, 512, 10, 10)
conv9_2 : (N, 256, 5, 5)
conv10_2 : (N, 256, 3, 3)
conv11_2 : (N, 256, 1, 1)
return : 8732 locations, class scores
"""
batch_size = conv4_3_feats.size(0)
# Localization
l_conv4_3 = self.loc_conv4_3(conv4_3_feats) # (N, 16, 38, 38)
l_conv4_3 = l_conv4_3.permute(0, 2, 3, 1).contiguous() # (N, 38, 38, 16)
l_conv4_3 = l_conv4_3.view(batch_size, -1, 4) # (N, 5776, 4)
l_conv7 = self.loc_conv7(conv7_feats) # (N, 24, 19, 19)
l_conv7 = l_conv7.permute(0, 2, 3, 1).contiguous() # (N, 19, 19, 24)
l_conv7 = l_conv7.view(batch_size, -1, 4) # (N, 2166, 4)
l_conv8_2 = self.loc_conv8_2(conv8_2_feats) # (N, 24, 10, 10)
l_conv8_2 = l_conv8_2.permute(0, 2, 3, 1).contiguous() # (N, 10, 10, 24)
l_conv8_2 = l_conv8_2.view(batch_size, -1, 4) # (N, 600, 4)
l_conv9_2 = self.loc_conv9_2(conv9_2_feats) # (N, 24, 5, 5)
l_conv9_2 = l_conv9_2.permute(0, 2, 3, 1).contiguous() # (N, 5, 5, 24)
l_conv9_2 = l_conv9_2.view(batch_size, -1, 4) # (N, 150, 4)
l_conv10_2 = self.loc_conv10_2(conv10_2_feats) # (N, 16, 3, 3)
l_conv10_2 = l_conv10_2.permute(0, 2, 3, 1).contiguous() # (N, 3, 3, 16)
l_conv10_2 = l_conv10_2.view(batch_size, -1, 4) # (N, 36, 4)
l_conv11_2 = self.loc_conv11_2(conv11_2_feats) # (N, 16, 1, 1)
l_conv11_2 = l_conv11_2.permute(0, 2, 3, 1).contiguous() # (N, 1, 1, 16)
l_conv11_2 = l_conv11_2.view(batch_size, -1, 4) # (N, 4, 4)
# Classes scores
c_conv4_3 = self.cl_conv4_3(conv4_3_feats) # (N, 4 * n_classes, 38, 38)
c_conv4_3 = c_conv4_3.permute(0, 2, 3, 1).contiguous() # (N, 38, 38, 4 * n_classes)
c_conv4_3 = c_conv4_3.view(batch_size, -1, self.n_classes) # (N, 5776, n_classes)
c_conv7 = self.cl_conv7(conv7_feats) # (N, 6 * n_classes, 19, 19)
c_conv7 = c_conv7.permute(0, 2, 3, 1).contiguous() # (N, 19, 19, 6 * n_classes)
c_conv7 = c_conv7.view(batch_size, -1, self.n_classes) # (N, 2166, n_classes)
c_conv8_2 = self.cl_conv8_2(conv8_2_feats) # (N, 6 * n_classes, 10, 10)
c_conv8_2 = c_conv8_2.permute(0, 2, 3, 1).contiguous() # (N, 10, 10, 6 * n_classes)
c_conv8_2 = c_conv8_2.view(batch_size, -1, self.n_classes) # (N, 600, n_classes)
c_conv9_2 = self.cl_conv9_2(conv9_2_feats) # (N, 6 * n_classes, 5, 5)
c_conv9_2 = c_conv9_2.permute(0, 2, 3, 1).contiguous() # (N, 5, 5, 6 * n_classes)
c_conv9_2 = c_conv9_2.view(batch_size, -1, self.n_classes) # (N, 150, n_classes)
c_conv10_2 = self.cl_conv10_2(conv10_2_feats) # (N, 4 * n_classes, 3, 3)
c_conv10_2 = c_conv10_2.permute(0, 2, 3, 1).contiguous() # (N, 3, 3, 4 * n_classes)
c_conv10_2 = c_conv10_2.view(batch_size, -1, self.n_classes) # (N, 36, n_classes)
c_conv11_2 = self.cl_conv11_2(conv11_2_feats) # (N, 4 * n_classes, 1, 1)
c_conv11_2 = c_conv11_2.permute(0, 2, 3, 1).contiguous() # (N, 1, 1, 4 * n_classes)
c_conv11_2 = c_conv11_2.view(batch_size, -1, self.n_classes) # (N, 4, n_classes)
# 8732 boxes
locs = torch.cat([l_conv4_3, l_conv7, l_conv8_2, l_conv9_2, l_conv10_2, l_conv11_2], dim=1) # (N, 8732, 4)
classes_scores = torch.cat([c_conv4_3, c_conv7, c_conv8_2, c_conv9_2, c_conv10_2, c_conv11_2], dim=1) # (N, 8732, n_classes)
return locs, classes_scoresSSD Model
class SSD300(nn.Module):
def __init__(self, n_classes):
super(SSD300, self).__init__()
self.n_classes = n_classes
self.base = VGGBase()
self.aux_convs = AuxiliaryConvolutions()
self.pred_convs = PredictionConvolutions(n_classes)
# conv4_3 L2 정규화 (Vgg feature map 고해상도이기에 스케일 조정)
# 피처 맵에 가중치를 부여하여 작은 객체의 특징을 더 부각하는 데 사용
self.rescale_factors = nn.Parameter(torch.FloatTensor(1, 512, 1, 1))
nn.init.constant_(self.rescale_factors, 20)
# Prior boxes
self.priors_cxcy = self.create_prior_boxes()
def forward(self, image):
conv4_3_feats, conv7_feats = self.base(image) # (N, 512, 38, 38), (N, 1024, 19, 19)
# L2 정규화 및 Rescaling
norm = conv4_3_feats.pow(2).sum(dim=1, keepdim=True).sqrt() # (N, 1, 38, 38)
conv4_3_feats = conv4_3_feats / norm # (N, 512, 38, 38)
conv4_3_feats = conv4_3_feats * self.rescale_factors # (N, 512, 38, 38)
# Auxiliary Convolutions
conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats = \
self.aux_convs(conv7_feats) # (N, 512, 10, 10), (N, 256, 5, 5), (N, 256, 3, 3), (N, 256, 1, 1)
# Prediction Convolutions
locs, classes_scores = self.pred_convs(conv4_3_feats, conv7_feats, conv8_2_feats, conv9_2_feats, conv10_2_feats,
conv11_2_feats) # (N, 8732, 4), (N, 8732, n_classes)
return locs, classes_scores
def create_prior_boxes(self):
fmap_dims = {'conv4_3': 38,
'conv7': 19,
'conv8_2': 10,
'conv9_2': 5,
'conv10_2': 3,
'conv11_2': 1}
obj_scales = {'conv4_3': 0.1,
'conv7': 0.2,
'conv8_2': 0.375,
'conv9_2': 0.55,
'conv10_2': 0.725,
'conv11_2': 0.9}
aspect_ratios = {'conv4_3': [1., 2., 0.5],
'conv7': [1., 2., 3., 0.5, .333],
'conv8_2': [1., 2., 3., 0.5, .333],
'conv9_2': [1., 2., 3., 0.5, .333],
'conv10_2': [1., 2., 0.5],
'conv11_2': [1., 2., 0.5]}
fmaps = list(fmap_dims.keys())
prior_boxes = []
for k, fmap in enumerate(fmaps):
for i in range(fmap_dims[fmap]):
for j in range(fmap_dims[fmap]):
cx = (j + 0.5) / fmap_dims[fmap]
cy = (i + 0.5) / fmap_dims[fmap]
for ratio in aspect_ratios[fmap]:
prior_boxes.append([cx, cy, obj_scales[fmap] * sqrt(ratio), obj_scales[fmap] / sqrt(ratio)])
if ratio == 1.:
try:
additional_scale = sqrt(obj_scales[fmap] * obj_scales[fmaps[k + 1]])
except IndexError:
additional_scale = 1.
prior_boxes.append([cx, cy, additional_scale, additional_scale])
prior_boxes = torch.FloatTensor(prior_boxes).to(device) # (8732, 4)
prior_boxes.clamp_(0, 1) # (8732, 4)
return prior_boxescreate prior boxes
1) Aspect ratio
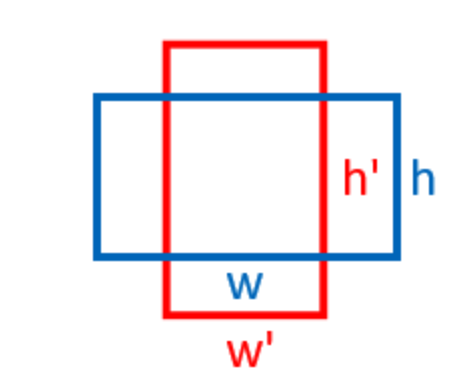
ex) conv4_3 피처 맵:
-
object 스케일은 0.1
-
aspect ratio [1., 2., 0.5]
1 = 정사각형
2 = 가로가 세로보다 2배긴 직사각형(빨간색 box)
0.5 = 세로가 2배긴 직사각형(파란색 box)
각 위치에서 prior box의 크기는 다음과 같이 계산됩니다.
-
Aspect ratio 1:
- width:
- height:
-
Aspect ratio 2:
- width:
- height:
-
Aspect ratio 0.5:
- width:
- height:
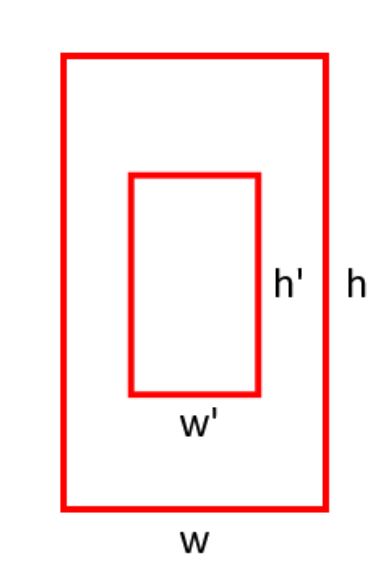
2) Object scale
위 그림은 같은 aspect ratio를 가지진만 다른 Scale로 다른 Box 가 나오는 예시
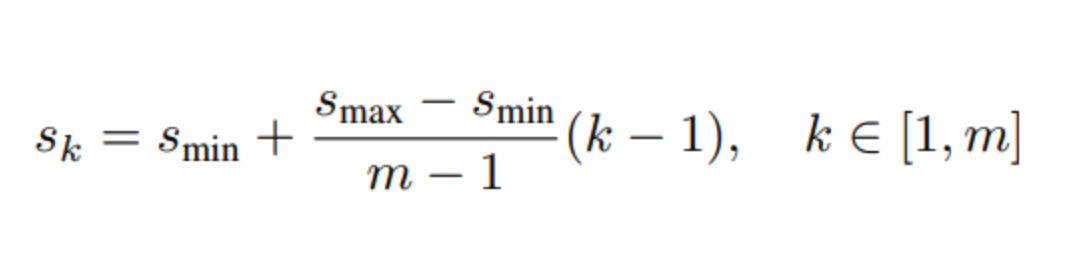 $m$ : 몇 개의 feature map (con7 ~ conv11_2 5개)
$s_k$ : scalre of $k^{th}$ layer
smin : 0.2 (단, PASCAL VOC 2007 에서 conv4_3 의 scale 을 0.1 로 setting)
smax : 0.9
$m$ : 몇 개의 feature map (con7 ~ conv11_2 5개)
$s_k$ : scalre of $k^{th}$ layer
smin : 0.2 (단, PASCAL VOC 2007 에서 conv4_3 의 scale 을 0.1 로 setting)
smax : 0.9
-
= 0.1 (PASCAL VOC 2007 에서 conv4_3 의 scale 을 0.1 로 setting)
-
= smin = 0.2 (k=1 이므로 뒤의항 없어짐)
-
= = = = 0.375
-
= = = = 0.55
-
= = = = 0.725
-
= = = = 0.9
따라서 conv4_3 부터 conv11_2 까지 각 [0.1, 0.2, 0.375, 0.55, 0.725, 0.9] 의 scale 을 갖습니다.
3) Prior box
각 feature map의 크기와 각 feature map의 n_boxes의 갯수로 Total prior box 계산
n_boxes 갯수 및 feature map 크기
1. 'conv4_3': 4 (38 x 38) = 38 x 38 x 4 = 5776 -> 작은 객체 탐지
-
'conv7': 6 (19 x 19) = 19 x 19 x 6 = 2166 -> 중간 크기 객체 탐지
-
'conv8_2': 6 (10 x 10) = 10 x 10 x 6 = 600 -> 중간 크기 객체
-
'conv9_2': 6 (5 x 5) = 5 x 5 x 6 = 150 -> 더 큰 객체 탐지
-
'conv10_2': 4 (3 x 3) = 3 x 3 x 4 = 36 -> 큰 객체 탐지
-
'conv11_2': 4 (1 x 1) = 1 x 1 x 4 = 4 -> 매우 큰 객체 탐지
Total prior box = 8732
def detect_objects(self, predicted_locs, predicted_scores, min_score, max_overlap, top_k):
"""
Eval.py
det_boxes_batch, det_labels_batch, det_scores_batch = model.detect_objects(predicted_locs, predicted_scores,
min_score=0.01, max_overlap=0.45,
top_k=200)
predicted_locs : SSD가 예측한 바운딩 박스 좌표 (M, 8732, 4)
predicted_scores : 각 prior box에 대한 클래스 확률 (N, 8732, n_classes)
min_score : 클래스 예측 확률의 기준 값 (값 이상일 때만 객체 인식)
max_overlap : NMS를 적용하는 겹침의 기준 값 (값 이하일 경우 바운딩 박스 제거)
top_k : 각 이미지에서 최종적으로 남길 객체의 상위 k개만 유지
"""
batch_size = predicted_locs.size(0)
n_priors = self.priors_cxcy.size(0)
predicted_scores = F.softmax(predicted_scores, dim=2) # (N, 8732, n_classes) # 예측된 클래스 확률에 softmax 함수로 변환 클래스 확률 분포생성
all_images_boxes = list()
all_images_labels = list()
all_images_scores = list()
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)
# 각 배치별로 이미지 처리
# 좌표 생성 함수 (utils.py)
for i in range(batch_size):
decoded_locs = cxcy_to_xy(
gcxgcy_to_cxcy(predicted_locs[i], self.priors_cxcy)) # (8732, 4)
image_boxes = list()
image_labels = list()
image_scores = list()
max_scores, best_label = predicted_scores[i].max(dim=1) # (8732)
# 클래스별로 탐지된 객체 확인
# 클래스 1 : 배경
for c in range(1, self.n_classes):
class_scores = predicted_scores[i][:, c] # (8732)
score_above_min_score = class_scores > min_score # 기준값 이상 박스만
n_above_min_score = score_above_min_score.sum().item()
if n_above_min_score == 0:
continue
class_scores = class_scores[score_above_min_score] # (n_qualified), n_min_score <= 8732
class_decoded_locs = decoded_locs[score_above_min_score] # (n_qualified, 4)
class_scores, sort_ind = class_scores.sort(dim=0, descending=True) # (n_qualified), (n_min_score)
class_decoded_locs = class_decoded_locs[sort_ind] # (n_min_score, 4)
# NMS : find_jaccard_overlap(utils.py) 함수로 IoU 계산
overlap = find_jaccard_overlap(class_decoded_locs, class_decoded_locs) # (n_qualified, n_min_score)
# Non-Maximum Suppression (NMS)
suppress = torch.zeros((n_above_min_score), dtype=torch.uint8).to(device) # (n_qualified)
for box in range(class_decoded_locs.size(0)):
if suppress[box] == 1:
continue
suppress[box] = 0
# 기준을 통과한 바운딩 박스, 클레스 라벨 및 클래스 확률 저장
image_boxes.append(class_decoded_locs[1 - suppress])
image_labels.append(torch.LongTensor((1 - suppress).sum().item() * [c]).to(device))
image_scores.append(class_scores[1 - suppress])
# 객체 탐지 안될 경우 -> 배경으로 간주되어 바운딩 박스, 클레스 라벨 저장
if len(image_boxes) == 0:
image_boxes.append(torch.FloatTensor([[0., 0., 1., 1.]]).to(device))
image_labels.append(torch.LongTensor([0]).to(device))
image_scores.append(torch.FloatTensor([0.]).to(device))
image_boxes = torch.cat(image_boxes, dim=0) # (n_objects, 4)
image_labels = torch.cat(image_labels, dim=0) # (n_objects)
image_scores = torch.cat(image_scores, dim=0) # (n_objects)
n_objects = image_scores.size(0)
# 탐지된 상자 중 상위 k개만 남기기
if n_objects > top_k:
image_scores, sort_ind = image_scores.sort(dim=0, descending=True)
image_scores = image_scores[:top_k] # (top_k)
image_boxes = image_boxes[sort_ind][:top_k] # (top_k, 4)
image_labels = image_labels[sort_ind][:top_k] # (top_k)
all_images_boxes.append(image_boxes)
all_images_labels.append(image_labels)
all_images_scores.append(image_scores)
return all_images_boxes, all_images_labels, all_images_scores # lists of length batch_size
Multi Box Loss
class MultiBoxLoss(nn.Module):
def __init__(self, priors_cxcy, threshold=0.5, neg_pos_ratio=3, alpha=1.):
"""
priors_cxcy : Prior Boxes
threshold : IoU 임계값 (값 이상일 때 Positive로 간주)
neg_pos_ratio : Negative-to-positive 비율로, 논문에서는 3:1 비율
alpha : Localizatioin Loss와 Confidence Loss 간의 가중치 설정하는 파라미터
smooth_l1 : Localization Loss 계산을 위한 Smooth L1 Loss
cross_entropy : Confidence Loss 계산을 위한 Cross Entropy Loss
"""
super(MultiBoxLoss, self).__init__()
self.priors_cxcy = priors_cxcy
self.priors_xy = cxcy_to_xy(priors_cxcy)
self.threshold = threshold
self.neg_pos_ratio = neg_pos_ratio
self.alpha = alpha
self.smooth_l1 = nn.L1Loss()
self.cross_entropy = nn.CrossEntropyLoss(reduce=False)
# 모델이 예측한 Bounding Box 좌표, Class 확률
def forward(self, predicted_locs, predicted_scores, boxes, labels):
batch_size = predicted_locs.size(0)
n_priors = self.priors_cxcy.size(0)
n_classes = predicted_scores.size(2)
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)
# True locs, True classs 텐서 초기화후 실제 정답값들 저장
true_locs = torch.zeros((batch_size, n_priors, 4), dtype=torch.float).to(device) # (N, 8732, 4)
true_classes = torch.zeros((batch_size, n_priors), dtype=torch.long).to(device) # (N, 8732)
for i in range(batch_size):
n_objects = boxes[i].size(0)
# 각 이미지에 대해 prior box와 정답(Ground Truth)과 매칭
# find_jaccard_overlap 함수로 IoU 계산
overlap = find_jaccard_overlap(boxes[i],
self.priors_xy) # (n_objects, 8732)
overlap_for_each_prior, object_for_each_prior = overlap.max(dim=0) # (8732) # overlap.map(dim=0) prior box에 대해 IoU가 가장큰 객체를 선택
_, prior_for_each_object = overlap.max(dim=1) # (N_o) # 각 정답 객체와 가장 많이 겹치는 Prior box 선택
object_for_each_prior[prior_for_each_object] = torch.LongTensor(range(n_objects)).to(device)
overlap_for_each_prior[prior_for_each_object] = 1. # 정답과 prior box 간의 IoU 값을 1로 설정 -> 완벽하게 맞는 것으로 간주
# Positive or Negative 식별
# IoU 값이 Threshold 기준 미만이면 Negarive -> 배경으로 간주
label_for_each_prior = labels[i][object_for_each_prior] # (8732)
label_for_each_prior[overlap_for_each_prior < self.threshold] = 0 # (8732)
true_classes[i] = label_for_each_prior
true_locs[i] = cxcy_to_gcxgcy(xy_to_cxcy(boxes[i][object_for_each_prior]), self.priors_cxcy) # (8732, 4)
positive_priors = true_classes != 0 # (N, 8732) # Posive Prior Box
# LOCALIZATION LOSS
# Positive prior box 좌표와 정답 좌표간의 차이를 Smooth L1 Loss로 계산
loc_loss = self.smooth_l1(predicted_locs[positive_priors], true_locs[positive_priors]) # (), scalar
# CONFIDENCE LOSS
# Positive와 Negative에 대한 계산을 Hard Negative Mining을 사용하여 Negative 예측이 너무 많이 학습되지 않게 제어
n_positives = positive_priors.sum(dim=1) # (N)
n_hard_negatives = self.neg_pos_ratio * n_positives # (N)
conf_loss_all = self.cross_entropy(predicted_scores.view(-1, n_classes), true_classes.view(-1)) # (N * 8732)
conf_loss_all = conf_loss_all.view(batch_size, n_priors) # (N, 8732)
conf_loss_pos = conf_loss_all[positive_priors] # (sum(n_positives))
conf_loss_neg = conf_loss_all.clone() # (N, 8732)
conf_loss_neg[positive_priors] = 0. # (N, 8732)
conf_loss_neg, _ = conf_loss_neg.sort(dim=1, descending=True) # (N, 8732)
hardness_ranks = torch.LongTensor(range(n_priors)).unsqueeze(0).expand_as(conf_loss_neg).to(device) # (N, 8732)
hard_negatives = hardness_ranks < n_hard_negatives.unsqueeze(1) # (N, 8732)
conf_loss_hard_neg = conf_loss_neg[hard_negatives] # (sum(n_hard_negatives))
conf_loss = (conf_loss_hard_neg.sum() + conf_loss_pos.sum()) / n_positives.sum().float() # (), scalar
# TOTAL LOSS
return conf_loss + self.alpha * loc_loss
