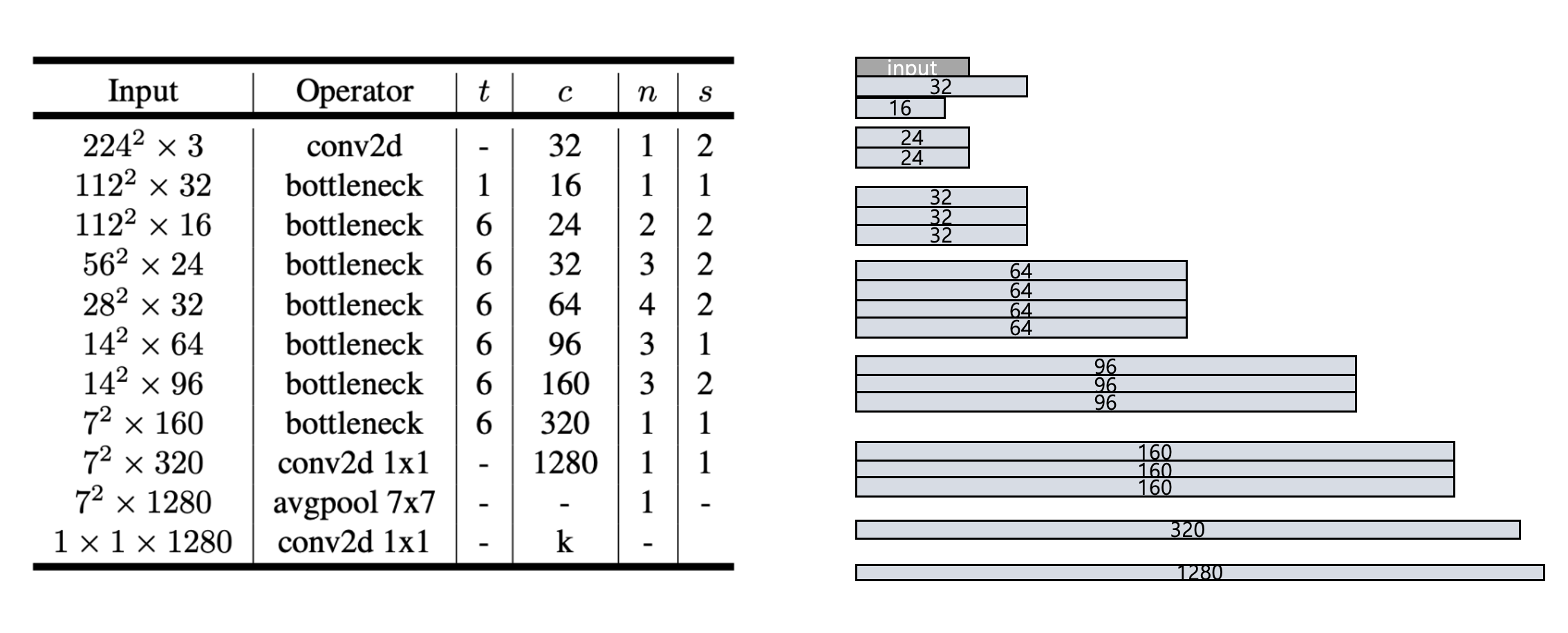
1. MobilnetV2 Backbone
기존 MobilenetV2 Model Architecture (input: 300x300)
| 층 (Layer) | 출력 채널 수 (Output Channels) | Feature Map 크기 (Feature Map Size) |
|---|---|---|
| 입력 이미지 (Input Image) | 3 | 300 × 300 |
| Conv2d (stride=2, kernel=3x3) | 32 | 150 × 150 |
| Bottleneck 1 (stride=1) | 16 | 150 × 150 |
| Bottleneck 2 (stride=2) | 24 | 75 × 75 |
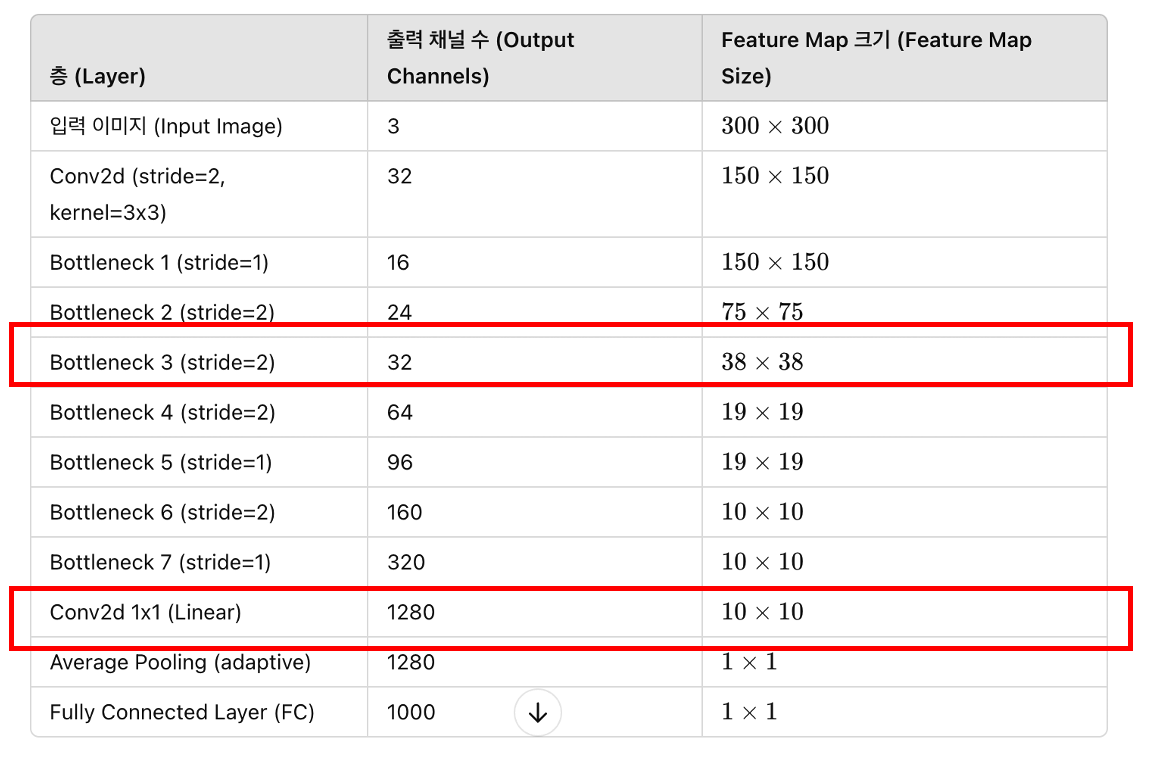
| Bottleneck 3 (stride=2) | 32 | 38 × 38 |
| Bottleneck 4 (stride=2) | 64 | 19 × 19 |
| Bottleneck 5 (stride=1) | 96 | 19 × 19 |
| Bottleneck 6 (stride=2) | 160 | 10 × 10 |
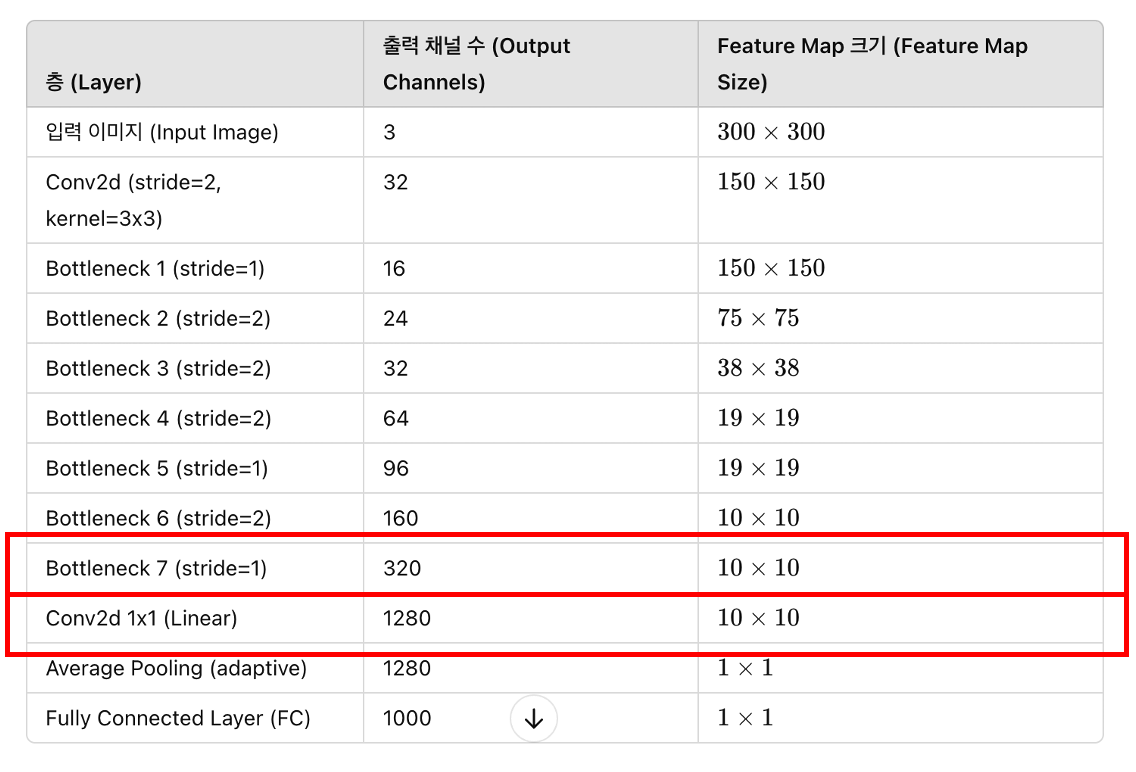
| Bottleneck 7 (stride=1) | 320 | 10 × 10 |
| Conv2d 1x1 (Linear) | 1280 | 10 × 10 |
| Average Pooling (adaptive) | 1280 | 1 × 1 |
| Fully Connected Layer (FC) | 1000 | 1 × 1 |
1) 모델 구조 개선
SSD 모델의 백본으로 사용하기 위해서 4가지 방법으로 모델 구조를 개선하여서 실험을 진행
목표 : MobilenetV2의 모델 속도를 위한 flop-efficient한 Bottleneck 구조의 조정으로 Feature가 부족하지 않게 모델 구조 개선
Experiment 1.
실험 1
Bottleneck 7번과 마지막 출력인 Linear Block을 사용하여 Base Network로 설정
class MobileNetV2Base(nn.Module):
def __init__(self):
super(MobileNetV2Base, self).__init__()
# First convolution layer
self.first_conv = nn.Sequential(
nn.Conv2d(3, 32, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True)
)
# Bottleneck layers (inverted residual blocks)
self.bottlenecks = nn.Sequential(
self._make_stage(32, 16, t=1, n=1),
self._make_stage(16, 24, t=6, n=2, stride=2),
self._make_stage(24, 32, t=6, n=3, stride=2),
self._make_stage(32, 64, t=6, n=4, stride=2),
self._make_stage(64, 96, t=6, n=3),
self._make_stage(96, 160, t=6, n=3, stride=2),
self._make_stage(160, 320, t=6, n=1)
)
# Last convolution layer in MobileNetV2
self.last_conv = nn.Sequential(
nn.Conv2d(320, 1280, 1, bias=False),
nn.BatchNorm2d(1280),
nn.ReLU6(inplace=True)
)
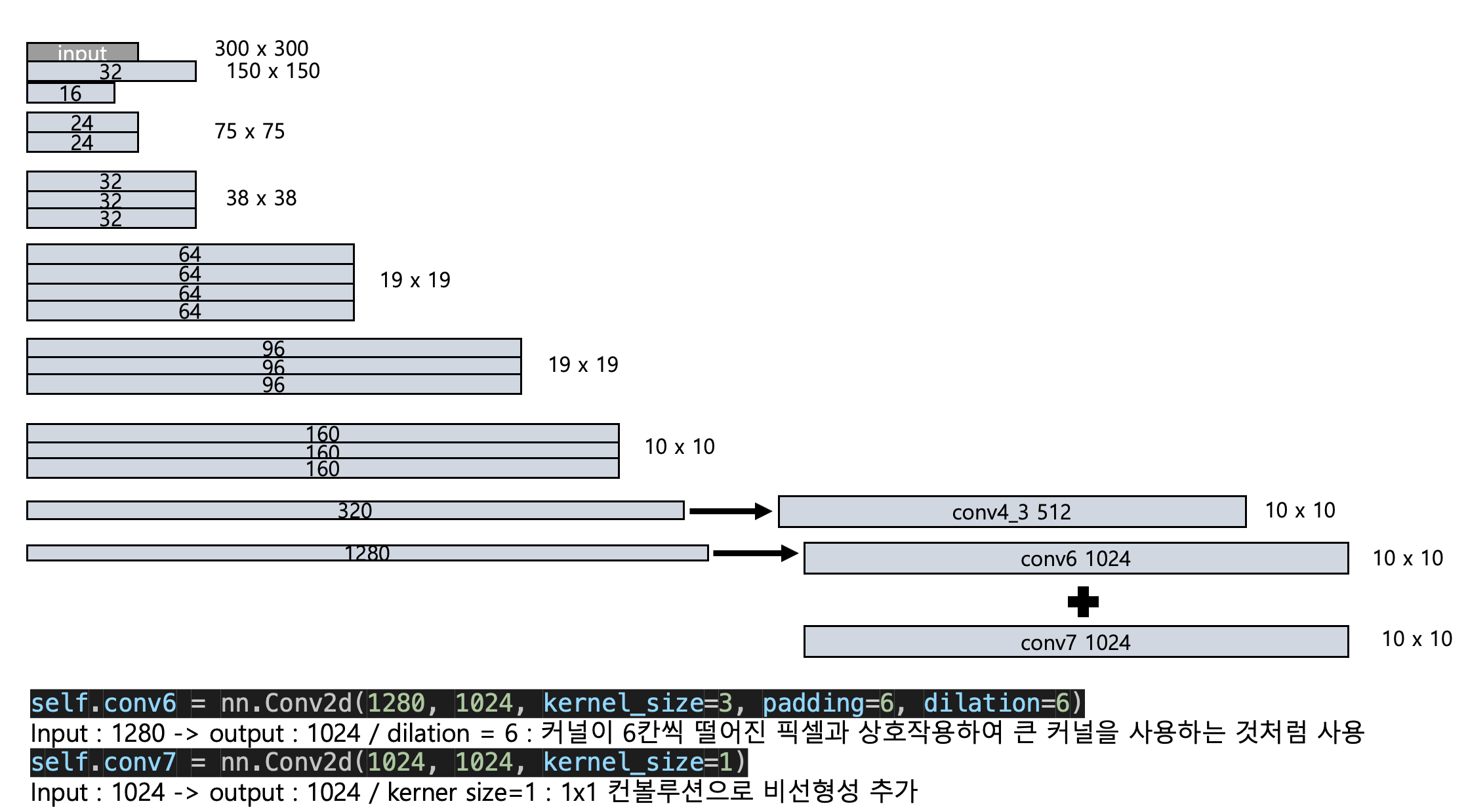
# Additional layers for SSD (conv6, conv7)
self.conv6 = nn.Conv2d(1280, 1024, kernel_size=3, padding=6, dilation=6) # atrous convolution
self.conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
# Adjust conv4_3 feature map to have 512 channels
self.conv4_3_adjust = nn.Conv2d(320, 512, kernel_size=1)
Result
Total prior boxes : 1212
Localization output shape: torch.Size([1, 1212, 4])
Class scores output shape: torch.Size([1, 1212, 21])
Experiment 2.
실험2
Bottleneck 3번과 마지막 출력인 Linear block을 사용하여 Base Network로 설정
class MobileNetV2Base(nn.Module):
def __init__(self):
super(MobileNetV2Base, self).__init__()
# First convolution layer
self.first_conv = nn.Sequential(
nn.Conv2d(3, 32, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True)
)
# Bottleneck layers (inverted residual blocks)
self.bottlenecks = nn.Sequential(
self._make_stage(32, 16, t=1, n=1),
self._make_stage(16, 24, t=6, n=2, stride=2),
self._make_stage(24, 32, t=6, n=3, stride=2),
self._make_stage(32, 64, t=6, n=4, stride=2),
self._make_stage(64, 96, t=6, n=3),
self._make_stage(96, 160, t=6, n=3, stride=2),
self._make_stage(160, 320, t=6, n=1)
)
# Last convolution layer in MobileNetV2
self.last_conv = nn.Sequential(
nn.Conv2d(320, 1280, 1, bias=False),
nn.BatchNorm2d(1280),
nn.ReLU6(inplace=True)
)
# Additional layers for SSD (conv6, conv7)
self.conv6 = nn.Conv2d(1280, 1024, kernel_size=3, padding=6, dilation=6) # atrous convolution
self.conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
# Adjust conv4_3 feature map to have 512 channels
self.conv4_3_adjust = nn.Conv2d(32, 512, kernel_size=1)
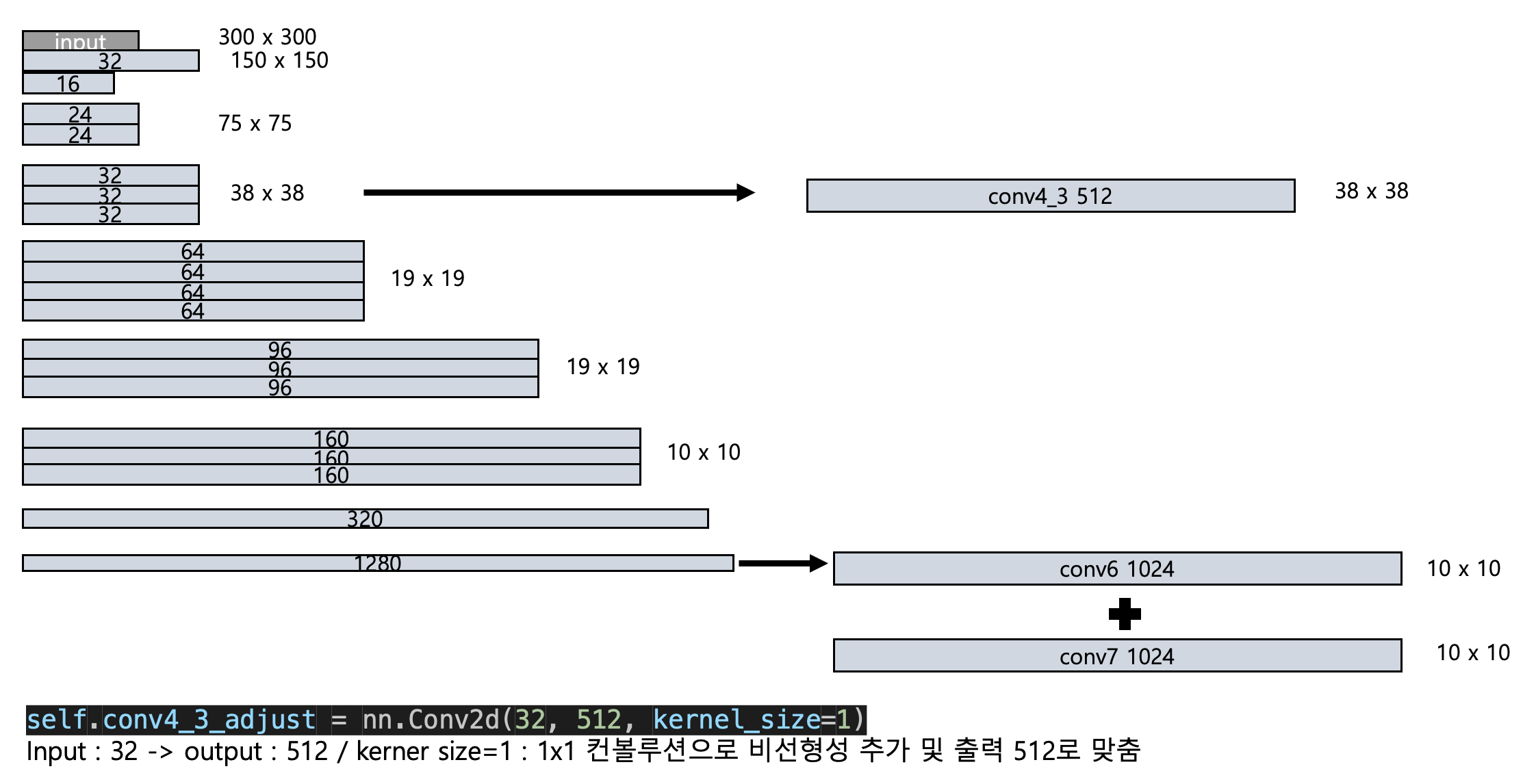
Result
Total prior boxes: 6600
Localization output shape: torch.Size([1, 6600, 4])
Class scores output shape: torch.Size([1, 6600, 21])
Experiment 3.
실험 3
기존 MobilenetV2의 모델 구조를 개선하여 conv4_3, conv7 Base Network 설정
class MobileNetV2Base(nn.Module):
def __init__(self):
super(MobileNetV2Base, self).__init__()
# First convolution layer
self.first_conv = nn.Sequential(
nn.Conv2d(3, 32, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True)
)
# Bottleneck layers
self.bottlenecks = nn.Sequential(
self._make_stage(32, 24, t=1, n=1), # Bottleneck 1: 16 -> 24
self._make_stage(24, 32, t=6, n=2, stride=2), # Bottleneck 2: 24 -> 32
self._make_stage(32, 64, t=6, n=3, stride=2), # Bottleneck 3: 32 -> 64
self._make_stage(64, 128, t=6, n=4, stride=2), # Bottleneck 4: 64 -> 128
self._make_stage(128, 256, t=6, n=3), # Bottleneck 5: 128 -> 256
self._make_stage(256, 512, t=6, n=3, stride=1), # Bottleneck 6: 256 -> 512
self._make_stage(512, 1024, t=6, n=1) # Bottleneck 7: 512 -> 1024
)
def forward(self, image):
out = self.first_conv(image) # ([1, 32, 150, 150])
out = self.bottlenecks[:6](out) #([1, 512, 19, 19])
conv4_3_feats = out # ([1, 512, 19, 19])
out = self.bottlenecks[6:](out) # Rest of Bottleneck [1, 1024, 19, 19])
conv7_feats = out # [1, 1024, 19, 19])
return conv4_3_feats, conv7_feats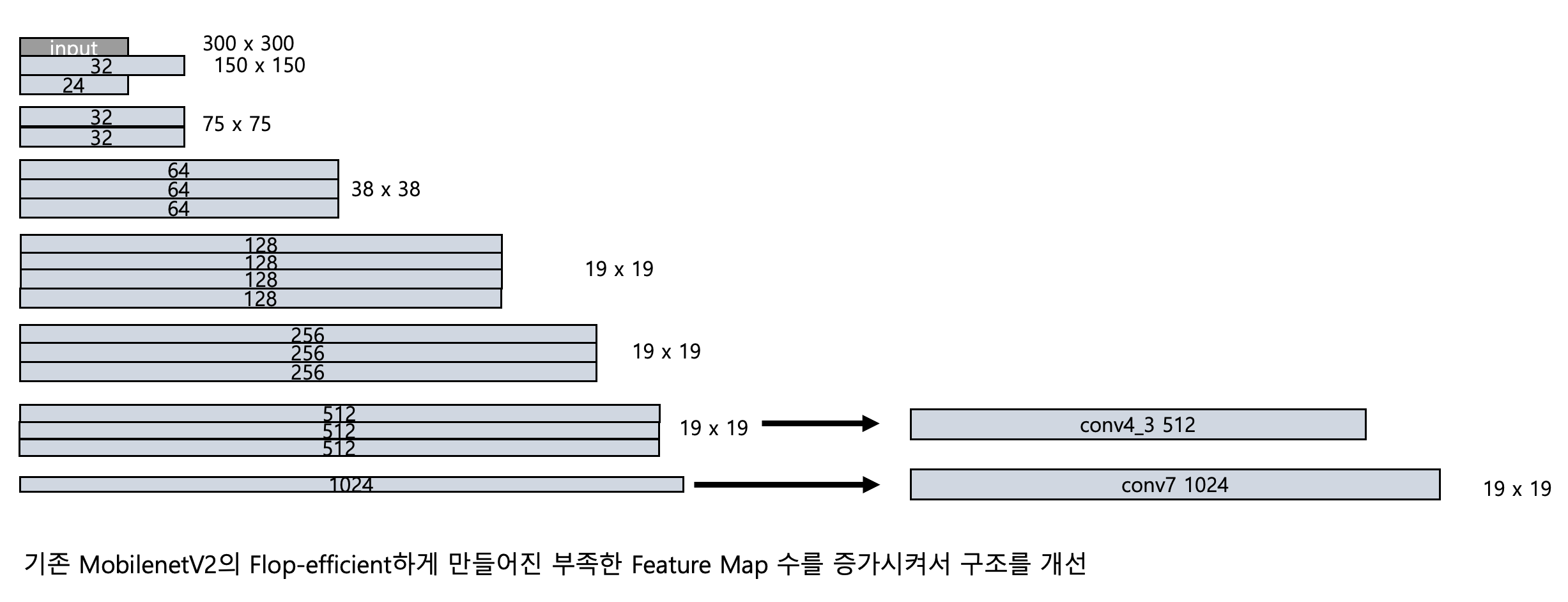
Result
Total prior boxes: 4400
Localization output shape: torch.Size([1, 4400, 4])
Class scores output shape: torch.Size([1, 4400, 21])
Experiment 4.
실험 4
실험 3과 동일한 구조이지만, 추후 iphone ios(Real Time Object Detection) App을 만들떄 모델의 Bottleneck 구조를 하나로 설정하게 되면, conv4_3, conv7을 각각 뽑아낼 수 없기에 nn.Sequential() 로 묶어주기
class MobileNetV2Base(nn.Module):
def __init__(self):
super(MobileNetV2Base, self).__init__()
# First convolution layer
self.first_conv = nn.Sequential(
nn.Conv2d(3, 32, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True)
)
# Bottleneck layers with gradual channel increase
self.bottleneck1_6 = nn.Sequential(
self._make_stage(32, 24, t=1, n=1), # Bottleneck 1: 32 -> 24
self._make_stage(24, 32, t=6, n=2, stride=2), # Bottleneck 2: 24 -> 32
self._make_stage(32, 64, t=6, n=3, stride=2), # Bottleneck 3: 32 -> 64
self._make_stage(64, 128, t=6, n=4, stride=2), # Bottleneck 4: 64 -> 128
self._make_stage(128, 256, t=6, n=3), # Bottleneck 5: 128 -> 256
self._make_stage(256, 512, t=6, n=3, stride=1) # Bottleneck 6: 256 -> 512
)
self.bottleneck7_rest = nn.Sequential(
self._make_stage(512, 1024, t=6, n=1) # Bottleneck 7: 512 -> 1024
)
def forward(self, image):
out = self.first_conv(image) # ([1, 32, 150, 150])
out = self.bottleneck1_6(out) #([1, 512, 19, 19])
conv4_3_feats = out # ([1, 512, 19, 19])
out = self.bottleneck7_rest(out) # Rest of Bottleneck ([1, 1024, 19, 19])
conv7_feats = out # [1, 1024, 19, 19])
return conv4_3_feats, conv7_feats
Result
Total prior boxes: 4400
Localization output shape: torch.Size([1, 4400, 4])
Class scores output shape: torch.Size([1, 4400, 21])
2) Mean Average Precision(mAP)
각 실험별 mAP 값 확인
| Class | Exp. 1 | Exp. 2 | Exp. 3 | Exp. 4 |
|---|---|---|---|---|
| aeroplane | 63.4 | 66.3 | 71.3 | 70.4 |
| bicycle | 69.6 | 70.2 | 79.9 | 80.6 |
| bird | 49.8 | 47.2 | 63.1 | 65.9 |
| boat | 42.4 | 48.1 | 57.7 | 60.1 |
| bottle | 15.2 | 16.2 | 34.9 | 34.8 |
| bus | 69.7 | 71.1 | 81.4 | 80.2 |
| car | 68.3 | 74.3 | 77.7 | 79.4 |
| cat | 77.2 | 76.0 | 82.2 | 83.2 |
| chair | 33.7 | 34.9 | 54.1 | 53.9 |
| cow | 52.2 | 59.1 | 71.3 | 71.2 |
| diningtable | 59.9 | 63.3 | 73.3 | 73.4 |
| dog | 68.1 | 65.5 | 79.2 | 78.9 |
| horse | 77.2 | 78.3 | 84.4 | 84.4 |
| motorbike | 74.7 | 72.1 | 80.9 | 82.4 |
| person | 59.8 | 63.0 | 73.6 | 73.3 |
| pottedplant | 27.6 | 30.6 | 45.6 | 42.5 |
| sheep | 51.7 | 56.8 | 68.4 | 70.6 |
| sofa | 63.3 | 66.6 | 77.7 | 78.2 |
| train | 76.3 | 74.1 | 82.7 | 83.2 |
| tvmonitor | 50.2 | 56.5 | 65.7 | 65.5 |
| Mean Average Precision (mAP) | 57.5 | 59.5 | 70.3 | 70.6 |
| Total Prior Boxes | 1212 | 6600 | 4400 | 4400 |
논문 SSD별 mAP

정리
| 모델 | 백본(Backbone) | 데이터셋 | mAP |
|---|---|---|---|
| SSD300 | VGG16 | Pascal 2007+2012 | 72.4 |
| SSD(MobileNetV2) | MobileNetV2 | Pascal 2007+2012 | 70.6 |
3) FLOPs
FLOPs 비교:
VGG16 기반 SSD: 31,373,537,792 FLOPs (약 31.37 GFLOPs)
MobileNetV2 기반 SSD: 6,945,977,920 FLOPs (약 6.95 GFLOPs)
약 4.5배 적은 FLOPs로 적은 연산량 요구
4) Object Detection in Video Frames
-
24fps 영상

-
36fps 영상

-
60fps 영상

5) CoreML ios Application
Apple의 Coreml을 통해서 iphone App 만들어서 구동

