ILSVRC 2017 ImageNet 분류 대회에서 1위
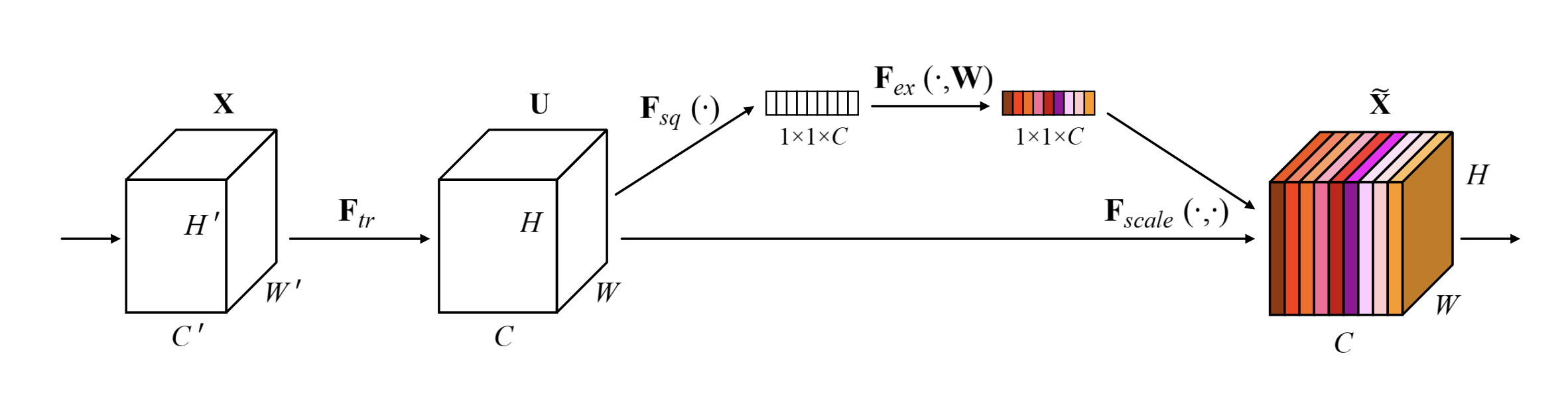
SNet(Squeeze and Excitation Networks)
저자 : Jie Hu, Li Shen, Samuel Albanie, Gang Sun, Enhua Wu
Squeeze and Excitation Networks
1.Introduction
Squeeze and Excitation Networks(SENet)은 기존 CNN의 성능을 향상시키기 위해 간단하고도 효과적인 방법을 제안한 네트워크입니다. CNN 과정에서 중요한 정보와 덜 중요한 정보를 구별하는 능력을 높여주는 SE Block을 도입함으로써 채널 간의 상호작용을 학습하고 각 채널의 중요도를 조정합니다. 논문에서는 SE Block을 다양한 CNN 모델 구조에 통합하여, SE Block의 네트워크 표현력의 향상 효과에 대해서 설명하고 있습니다. 그 결과로 ImageNet 대회에서 큰 성과를 거두며 그 유용성을 입증했습니다.
 Fig.1
Fig.1
먼저, CNN(인공신경망)은 Local Receptive Field을 기반으로 연산을 한다는 점에서 시작됩니다. CNN의 연산 과정을 생각하면, 위의 Fig.1 처럼 이미지의 작은 부분, 즉 국소영역에만 집중해서 추출합니다. 이때 각 Convolution filter 또는 Feature map은 이미지의 일정한 작은 영역에서(local)을 학습하여 정보를 얻습니다. 이러한 CNN의 연산과정은 이미지를 작은 크기의 패치로 분해하고 그 패치에서 중요한 특징(Edge, 코너, 질감 등)을 뽑아냅니다.
 Fig.2
Fig.2
그러나, 논문에서는 CNN의 연산은 국소적 영역(local)에서 정보를 얻기 때문에 전체적인(global)문맥을 이해하기는 어렵다라는 문제점을 제기합니다. 즉, Feature map도 각 필터의 국소적 시야에서 추출된 정보로, 이미지의 특정 영역에만 집중합니다.
예를들어, 한 이미지에서 동물의 귀에 집중하게 되면, 그 귀가 고양이의 귀인지 강아지의 귀인지 구분하기 어려울 수 있습니다. 그러나 이미지 전체를 보면 고양이인지 강아지인지 쉽게 판단할 수 있습니다.
논문의 저자들은 다음과 같이 얘기합니다.
"We propose a mechanism that allows the network to perform feature recalibration, through which it can learn to use global information to selectively emphasise informative features and suppress less useful ones"
SE Block을 도입하면서, 네트워크가 전체적인 정보를 사용하여 중요한 특징을 강조하고, 덜 중요한 특징을 사용 억제하여 특징을 재보정하는 메커니즘을 제안합니다.
Squeeze and Excitation Blocks
은 단순한 Convolution 연산입니다.
: , ,
= Input
= : 을 통과한 Output
= : 필터 집합 와 각 필터의 파라미터. 는 번째 필터의 파라미터
= : 가중치 벡터, 는 번째 입력 채널에서 번째 출력 채널로 연결되는 2D spatial kernel이자 학습가능한 가중치
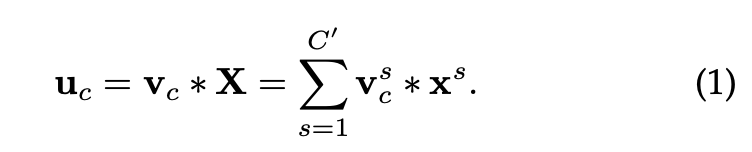
수식은, 번째 출력 채널 값이 여러 입력 채널의 가중합으로 계산됩니다. 각 입력 채널 값에 가중치를 곱해주고, 그 결과를 모두 더해서 하나의 출력 채널을 생성하는 Convolution 연산 과정입니다.
Squeeze: Global Information Embedding
Squeeze Operatioin은 말그대로 압축하는 과정입니다. Feature Map을 각 Channel로 분리하여 중요한 정보만 추출해서 사용하는 것 입니다.
논문에서는 GAP(Global Average Pooling)로 중요 정보를 추출 합니다. GAP를 사용하여 Global Spatial Information을 Channel Descriptor로 압축시킬 수 있습니다.
수식은 다음과 같습니다.
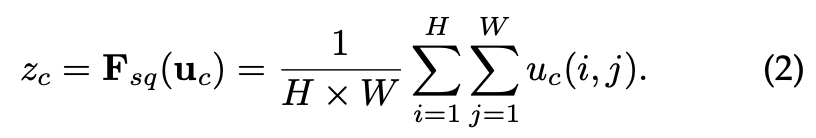
: 채널 에 대한 Squeeze 단계 출력 값
, : 입력 Feature Map의 높이와 너비
: 채널의 위치 값
: 평균을 위한 나누기
입력 Feature Map의 각 채널에 대해 spatial dimensions에서 평균을 계산합니다. 주어진 채널의 모든 픽셀 값들을 더한 후, 픽셀 수 로 나누어 평균을 구합니다. 이를 통해서 공간적인 정보를 요약하여 각 채널의 Global Representation을 얻습니다. GAP를 통해 전체적인 공간적 패턴을 요약할 수 있어 네트워크가 특정 Channel 정보가 얼마나 중요한지를 학습할 수 있게 도와줍니다.
논문의 저자들은 간단한 방식으로 GAP를 사용했지만, 다른 방법론을 사용할 수 있다고 합니다.
Excitation: Adaptive Recalibratcion
Excitation Operation은 재조정 과정으로, 채널 간 의존성(Channel-wise-dependencies)을 계산하게 됩니다. 논문에서는 Fully Connected Layer와 비선형 함수를 조절하는 것으로 간단하게 계산합니다. 수식은 다음과 같습니다.
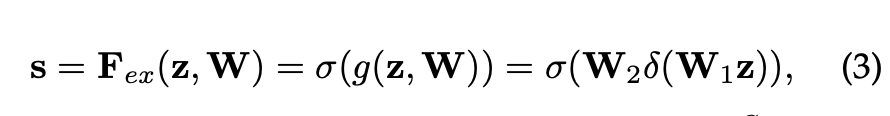
: 채널 에 대한 Excitation 가중치(Excitation 단계의 출력 값)
: Squeeze 단계에서 구한 Channel Descriptor
, : Fully Connected Layer의 가중치 행렬. 은 채널 수를 줄이며 는 채널 수를 다시 원래대로 복원
: ReLU 활성화 함수
: Sigmoid 활성화 함수
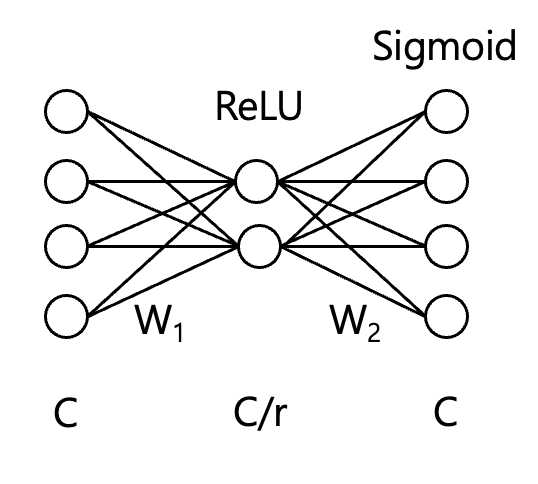
그림으로 간단하게 그려보면 다음과 같습니다.(그림은 C=4, r=2라 가정한 그림)
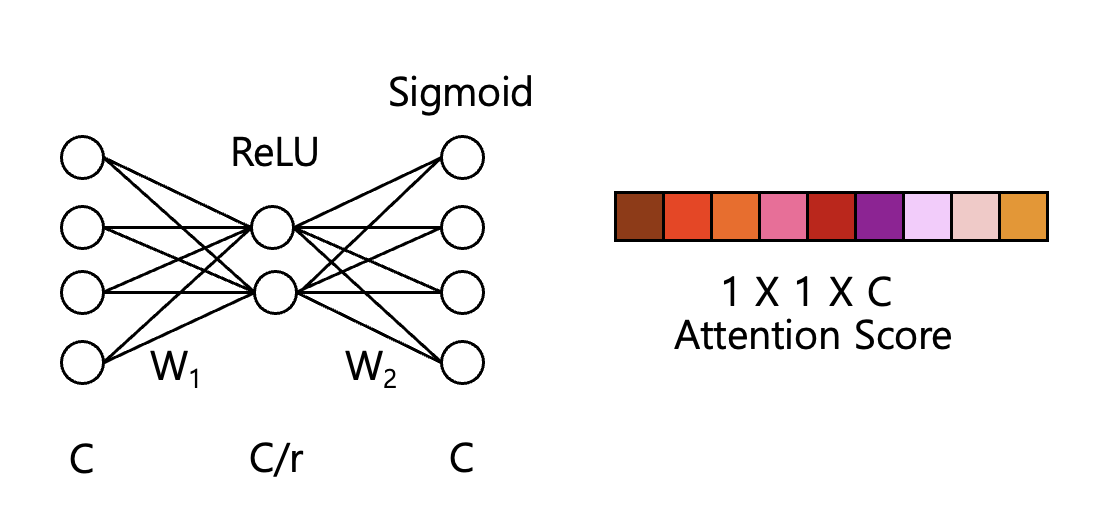
1) Squeeze 단계에서 생성된 채널 디스크립터 를 입력으로 받아, 의 노드 C를 reduction ratio r을 통해서 노드 수를 줄입니다. 이때 차원 축소를 통해 비선형성을 도입하고, 중요한 특징만을 더 잘 학습할 수 있도록 합니다.
2) 에 ReLU를 적용하여 음수 값을 0으로 비선형 변환을 수행합니다.
3) 에서 다시 피쳐맵의 수 C만큼 복원합니다. 이 단계는 각 채널에 대한 가중치를 결정하는 과정입니다.
4) 최종적으로 Sigmoid 함수를 사용하여 0~1 사이의 값으로 정규화하여 각 채널의 가중치를 확률적으로 해석할 수 있으며, 중요한 채널은 가종하고 덜 중요한 채널은 억제할 수 있습니다.
이렇게 모든 함수를 거쳐서 나온 값을 아래 수식으로 계산합니다.
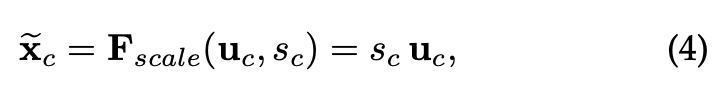
: 입력 특징 맵의 번째 채널. Squeeze 단계 전에 Convolution 연산으로 나온 번째 채널의 Spatial 특징
: Excitation 과정에서 학습된 번째 채널에 대한 중요도. Sigmoid로 정규화 되어 0 ~ 1 값으로 채널의 중요도를 나타낸다.
: Reweighting 과정의 출력, 입력 특징맵 에 가중치 를 곱한 값
: Channel-wise Multiplication(채널 별 곱셈), 각 채널의 Global Spatial에 걸쳐 동일한 가중치 를 곱하여 채널의 중요도 반영
1) 입력 Feature map 는 번째 채널에서 추출된 Spatial Information을 포함하고 있습니다.
2) Excitaion 단계에서 학습된 가중치 는 해당 채널의 중요도를 나타내며, 중요도가 높은 채널은 강조되고, 중요도가 낮으면 억제됩니다.
3) Reweighting 단계에서, 각 채널에 대해 를 곱하여, 중요도에 따라 입력 Feature map을 재조정합니다. 가 1에 가까우면 정보가 유지되며, 반대로 0에 가까우면 해당 채널의 정보는 많이 억제됩니다.
Model and Computational Complexity
다음 수식은 모델의 네트워크에서 연산량을 계산할 때 사용되는 수식입니다.
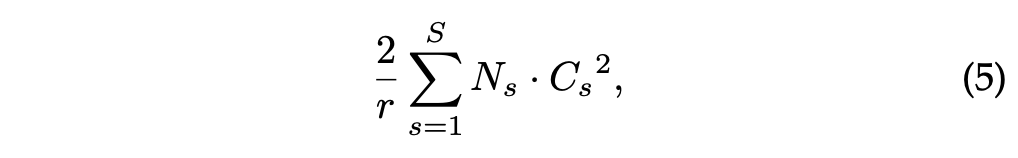
: Reduction ratio
: Number of stages(Squeeze, , 단계)
: Dimension of the output channels
: Repeated block number of stage s
1) 는 각 블록의 채널 크기에 제곱을 적용하여 해당 블록의 연산 복잡도를 반영합니다.
2) 는 각 블록이 몇 번 반복 되는지를 반영하여, 네트워크 깊이에 따른 연산량을 계산합니다.
3) 축소 비율 에 의해 채널 수가 줄어드는 과정에서 효율성을 반영하는 스케일링 요소입니다.
SE Block을 적용시킨 SE-ResNet-50 기준
기존 ~25 Million Parameters인 ResNet-50에서 ~2.5 Million Additional Parameters가 더해집니다.
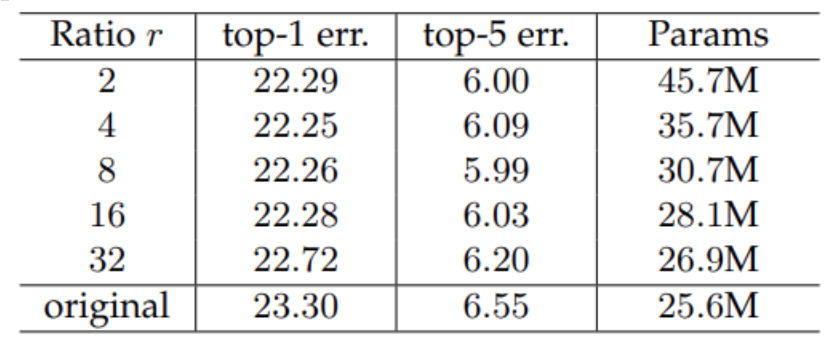
Reduction ratio 에 따른 영향은 아래 표와 같습니다.
= 16은 Error rate에 큰 영향을 미치지 않았으며, =2 에 비해서 38%의 Parameter 감소 효과를 보였습니다.
Exemplars: SE-Inception and SE-ResNet
논문 저자들은 SE Block을 VGGNet, InceptionNet, ResNet등 다양한 모델에 적용을 합니다. InceptionNet과 ResNet에 적용한 구조는 다음과 같습니다.
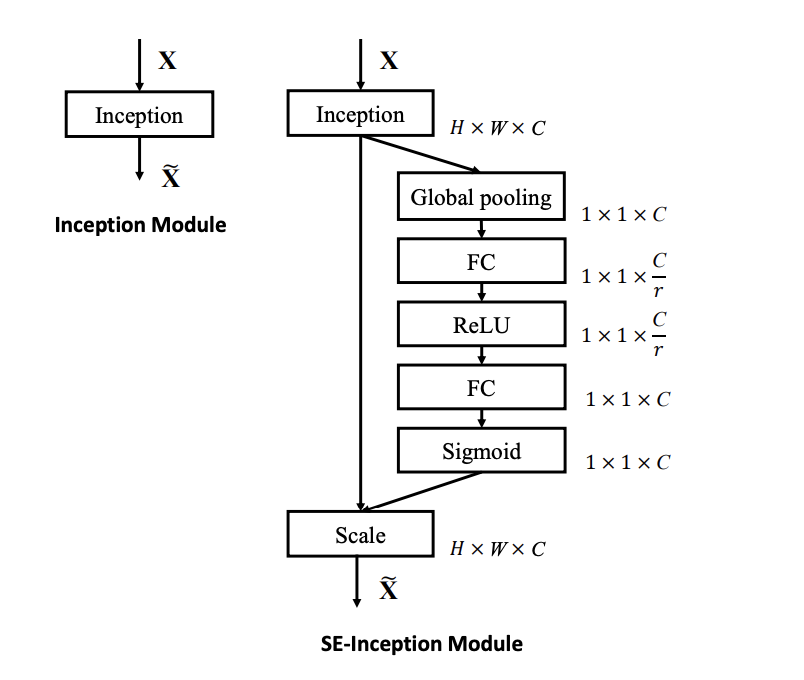
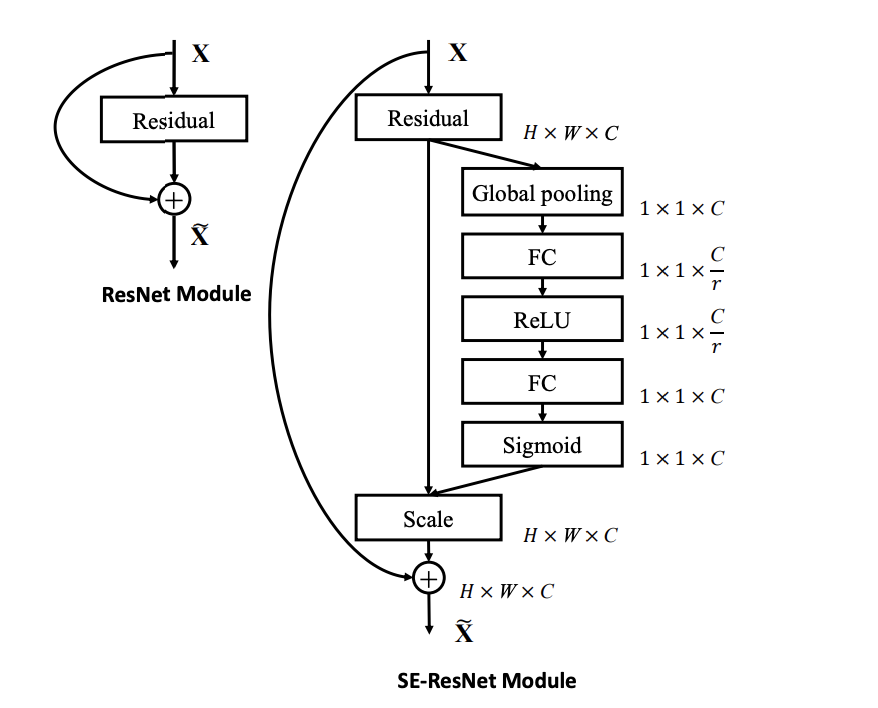
ResNet-50과 ResNeXt-50을 예시로 SEBlock을 적용했을때 모델 구조의 설명
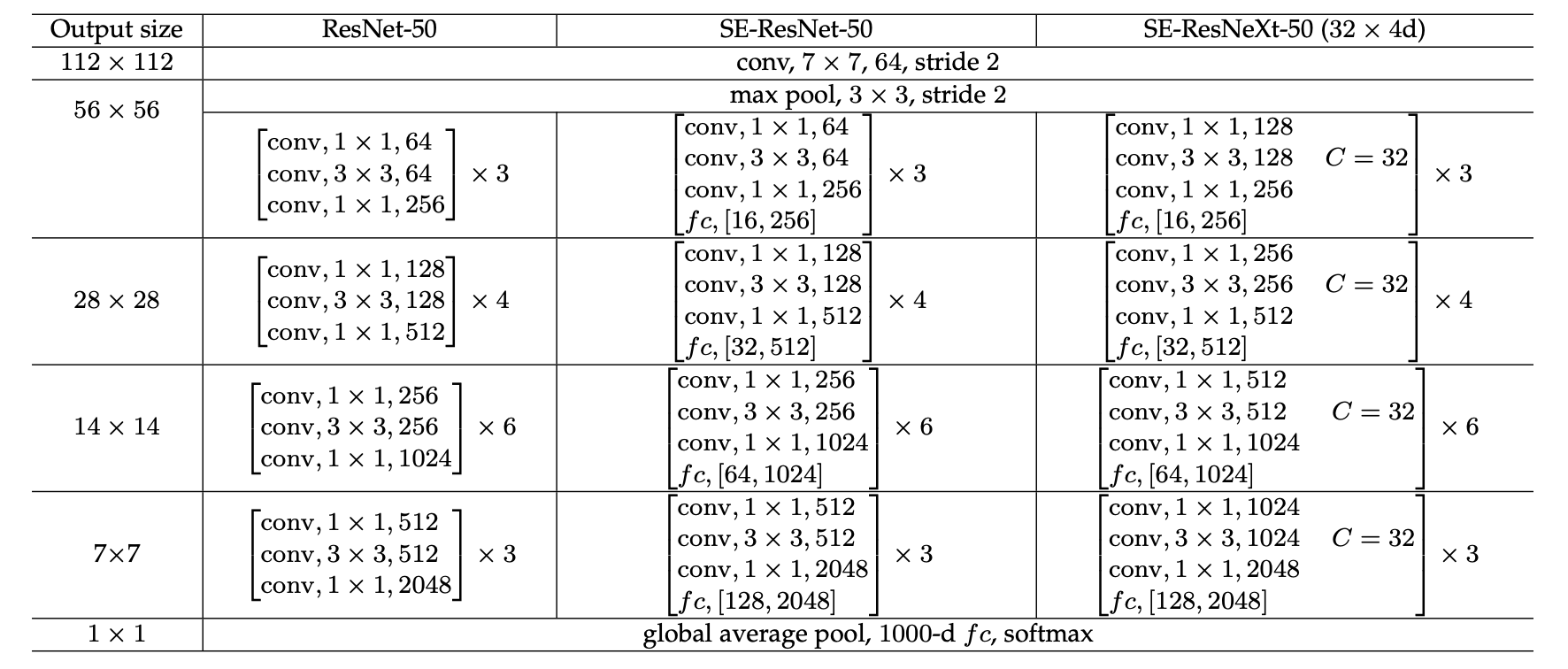
SEBlock을 다양한 모델에 적용했을때 모델의 성능 비교 테이블
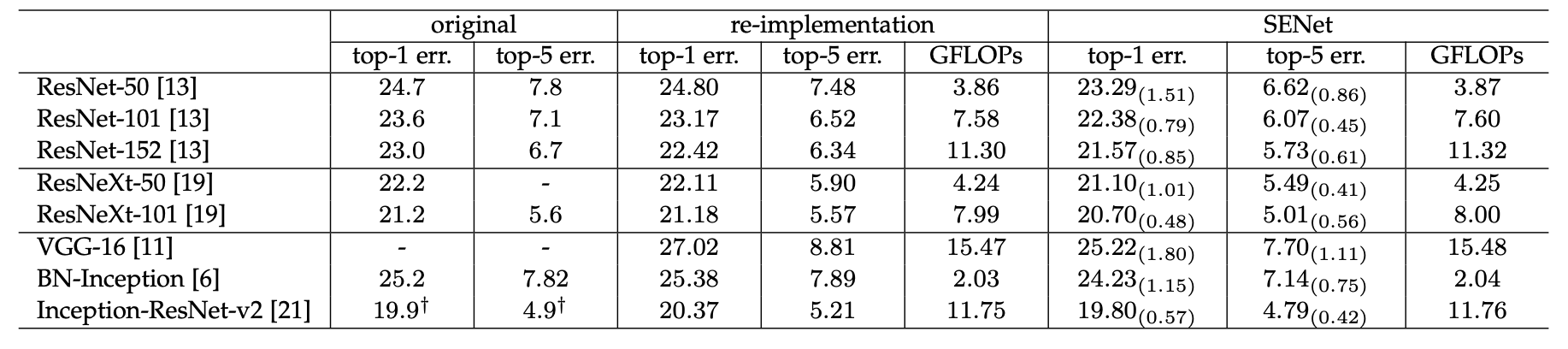
SE Block을 적용한 것 만으로도 연산량은 아주 조금 늘어났지만 모델의 성능을 어느정도 상승시키는 특징을 가지고 있다.
Pytorch 코드 구현
SE Block
SE Block은 앞서 얘기한 계산 과정처럼 GAP와 ReLU, Sigmoid의 연산과정으로 나타낸다.
import torch
from torch import nn
class SE_block(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(SE_block, self).__init__()
# Squeeze: Global Information Embedding
self.squeeze = nn.AdaptiveAvgPool2d((1, 1))
# Excitation: Adaptive Recalibration
self.excitation = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction_ratio, in_channels),
nn.Sigmoid()
)
def forward(self, x):
se_weight = self.squeeze(x) # (N, C, H, W) -> (N, C, 1, 1)
se_weight = se_weight.view(se_weight.size(0), -1) # (N, C, 1, 1) -> (N, C)로 reshape
se_weight = self.excitation(se_weight) # 채널별 중요도 계산
se_weight = se_weight.view(se_weight.size(0), se_weight.size(1), 1, 1) # (N, C) -> (N, C, 1, 1)로 다시 reshape
return x * se_weight # 입력에 중요도를 반영하여 조정SE ResNet
import torch
from torch import nn
from model.se_block import SE_block
from torchinfo import summary
class SE_BottleNeck(nn.Module):
expansion_factor = 4
def __init__(self, in_channels, out_channels, stride=1):
super(SE_BottleNeck, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
self.conv2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
self.conv3 = nn.Sequential(nn.Conv2d(out_channels, out_channels * self.expansion_factor, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels * self.expansion_factor))
self.residual = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion_factor:
self.residual = nn.Sequential(
nn.Conv2d(in_channels, out_channels * self.expansion_factor, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * self.expansion_factor))
self.se_block = SE_block(out_channels * self.expansion_factor)
self.relu1 = nn.ReLU(inplace=True)
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.se_block(x)
x += self.residual(identity) # shortcut connection
x = self.relu1(x)
return x
class SE_Resnet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(SE_Resnet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_features=64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.conv2 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.conv3 = self._make_layer(block,128, num_blocks[1], stride=2)
self.conv4 = self._make_layer(block,256, num_blocks[2], stride=2)
self.conv5 = self._make_layer(block,512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(512 * block.expansion_factor, num_classes)
# 가중치 초기화
self._init_layer()
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks -1) # [stride, 1, 1, ..., 1] 1은 num_block -1 개
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion_factor
return nn.Sequential(*layers)
def _init_layer(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def se_resnet50():
return SE_Resnet(SE_BottleNeck, [3, 4, 6, 3])
def se_resnet101():
return SE_Resnet(SE_BottleNeck, [3, 4, 23, 3])
def se_resnet152():
return SE_Resnet(SE_BottleNeck, [3, 8, 36, 3])
# model = se_resnet50()
# summary(model, input_size=(2,3,224,224), device='cpu')
Experiment
ResNet
| Epoch | Train Loss | Train Accuracy (%) | Train Error Rate (%) | Val Loss | Top-1 Error Rate (%) | Top-5 Error Rate (%) |
|---|---|---|---|---|---|---|
| 10 | 0.7902 | 72.83 | 27.17 | 1.0174 | 31.55 | 4.09 |
| 20 | 0.2138 | 92.48 | 7.52 | 1.3049 | 30.42 | 3.30 |
| 30 | 0.0420 | 98.78 | 1.22 | 1.2505 | 26.20 | 3.09 |
SE-ResNet
| Epoch | Train Loss | Train Accuracy (%) | Train Error Rate (%) | Val Loss | Top-1 Error Rate (%) | Top-5 Error Rate (%) |
|---|---|---|---|---|---|---|
| 10 | 0.6826 | 76.81 | 23.19 | 0.9393 | 30.44 | 3.51 |
| 20 | 0.1120 | 96.43 | 3.57 | 1.1439 | 27.16 | 4.05 |
| 30 | 0.0139 | 99.71 | 0.29 | 1.0737 | 23.43 | 2.98 |
SE-ResNet은 epoch 10, 20, 30에서 훈련 손실이 더 빠르게 감소하고, Train Accuracy 더 높습니다. SE-ResNet의 30 epoch에서 Train Accuracy는 99.71%이며, ResNet은 98.78%로 SE-ResNet보다 낮습니다.
Validation Loss에서도 SE-ResNet이 더 낮은 값을 보입니다. 특히 30 epoch에서 SE-ResNet의 Validation Loss는 1.0737로, ResNet의 1.2505보다 낮습니다.
Top-1 Error Rate와 Top-5 Error Rate 둘다 SE-ResNet이 더 낮은 Error Rate를 보입니다. 30 epoch 기준으로 SE-ResNet의 Top-1 Error Rate는 23.43%로, ResNet의 *26.20%보다 낮습니다.
ResNeXt
| Epoch | Train Loss | Train Accuracy (%) | Train Error Rate (%) | Val Loss | Top-1 Error Rate (%) | Top-5 Error Rate (%) |
|---|---|---|---|---|---|---|
| 10 | 0.7902 | 72.83 | 27.17 | 1.0174 | 31.55 | 4.09 |
| 20 | 0.2138 | 92.48 | 7.52 | 1.3049 | 30.42 | 3.30 |
| 30 | 0.0420 | 98.78 | 1.22 | 1.2505 | 26.20 | 3.09 |
SE-ResNeXt
| Epoch | Train Loss | Train Accuracy (%) | Train Error Rate (%) | Val Loss | Top-1 Error Rate (%) | Top-5 Error Rate (%) |
|---|---|---|---|---|---|---|
| 10 | 0.7902 | 72.83 | 27.17 | 0.9393 | 30.44 | 3.51 |
| 20 | 0.1120 | 96.43 | 3.57 | 1.1439 | 27.16 | 4.05 |
| 30 | 0.0139 | 99.71 | 0.29 | 1.0737 | 23.43 | 2.98 |
SE-ResNeXt는 epoch 10, 20, 30 모두에서 Train Loss가 더 빠르게 감소하고, Train Accuracy도 더 높습니다. epoch 30에서는 SE-ResNeXt의 Train Accuracy는 99.71%, ResNeXt는 98.78%입니다.
epoch 30 기준으로, SE-ResNeXt의 Val Loss은 1.0737로 ResNeXt의 1.2505보다 낮습니다. 이는 SE-ResNeXt가 더 일반화된 성능을 보인다는 것을 의미합니다.
Top-1 Error Rate에서 SE-ResNeXt는 에포크 30에서 23.43%로, ResNeXt의 26.20%보다 더 낮은 Error Rate를 보입니다. Top-5 Error Rate 역시 SE-ResNeXt가 2.98%로 더 좋은 성능을 보이고 있습니다.
MobilenetV1, ResNeXt, VgGG16이 적용된 다른 코드는 Github 참조
https://github.com/PARKYUNSU/SE-Net
