Link to Paper:
“Deep Residual Learning for Image Recognition” - 2015
— Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Microsoft Research
https://arxiv.org/pdf/1512.03385v1
Table of Contents
- Introduction
- Residual Learning
- Network Architectures
- Augmentation
- Code
- Conclusion
1. Introduction
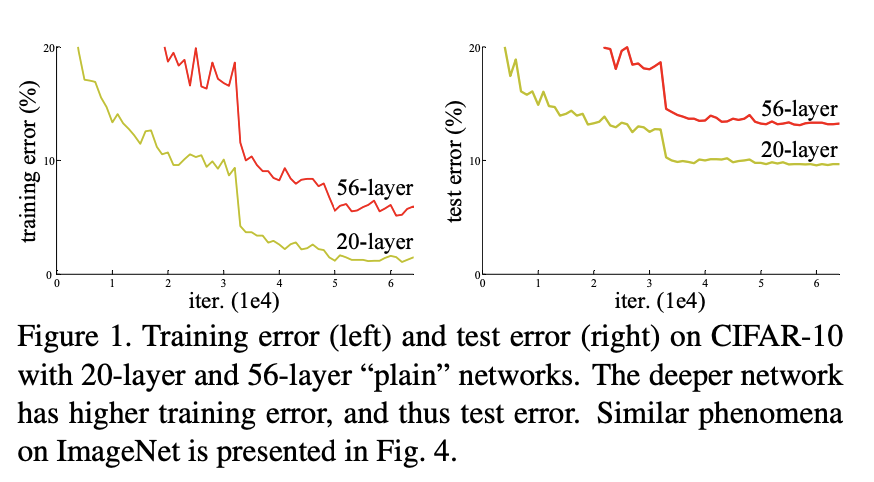
Fig.1
Deep convolutional neural networks은 이미지 인식 및 다양한 컴퓨터 비전 작업에 뛰어난 두각을 내왔습니다.
하지만, 더 깊은 네트워크 모델에서는 성능 저하(degradtion problem) 및 기울기 소실 문제가 발생했습니다.
마이크로 소프트 연구진들은 해결방법으로 기존 신경망 구조에서 Skip Connection을 활용한 Residual Learning(잔차 학습) 프레임워크를 통해 문제를 해결하고, 더 깊은 신경망 학습을 통해 성능을 향상 시키고자 했습니다.
Traditional Architecture의 문제점
Skip connection을 이해하기 전에 왜 필요한지에 대해 알 필요가 있습니다. VGG와 같은 Architecture를 설계할 때 깊을수록 더 나은 성능을 보입니다. 하지만 깊이가 너무 깊어지면 오히려 성능이 하락하는 결과나 나타납니다. Fig.1은 56-layer network는 전체 training 절차 동안 높은 training error를 갖습니다. 20-layer network의 solution space는 56-layer의 subspace이지만, 더 높은 error가 나타납니다.
VGG와 같은 전통적인 network에서 깊이는 많은 layers를 걸쳐학습할 때 성능저하 문제에 의해 제한됩니다. ResNet에서는 short skip connections을 사용하는 residual architectures 방법을 제공하여 문제를 해결합니다. 몇 개의 layer를 건너 뛰어 연결해 non-linearities를 추가하는 skip connections은 gradient가 layers를 건너뛰어 연결될 수 있는 shortcuts를 만들어 parameters를 network에 deep하게 업데이트 할 수 있습니다.
2. Residual Learning
1) Residual Block
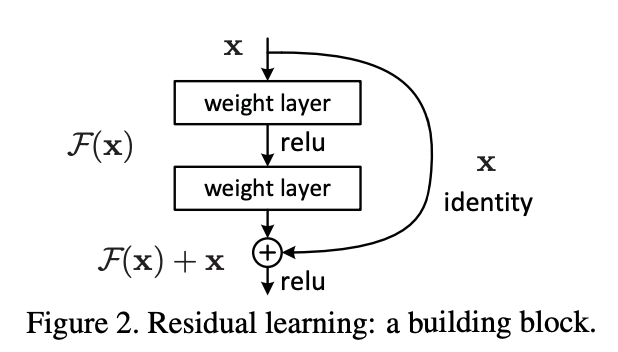
Fig.2
Residual Block은 입력 𝑥가 직접 다음 레이어로 전달되는 Skip connection을 활용합니다.
Residual Block의 입력 값 𝑥는 출력 값 𝐹(𝑥) + 𝑥 나타납니다.
여기서 𝐹(𝑥)는 기존 Plain block과 동일하며, 𝑥 는 Identity mapping 입니다.
→ Identity mapping은 입력을 그대로 출력으로 전달하는 것을 의미합니다.
함수 f 가주어졌을 때, 𝑥를 그대로 반환하여 출력도 𝑥가 되는 것
f(𝑥) = 𝑥
이를 수식으로 나타내면,
𝐻(𝑥) = 𝐹(𝑥) + 𝑥
즉,
→ 𝐹(𝑥) = 𝐻(𝑥) − 𝑥
이것을 Residual Mapping(잔차 매핑) 이라고 합니다. 𝐹(𝑥)는 출력 값에서 입력 값을 뺀 값이므로 잔차를 의미합니다. 잔차 학습의 목표는 입력 값 𝑥에 대해 출력 값 𝐻(𝑥)가 Ground truth(실제 값)와 같아지도록 최적의 𝐹(𝑥) 함수를 학습하는 것입니다.
학습 과정 요약:
-
𝐻(𝑥) = 𝐹(𝑥) + 𝑥
-
𝑥는 입력 값과 동일하므로, 𝐻(𝑥) 에서 원하는 𝐹(𝑥)을 도출할 수 있다면 Ground truth(실제 값)을 구할 수 있습니다.
-
𝐻(𝑥)와 𝐹(𝑥) 학습의 차이
-
𝐻(𝑥) 학습:
𝐻(𝑥) = 𝑥 → weight → ReLU → weight → 𝐻(𝑥)
-
𝐹(𝑥) 학습:
𝐹(𝑥) = 𝑥 → weight → ReLU → weight → 𝐹(𝑥)
기존 여러 레이어를 통해 입력 값을 변형시켜 최종 출력 𝐻(𝑥)을 얻는 학습에서, 입력 값을 변형시켜 𝐹(𝑥)을 얻고, 이 𝐹(𝑥)가 0이 되도록 하면 자연스럽게 𝐻(𝑥)가 입력 값 𝑥와 같아지게 됩니다. 즉, 𝐻(𝑥) = 𝐹(𝑥) + 𝑥 이므로, 𝐹(𝑥)를 0으로 만드는 쉬운 문제가 됩니다.
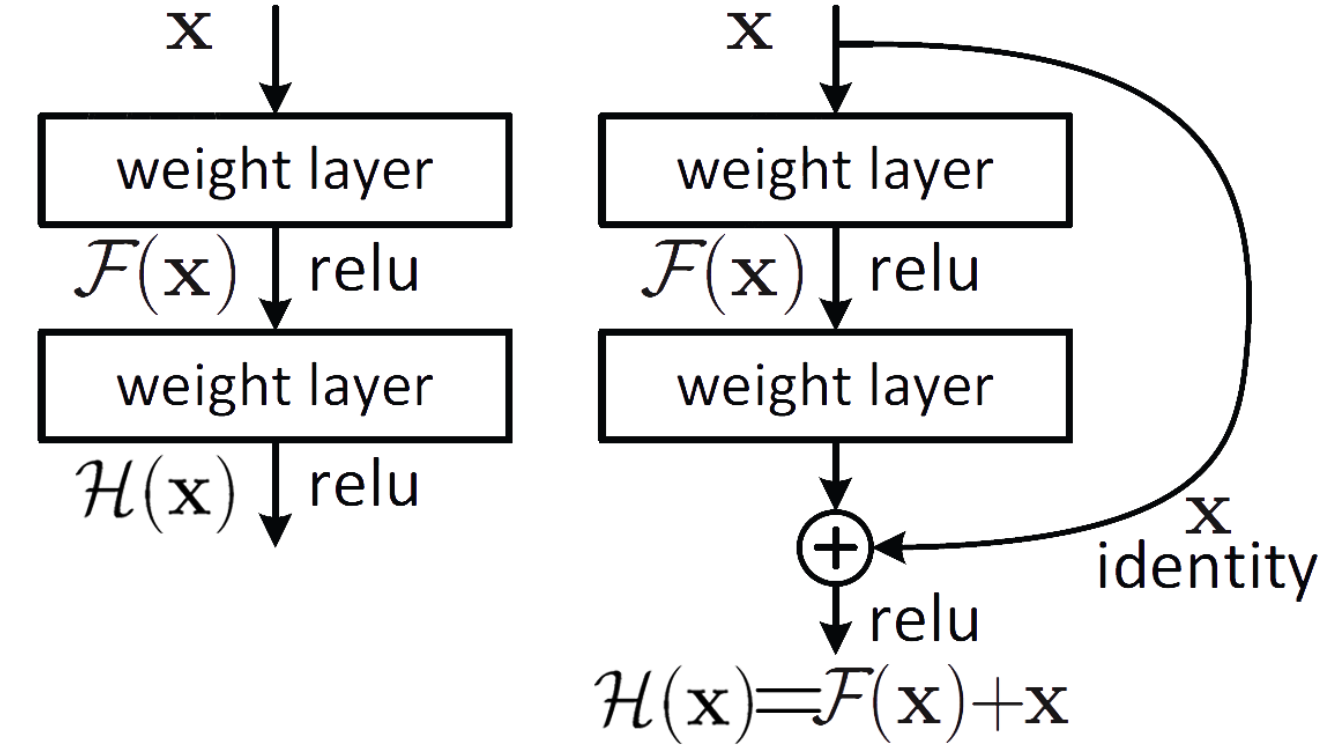
FIg.3
- 왼쪽 그림은 원래 𝐻(𝑥)를 직접 학습하는 구조입니다. 입력 𝑥 가 여러 층을 거쳐서 최종 출력 𝐻(𝑥)를 만듭니다. 이는 기존에 학습한 정보를 보존하지 않고 변형시켜서 새롭게 생성하는 방식입니다.
- 오른쪽 그림은 Residual Network 구조로, 입력 𝑥가 여러 층을 거쳐 잔차 함수 𝐹(𝑥)를 학습하고, 최종 출력은 𝐹(𝑥) + 𝑥로 계산됩니다. 이 방식은 이전 레이어에서 학습햅던 정보를 연결하여 해당 층에서는 추가적으로 학습해야 할 정보만들 mapping 학습합니다.
잔차 함수를 학습 하는 방식은 입력과 같은 𝑥가 그대로 출력에 연결되어 파라미터 수에 영향이 없기 때문고 𝐻(𝑥)를 직접 학습하는 것보다 더 안정적, 그래서 이 방식으로 깊은 네트워크에서 degradtion problem 문제를 완하하여 깊은 학습이 가능합니다.
2) Matching Dimensions
논문에서는 차원을 맞춰야지 Shortcut Connection을 사용할 수 있다고합니다.
즉, 𝑥와 𝐹의 차원이 동일해야합니다.
논문에서는 Ws(정사각행렬) 사용해서 차원을 맞춥니다.
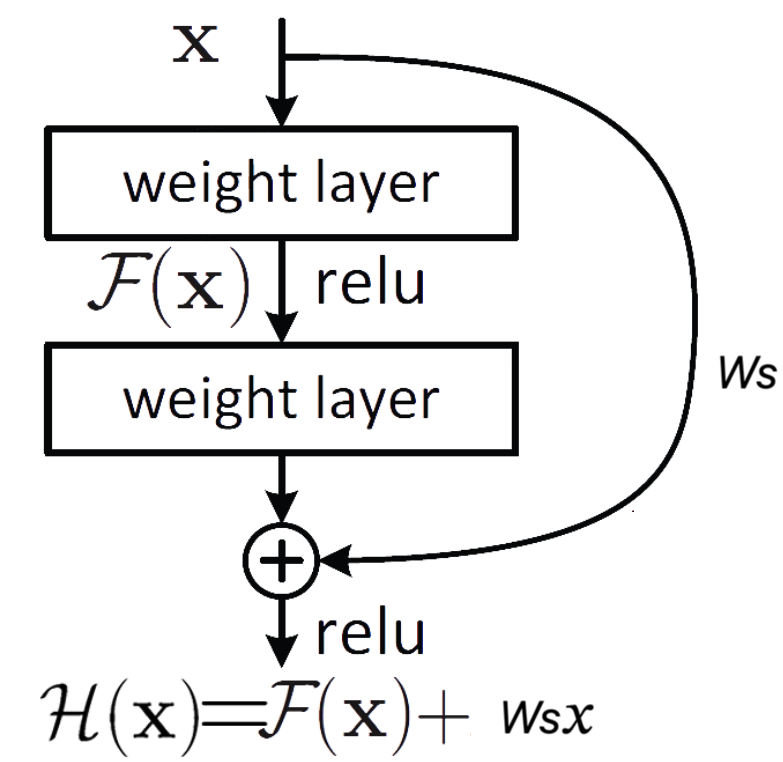
Fig.4
3. Network Architectures
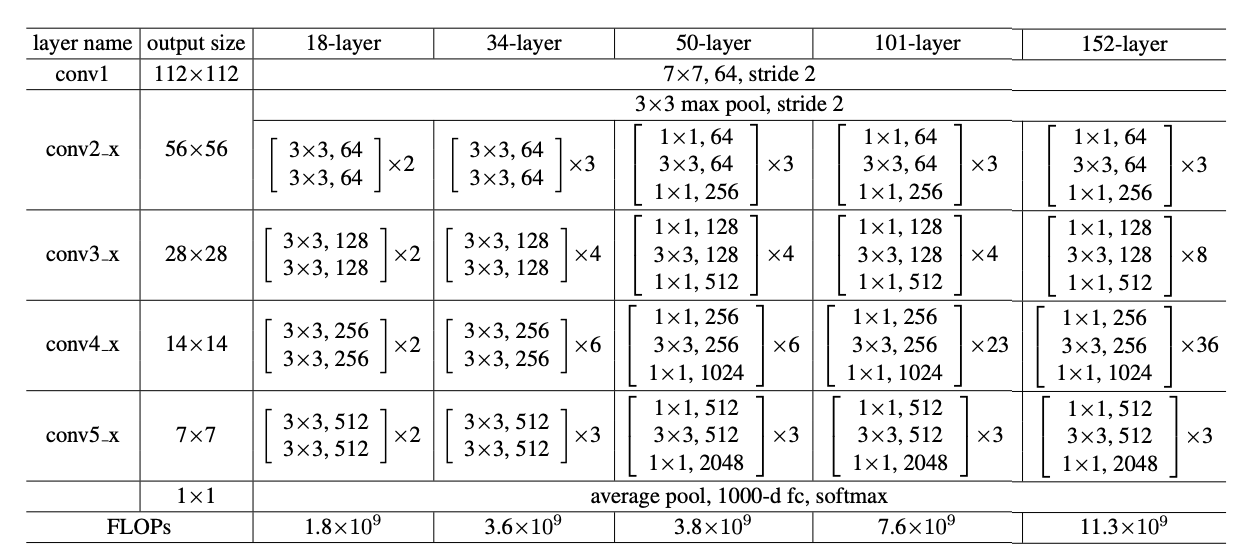
Fig.5
Residual Block을 이용하여 논문에서는 18-layer, 34-layer, 50-layer, 101-layer, 152-layer의 ResNet을 제안
18-layer 경우는 1 + 2 X 2 + 2 X 2 + 2 X 2 +2 X 2 + 1 = 18

Fig.6
왼쪽 그래프는 네트워크 망이 깊어지면서 에러율(%)이 커진다. 34층의 네트워크가 18층의 네트워크보다 성능이 안좋다.
오른쪽 그래프는 ResNet 네트워크 망으로 망이 깊어지면서 에러율(%)도 작아졌다.
4. Agumentation and Training Setup
1) Agumentation
Image Size = 256 ~ 480 랜덤 샘플링
Mean Subtraction - 원본 이미지에서 각 픽셀 값에서 해당 픽셀의 평균 값을 빼서 정규화
Horizontal Flip - 이미지 수평으로 뒤집기
224 x 224 이미지로 Random crop
Color Augmentation
2) Hyper parameters
Optimizer - SGD
Batch_size - 128 ( 논문에서는 128이지만, 자원 한계로 64로 진행)
weight decay - 0.001, momentum - 0.9
Learning_rate - 0.1 로 시작해서 Validation error 가 줄지 않으면 10만큼 곱하여줄 줄임 (scheduler)
5. Code
Basic Block
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
expansion_factor = 1
def __init__(self, in_channels: int, out_channels: int, stride: int = 1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
self.conv2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
self.residual = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion_factor:
self.residual = nn.Sequential(
nn.Conv2d(in_channels, out_channels*self.expansion_factor, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels*self.expansion_factor))
self.relu1 = nn.ReLU()
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.conv2(x)
x += self.residual(identity) # shortcut connection
x = self.relu1(x)
return xBottle Neck Block
class BottleNeck(nn.Module):
expansion_factor=4
def __init__(self, in_channels, out_channels, stride=1):
super(BottleNeck, self).__init__()
self.conv1 = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
self.conv2 = nn.Sequential(nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU())
self.conv3 = nn.Sequential(nn.Conv2d(out_channels, out_channels * self.expansion_factor, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_channels * self.expansion_factor))
self.residual = nn.Sequential()
if stride != 1 or in_channels != out_channels * self.expansion_factor:
self.residual = nn.Sequential(
nn.Conv2d(in_channels, out_channels * self.expansion_factor, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * self.expansion_factor))
self.relu1 = nn.ReLU()
def forward(self, x):
identity = x
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x += self.residual(identity) # shortcut connection
x = self.relu1(x)
return xResnet Model
class Resnet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(Resnet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.conv2 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.conv3 = self._make_layer(block,128, num_blocks[1], stride=2)
self.conv4 = self._make_layer(block,256, num_blocks[2], stride=2)
self.conv5 = self._make_layer(block,512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(512 * block.expansion_factor, num_classes)
self._init_layer()
def _make_layer(self, block, out_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks -1) # [stride, 1, 1, ..., 1] 1은 num_block -1 개
layers = []
for stride in strides:
layers.append(block(self.in_channels, out_channels, stride))
self.in_channels = out_channels * block.expansion_factor
return nn.Sequential(*layers)
def _init_layer(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return xclass Model:
def resnet18(self):
return Resnet(BasicBlock, [2, 2, 2, 2])
def resnet34(self):
return Resnet(BasicBlock, [3, 4, 6, 3])
def resnet50(self):
return Resnet(BottleNeck, [3, 4, 6, 3])
def resnet101(self):
return Resnet(BottleNeck, [3, 4, 23, 3])
def resnet152(self):
return Resnet(BottleNeck, [3, 8, 36, 3])resnet_101을 기준으로 구조 설명
BottleNeck을 [3, 4, 23, 3]의 형태로 블록을 구성
-
처음은 입력 이미지를 64 채널로 바꾸는 7 X 7 컨볼루션 계층 과 MaxPooling 계층
Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
BatchNorm2d(64)
ReLU()
MaxPool2d(kernel_size=3, stride=2, padding=1)
-
64 채널로 구성된 3개의
BottleNeck_make_layer(BottleNeck, 64, 3, stride=1)
-
128 채널로 구성된 4개의
BottleNeck_make_layer(BottleNeck, 128, 4, stride=2)
-
256 채널로 구성된 23개의
BottleNeck_make_layer(BottleNeck, 256, 23, stride=2)
-
512 채널로 구성된 3개의
BottleNeck_make_layer(BottleNeck, 512, 3, stride=2)
-
Adaptive Average Pooling → 출력 크기를 1 X 1
AdaptiveAvgPool2d(output_size=(1, 1))
-
최종 분류 계층:
512 X 4 (expansion_factor) = 2048을 입력으로 받아num_classes출력Linear(512 * 4, num_classes)
# Model 클래스
class Model:
def resnet101(self): # resnet-101 layer
return models.resnet101(pretrained=False, num_classes=10)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Model().resnet101()
model = model.to(device)
input_tensor = torch.randn(1, 3, 224, 224).to(device)
y = model(input_tensor)
print(y.size()) # torch.Size([1, 10])Mean Subtraction (이미지에서 각 픽셀 값에 해당하는 평균과 표준편차 구하는 코드)
path = '/kaggle/working/data'
if not os.path.exists(path):
os.mkdir(path)
transfor = transforms.Compose([transforms.ToTensor()])
trainset = datasets.CIFAR10(root=path, train=True, download=True, transform=transfor)
testset = datasets.CIFAR10(root=path, train=False, download=True, transform=transfor)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=256, shuffle=False, num_workers=2)
# 이미지 평균 및 표준편차 계산
mean = torch.zeros(3)
std = torch.zeros(3)
nb_samples = 0.0
for images, _ in trainloader:
batch_samples = images.size(0)
images = images.view(batch_samples, images.size(1), -1)
mean += images.mean(2).sum(0)
std += images.std(2).sum(0)
nb_samples += batch_samples
mean /= nb_samples
std /= nb_samples
mean = mean.numpy().tolist()
std = std.numpy().tolist()
print(mean)
print(std)
# mean = [0.4913995563983917, 0.48215848207473755, 0.44653093814849854]
#std = [0.20230084657669067, 0.19941289722919464, 0.20096157491207123]Augmentation 및 데이터셋 (CIFAR-10)
# 데이터셋 전처리
transform_train = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.875, 1.0)), # Random crop 224x224
transforms.RandomHorizontalFlip(), # 수평으로 뒤집기
transforms.Resize((224, 224)), # 크기 변경
transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.2), # 색상 변형
transforms.ToTensor(),
transforms.Normalize(mean, std), # 평균과 표준편차를 이용한 정규화
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean, std),
])
# CIFAR-10
trainset = datasets.CIFAR10(root=path, train=True, download=True, transform=transform_train)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2)
testset = datasets.CIFAR10(root=path, train=False, download=True, transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False, num_workers=2)Hyperparameters
# CUDA 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# hyper parameters
initial_learnin_rate = 0.1 # 초기 learning_rate = 0.1
num_epochs = 50
epoch_step = 5
# Loss function, optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=initial_learnin_rate, momentum=0.9, weight_decay=0.0001) # weight_decay = 0.0001, momentum = 0.9
# scheduler
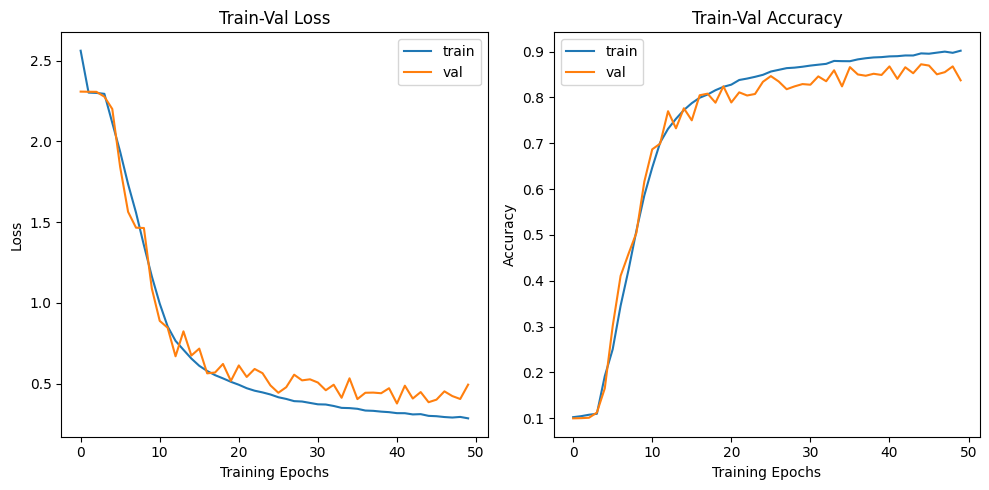
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=0.1, patience=10, verbose=True) # Validation error가 줄지 않으면 10만큼 곱하여 줄임6. Conclusion
[Training] loss: 2.5621, accuracy: 0.1025: 100%|██████████| 782/782 [09:49<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.78it/s]
epoch 001, Training loss: 2.5621, Training accuracy: 0.1025
Test loss: 2.3088, Test accuracy: 0.0999
[Training] loss: 2.1157, accuracy: 0.1919: 100%|██████████| 782/782 [09:48<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.77it/s]
epoch 005, Training loss: 2.1157, Training accuracy: 0.1919
Test loss: 2.2013, Test accuracy: 0.1653
[Training] loss: 1.1649, accuracy: 0.5863: 100%|██████████| 782/782 [09:49<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.75it/s]
epoch 010, Training loss: 1.1649, Training accuracy: 0.5863
Test loss: 1.0895, Test accuracy: 0.6163
[Training] loss: 0.6558, accuracy: 0.7725: 100%|██████████| 782/782 [09:49<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.74it/s]
epoch 015, Training loss: 0.6558, Training accuracy: 0.7725
Test loss: 0.6743, Test accuracy: 0.7764
[Training] loss: 0.5116, accuracy: 0.8232: 100%|██████████| 782/782 [09:49<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.74it/s]
epoch 020, Training loss: 0.5116, Training accuracy: 0.8232
Test loss: 0.5172, Test accuracy: 0.8243
[Training] loss: 0.4332, accuracy: 0.8494: 100%|██████████| 782/782 [09:49<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.74it/s]
epoch 025, Training loss: 0.4332, Training accuracy: 0.8494
Test loss: 0.4895, Test accuracy: 0.8342
[Training] loss: 0.3809, accuracy: 0.8670: 100%|██████████| 782/782 [09:49<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.76it/s]
epoch 030, Training loss: 0.3809, Training accuracy: 0.8670
Test loss: 0.5271, Test accuracy: 0.8292
[Training] loss: 0.3488, accuracy: 0.8792: 100%|██████████| 782/782 [09:49<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.77it/s]
epoch 035, Training loss: 0.3488, Training accuracy: 0.8792
Test loss: 0.5333, Test accuracy: 0.8242
[Training] loss: 0.3237, accuracy: 0.8880: 100%|██████████| 782/782 [09:48<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.75it/s]
epoch 040, Training loss: 0.3237, Training accuracy: 0.8880
Test loss: 0.4719, Test accuracy: 0.8491
[Training] loss: 0.3008, accuracy: 0.8962: 100%|██████████| 782/782 [09:48<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.76it/s]
epoch 045, Training loss: 0.3008, Training accuracy: 0.8962
Test loss: 0.3853, Test accuracy: 0.8724
[Training] loss: 0.2854, accuracy: 0.9020: 100%|██████████| 782/782 [09:48<00:00, 1.33it/s]
100%|██████████| 157/157 [00:27<00:00, 5.76it/s]
epoch 050, Training loss: 0.2854, Training accuracy: 0.9020
Test loss: 0.4941, Test accuracy: 0.8374
github : https://github.com/PARKYUNSU/Resnet
