"Learning Pyramid-Context Encoder Network for High-Quality Image Inpainting" 논문을 리뷰해보는 시간을 갖겠습니다.
Abstract & Introduction
High quality image inpainting은 missing area를 plausible(그럴듯한, 원본 이미지와 최대한 비슷하다는 의미의) content로 채워넣어야함.
이는 visual coherence, semantic coherence 모두 만족시킬 수 있어야 함.
현재 존재하는 inpainting technique들은 두 종류로 나눌 수 있음.
-
단순하게 image patches를 복사해서 집어넣는 경우 semantic coherence content 생성에 있어서 실패할 가능성이 높음
-
앞 선 문제를 해결하기 위해 semantic context를 encode해서 얻은 latent feature를 이용해 patch를 generate할 경우 visually realistic한 결과물을 얻기 어려움. --> encoding 과정(stacked convolution, pooling)에서 image의 detail이 smoothing 되기 때문.
논문에서 제시하는 Pyramid-context Encoder Network(PEN-Net)은 U-Net 구조 기반의 deep generative model임.
주목할만한 특징으로는
-
U-Net을 기반으로 함으로써 pixel-level context, high-level semantic feature를 모두 사용할 수 있음.
-
image로부터 latent feature를 얻게 되면 이를 pyramid 구조 통해서 high-level 부터 low-level까지 단계적으로 채워 넣어감.
또한 ATN(Attentaion transfer network)를 이용해 missing region의 안쪽과 바깥쪽 사이 region affinity를 학습 후 transfer.
-
multi-scale decoder를 통해 ATN으로부터 생성된 feature를 이용, decode.
PEN-Net은 pyramid-L1 loss와 adversarial loss를 이용.
이를 통해 visual, semantic coherence 두 부분 모두 만족시킬 수 있음.
Pyramid-context Encoder Network
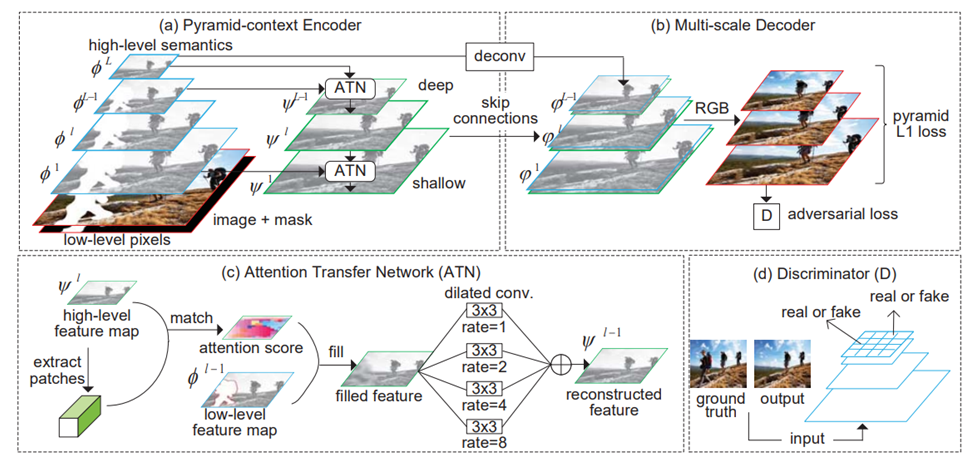
사진은 PEN-Net의 구조
PEN-Net은 크게 세 가지 부분으로 나눌 수 있음.
-
Pyramid context encoder : U-Net 구조로 생성된 compact latent feature에 semantics of context가 저장되어 있으므로, compact latent feature를 이용해 missing region을 채워넣을 수 있음.
채워넣을 때, Attention Transfer Network(ATN)을 여러번 이용하는데, ATN은 high-level semantic feature로부터 missing region의 inside/outside 사이의 region affinity를 학습하고 다른 feature map으로 transfer함.
multi-scale information은 ATN에서 다양한 수준의 convolution을 통해 수집되어 후에 missing region을 채워넣은 것을 다듬는 작업에 사용됨.
-
multi-scale decoder : ATN으로부터 재생성된 Feature map을 skip connection을 통해 받고, latent feature 이렇게 총 두 가지를 받아서 decode에 이용.
이때 loss로 adversarial loss와 pyramid loss(multi-scale loss)를 이용해 prediction(inpainting results)를 다듬음.
-
discriminator : adversarial loss를 사용하기 위함.
Pyramid-context encoder
Pyramid-context encoder
encoding의 효율성을 향상시키기 위해, pyramid context encoder는 decoding 과정 이전에 missing region을 채워넣음.
compact latent feature가 학습되면, missing region을 high-level semantic feature부터 차근차근 low-level feature까지 ATN 사용을 반복하며 채워넣는 형식.
Pyramid-context encoder가 개의 layer로 이루어져있으면, 가장 깊은 feature map부터 얕은 feature map을 , , ... , 로 정의할 수 있음.
그리고 이 feature map과 ATN을 이용해 재생성한 feature는 다음과 같이 정의 가능.
=
=
.
.
.
= =
여기서 ATN은 로 나타냈음.
이런 cross-layer attention transfer(ATN)과 pyramid filling mechanism을 통해 visual and semantic coherence를 모두 해결할 수 있음.
Attention Transfer Network(ATN)
attention은 missing region의 inside/outside patch(3 x 3 size)간의 region affinity를 통해 얻을 수 있음.
이런 연산을 통해 missing region의 outside에 존재하는 relevant feature가 inside로 전해질 수 있음.
ATN은 로부터 region affinity를 얻음.
로부터 patches를 추출, missing region의 inside와 outside간 cosine 유사도를 측정.
= (,)
는 의 outside mask 중 i번째 patch, 는 의 mask의 inside 중 j번째 patch
그 후, 위에서 구한 cosine 유사도에 softmax를 적용해 각 patch들에 대한 attention score를 계산
=
이렇게 얻은 attention score를 통해 missing region을 다음 식을 이용해 missing region을 채워넣을 수 있음.
=
이때 는 에서 추출한 outside masked regions의 i번째 patch, $p^{l-1}_j는 missing region을 채워넣을 j번째 patch.
모든 patch들에 대해 연산, 채워넣기가 완료되면 을 얻을 수 있음.
Multi-scale decoder
Multi-scale decoder
multi-scale decoder는 ATN을 이용해 재생성한 feature와 latent feature map 두 가지를 input으로 받아 decode 연산을 수행하여 multi-scale feature map을 생성함.
깊은 feature map부터 차례대로
=
=
.
.
.
=
여기서 는 transposed convolution 연산, 는 feature concatenation, 은 encoder의 l번째 layer에 있는 ATN으로 부터 재생성된 feature 의미.
ATN으로부터 재생성된 feature는 low-level information이 풍부해서 decoder가 visually realistic한 결과를 내는 것에 도움이 됨.
또 latent feature의 경우 missing region을 synthesize하는 것에 도움이 됨.
이 두 가지 이점을 decoder가 활용해 visual, semantic coherence를 충족시킬 수 있음.
Pyramid L1 losses
decoder를 통해 생성한 결과와 groud truth(물론 생성한 결과에 맞춰 여러 size로 scaling한 이미지를 말함)의 L1 distance를 구함.
후술할 Adversarial loss 까지 합친게 전체 objective function
Adversarial training loss
= ground truth
= prediction(inpainting results)
=
=
로 Adversarial Loss를 정의할 수 있음.
Experiments & Conclusion
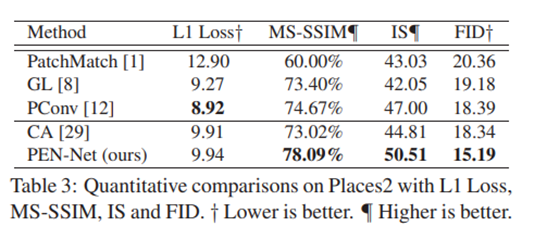
위 사진은 places2 dataset에 대해 inpainting 수행 결과에 대한 수치적 평가를 비교한 것.
제안한 모델 PEN-net은 L1 loss를 제외한 MS-SSIM, IS, FID에서 가장 좋은 결과를 보여줬음.

위 사진은 위에서부터 Facade dataset, places2 dataset, celeba-hq dataset에 대해 inpainting 한 결과에 대해 질적인 비교를 나타냄.
결과적으로 pyramid L1 loss와 ATN(Attention transfer network)를 사용한 PEN-net이 가장 좋은 결과를 보여줬음.
