"PEPSI : Fast Image Inpainting with Parallel Decoding Network" 논문을 리뷰해보는 시간을 갖겠습니다.
Abstract & Introduction
GAN을 기반으로 CAN(contextual attention module)을 사용하는 coarse-to-fine network가 image inpainting에서 좋은 결과를 내고 있음.
하지만 coarse-to-fine의 연산 비용이 너무 큰 문제점이 존재.
따라서 이 논문에서는 PEPSI(Parallel extended-decoder path for semantic inpainting)을 제시.
PEPSI는 single encoding network와 parellel decoding network를 이용해 convolution 연산의 양을 효과적으로 줄였음.
decoding network는 coarse path와 inpainting path, 이 두 가지 path가 parellel하게 연결되어있음.
coarse path의 경우 살짝 거친('완벽하지 않은' 이라는 의미로 받아들이면 될 듯) inpainting result를 생성하여 CAM(Contextual attention module)이 feature를 만들 수 있게 해줌.
inpainting path의 경우 CAM이 만든 feature를 바탕으로 high-quality inpainting result를 생성시킴.
또한 CAM의 경우, 기존의 cosine similarity를 사용한 것을 Euclidean distance로 교체하여 inpainting region의 안쪽과 바깥쪽의 관계성(relationship)을 더욱 잘 나타낼 수 있게 수정함.
discriminator의 경우 이미지 전체에 대해 real/fake를 판단하지 않고, image region 각각에 대해 real/fake를 판단.
PEPSI는 기존의 coarse-to-fine network에 비해 연산량을 반 가까이 줄였을 뿐만 아니라 시간적으로도, 질적으로도 좋은 결과물을 만들어냄.
Proposed Method
CAM(contextual attention module)은 patches(missing region에 대한 안과 밖) 유사도를 기반으로, known background feature(이미 존재하는 feature)를 이용해 missing region의 feature를 생성함.
따라서 조금이라도 완성된(missing region이 roughly하게 채워진) image(coarse result)에서 feature를 가져와야할 필요가 있음.
이는 결국 coarse-to-fine network는 두 번의 encoding-decoding 과정을 거쳐야 한다는 의미(coarse result, refine result).
이는 계산량이 많아지는 문제에 도달하게 됨.
Architecture of PEPSI
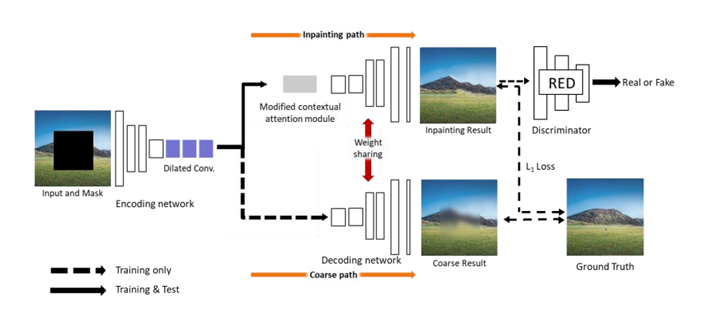
위 사진은 PEPSI의 architecture를 나타낸 사진
논문에서 제안하는 PEPSI는 위에서 언급한 두 번의 encoding-decoding 과정을 single encoding-decoding network로 합쳤음.
encoding network는 input image의 feature를 추출하는데, 이때 missing feature에 대해서도 완성을 시켜가면서 feature를 추출함.
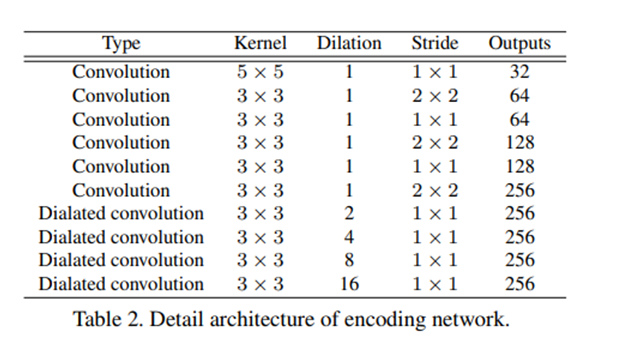
위의 표(encoding network의 구조)를 보면 3 x 3 convolution series에 통과시키기 전에 5 x 5 convolution 연산을 한번 진행함을 볼 수 있음.
이 5 x 5 convolution layer는 이미지 전체의 latent feature를 갖고오는 효과를 가지고 있음.
또한 다양한 dilation rate를 가진 dilated convolution layer를 사용하여 large receptive fields에서 feature를 추출하게 됨.
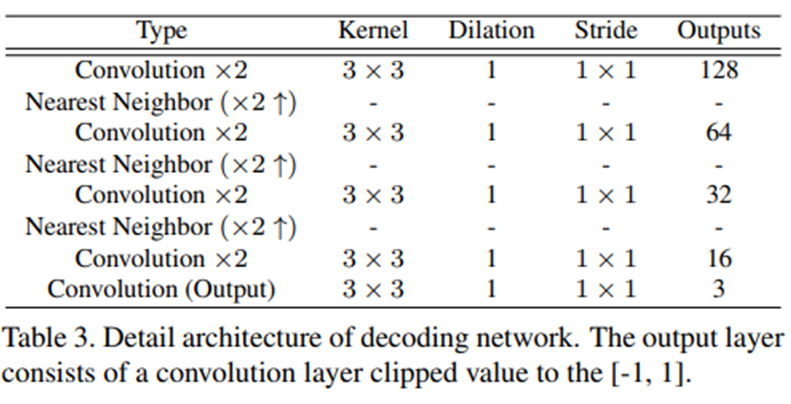
위의 표는 decoding network의 구조를 나타낸 표임.
coarse path에서는 encoding network로부터 받은 feature map을 이용해 rougly completed result를 생산해내는 역할을 수행.
inpainting path에서는 encoding network로부터 받은 feature map에 대해 CAM이 다시 feature map을 reconstruction 하고, reconstructed feature map에 대해 higher-quality result를 생성하는 역할을 수행.
이 두 path decoder가 weight을 공유하면서, inpainting path decoder에 regularization 효과를 줌.
또한 testing 과정에서는 inpainting path decoder만 사용하기 때문에 계산량이 확연히 주는 효과가 생김.
Training 과정에서 coarse path는 reconstruction L1 loss, inpainting path는 reconstruction L1 loss + adversarial loss를 사용했음.
또한 모든 convolution layer에 대해 mirror padding을 적용하고 activation function은 ELU를 사용.
input image에 대해서는 [-1, 1]로 normalize 시켰고, output image에 대해서는 [-1, 1]로 clipping 시켜줬음.
Modified CAM
기존의 CAM은 cosine similarity를 사용했음.
하지만 cosine similarity를 구하는 과정 중 normalize 하는 과정에서 semantic feature representation이 손상될 수 있다고 봤음.
그래서 Euclidean distance를 도입했음.
Euclidean distance는 두 vector 사이의 각도를 고려할 뿐만 아니라, magnitude까지 고려하기 때문에 reconstruction에 있어서 더 효과적이라고 생각.
또 Euclidean distance를 이용해 구한 distance similarity에 tanh를 적용해 범위가 [-1. 1]인 truncated distance similarity scores를 구했음.
이를 수식으로 나타내면
=
=
로 나타낼 수 있음
를 통해 [-1, 1]로 범위를 줄여주면 foreground patch와 background patch의 연관관계를 더 잘 표현할 수 있음(이 부분은 잘 이해가 안됨...)
Region Ensemble Discriminator(RED)
PEPSI 구조는 GAN을 기반.
기존의 local, global discriminator 둘 다 사용하는 방법은 전체 이미지와 local texture 모두를 고려하는 좋은 방법이였지만, missing region이 fixed size일 경우에만 잘 작동함.
따라서 임의의 모양이나 크기에 따른 missing region에서는 효과를 기대하기 힘듦.
이 문제를 해결하기 위해 이 두가지 discriminator를 ensemble 시켰음.
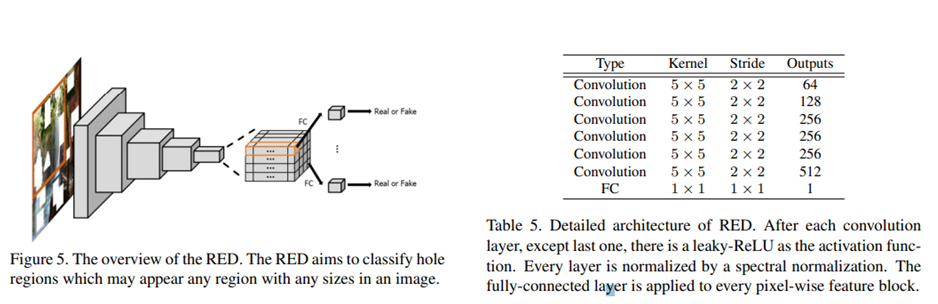
사진과 표는 RED의 구조를 나타냈음.
RED의 마지막 layer에서는 pixel 단위로 real/fake 판단을 실행함.
따라서 various hole(missing region)에 대해 잘 대응할 수 있음.
Loss function
GAN loss의 특성 중 generator가 잘 학습되지 않는 문제점을 해결하기 위해 다음과 같은 해결책을 사용했음.
-
generator에는 adversarial loss
-
discriminator에는 hinge loss + spectral normalization
또한 regularization 까지 적용해서 다음과 같은 loss 생성.
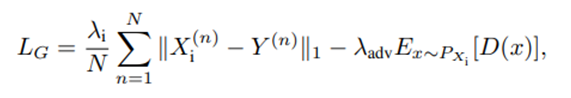
또한 reconstruction L1 loss의 경우 아래와 같음.
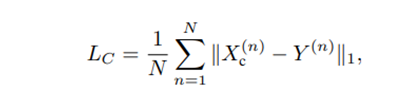
최종 loss는 다음과 같음.
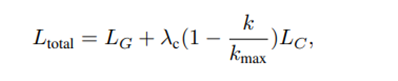
Experiments
Implementation details
Free-From Mask

왼쪽부터 차례대로 original image, square masked image, free-form masked image
regular mask로 학습된 network는 여러 형태의 missing region이 있는 image에 대해서 좋지 못한 결과를 내기 때문에 위 사진처럼 free-form masked image를 이용해 학습을 진행했음.
Training Procedure
batch size : 8
optimizer : ADAM
Learning rate scheduler : TTUR scheduler
Performance Evaluation
CelebA-HQ dataset, ImageNet dataset, Place2 dataset을 이용해 평가를 진행했음.
Qualitative Comparison


기존의 method들에 비해 PEPSI가 시각적으로 더 좋은 결과를 만들었음을 확인할 수 있다.
Quantitative Comparison
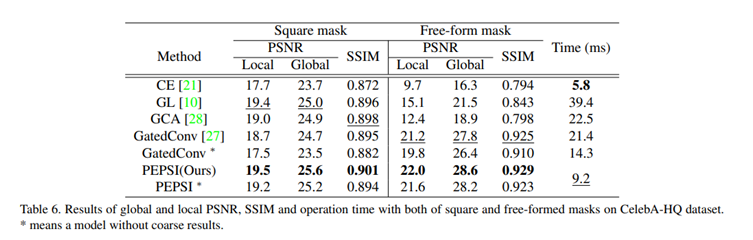
마찬가지로 수치적으로도 좋은 결과를 냈음을 확인할 수 있다.
주목할만한 점은 수치적으로 좋은 결과가 나왔음에도 불구하고 수행시간은 짧다는 점이다.
Conclusion
PEPSI는 coarse-to-fine network의 두 단계 encoding-decoding network를 한 단계로 합치면서 paramter reducing을 이뤄냈고, reducing에도 불구하고 시각적 수치적으로 좋은 결과를 확인할 수 있었다.
