distortion correction(4)
DR-GAN: Automatic Radial Distortion Rectification Using Conditional GAN in Real-Time
논문을 리뷰해보는 시간을 갖겠습니다.
Abstract & Introduction
Radial distortion(방사형 왜곡)의 보정에 관한 연구.
논문에서 제시하는 DR(distortion rectification)-GAN의 장점은
-
radial distortion의 보정을 위한 여러 방법들 중 최초의 end-to-end trainable model
-
one-stage rectification, 즉 한번의 과정으로 보정을 했기에 다른 방법들 보다 보정에 걸리는 시간이 매우 적어 real-time에 응용이 가능
-
2의 장점에도 불구하고 DR-GAN은 수치적 평가에서 좋은 결과를 기록
으로 나열할 수 있음.
2의 장점에 대해 좀 더 자세히 설명하자면, 이 논문 이전의 방법들은 대부분 two-stage rectification을 이용했는데 이는 stage 1에서 왜곡 계수를 추정하고 stage 2에서 추정한 왜곡 계수를 바탕으로 이미지를 보정하는 과정임.
이 논문에서는 one-stage rectification을 이용해 좀 더 빠른 연산 속도를 보여줬다는 것이 장점 2.
Proposed method
Network Architecture
Generator
이 논문에서는 GAN을 이용했고, 그 중 Generator에 관한 설명.
Generator는 왜곡 이미지와 정상 이미지의 구조적 차이를 학습해야 하며 학습한 차이를 통해 왜곡 이미지를 보정 시킬 수 있어야 함.
이를 위해 high-level information에서는 이미지의 구조적 차이, low-level information에서는 texture와 같은 이미지 질감 등을 학습해야 함.
그런 이유로 인해 Generator를 U-Net 구조 바탕으로 만들었음.(skip-connection을 이용해 low level과 high level information을 모두 사용할 수 있음.)
따라서 Generator에는 encoder와 decoder가 존재하며 encoder에는 8개의 convolution layer 그리고 그에 뒤따르는 Batch normalization과 LeakyReLU 함수를 이용함.
decoder는 encoder에서 압축한 이미지를 다시 원래 크기로 만들어줘야 하므로 encoder와 반대 성질의 layer를 사용 해야 하는데, 여기서는 checkerboard artifact를 고려해 upsampling + transposed convolution을 이용해 deconvolution을 구현했음.

위 사진은 checkerboard artifact의 예시
또 앞서 언급한 low, high information을 모두 사용하기 위해 Generator의 i번째 layer와 n-i 번째 layer를 skip-connection을 통해 연결해줬음.
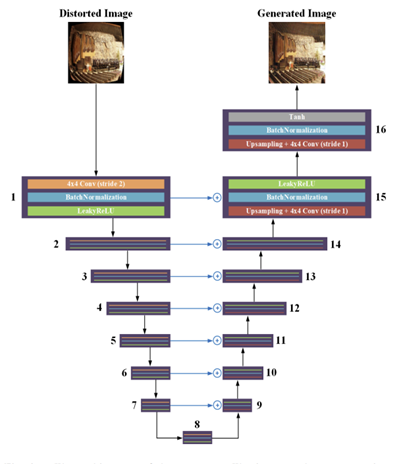
Generator의 경우 총 16개의 layer로 이루어져 있음.
Discriminator
Discriminator의 경우 Convolution layer와 그에 뒤따르는 batch normalization, LeakyReLU를 6개의 층으로 쌓고 마지막 layer의 경우 2개의 fully connected layer를 이용해 Generator의 출력을 판별.
Loss function
Content Loss
일반적으로 신경망을 학습시킬 때 l1, l2 loss가 사용되지만, 타 연구 결과에 따르면 l1, l2 loss를 사용할 경우 이미지 생성에 있어서 blur가 껴있는 이미지를 생성하는 문제가 있음.
이 문제를 해결하기 위해 perceptual loss를 기반으로 한 content loss를 제시.
Perceptual loss의 경우 ImageNet으로 pre-trained 된 VGG19를 이용해 ground truth와 distorted 이미지의 feature map을 뽑고, 두 feature map 사이의 유클리디안 거리를 계산한 것.
이를 수식으로 나타내면
=
로 나타낼 수 있음.
이때 의 의미는 VGG의 i번째 maxpooling layer 바로 전의 j번째 convolution layer임을 의미함.
CNN의 낮은 layer는 간단한 feature를 포착하고, 높은 layer는 복잡한 feature를 포착하는 점을 이용해 low perceptual loss와 high perceptual loss를 만들었고 이를 DR-GAN 학습에 이용했음.
해당 수식은
= +
로 나타낼 수 있으며 는 두 loss를 조절하는 weight이라 여기면 됨.
Adversarial loss
negative 로그우도를 이용해 adversarial loss를 설정했으며 수식은 다음과 같음.
이때 는 generator가 만든 이미지가 original 이미지라고 판별했을 확률을 의미함.
그래서 최종적인 loss 함수는
로 나타낼 수 있음.
Dataset
모델을 학습하기 위해 dataset이 필요한데, 여기서는 even-order polynomial model(왜곡 모델의 종류, 왜곡 계수의 제곱수 종류에 따른 명칭)을 이용해 왜곡 이미지를 생성했음.
Experiments
Training details
학습시킨 장비에 대한 설명과 그 외의 hyperparams에 대한 설명.
Adam optimzer와 의 learning rate를 사용했고 low perceptual loss의 VGG는 high의 경우는 사용.
Generator와 Discriminator의 학습 비율을 1 : 10으로 설정했으며 16 batch size와 2000 epochs 학습.
Analysis of the loss function
앞서 언급한 low to high perceptual loss를 이용했을 때 좋은 결과가 나옴을 실험 통해 확인할 수 있음.
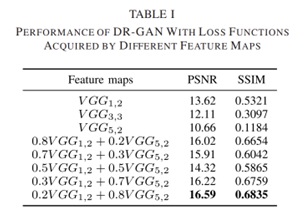
위 표를 보면 하나의 VGG layer를 사용할 때보다 두 layer를 합쳐 사용함이 PSNR과 SSIM과 같은 수치적 평가 결과에서 좋은 모습을 보이며, 많은 실험을 통해 의 최적값인 0.2를 찾았음.
Experimental Evaluation
Visual comparison

이전 연구들에 비해 시각적으로 좋은 결과가 나왔음을 설명함.
Quantitative measurement
역시 이전 연구들에 비해 수치적으로 좋은 결과가 나왔음을 설명함.
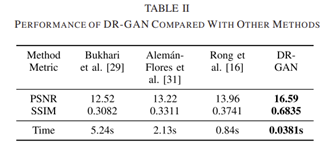
주목할 점은 rectification 실행 시간 또한 가장 짧았음.
Robustness
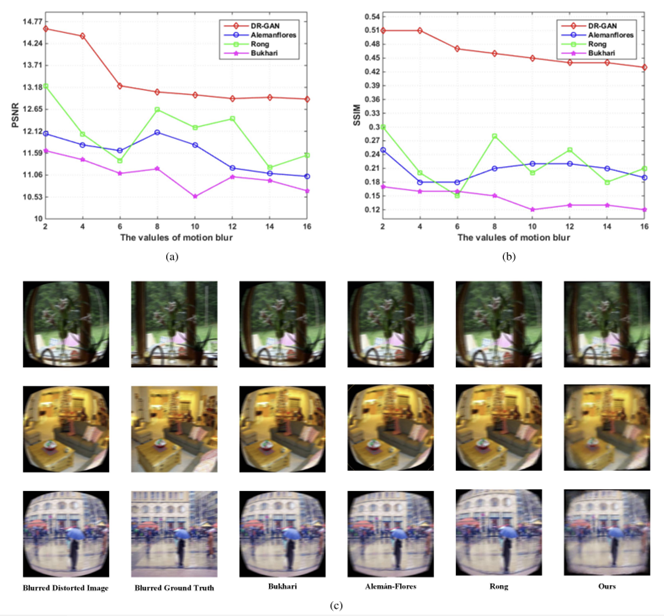
또한 이미지를 얻는 과정에서 진동이나 몸 동작으로 인해 흔들려 이미지에 blur가 생기는 경우가 있는데, 여기서는 blur의 세기별로 이미지에 가하여 역시 이전 연구들과 비교하였으며 DR-GAN이 blur에 어느 정도 robust하다는 것을 보여주고 있음.
나의 결론
이전에 내가 진행한 프로젝트에서는 왜곡 보정 시간이 길었는데, 이 논문 제목에 real-time이 들어가있어 어떻게 수행 시간을 줄이는지 궁금해 이 논문을 선정하게 됐었다.
뭔가 특별한(?) 혹은 고난이도의 기술이 들어가있지 않을까 했는데 단지 보정 과정 자체를 하나로, 좀 더 간단한 모델을 사용해서 보정 시간을 줄였다는게 신기하면서도 허무.
