이번 글에서는 React 환경에서 YOLOv11n 모델과 ONNX Runtime Web을 활용해 웹 브라우저에서 직접 객체 인식을 수행하는 방법을 공유합니다.
목차
개요 및 배경
웹 애플리케이션에서 머신러닝 모델을 활용할 때는 주로 서버에 요청을 보내는 방식을 사용합니다. 하지만 이 방식은 네트워크 지연, 서버 비용, 개인 정보 보호 등의 이슈가 있습니다.
이를 해결하기 위해 클라이언트 사이드 추론(Client-side Inference)이 대안으로 떠오르고 있습니다. 특히 ONNX Runtime Web과 같은 라이브러리의 등장으로 브라우저에서 직접 딥러닝 모델을 실행하는 것이 가능해졌습니다.
이번 R&D에서는 React 환경에서 YOLOv11n 객체 인식 모델을 ONNX 형식으로 변환하고, 웹 브라우저에서 실시간으로 비디오 스트림에서 객체를 감지하는 기능을 구현했습니다.
객체 인식 기본 개념
먼저 객체 인식의 핵심 개념부터 살펴보겠습니다.
객체 인식이란?
객체 인식(Object Detection)은 이미지나 비디오에서 물체를 찾고, 그것이 무엇인지 분류하고, 어디에 위치하는지 파악하는 컴퓨터 비전 기술입니다.
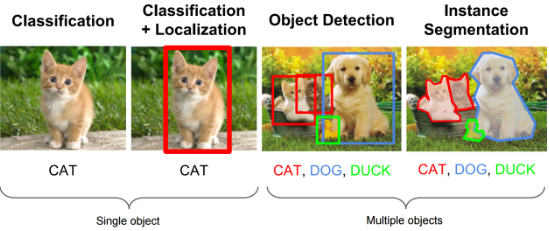
객체 인식은 다음 개념들로 구성됩니다.
- 이미지 분류(Classification): 이미지에 무엇이 있는지 판별
- 객체 위치 추정(Localization): 객체가 이미지의 어디에 있는지 경계 상자(bounding box)로 표시
- 객체 탐지(Detection): 분류 + 위치 추정을 결합하여 이미지 내 여러 객체를 동시에 식별
YOLO란?
YOLO(You Only Look Once)는 실시간 객체 인식을 위한 인기 있는 모델입니다. 기존 방식과 달리 이미지를 한 번만 처리하여 객체를 감지하므로 속도가 빠른 것이 특징입니다.
YOLO 모델은 다음과 같이 구분됩니다:
- Two-stage 검출기: R-CNN, Fast R-CNN, Faster R-CNN (정확도 높음)
- One-stage 검출기: YOLO, SSD, NanoDet (속도 빠름)
우리가 사용한 YOLOv11n은 YOLO 모델의 최신 버전 중 하나로, 경량화되어 웹 환경에서도 효율적으로 동작합니다.
객체 인식 모델 평가 지표
객체 인식 모델의 성능을 평가하는 주요 지표를 알아보겠습니다.
IoU(Intersection over Union)
IoU는 예측된 바운딩 박스가 실제 바운딩 박스와 얼마나 정확하게 일치하는지 측정하는 지표입니다.
IoU = (예측 box와 실제 box의 겹치는 영역) / (예측 box와 실제 box의 합집합 영역)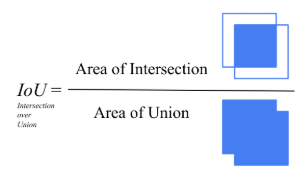
- IoU = 1.0 (100%): 완벽하게 일치
- IoU = 0.0 (0%): 전혀 겹치지 않음
일반적으로 IoU 값이 0.5 이상이면 해당 예측을 '정확한 감지'로 간주합니다.
Precision과 Recall
객체 인식에서 가장 중요한 평가 지표 중 두 가지입니다.
Precision(정밀도)
- 정의: 모델이 "객체가 있다"고 예측한 것 중에서 실제로 맞게 예측한 비율
- 수식: Precision = TP / (TP + FP)
- 의미: 감지했다고 주장한 것들 중 실제로 맞은 비율
- 예시: 모델이 10개의 객체를 찾았는데, 그 중 7개만 실제로 맞고 3개는 오탐지라면 Precision = 7/10 = 0.7 (70%)
Recall(재현율)
- 정의: 실제 존재하는 객체 중에서 모델이 올바르게 찾아낸 비율
- 수식: Recall = TP / (TP + FN)
- 의미: 실제로 있는 것들 중 찾아낸 비율
- 예시: 이미지에 실제로 8개의 객체가 있는데, 그 중 7개를 찾고 1개를 놓쳤다면 Recall = 7/8 = 0.875 (87.5%)
용어 설명:
- TP(True Positive): 실제 있는 객체를 올바르게 찾은 경우
- FP(False Positive): 없는데 있다고 잘못 찾은 경우(오탐지)
- FN(False Negative): 있는데 찾지 못한 경우(미탐지)
mAP(mean Average Precision)
mAP는 객체 인식 모델의 전체적인 정확도를 측정하는 핵심 지표입니다.
- AP(Average Precision):
- 한 클래스에 대한 Precision-Recall 곡선 아래 영역의 넓이
- 예: "사람" 클래스에 대한 AP = 0.90 (90%)
- mAP(mean Average Precision):
- 모든 클래스의 AP 값을 평균낸 것
- 예: "사람" AP = 0.90, "자동차" AP = 0.85, "개" AP = 0.75 → mAP = 0.83 (83%)
Precision-Recall 곡선은 다음과 같이 생성됩니다:
-
신뢰도 점수(Confidence Score):
- 객체 인식 모델은 각 예측마다 "이게 객체일 확률"을 신뢰도 점수로 출력
- 예: "고양이 90%", "개 85%", "자동차 60%" 등
-
신뢰도 임계값 변화:
- 임계값을 높게 설정: 확실한 객체만 감지 → Precision ↑, Recall ↓
- 임계값을 낮게 설정: 더 많은 객체 감지 → Precision ↓, Recall ↑
-
곡선 그리기:
- 여러 임계값마다 Precision과 Recall을 계산
- x축(Recall)과 y축(Precision)에 점을 찍어 곡선 형성
F1-Score: Precision과 Recall의 조화평균으로, 모델 성능을 단일 숫자로 평가
F1 = 2 (Precision Recall) / (Precision + Recall)
구현 환경
이번 프로젝트에서 사용한 기술과 도구는 다음과 같습니다.
- 프론트엔드: React, TypeScript
- 객체 인식 모델: YOLOv11n
- 모델 실행 환경: ONNX Runtime Web
- 비디오 처리: HTML5 Video 및 Canvas API
ONNX 포맷의 이점
ML 모델은 보통 PyTorch, TensorFlow 등으로 개발되어 .pt 또는 .pth 확장자로 저장됩니다. 그러나 이들은 원래 환경에서만 실행 가능합니다.
ONNX(Open Neural Network Exchange)는 다양한 환경에서 실행 가능한 표준 형식으로, 브라우저에서도 실행할 수 있습니다. 우리는 YOLOv11n 모델을 ONNX 형식으로
변환하여 웹에서 사용했습니다.
ONNX Runtime Web
ONNX Runtime Web은 ONNX 모델을 웹 브라우저에서 실행할 수 있게 해주는 JavaScript 라이브러리입니다.
주요 특징:
- 클라이언트 사이드 추론: 서버 없이 브라우저에서 직접 딥러닝 모델 실행
- 다양한 백엔드 지원: WebGL(GPU 가속), WASM(CPU 기반) 등
- 자동 폴백: WebGL 실패 시 WASM으로 자동 전환 가능
- 최적화 기능: 자동 그래프 최적화, 효율적인 메모리 관리
- 양자화 모델 지원: 8비트 정수 양자화 등 경량화된 모델 실행 가능
데모 및 구현 결과
이론적인 내용을 바탕으로 실제 동작하는 웹 애플리케이션을 구현했습니다.
라이브 데모
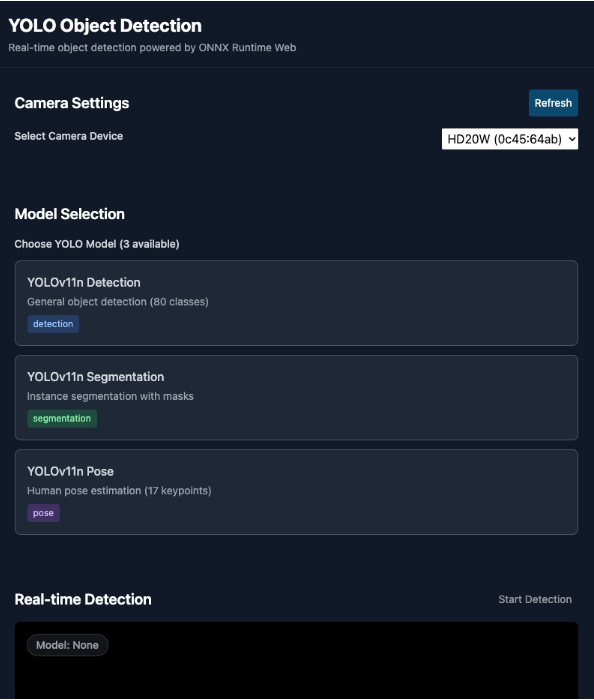
데모 페이지: https://qkrdkwl9090.github.io/react-yolo11n-object-detection-web
GitHub Repository: https://github.com/qkrdkwl9090/react-yolo11n-object-detection-web
웹캠을 통한 실시간 객체 인식, 이미지 업로드를 통한 객체 감지, 그리고 비디오 파일 분석 등의 기능을 직접 체험해볼 수 있습니다.
지원하는 모델
이번 구현에서는 YOLOv11 시리즈의 세 가지 모델을 지원합니다.
1. YOLO11n - 객체 감지
- 입력 크기: 640×640
- 모델 크기: 10.7MB
- 기능: 80가지 객체 클래스 감지
- 용도: 일반적인 객체 인식 (사람, 자동차, 동물 등)
2. YOLO11n-seg - 세그멘테이션
- 입력 크기: 640×640
- 모델 크기: 11.7MB
- 기능: 인스턴스 세그멘테이션 마스크 생성
- 용도: 객체의 정확한 윤곽선 추출
3. YOLO11n-pose - 포즈 추정
- 입력 크기: 640×640
- 모델 크기: 11.8MB
- 기능: 17개 인체 관절 추정
- 용도: 사람의 자세 분석 및 동작 인식
주요 기능
- 실시간 웹캠 객체 인식: 브라우저 웹캠을 통한 실시간 감지
- 결과 시각화: 바운딩 박스, 마스크, 관절점 등의 직관적 표시
결과 및 정리
실제 성능
- 로딩 시간: 초기 모델 로딩에 약 1-2초 소요
- 추론 속도: 10-20 FPS (디바이스 성능에 따라 차이)
- 정확도: mAP@0.5 약 27% (YOLOv11n 기준)
- 모델 크기: 10.7MB ~ 11.8MB (모델별 상이)
ONNX Runtime Web의 장점
클라이언트 사이드 추론
- 서버 비용 절감: 추론이 사용자 디바이스에서 실행되어 서버 인프라 비용 불필요
- 실시간 처리: 네트워크 지연 없이 즉시 결과 제공
- 프라이버시 보장: 영상 데이터가 사용자 디바이스를 벗어나지 않음
- 오프라인 지원: 인터넷 연결 없이도 추론 가능
하드웨어 가속
- 브랜드 중립적: NVIDIA, AMD, Intel, Apple Silicon 모든 GPU 지원
- WebGPU 표준: 브라우저 표준 기술로 네이티브 수준의 GPU 성능 활용
- 자동 최적화: 사용자 하드웨어에 맞춰 최적의 실행 백엔드 선택
한계점과 고려사항
성능 일관성 문제
- 디바이스 성능 의존: 사용자 하드웨어에 따라 추론 속도 편차 발생
- 고성능 GPU: ~30-60fps
- 중급 GPU: ~15-30fps
- CPU만 사용: ~5-15fps
- 배터리 소모: 모바일 디바이스에서 GPU 사용 시 배터리 사용량 증가
브라우저 호환성
- WebGPU 지원: Chrome 113+, Edge 113+, Safari 18+
- 메모리 제한: 브라우저 메모리 제한으로 대형 모델 사용 어려움
- 초기 로딩 시간: 모델 다운로드 및 초기화에 1-2초 소요
결론
프론트엔드 개발에서도 딥러닝 기술을 직접 활용할 수 있는 시대가 됐습니다. ONNX Runtime Web과 같은 라이브러리는 웹 브라우저에서 객체 인식과 같은 복잡한 AI 작업을 가능하게 만들어 주었고, 이는 프론트엔드 개발자에게 새로운 가능성을 보여준다 생각합니다.
참고 자료:
