PydanticOuputParser란
언어 모델의 출력을 더 구조화된 정보로 변환하는 데 도움이 되는 클래스이다.
단순 텍스트 형태의 응답 대신, 사용자가 필요로 하는 정보를 명확하고 체계적인 형태로 제공할 수 있다.PydanticOuputParser에는 주로 두 가지 핵심 메서드가 구현되어야 한다.
get_format_instructions()
언어 모델이 출력해야 할 정보의 형식을 정의하는 지침 (instruction)을 제공한다.
예를 들어, 언어 모델이 출력해야 할 데이터의 필드와 그 형태를 설명하는 지침을 문자열로 반환할 수 있다.
이 때 설정하는 지침의 역할이 매우 중요하다.
이 지침에 따라 언어 모델은 출력을 구조화하고, 이를 특정 데이터 모델에 맞게 변환할 수 있다.parse()
언어 모델의 출력 (문자열로 가정)을 받아들여 이를 특정 구조로 분석하고 변환한다.
Pydantic와 같은 도구를 사용하여, 입력된 문자열을 사전 정의된 스키마에 따라 검증하고,
해당 스키마를 따르는 데이터 구조로 변환한다.이메일 본문
email_conversation = """
From: 김철수 (chulsoo.kim@bikecorporation.me)
To: 이은채 (eunchae@teddyinternational.me)
Subject: "ZENESIS" 자전거 유통 협력 및 미팅 일정 제안
안녕하세요, 이은채 대리님,
저는 바이크코퍼레이션의 김철수 상무입니다.
최근 보도자료를 통해 귀사의 신규 자전거 "ZENESIS"에 대해 알게 되었습니다.
바이크코퍼레이션은 자전거 제조 및 유통 분야에서 혁신과 품질을 선도하는 기업으로,
이 분야에서의 장기적인 경험과 전문성을 가지고 있습니다.
ZENESIS 모델에 대한 상세한 브로슈어를 요청드립니다. 특히 기술 사양, 배터리 성능,
그리고 디자인 측면에 대한 정보가 필요합니다.
이를 통해 저희가 제안할 유통 전략과 마케팅 계획을 보다 구체화할 수 있을 것입니다.
또한, 협력 가능성을 더 깊이 논의하기 위해 다음 주 화요일(1월 15일) 오전 10시에 미팅을 제안합니다.
귀사 사무실에서 만나 이야기를 나눌 수 있을까요?
감사합니다.
김철수
상무이사
바이크코퍼레이션
"""출력 파서를 사용하지 않는 경우
from itertools import chain
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"다음의 이메일 내용중 중요한 내용을 추출해 주세요.\n\n{email_conversation}"
)
llm = ChatOpenAI(temperature=0, model_name="gpt-4o")
chain = prompt | llm
answer = chain.stream({"email_conversation": email_conversation})
output = stream_response(answer, return_output=True)출력값
**중요한 내용 추출:**
1. **발신자:** 김철수 (chulsoo.kim@bikecorporation.me)
2. **수신자:** 이은채 (eunchae@teddyinternational.me)
3. **제목:** "ZENESIS" 자전거 유통 협력 및 미팅 일정 제안
4. **요청 사항:**
- ZENESIS 모델에 대한 상세한 브로슈어 요청 (기술 사양, 배터리 성능, 디자인 정보 포함)
5. **미팅 제안:**
- 날짜: 다음 주 화요일 (1월 15일)
- 시간: 오전 10시
- 장소: 귀사 사무실내가 생각한 것 보다 꽤 괜찮은 답변이 나왔지만 출력 파서를 사용하는 이유는
내가 원하는 방향으로 답변이 나오게하기 위해서이다.
프로젝트를 계획해서 시스템을 만들 때 구조화된 데이터가 나오지 않으면
다른 시스템들과의 파라미터 매핑오류로 정상적인 작동이 어려울 수 있다.
따라서 출력 파서를 통해 시스템이 요구하는 데이터로 구조화 시키기 위해 출력파서를 사용한다.
Pydantic 사용
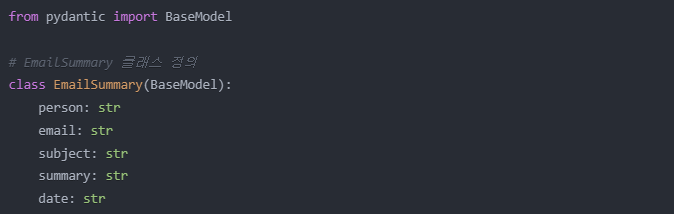
class EmailSummary(BaseModel):
person: str = Field(description="메일을 보낸 사람")
email: str = Field(description="메일을 보낸 사람의 이메일 주소")
subject: str = Field(description="메일 제목")
summary: str = Field(description="메일 본문을 요약한 텍스트")
date: str = Field(description="메일 본문에 언급된 미팅 날짜와 시간")
# PydanticOutputParser 생성
parser = PydanticOutputParser(pydantic_object=EmailSummary)Python의 BaseModel을 상속받아 데이터 모델을 정의한다.
EmailSummary라는 클래스를 만들어 Field 클래스를 정의한다.
Field 클래스 = 필드의 메타데이터 정의
description : LLM이 각 필드의 의미를 이해하는 데 사용됨
description
Field 안에 description은 텍스트 형태의 답변에서
주요 정보를 추출하기 위한 설명이다.
LLM이 이 설명을 보고 필요한 정보를 추출하게 된다.
그러므로 이 설명은 정확하고 명확해야 한다.
출력값

그에 따른 JSON 형태의 출력값이다.
이 출력값이 EmailSummary의 형식을 따른 값이 아니라
그냥 LLM이 뱉은 단순한 텍스트 형식의 JSON 형태 문자열이다.
웹사이트를 만들어서 해당 출력파서가 필요한 상황에 직면한다면
Json형태의 문자열만으로는 프로그램 구동에 문제가 생긴다.
여기서 ! PydanticOutputParser가 위에서 정의한 EmailSummary 클래스의 인스턴스로 변환한다.
코드 구성
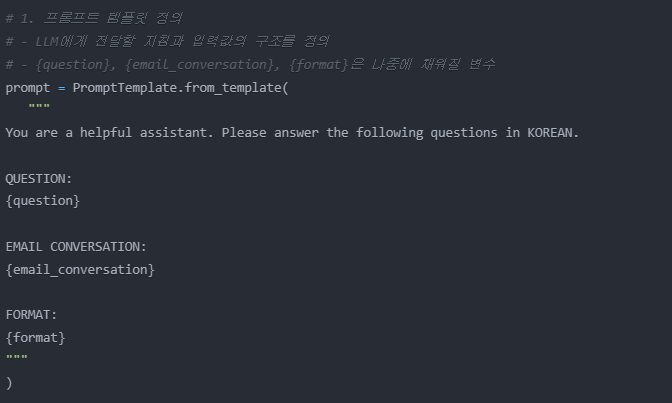
그 후 프롬프트 템플릿을 정의한다
{} 부분은 나중에 채워질 변수이다.
프롬프트를 구성하는 요소는 아래와 같다

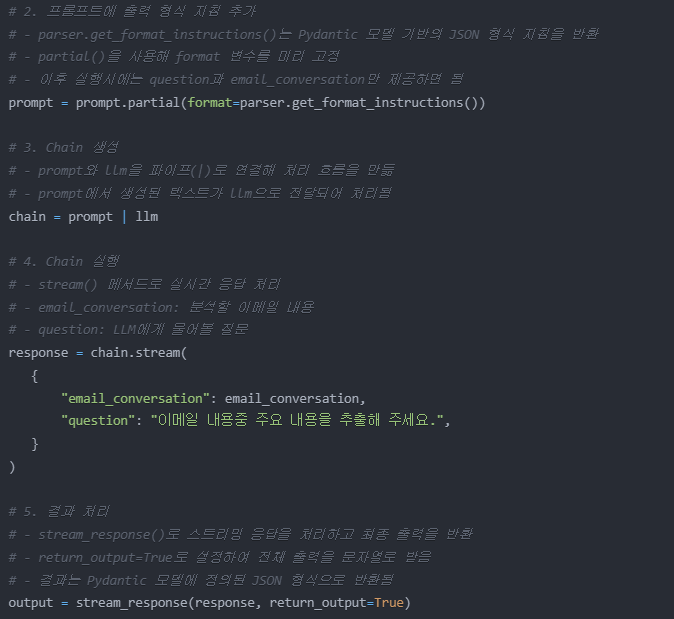
get_format_instructions() 함수는 EmailSummary 클래스에서 정의한
데이터 구조와 형식에 대한 정보를 가져온다.
가져온 형식 지침은 PydanticOutputParser에서 사용된다.
PydanticOutputParser는 LLM이 생성한 JSON 형식의 출력값을
EmailSummary 객체로 변환할 때 이 형식 지침을 활용한다.

그리고 parser를 사용하여 결과를 파싱하고 EmailSummary 객체로 변환한다.

parser가 추가된 체인 생성

랭체인에서 파서(Parser)는 체인의 마지막 단계에 추가되어
LLM이 생성한 출력을 원하는 Python 객체로 변환하는 역할을 한다.
Prompt : 입력 지침 제공
LLM : JSON 형태의 출력 생성
Parser : JSON을 지정한 Python 클래스(Pydantic 모델)의 객체로 변환
한마디로 내가 프로그램을 만들 때 LLM이 뱉은 결과를 바탕으로
다음 단계를 이어가야하는데 JSON 문자열은 문자열 그대로이기 때문에
다음 로직에서 요구하는 Python 객체나 특정 데이터 타입과 매칭되지 않아서 오류가 발생한다.
따라서 PydanticOutputParser로 유효한 데이터 타입으로 변환시키는 것이다.
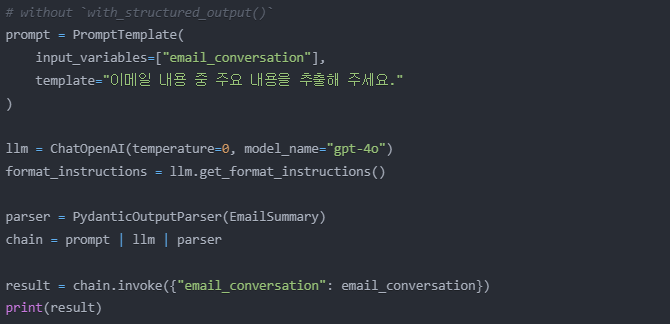
with_structured_output()
LLM의 출력을 Pydantic 객체로 변환할 수 있게 해준다.
Pydantic은 Python의 데이터 모델링 라이브러리로 데이터의 유효성 검사와 형식 지정을 지원한다.
이 메서드는 전체 체인 구성에서 LLM 모델 정의 후, 출력 파서를 추가하는 부분에 들어간다.
해당 메서드를 사용하면 LLM의 출력이 자동으로 EmailSummary 클래스 (사용자가 지정한 데이터 타입이 정의되어 있는 클래스) Pydantic 객체로 변환된다.
이 메서드를 사용하면 따로 get_format_instructions()를 호출하거나 파서를 체인 마지막에 직접 연결하지 않아도 된다.
EmailSummary 클래스 정의
without
with
with_structured_output()을 쓰나
get_format_instructions() 호출과 PydanticOutputParser 연결을 해서 쓰나 결과 값은 같다.
하지만 with_structured_output()가 데이터 구조나
요구사항이 Pydantic 모델과 일치하지 않는 경우가 발생할 수 있다.
이런 경우 get_format_instructions()와 PydanticOutputParser를 구현해서 유연하고 세밀한 제어를 하는 것이다.
