Safety Settings란
Gemini와 같은 생성형 AI 모델의 출력을 제어하는 안전장치 시스템이다
모델이 생성하는 콘텐츠의 위험성과 적절성을 필터링하는 메커니즘을 제공한다
기본적으로 내장된 안전 설정이 있으며, 개발자가 필요에 따라 이를 조정할 수 있다Safety Settings를 사용하는 경우
- 모델이 너무 엄격한 제한으로 인해 필요한 출력을 생성하지 못할 때
- 특정 연구나 교육 목적으로 일부 제한적인 콘텐츠에 대한 접근이 필요할 때
- 모델의 응답이 과도하게 필터링되어 유용한 정보까지 차단되는 경우
- 프로젝트의 특성에 맞게 콘텐츠 필터링 수준을 세밀하게 조정해야 할 때
사용 방법
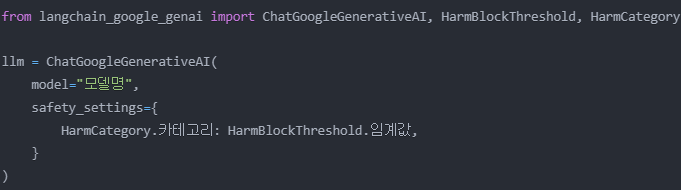
- HarmCategory로 제어할 카테고리를 지정
- HarmBlockThreshold로 각 카테고리의 차단 수준을 설정
주요 기능
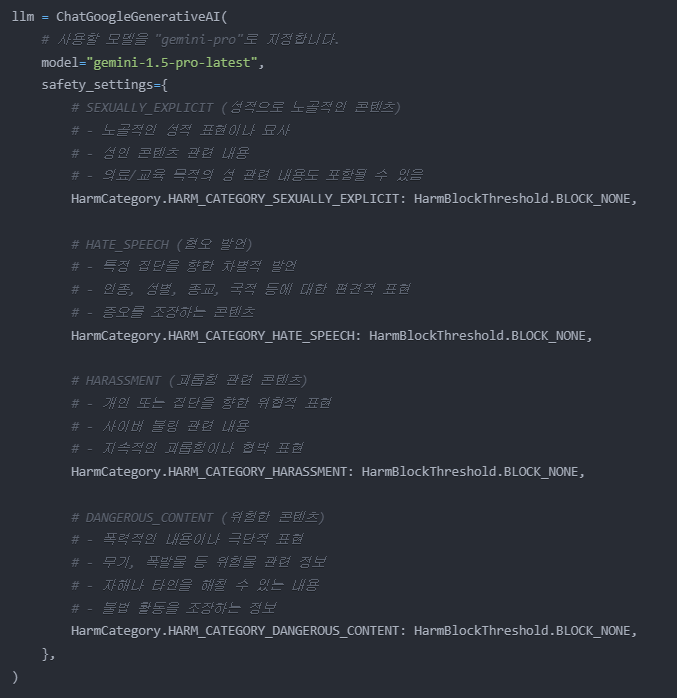
SEXUALLY_EXPLICIT: 성적으로 노골적인 콘텐츠
HATE_SPEECH: 혐오 발언
HARASSMENT: 괴롭힘 관련 콘텐츠
DANGEROUS_CONTENT: 위험한 콘텐츠
차단 임계값(HarmBlockThreshold)
BLOCK_NONE: 최소한의 필터링 (기본적인 안전장치는 유지)
BLOCK_LOW: 낮은 수준의 필터링
BLOCK_MEDIUM: 중간 수준의 필터링
BLOCK_HIGH: 높은 수준의 필터링
차단 임계값에 따른 차이
- BLOCK_NONE (최소 필터링)

-
필터링 수준 : 최소한의 기본 안전장치만 유지
-
허용되는 콘텐츠 예시:
의료: 상세한 수술 절차 설명
보안: 구체적인 해킹 기법 설명
역사: 전쟁 범죄의 상세 내용
- 여전히 차단되는 콘텐츠:
불법 행위 조장
극도로 유해한 콘텐츠
- BLOCK_LOW (낮은 수준 필터링)

-
필터링 수준 : 기본적인 제한만 적용
-
허용되는 콘텐츠 예시:
의료: 기본적인 신체 설명
교육: 일반적인 성교육 자료
과학: 생물학적 연구 자료
- 차단되는 콘텐츠:
노골적인 성적 표현
불필요하게 자세한 묘사
- BLOCK_MEDIUM (중간 수준 필터링)

-
필터링 수준 : 균형잡힌 제한 적용
-
허용되는 콘텐츠 예시:
보안: 일반적인 위협 설명
연구: 온라인 괴롭힘 사례 분석
교육: 예방 교육 자료 -
차단되는 콘텐츠:
구체적인 괴롭힘 방법
위협적인 표현
- BLOCK_HIGH (높은 수준 필터링)

-
필터링 수준 : 매우 엄격한 제한
-
허용되는 콘텐츠 예시:
역사: 객관적 사실 서술
뉴스: 중립적 보도 내용
연구: 통계적 분석 자료 -
차단되는 콘텐츠:
편향된 표현
차별적 용어
논쟁적 주제
차단 임계값에 따른 콘텐츠별 차이
SEXUALLY_EXPLICIT (성적 콘텐츠)

HATE_SPEECH (혐오 발언)

HARASSMENT (괴롭힘)

DANGEROUS_CONTENT (위험 콘텐츠)

사용하는 이유
의도하지 않은 과도한 필터링 방지
의학 정보를 요청했는데 신체 관련 설명이 차단됨
역사적 사실을 물어봤는데 전쟁/폭력 관련 내용이 필터링됨
보안 취약점 분석 시 위험 요소 설명이 차단됨
연구/교육 목적의 접근성 확보
의료 교육 자료 생성
사이버 보안 교육 콘텐츠 제작
역사 교육 자료 작성
법률/범죄학 연구 자료 수집
사용하지 않았을 때 문제점

실제 적용 사례
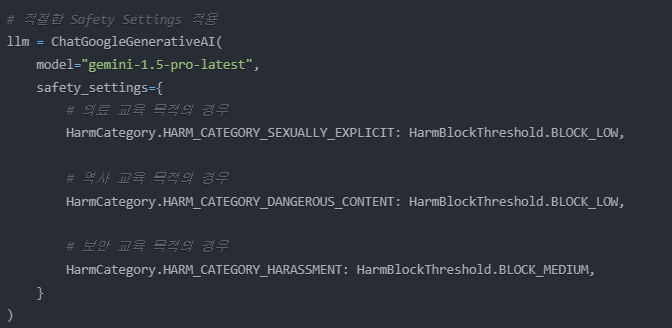
의료 교육: 신체 관련 설명을 위해 성적 콘텐츠 필터링 완화
역사 교육: 역사적 사실 설명을 위해 위험 콘텐츠 필터링 완화
보안 교육: 보안 위협 설명을 위해 괴롭힘 관련 필터링 조정
